-
-
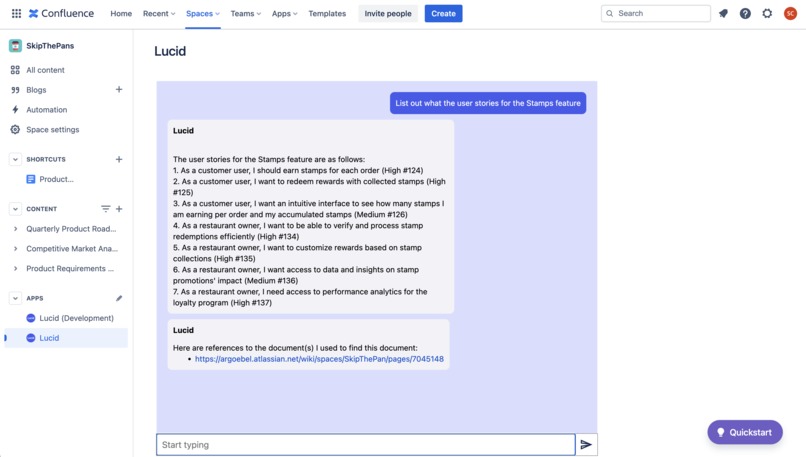
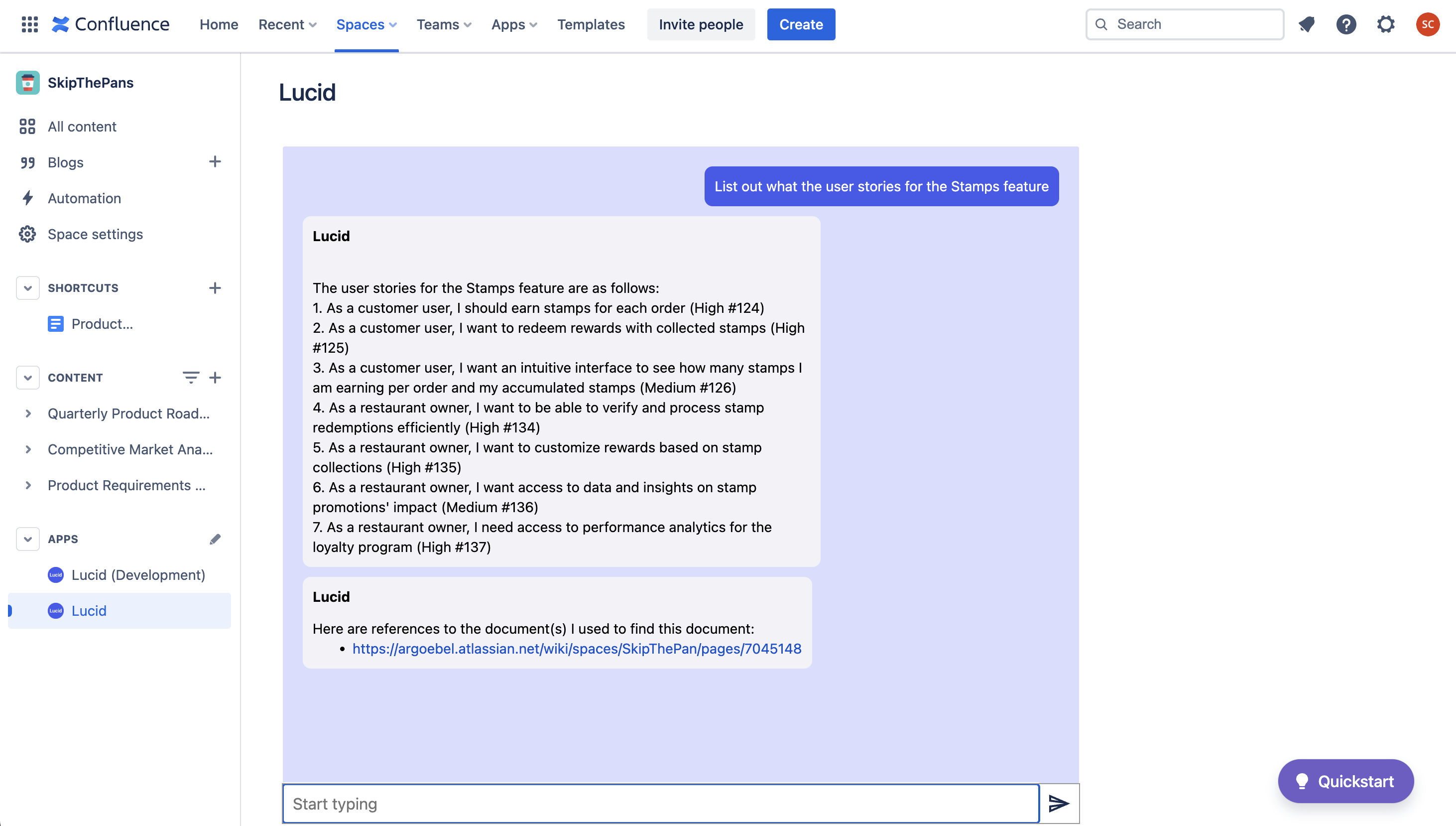
Demo
-
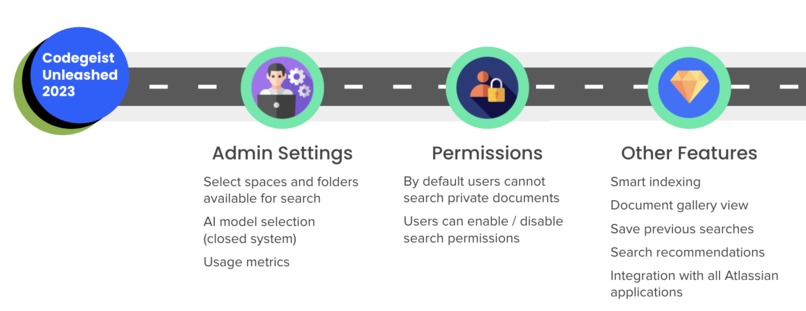
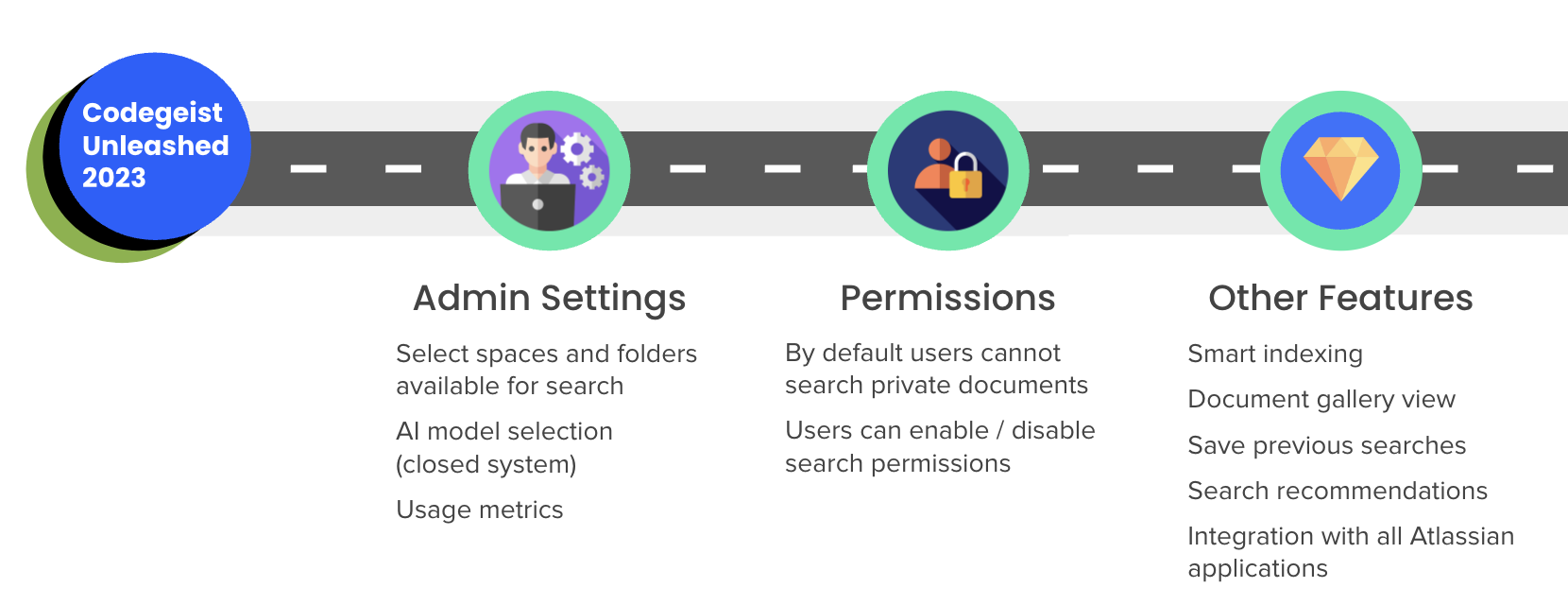
Roadmap
Inspiration
In our own journeys with Confluence, we've often grappled with the challenge of swiftly locating specific information—navigating through numerous pages and subpages, hoping to find what we seek. We weren't alone in this; various discussions and blogs echoed our sentiments. Recently, Retrieval Augmented Generation (RAG) paired with Large Language Models (LLMs) has emerged as a promising solution to search challenges. Inspired by this, we introduce 'Lucid': a tool designed to illuminate your Confluence experience by harnessing the power of RAG. We hope that with Lucid, users can unleash clarity in the confluence of ideas
What it does
Lucid is a Confluence Spaces App built using Forge. It appears as a chat interface where you can search for documents across your Confluence Spaces. Based on your question, Lucid first fetches relevant documents or data snippets from Confluence using a retrieval system. Then, it channels this retrieved information to a large language model, which crafts coherent and contextually-rich responses with cited hyperlinks to the original material. This creates a conversational search