-
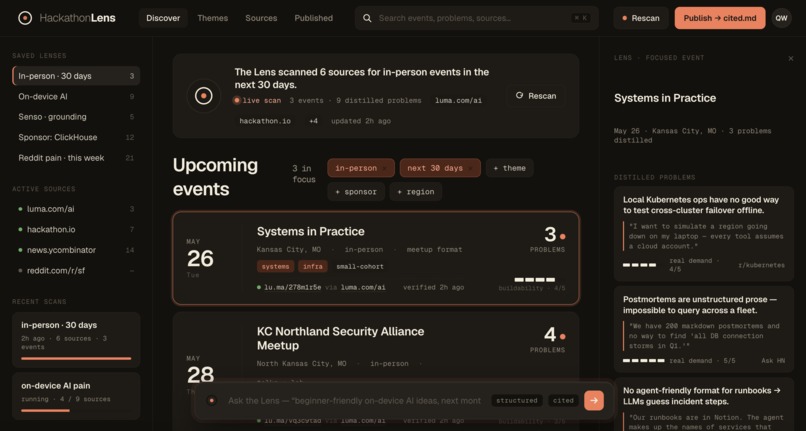
Dashboard
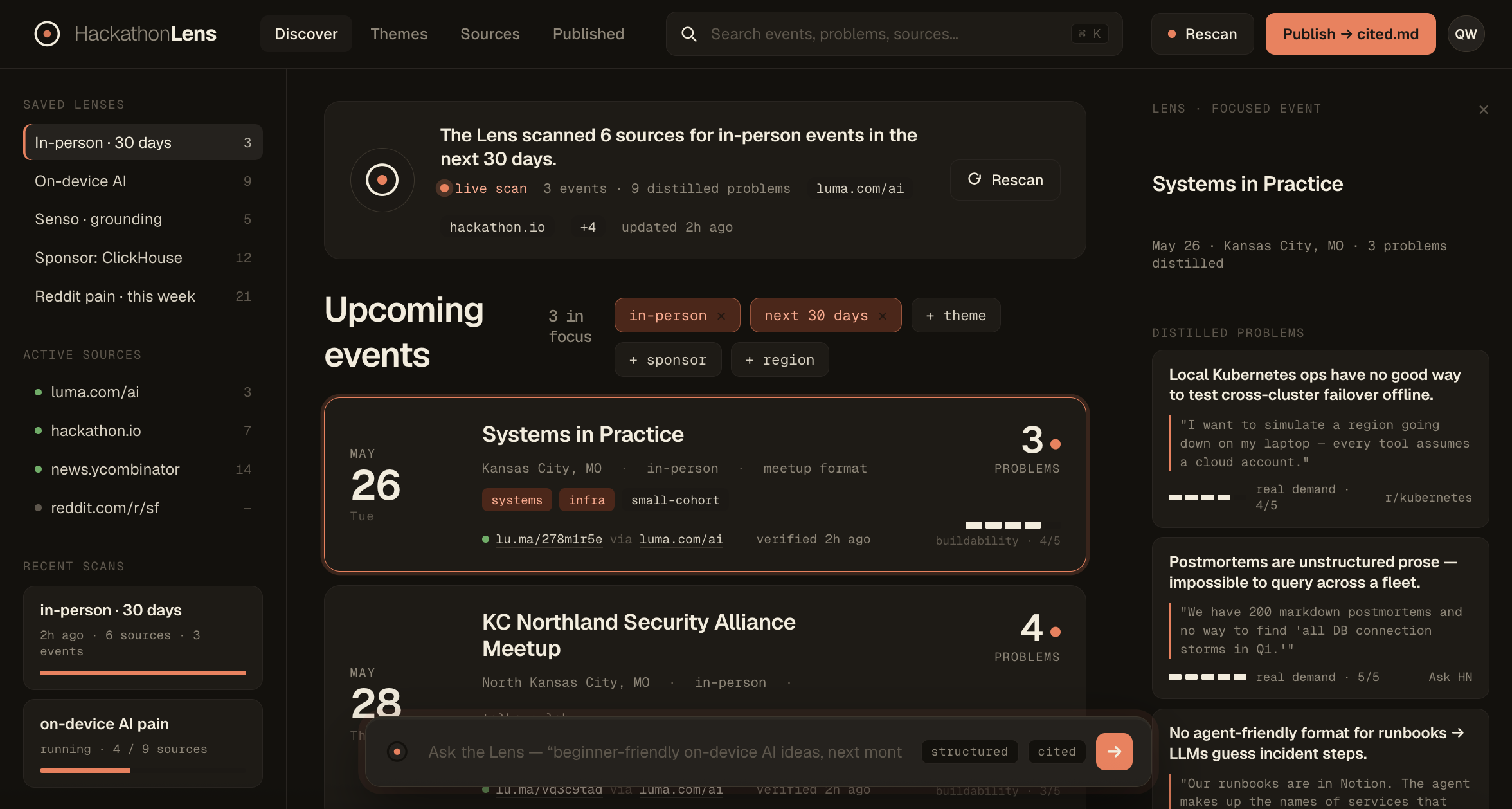
Inspiration
It started on a napkin. Every hackathon begins the same way: you spend the first hours just figuring out what to build — and before that, you spent days hunting for the hackathon itself across a dozen scattered sources. Cerebral Valley, MLH, Devpost, random posts that scroll away by the time you see them. There's no single place that answers "what's coming up, who's hosting, and what are the prizes."
