


Inspiration
Hackathons are where innovation is supposed to thrive—but judging them has quietly become one of the hardest unsolved problems in tech.
As hackathons scale to hundreds or thousands of submissions, organizers increasingly rely on AI to assist evaluation. Unfortunately, most AI judges today are:
- Opaque black boxes
- Impossible to audit
- Unobservable when they fail
- Blind to bias, drift, or disagreement
Having participated in and organized dozens of hackathons across Africa and globally, I’ve seen the consequences firsthand:
- Scores drifting without explanation
- Strong projects buried due to noisy or inconsistent signals
- LLM-based tools failing silently with no accountability
HackSight started with a simple but uncomfortable question:
If AI is going to judge builders — who is judging the AI?
What it does
HackSight is an observability-first AI judging platform for hackathons, accelerators, and grant programs.
Instead of a single opaque model, HackSight uses multiple specialized LLM agents, each responsible for a specific evaluation dimension:
- Code Agent – evaluates repository quality, architecture, and implementation depth
- Market Agent – assesses problem relevance, users, and competitive positioning
- Chat Agent – enables conversational clarification and feedback
- Score Agent – synthesizes signals into structured, explainable scores
Every agent decision is:
- Logged
- Traced
- Measured
- Auditable
This turns AI judging from a black box into an explainable, inspectable system.
How we built it
HackSight is built as a production-grade AI system, not a demo.
Architecture highlights
- Frontend + Backend fully instrumented
- LLM agents running on Vertex AI / Gemini