experience that can find your data within Confluence with high accuracy, and also summarize the results in meaningful and insightful ways. Lucid isn't just a chatbot with your Confluence, but a more effective way for searching for the information and documents you need.
How we built it
 Lucid is built using Atlassian Forge to connect to AWS services for the Retrieval Augmented Generation (RAG). Please refer to the system architecture diagram above.
Lucid is built using Atlassian Forge to connect to AWS services for the Retrieval Augmented Generation (RAG). Please refer to the system architecture diagram above.
RAG combines a Smart Retriever with a Large Language model to provide users with summarised search results that are accurate, cited, and free of hallucinations. Our architecture also allows a model agnostic system – meaning your confluence administrator can choose to use any model they want for their search. It can be OpenAI’s top of the line GPT4 or just an open source one to match their needs. As models evolve users will be able to easily upgrade to the latest service.
In this demo, we've harnessed a suite of AWS services, allowing us to leverage cutting-edge technology while keeping our focus razor-sharp on the user experience. By doing so, we've seamlessly integrated the latest AI advancements to enhance the Confluence user journey. The smart retriever used was AWS Kendra to generate the indices, an S3 bucket is used to store those indices, and a lambda function acts as the chief communicator between all the services while enabling serverless architecture. Finally we chose to use OpenAI APIs due to its strength and simplicity when connecting the API to AWS.
Why did we choose RAG?
 Recently, there has been a profusion of “chatbot for your database” proof of concepts, but they have encountered numerous barriers that hinder their product value and adoption. Our approach, designed with scalability in mind and utilizing RAG, effectively addresses and resolves many of the challenges discussed below.
Recently, there has been a profusion of “chatbot for your database” proof of concepts, but they have encountered numerous barriers that hinder their product value and adoption. Our approach, designed with scalability in mind and utilizing RAG, effectively addresses and resolves many of the challenges discussed below.
Problem 1 : Deeper insights from LLMs require fine tuning of new data
- The alternative for a fine-tuned LLMs is to send large amounts of context with the prompt. This is expensive and not scalable for large data sources, and limits the output that can be generated.
