-
-

Game Client
-
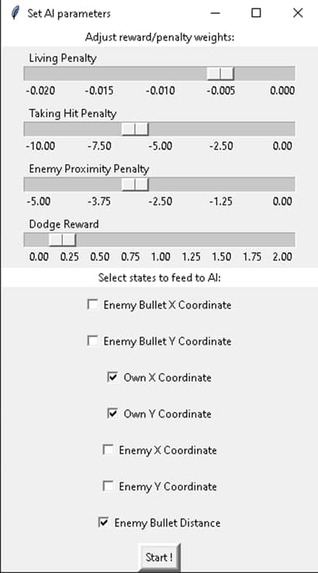
AI Configuration
-
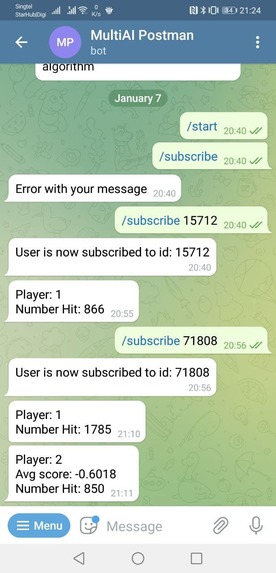
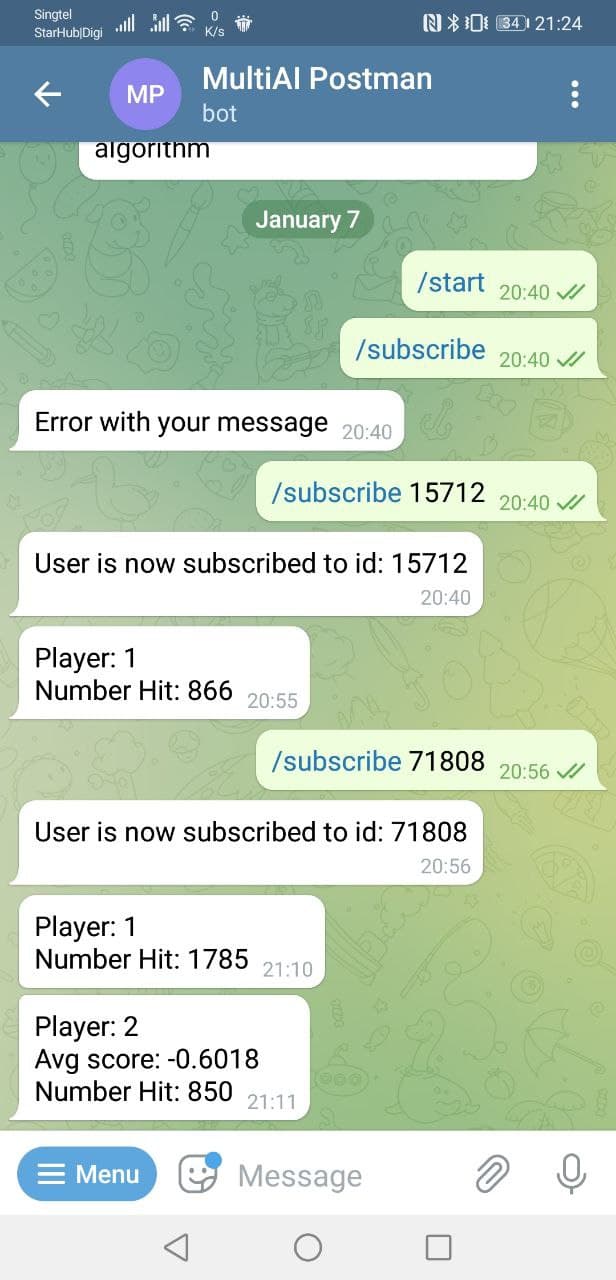
Telegram Bot to remind user of AI training progress
-
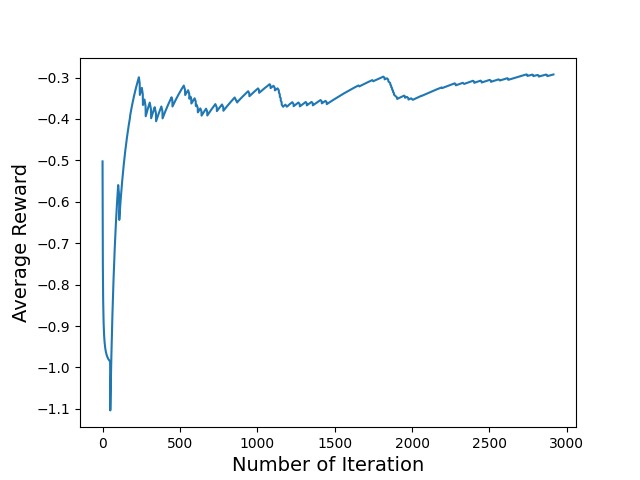
AI Training Graph


