-
-
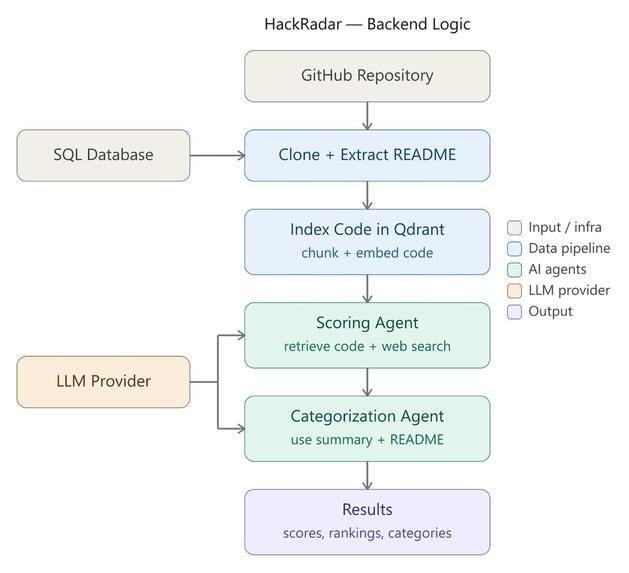
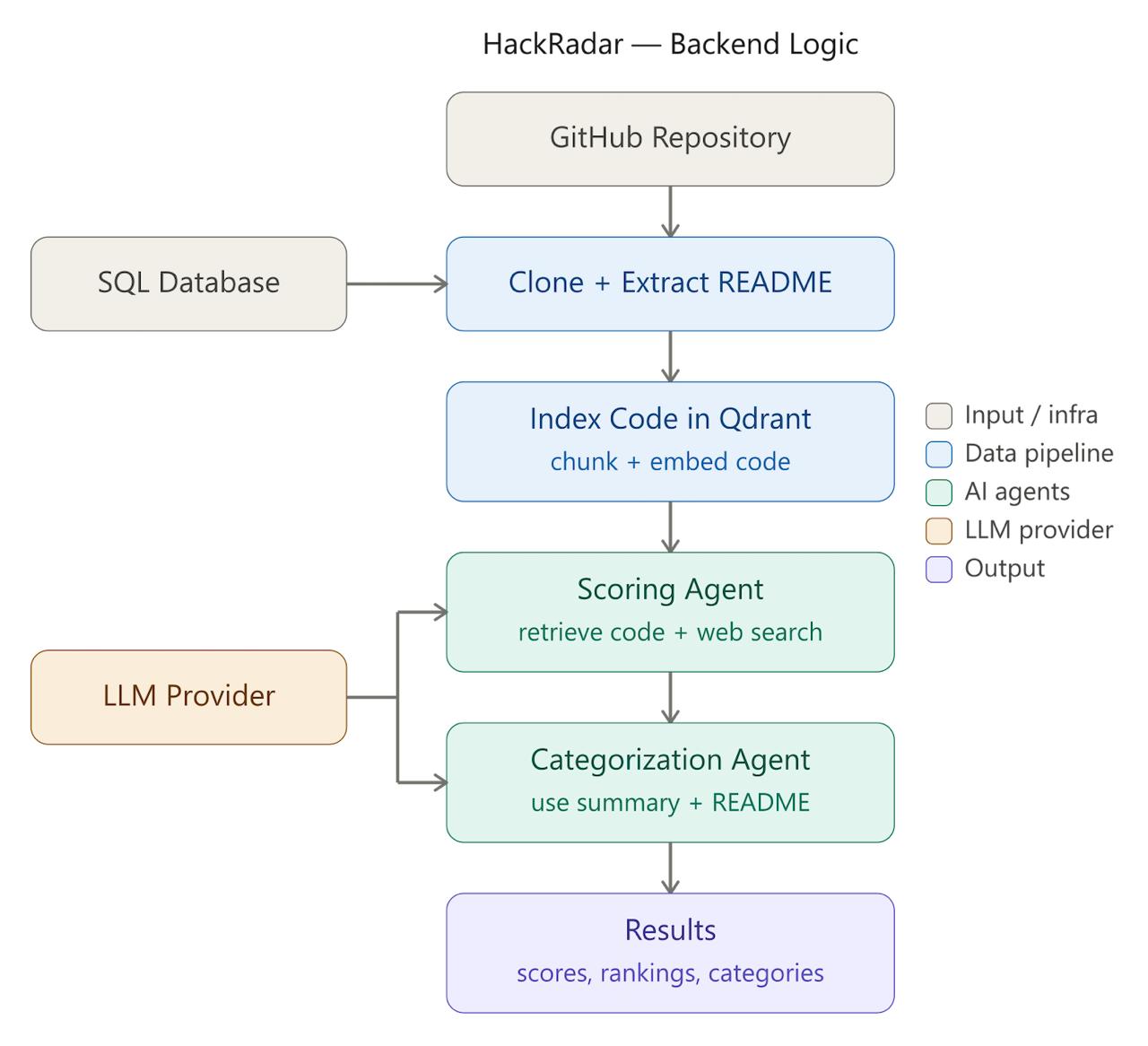
workflow
Inspiration
Every hackathon faces the same bottleneck: judging. Dozens — sometimes hundreds — of projects need to be evaluated fairly, but judges are human. They get tired, they read READMEs that oversell, and they rarely have time to actually look at the code. We've all seen a flashy demo win over a technically impressive project simply because the README told a better story.
