-
-
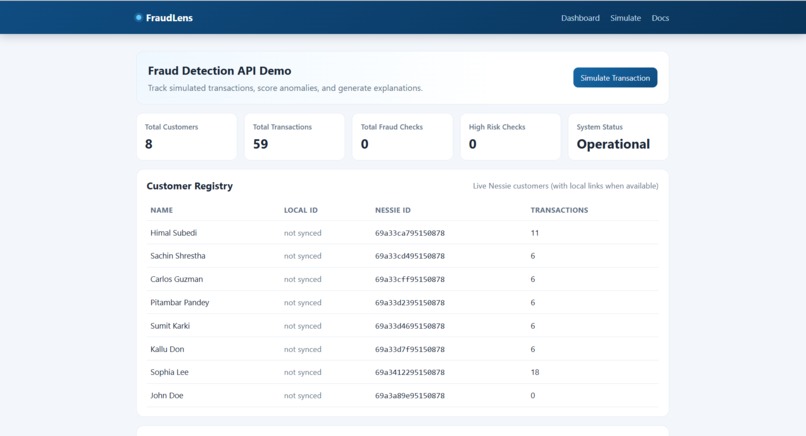
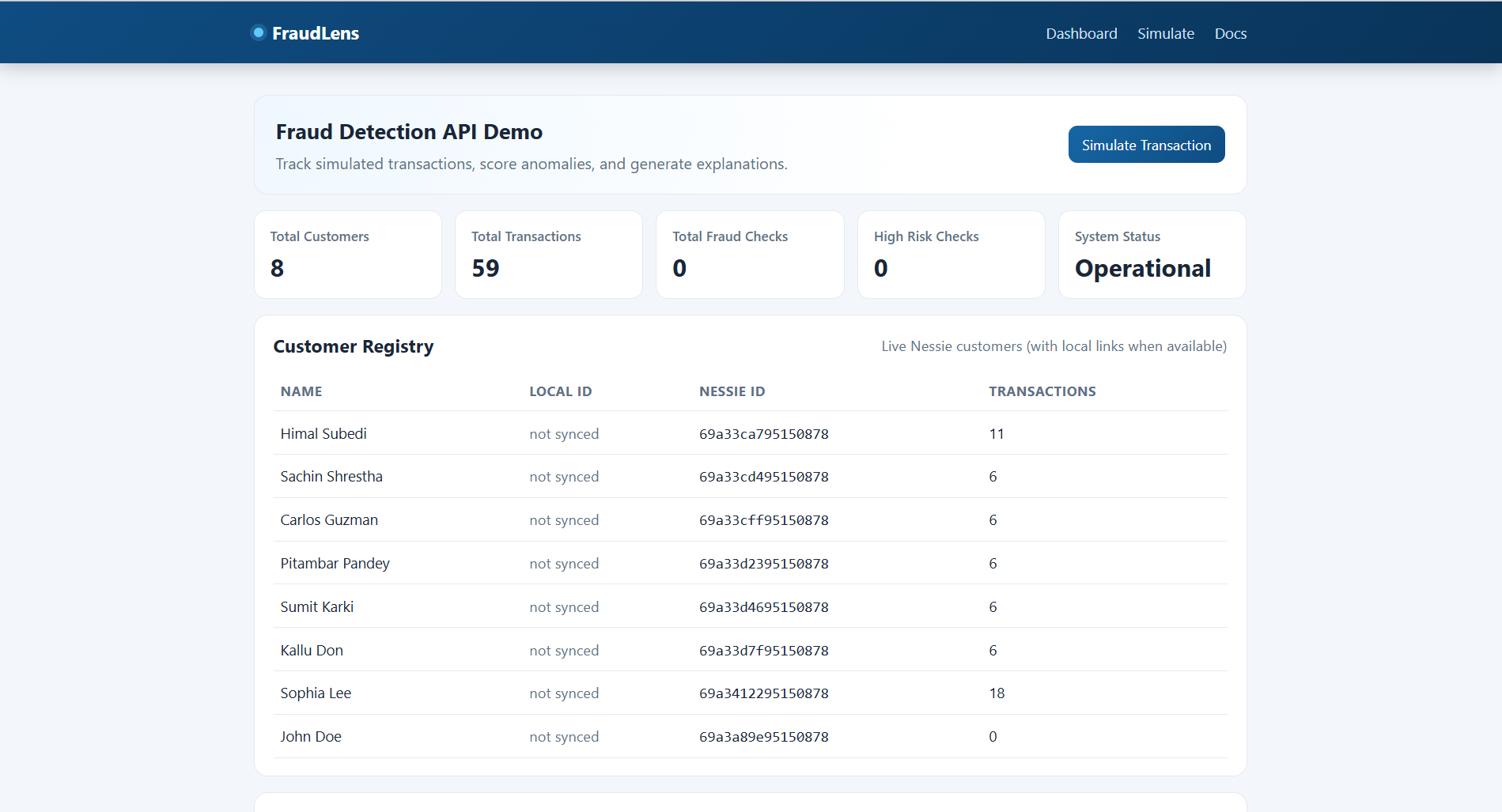
fraudlens-api.onrender.com
-
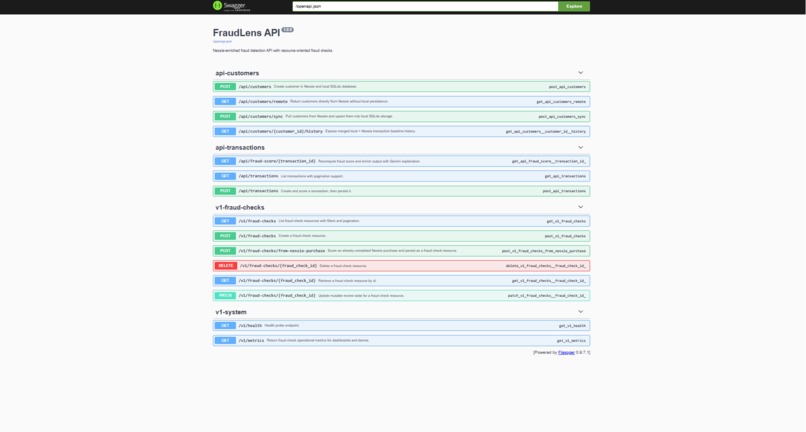
fraudlens-api.onrender.com/docs
-
fraudlens-api.onrender.com/openapi.json
Inspiration
Fraud in digital payments is often either a black-box ML decision or a static rules engine with poor developer UX. I wanted to build something in between: a practical API that gives fast fraud decisions and clear reasoning. The goal was to create a hackathon-ready backend that feels real-world: public HTTP endpoints, clear error semantics, idempotency, and explainable outputs.
What it does
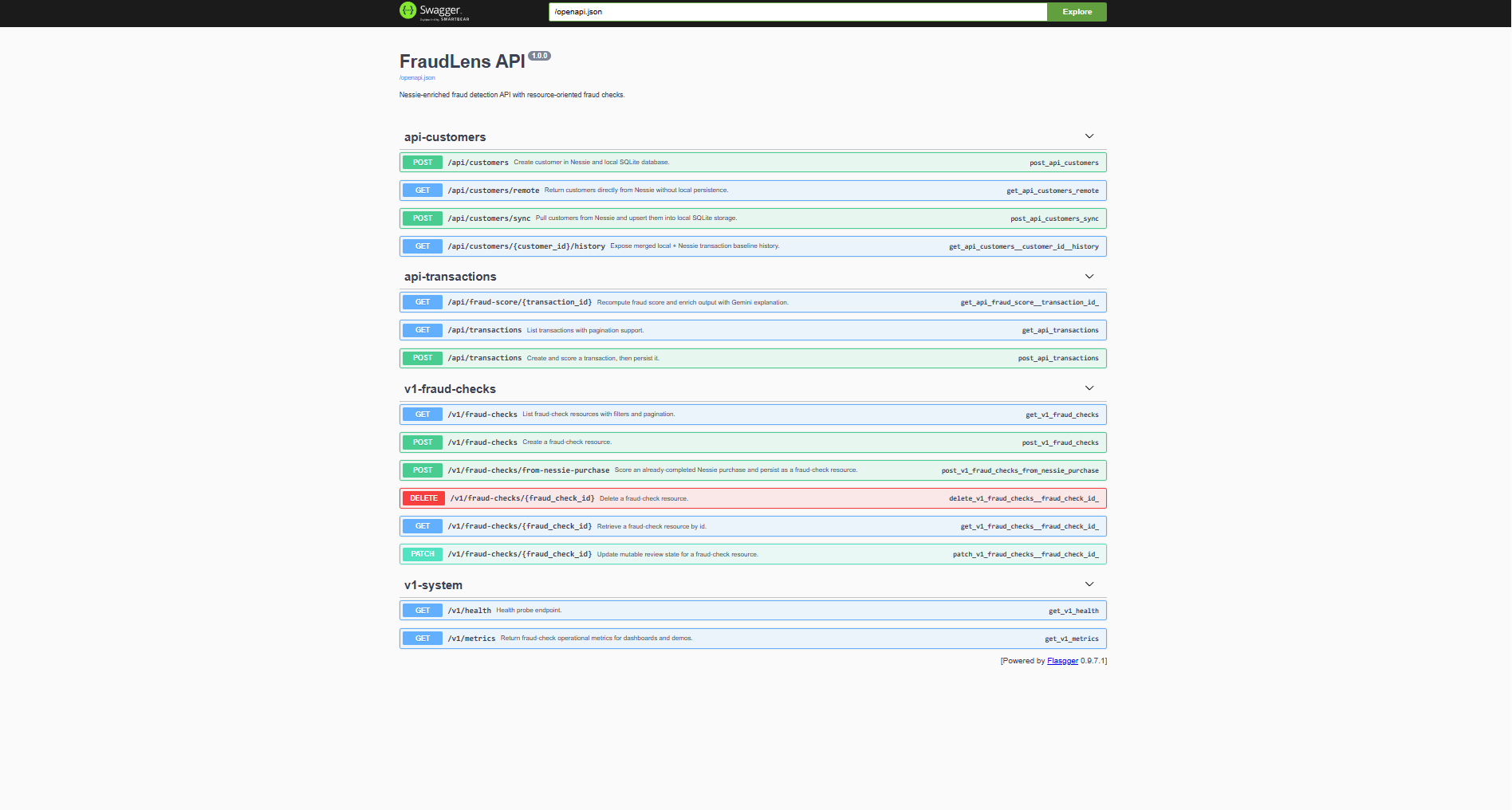
FraudLens is an API-first fraud detection platform that: Pulls customer and purchase history from Capital One Nessie Scores new or completed transactions using deterministic fraud rules Returns fraud_score, risk_level, risk_factors, and AI narrative Supports analyst workflows (list, filter, patch review status, delete checks) Exposes a public OpenAPI/Swagger surface for easy testing with cURL/Postman Core endpoints include: POST /v1/fraud-checks POST /v1/fraud-checks/from-nessie-purchase GET /v1/fraud-checks PATCH /v1/fraud-checks/{id} DELETE /v1/fraud-checks/{id} GET /v1/metrics
How we built it