HackNRoll-2022
2D Shooting Multiplayer AI Playground
LAN/WAN based multiplayer training environment for players to compete with their AI that they made. Players can also train their AI locally before joining in the battle competitive AI battle.
System Requirements
- At least a duo core CPU.
- Nvidia GPU as we need CUDA.
- Preferably Intel CPU since they have better support for their own Math Kernel Library (MKL) and Advanced Vector Extention (AVX).
Inspiration
We always wanted a platform where AI enthusiast/beginners can come together to train their agent and then fight with each other through LAN/WAN multiplayer. In this way, player from across the globe can either train their agent together or compete against each other to see whose AI is the best. The AI should also have a GUI to make it easy for AI beginners to make quick tweaks to the state and reward instead of having to read through the long code and determine what to change. Moreover, in most cases on YouTube, people used AI agent to play a game locally and we can't find anyone doing a multiplayer AI agent game. So it will be a very good experiment also to see how Deep Q-Learning pair with multiplayer.
Game Rules
The game is primarily centered around making an AI movement DQN such that the AI must be able to dodge the enemy's bullet while maintaining a close enough distance to the enemy. Because each player can only fire only when their bullet disappears due to collision, thus the closer the player is to the enemy, the faster the player can shoot at the enemy at the risk of being shot by the enemy also.
The AI is made to aim at the enemy position automatically due to time constraints instead of using a shooting DQN.
AI implementation
The AI uses Deep Q-Learning/Reinforcement-Learning with experience replay. The DQN allows us to train the agent based on reward-based learning. Positive reward if it does the correct action and negative otherwise. The experience replay also allows the AI to not just learn to optimize reward but also allow it to look back and think about what are the steps to take such that it can result in a long-term reward. Because sometimes taking 1 step back can let the agent take 3 steps forward.
Features
- Server with multi-paired sessions. (Each session/room consist of 2 players where player 1 will be the session's host)
- WAN/LAN-based multiplayer.
- GUI for choosing AI parameters and tweaking reward weight.
- Lets users choose parameters and tweak reward weight for their agent which will influence how the AI 'learns'
- Save/Load AI Deep Q network
- Users can Save/Load AI from previous iterations.
- Graph to show average reward of the agent
- Plot a graph to show the average reward of the user's agent over time/iterations.
- Randomized training adversary
- A training agent to train the user's agent such that the agent will not “overfit” and generate more extreme test cases which AI will have to learn to dodge.
- Telegram Notification
- Telegram bot to inform users of the Machine Learning progress of their agent.
- Toggle agent control
- Toggle between AI control and manual control of the user's agent to allow the user to fight manually with the opponent AI
Project Structure
This project is structured in a Server-Client format. Each Client has their own AI to control the agent. Each Client can also save and load AI and toggle manual control. The server is only responsible for synchronizing player and enemy coordinates and storing them.
Just for fun
Benjamin vs Wei Hng DQN Agent. Wei Hng's states used (Player X, Player Y, Bullet X, Bullet Y), Benjamin states used (Player X, Player Y, Bullet distance). Both trained with adversary agent before deploying on WAN at (whyelab.ddns.net) to fight. Over a period of 1 hour, Ben Score: 986, WHY Score: 739. Benjamin wins!
So more states doesn't necessarily mean that a AI will be better. You also need to account for your opponent's behavior and tweak your AI accordingly.
Challenges Faced
1) Configuring sockets for LAN/WAN
The networking server must be able to store the coordinates of player and enemies and their bullets. The server also needs to be able to receive client data and send back updated data back to the client. It also needs to be able to synchronize the data such that each of the 2 clients must take turns to update their player state.
For WAN configuration, we must enable port forwarding in the host router and set up Dynamic DNS so that players across the world can connect to the host.
2) Deep Q-Learning with Experience Replay
It is quite difficult to optimize the states to be passed into the DQN since there are many important parameters such as player, enemy, player bullet, enemy bullet x & y coordinates. However we could not pass in that many as it will confuse the DQN and also is very computationally expensive.
It took us a great amount of time through trial and error to optimize the DQN. We found that the key parameters are Player x and y coordinates and enemy's bullet x and y coordinates or enemy bullet distance. Of course there might be other configuration that we have not found out that will work well.
3) Shooting AI (targer_range.py)
Originally we had plans to integrate a shooting AI capable of approximating the enemy's future location. However, due to time constraints, complexity and how computationally expensive it would be for us to run both the movement and shooting AI simultaneously, we decided to not to include it in the submission.
However here are some overview of how we wanted to train it. We made a target range which have a target moving in different patterns like zig-zag, circular motion, straight line motion, stationary... And every time the target is hit, it will change the movement pattern to avoid "overfitting" the AI.
Note that there is actually no way for the AI to be able to predict the movement if the movement is totally random.




Log in or sign up for Devpost to join the conversation.