- Structured outputs enforced for:
- Scores
- Confidence levels
- Reasoning summaries
- Scores
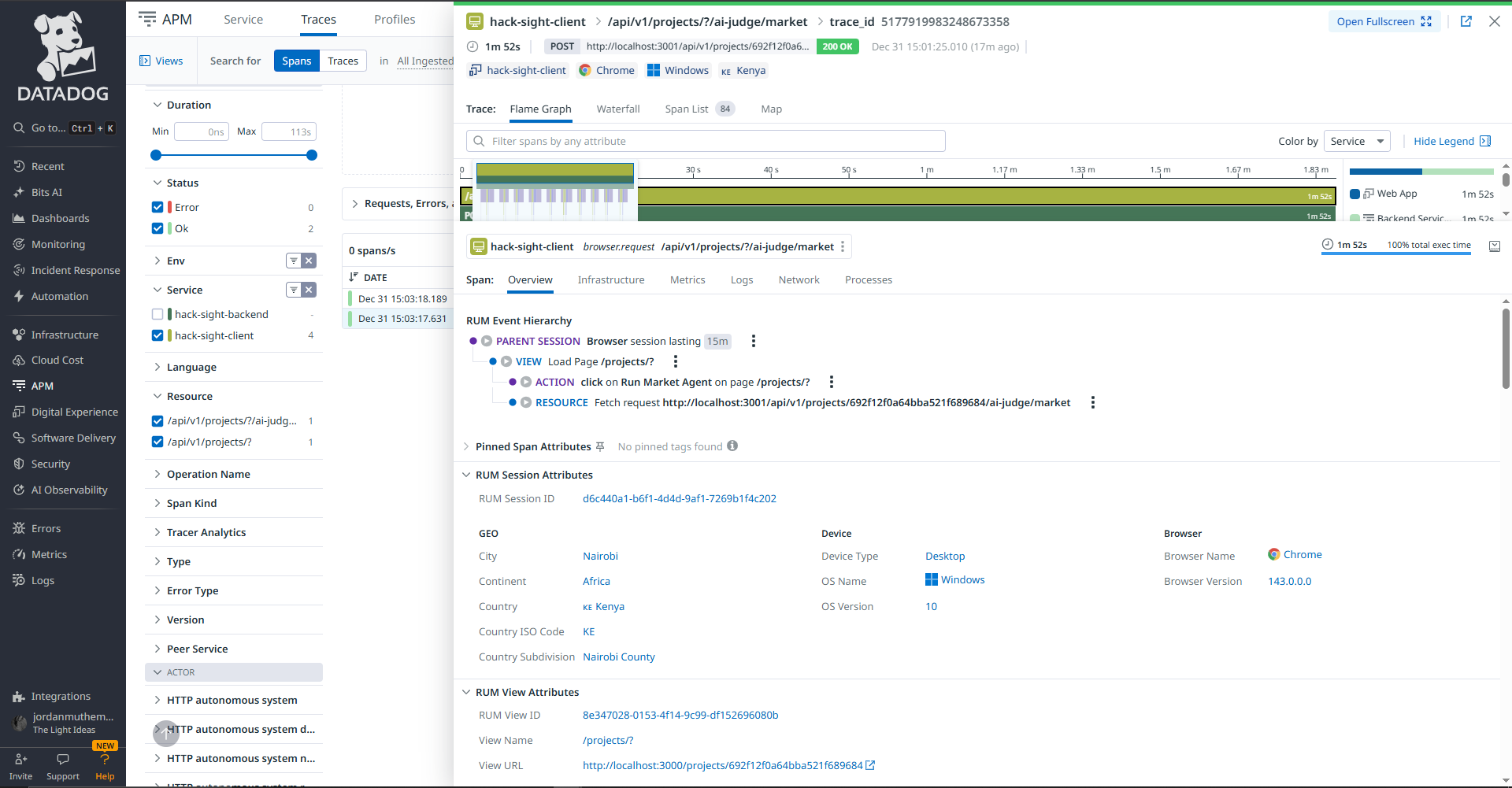
- Frontend user actions traced via RUM
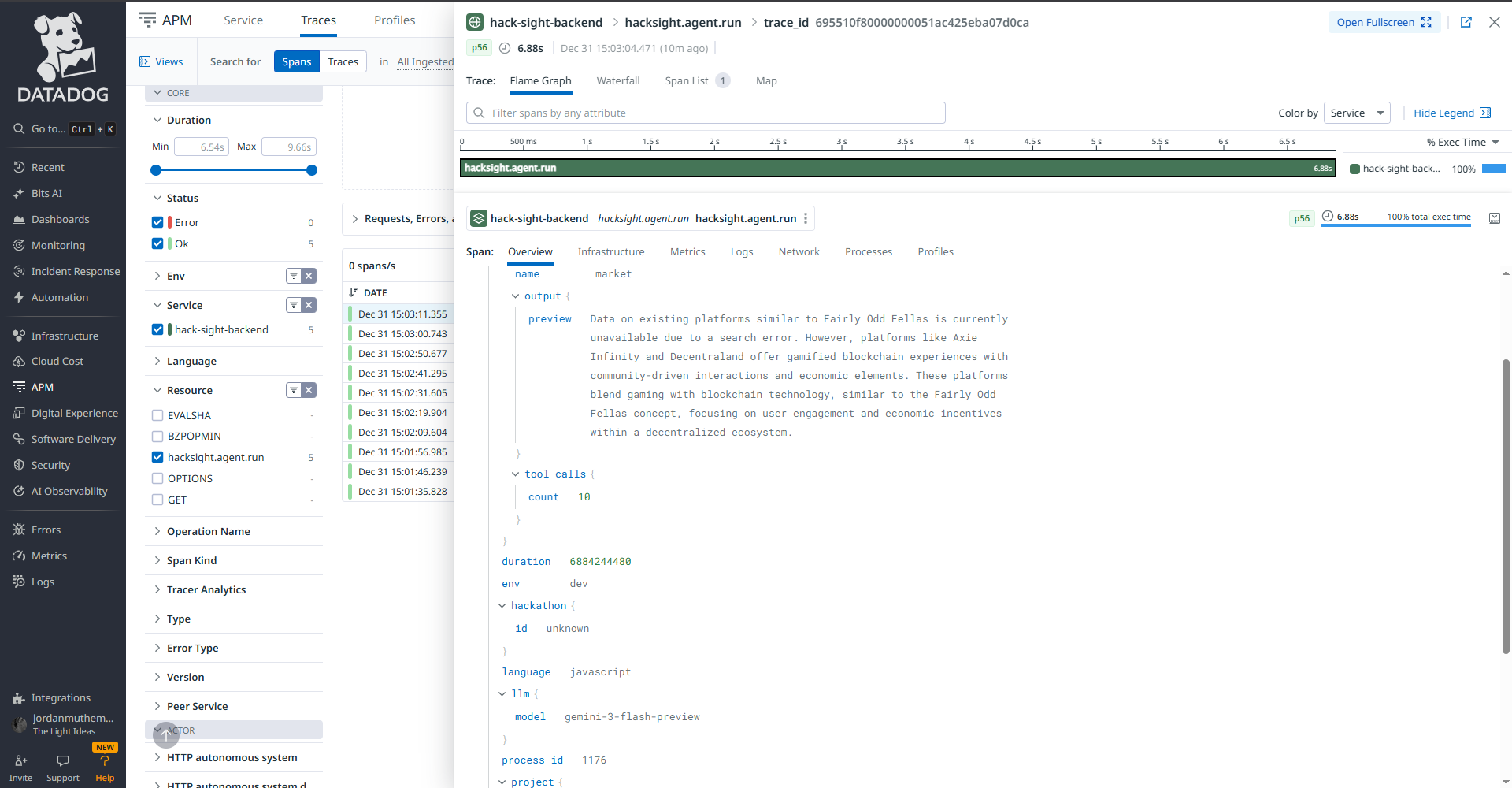
- Backend agent execution traced via APM
Observability pipeline
Each agent emits structured telemetry including:
- Prompt + response metadata
- Latency per agent run
- Token usage
- Confidence scores
- Cross-agent disagreement signals
All telemetry is streamed into Datadog, where we:
- Visualize agent health and latency
- Track score variance and drift over time
- Detect anomalies in agent behavior
- Correlate frontend actions → backend agent execution → LLM output
This allowed us to treat LLMs like real infrastructure:
observable, debuggable, and improvable.
Observability & evaluation (core focus)
HackSight implements end-to-end observability for LLM applications, including:
- Agent reliability dashboards
- Score variance and bias detection
- Latency and cost tracking per agent
- Full traceability from user action → agent → model → score
- Human-in-the-loop overrides when confidence drops
Automated alerts can be triggered when:
- Scores deviate beyond defined thresholds
- Agents contradict each other
- Confidence drops unexpectedly
- Latency or cost spikes
When this happens, Datadog surfaces a fully contextualized incident, allowing judges or organizers to intervene with confidence.
Challenges we ran into
This project forced us to solve real, non-trivial problems:
- Designing meaningful agent disagreement metrics that reflect evaluation risk, not just variance
- Structuring LLM outputs so they are both human-readable and machine-observable