- RAG allows for more versatile data sources. We can easily take in and index different sources of data through free adapters provided by AWS such as the Jira connector mentioned in our future roadmap
- Incorporating new data sources only requires re-indexing - a simple and cost effective process.
- By utilizing AWS’ connectors, we can easily index the entire Confluence database at the click of a button and index as often as needed.
Problem 2: LLMs hallucinate easily and can’t provide references
- RAG restricts the LLM to only use information provided in the Confluence database. By exclusively relying on output from the search query, hallucinations can be almost eliminated.
- The model produces cited references to confirm where it got the information, giving the user more trust and enabling them to dig deeper into the referenced documents.
Problem 3: “Forgetting” data for privacy or copyright issues is resource intensive
- By building out an index with Kendra, it gives us the ability in our future roadmap, to easily allow for permission hierarchies to hide and restrict sensitive data to users without sufficient privileges.
- The LLM will never need to be re-trained again - only the data needs to be re-indexed which is exponentially faster.
Challenges we ran into
- Creating a robust set of test data for us to be able to test this application on. As Lucid thrives on big data sets manually and AI assisted creation of tet data was time consuming.
- Learning new commoditized services such as Amazon Kendra.
- Learning how to properly and safely spin up instances to minimise cost to build a feasible proof of concept but with scale in mind.
Accomplishments that we're proud of
- Building an end to end pipeline that uses Atlassian Forge that integrated API components is something we are quite proud of. There were lots of small learnings along the way that will enable us to build other applications using these tools in the future.
- Building something that can be scaled for enterprise wikis with thousands of documents and still have accurate results! We aren't just sending document content as a prompt, but generating a rich index of the Confluence space.
- Using market research and discovery interviews to build a product that solves a real user pain to improve collaboration.
What we learned
- How to utilize the wide array of Forge UI components to quickly build an intuitive frontend
- How to develop within the AWS environment and use services such as Lambda Functions to build secure serverless architecture
- How to connect Confluence to Kendra using Confluence Cloud API
- How to connect OpenAI and potentially any model to AWS.
- Advantages and limitations of RAG search
- Considerations and techniques to limit the cost of cloud services
What's next for Lucid (Roadmap)
 This product was built with scale in mind and beyond just a submission for a hackathon! As we plan to launch Lucid as a marketplace app in the coming months, the team is already working on some features to enhance the application. These include:
This product was built with scale in mind and beyond just a submission for a hackathon! As we plan to launch Lucid as a marketplace app in the coming months, the team is already working on some features to enhance the application. These include:
Permission settings
- By default, users cannot search private documents
- Users will be able to enable / disable search permissions when publishing new documents
Administrative settings
- To keep in line with data existing compliance standards, confluence administrators will have the ability to select which spaces and folders are available for search
- For flexibility and data safety, administrators can choose to select which LLM model they prefer for Lucid. We acknowledge the limitations of OpenAI due to private company data. This is why administrators will be able to choose models from open source models, proprietary models, and more!
- For visibility and monitoring purposes, administrators will have the ability to see key metrics on how Lucid is used across the site. How many queries are made? Which spaces leverage Lucid the most? Which documents are the most popular? Soon you will know!
Smart Indexing
- Soon administrators no longer have to worry about clicking re-index or selecting the ideal indexing times.
- With smart indexing, only updated or new documents will be indexed by the backend, saving time, money, and significantly improve the user experience.
Question Recommendations
- Based on several factors such as historical queries, previously viewed documents, related documents, and more, Lucid will be able to provide pertinent question recommendations.
UI Improvements
- To improve navigation across referenced documents within Lucid, users will have the ability to preview documents on a document gallery view. This will replace the links Lucid provides as references
- You won’t have to do that same query again! Users will be able to see previous queries with lucid as well as the referenced documents at any time.
Added Integrations
- Lucid will soon be available on all Atlassian apps starting with Jira!
Built With
- amazon-ec2
- amazon-web-services
- docker
- fastapi
- forge
- kendra
- openai
- python
- react
- s3
- typescript




Log in or sign up for Devpost to join the conversation.