Built FraudLens in Flask with a modular architecture:
- Blueprints for route separation (/api/, /v1/, web routes)
- SQLAlchemy + SQLite for fraud-check lifecycle and idempotency records
- Nessie service layer for customer/history retrieval
- Fraud engine for weighted rule-based scoring:
- amount deviation
- overnight anomaly
- location shift
- merchant-category shift
- Gemini integration for human-readable fraud narratives
- Flasgger for hosted Swagger docs and OpenAPI JSON
- Render deployment for public API accessibility ## Challenges we ran into 1) Upstream API quirks and consistency 2)Reliability under external failures 3)API design quality for judging criteria 4)Deployment and public accessibility ## Accomplishments that we're proud of
- Built a fully functional, public-facing fraud detection API with clear REST design and hosted Swagger docs.
- Integrated live Capital One Nessie customer/history data as the behavioral baseline for fraud scoring.
- Implemented end-to-end fraud-check lifecycle workflows: create, retrieve, list/filter, update review status, and delete.
- Added explainable outputs (fraud_score, risk_level, risk_factors, ai_explanation) instead of opaque decisions.
- Designed resilient behavior with idempotency and graceful fallback when AI providers are unavailable or rate-limited.
- Delivered a demo-ready dashboard and simulation flow that mirrors analyst and developer workflows. ## What we learned
- API quality is not just endpoints; reliability, validation, and consistent errors matter for real-world usability.
- Combining deterministic rules with LLM narratives creates practical explainability while preserving control.
- External integrations require defensive design (timeouts, retries, fallback messaging, sync strategies).
- Public deployment introduces operational concerns (startup config, env management, observability) beyond local dev.
- Data modeling for lifecycle state (review status, timestamps, idempotency records) is essential for fraud operations. ## What's next for FraudLens
- Add API key auth + tenant-level rate limits for production-style access control.
- Expand detection signals (velocity checks, device/IP risk, geo-distance anomalies, merchant novelty).
- Introduce analyst feedback loops to calibrate thresholds and improve precision over time.
- Add persistent production database + audit logs for long-term case history.
- Build webhook/event ingestion for real-time transaction streams.
- Launch richer operational analytics (/v1/metrics by time window, risk segment, and investigator outcomes).


Log in or sign up for Devpost to join the conversation.