-
-
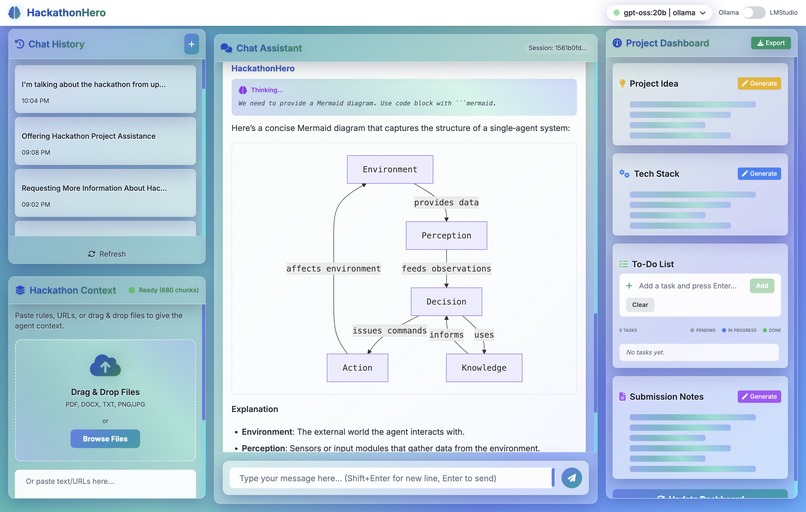
Markdown Diagram
-
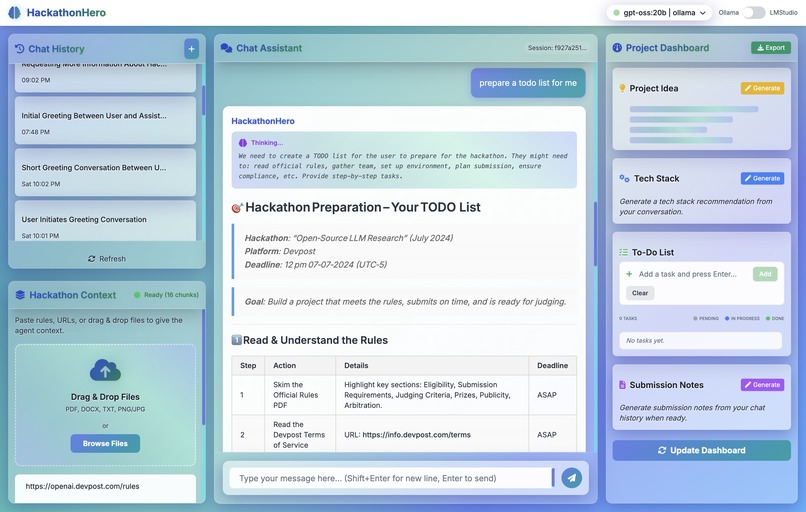
RAG
-
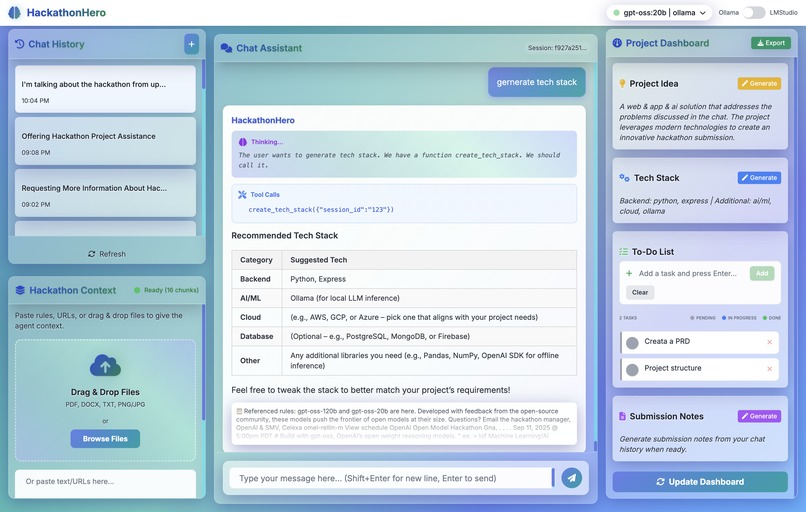
Tools
-
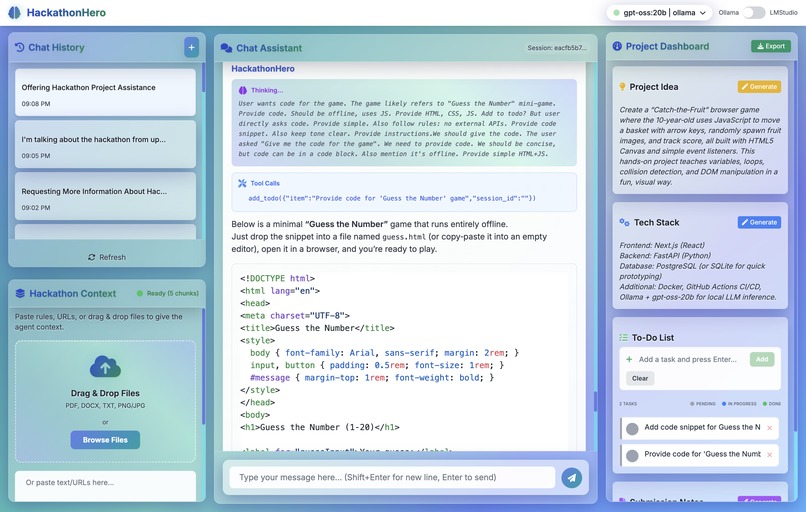
Stream Chat
Inspiration
As hackathon participants ourselves, we've experienced firsthand the frustration of spending precious hours organizing scattered ideas, tracking progress, and assembling submission materials instead of focusing on building. I noticed teams often lose momentum during the ideation phase or struggle to create polished artifacts under tight deadlines. The reliance on online AI tools introduces latency, privacy concerns, and potential downtime during critical moments.