And even once you're in the room, the blank page is brutal. The best ideas are real problems people actually have — but those are buried in Reddit threads and Hacker News "I wish there was an app for…" posts. We wanted one tool that closes both gaps: find the hackathons, then find the right thing to build — grounded in real, sourced problems, not ideas pulled out of thin air.
What it does
Hackathon Lens is an agent that:
- Finds hackathons across the web and pulls out what matters — name, date, location, hosts, prizes, description — into one searchable place.
- Answers the questions builders actually ask — "what's coming up near me," "who's hosted recently," "where are the biggest prizes."
- Tells you what to build — it mines the web for genuine developer pain, distills it into scored, weekend-buildable ideas with the evidence and source attached, and grounds each one in a verified knowledge base.
- Publishes those ideas as grounded, citeable pages so any AI agent — ChatGPT, Perplexity, Claude — can discover and cite them. Being mentioned on the web isn't the same as being citeable; we turn scattered, throwaway complaints into durable, sourced signal.
How we built it
A multi-stage pipeline, with each tool doing one job well:
- Nimble is the intake layer — agentic web search that scrapes hackathon listings and developer pain points from Reddit, Hacker News, and sponsor pages.
- An LLM distillation agent (Claude) reads the raw, messy content and extracts only genuine, buildable problems — rejecting vague aspirations and feature requests — then scores each on real demand, buildability, and originality.
- ClickHouse stores the structured records, so temporal and structured queries ("upcoming, by prize, recent") are fast and exact.
- Senso is the grounding and publishing layer — we ingest each problem as a verified knowledge-base entry, use Senso's content-generation APIs to produce structured, cited idea pages, and publish them to an agent-discoverable domain.
Built in TypeScript/Node, with all of it orchestrated to run from a single command.
Challenges we ran into
- Avoiding redundant layers. Early on, Nimble, ClickHouse, and Senso all looked like they wanted to be "where the agent gets answers." The breakthrough was realizing they're complementary: Nimble gets data in, ClickHouse handles structured/temporal queries (which vector search does poorly), and Senso handles semantic grounding and publishing. Once we split the work cleanly, the whole architecture clicked.
- Searching for problems that don't exist as a dataset. "Hackathon problems" isn't a thing you can query — searching for it returns useless listicles. We had to target where pain actually lives (Ask HN, "I wish there was an app" threads, sponsor challenge pages) and let the agent do the judging.
- Getting the distill agent strict enough. Our first version surfaced generic junk. Tightening the prompt to demand evidence and reject anything not weekend-buildable was what turned raw scraping into something genuinely usable.
- Undocumented edges. A few API specifics weren't in the docs, so we verified by reading carefully and asking sponsors directly rather than guessing — especially around the publishing step.
Accomplishments that we're proud of
- A scrape → distill pipeline that produces genuinely good, evidenced problems — every idea traces back to a real person's real complaint, with the source attached.
- Closing the loop from raw web noise all the way to published, citeable content an AI agent can find and cite — not just ingesting data, but publishing signal.
- A clean separation of concerns across four tools, where each one has an obvious job and the architecture is easy to explain in a sentence.
What we learned
- Mentioned ≠ citeable. The most-talked-about things online are rarely cited as sources by AI engines. Structured, grounded, sourced content gets cited far more often. That insight reshaped our whole output strategy.
- Match the query to the engine. SQL for structured/temporal questions, vector search for semantic ones — forcing everything through one of them gives worse results. Knowing which to use where is half the design.
- Grounding beats generating. An idea generator that invents from nothing is a dime a dozen. One that can prove every suggestion came from a real, evidenced problem is defensible and trustworthy.
- Read the docs, then ask the humans. When the win condition hinges on one detail, confirming it directly beats assuming.
What's next for Hackathon Lens
- More sources and live freshness — broaden discovery beyond the current set and keep events auto-updating as they're announced and expire.
- Personalized recommendations — match hackathons and ideas to a builder's actual skills and past projects.
- A richer published directory — a growing, citeable library of buildable problems per theme, kept in sync as new pain surfaces.
- Team matching — connect builders who want to tackle the same problem.
- Closing the agentic loop — let other agents query and build on our published context directly, the way the agentic web is heading.

Log in or sign up for Devpost to join the conversation.