- Balancing depth vs latency vs cost in real-time evaluation flows
- Avoiding hallucinated confidence by enforcing structured reasoning and explicit confidence scoring
- Correlating frontend RUM events with backend agent traces to get true end-to-end visibility
These challenges pushed us to treat observability as a first-class product feature, not an afterthought.
Accomplishments we’re proud of
- Built a multi-agent AI judging system that behaves like production software
- Implemented real-time LLM observability dashboards, not offline reports
- Successfully surfaced agent disagreement and score drift using live telemetry
- Achieved full traceability from UI click → API → agent → model → score
- Demonstrated that AI-assisted judging can scale without sacrificing trust
- Proved Datadog can be used as a first-class LLM observability platform
What we learned
- LLM systems fail silently unless you instrument them
- Observability dramatically increases trust in AI decisions
- Hackathons are a brutal but perfect real-world stress test for AI systems
- AI judges must be explainable, accountable, and measurable to be useful
What’s next for HackSight
- Streaming ingestion of submissions and evaluations
- Deeper bias and fairness analysis
- Voice-based conversational feedback
- Expansion beyond hackathons into:
- Grants
- Accelerators
- DAO governance and funding decisions
- Grants
HackSight is not just an AI judge it’s a blueprint for building trustworthy, observable AI systems in the real world.
Built With
- datadog
- express.js
- github-api
- google-cloud
- mongodb
- nextjs
- node.js
- react
- shadcn
- typescript


Log in or sign up for Devpost to join the conversation.