Our vision was to create an offline-first AI companion that could transform raw brainstorming sessions into structured, submission-ready packages without any external dependencies. I wanted to democratize access to AI-powered assistance, especially for teams in low-bandwidth environments or privacy-sensitive settings where data cannot leave the device.
What it does
HackathonHero is a fully offline AI agent that serves as your team's intelligent assistant throughout the entire hackathon journey:
- 🚀 One-Click Setup: Complete automated installation and launch across all platforms (macOS, Linux, Windows)
- 💬 Intelligent Chat Interface: Stream conversations with local LLM models (gpt-oss) with transparent tool calling
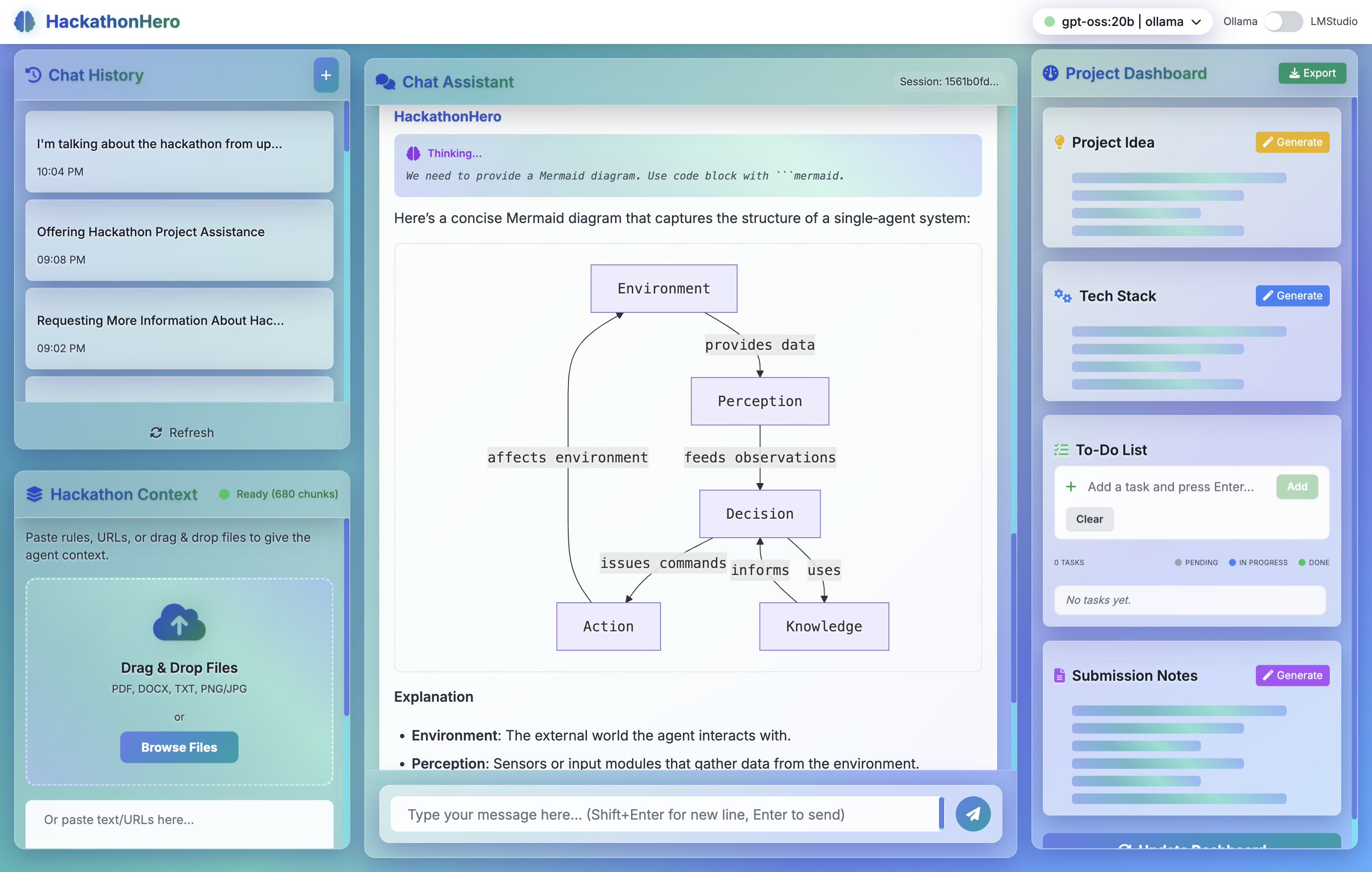
- 📚 Rules-Aware RAG System: Upload hackathon rules and context files for intelligent, context-aware responses
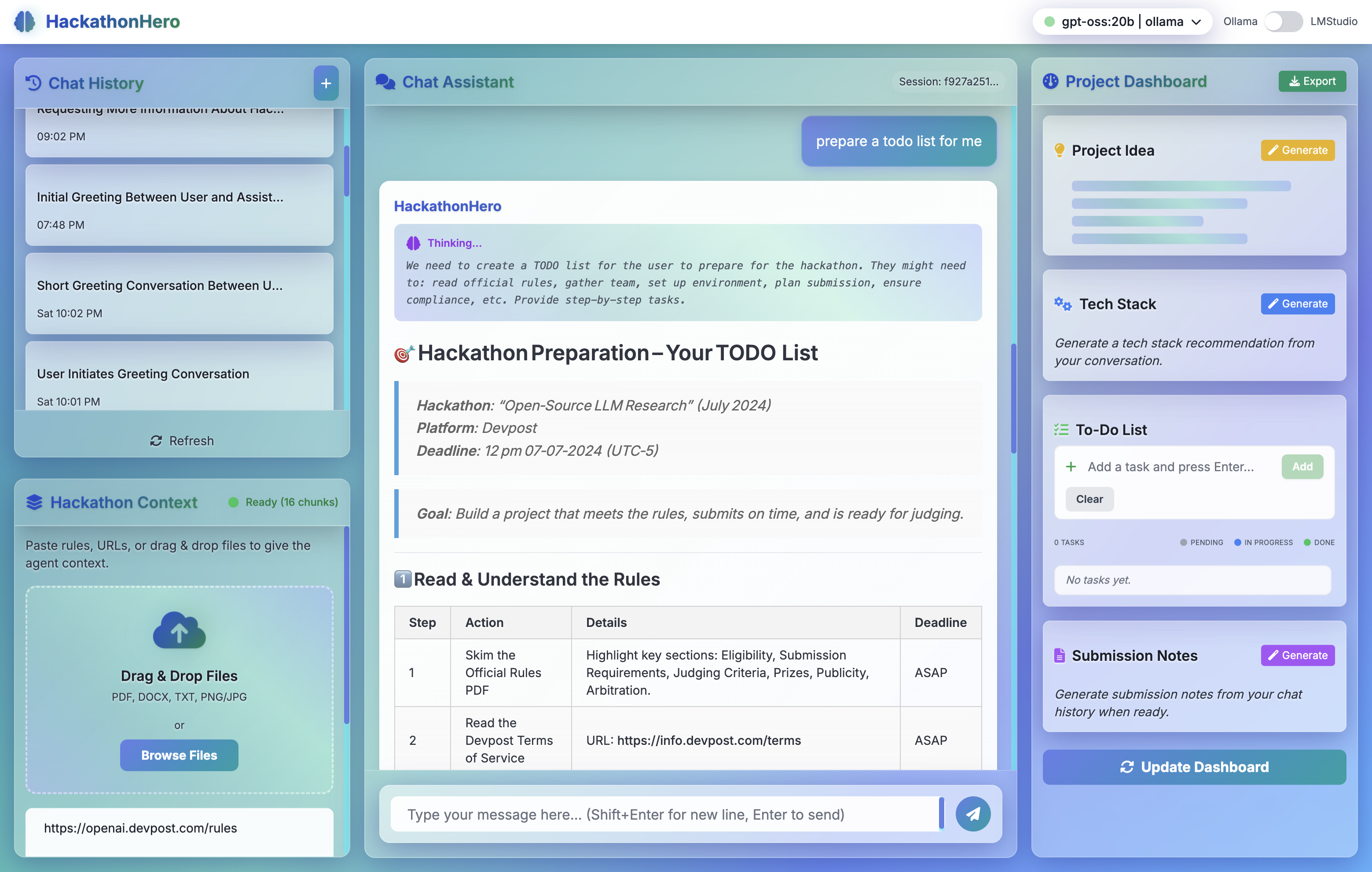
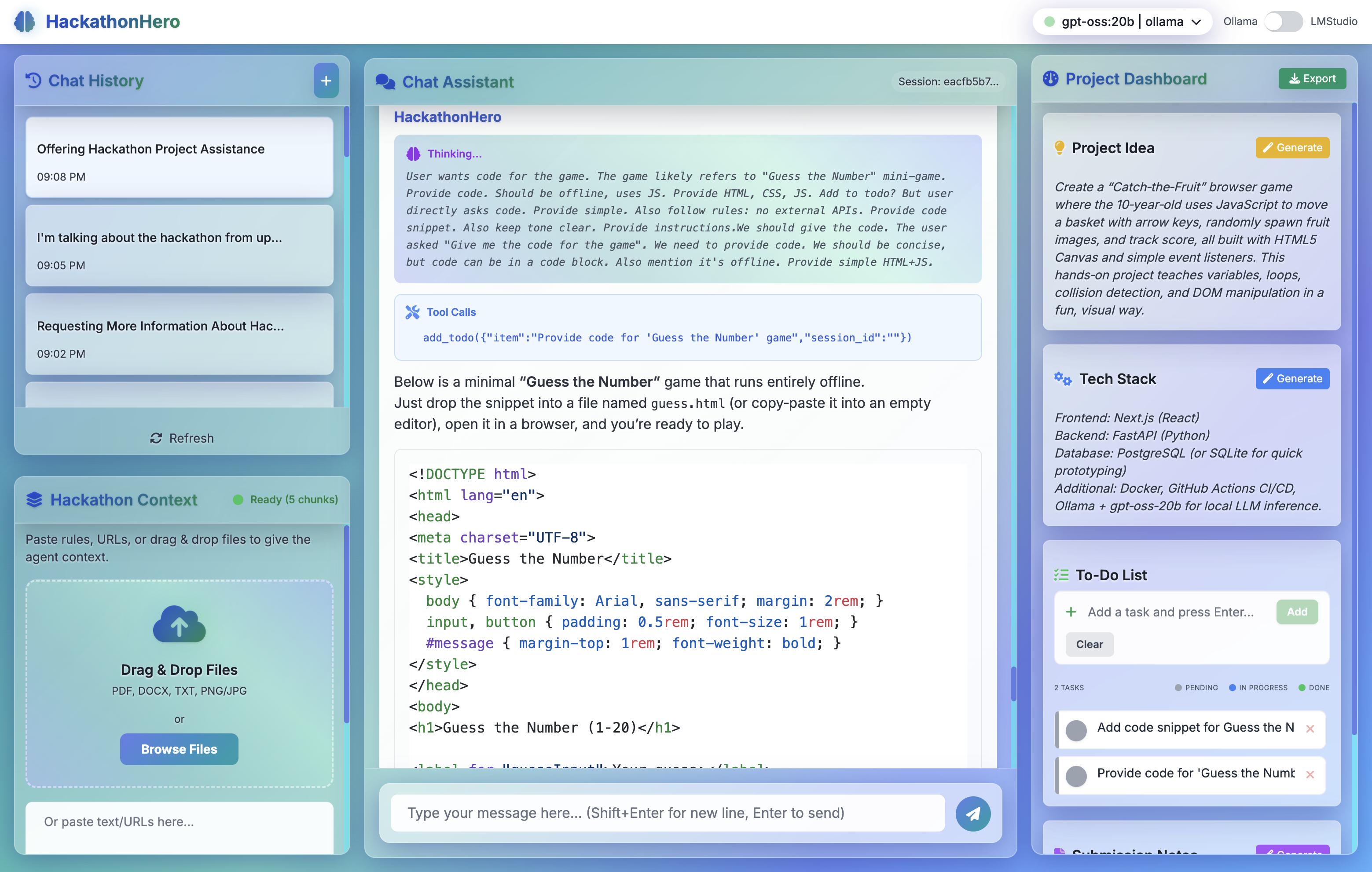
- ✅ Smart Todo Management: AI automatically suggests and manages tasks based on your conversations
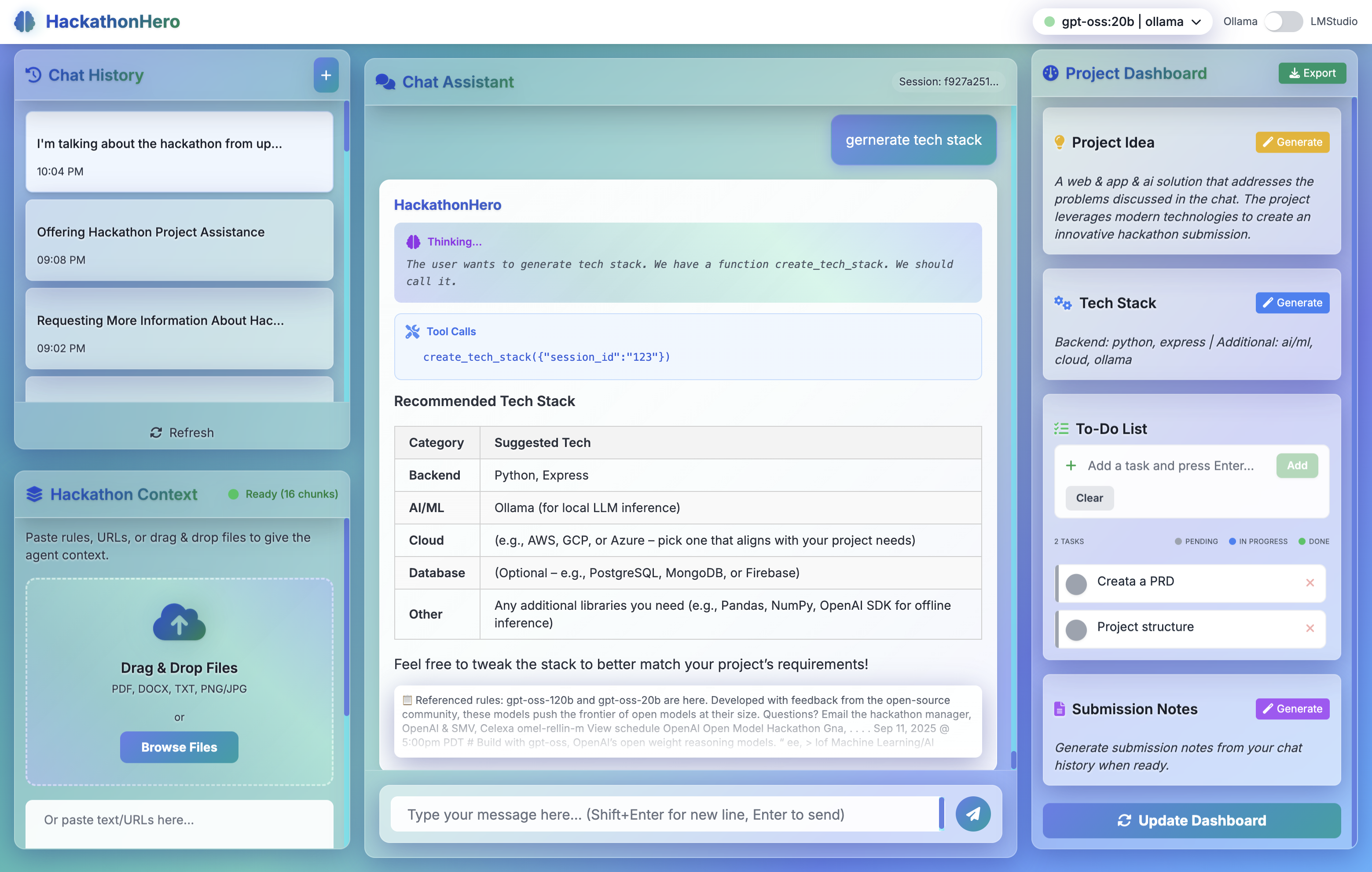