We asked ourselves: what if judging was grounded in what teams actually built — the code itself?
That question led to HackRadar. The idea was to build a system that doesn't just read project descriptions — it reads the source code, understands it semantically, and evaluates it against custom criteria with full rationales. Not to replace human judges, but to give them a head start: unbiased, evidence-backed scores they can review, adjust, and trust.
What it does
HackRadar is an AI-powered hackathon judging system. You give it GitHub repository URLs and a set of weighted judging criteria, and it:
- Clones each repository and splits the source code into semantically meaningful chunks using tree-sitter (supporting 13+ languages).
- Indexes those chunks as vector embeddings in a per-project Qdrant collection.
- Retrieves the most relevant code snippets for each judging criterion via semantic search (RAG).
- Scores each criterion on a 0–10 scale with detailed rationales citing specific files, functions, and patterns.
- Ranks all projects by a weighted overall score.
- Categorizes projects — either into predefined categories or by letting the AI discover natural clusters.
The final overall score is computed as a weighted average:
S_overall = (w₁·s₁ + w₂·s₂ + ... + wₙ·sₙ) / (w₁ + w₂ + ... + wₙ)
where sᵢ is the score for criterion i and wᵢ is its weight. This ensures criteria like "Technical Complexity" can carry more influence than "UI Polish" (or vice versa), depending on what the hackathon values.
How we built it
Backend — Python with FastAPI. We used SQLAlchemy 2.0 (async) for the data layer, with Alembic for schema migrations. The core AI pipeline is built on:
- LlamaIndex with tree-sitter-based
CodeSplitterfor language-aware chunking (40 lines per chunk, 5-line overlap, ≤1500 characters). - Sentence Transformers (
allenai-specter) for encoding code semantics into 768-dimensional embeddings. - Qdrant as the vector database, with one collection per project for retrieval isolation.
- Railtracks for agent orchestration, with LiteLLM enabling seamless switching between Google Gemini, OpenAI, and any OpenAI-compatible endpoint.
We designed two scoring strategies to handle the reality that not all LLM providers support function calling:
- ToolCallStrategy — the agent dynamically invokes
search_project_codeandgoogle_searchtools as needed (for Gemini/OpenAI). - RAGPrefetchStrategy — all evidence is pre-fetched and injected into the prompt for providers that lack tool support.
Frontend — Next.js 16 with React 19, TailwindCSS 4, and React Query v5 for data fetching and caching. The UI covers the full workflow: uploading projects (including bulk CSV/TXT import), managing criteria sets, triggering scoring, and viewing ranked results with per-criterion breakdowns.
Infrastructure — Qdrant runs in Docker. SQLite for development, PostgreSQL-ready for production via SQLAlchemy's async engine abstraction.
Challenges we ran into
Parsing code across 13+ languages. Each language has different syntax rules, and a naive text splitter would break functions in half. We solved this with tree-sitter-aware splitting, grouping files by language and applying language-specific parsers. When a parser fails (e.g., for an unsupported dialect), we fall back gracefully to raw document splitting.
Function-calling compatibility. We wanted agents that could dynamically decide when to search code and when to search the web. But some LLM endpoints (particularly self-hosted ones) don't support function calling at all. Rather than locking users into one provider, we built the dual-strategy architecture: ToolCallStrategy for capable models and RAGPrefetchStrategy as a universal fallback — same quality, different plumbing.
Global coherence in categorization. If you categorize projects one at a time, you get inconsistent, duplicate categories ("Web App" vs "Web Application" vs "Web-Based Tool"). Our solution: process all projects in a single LLM call so the model sees the full landscape and produces globally coherent clusters.
LLM output reliability. Language models don't always produce valid JSON. We built robust parsing that extracts JSON from markdown code blocks, handles partial outputs, and falls back to sensible defaults rather than crashing the pipeline.
Blocking I/O in an async world. Embedding computation is CPU-heavy and blocks the event loop. We wrapped the ingestion pipeline in run_in_executor to keep the FastAPI server responsive during heavy indexing workloads.
What we learned
- RAG changes the game for code understanding. Instead of asking an LLM to "rate this project" with a wall of source code, retrieving only the relevant snippets per criterion produces dramatically better and more grounded evaluations.
- Embedding model choice matters.
allenai-specterwas designed for scientific text, but its ability to capture semantic similarity in technical content transfers surprisingly well to source code — cosine similarity over specter embeddings proved effective for matching criteria descriptions to relevant code. - Abstractions pay off at the right time. The
ModelFactory+ strategy pattern felt like over-engineering at first, but when we added OpenAI-compatible endpoint support later, it slotted in cleanly without touching the scoring logic. - Tree-sitter is underappreciated. Having AST-aware code splitting means chunks respect function boundaries, class definitions, and logical blocks — which directly improves retrieval quality compared to naive line-based splitting.
Built With
- docker
- fastapi
- gemini
- litellm
- llamaindex
- next.js
- openai
- python
- qdrant
- railtracks
- react
- sqlalchemy
- tailwindcss

Log in or sign up for Devpost to join the conversation.