- 🎯 Automated Artifact Generation: Transform chat history into polished project ideas, tech stack recommendations, and submission summaries
- 📎 Multi-Format Ingestion: Process text files, PDFs, images (with OCR), and URLs to build comprehensive context
- 📦 Complete Export System: Generate submission-ready ZIP packages with all required materials
- 📴 100% Offline Operation: Works entirely without internet after initial model download
The system uses a modern React frontend with FastAPI backend, integrating seamlessly with Ollama for local LLM inference and FAISS for efficient vector search.
How I built it
Architecture & Tech Stack:
- Frontend: React + Vite + Tailwind CSS with PWA capabilities for offline use
- Backend: FastAPI with async/await patterns for high performance
- AI Runtime: Ollama integration with OpenAI-compatible API for local inference
- Vector Database: FAISS with SentenceTransformers (MiniLM) for efficient embeddings
- Persistence: SQLite with automated migrations for reliable data storage
- Streaming: Server-Sent Events (SSE) for real-time chat and tool call transparency
Key Technical Innovations:
- Offline-First RAG Pipeline: Custom chunking and embedding system that works entirely locally
- Tool Calling Framework: Modular system allowing the AI to invoke structured functions (todos, artifacts, file operations)
- Session-Scoped Context: Intelligent context management that maintains conversation history while optimizing for relevance
- Streaming Transparency: Real-time visibility into AI reasoning and tool execution via SSE
- Idempotent Setup Scripts: Platform-specific automation that handles dependencies, services, and model downloads
Development Process:
- Started with core offline LLM integration using Ollama
- Built modular tool system for extensible AI capabilities
- Implemented RAG pipeline with caching for performance
- Created responsive React UI with real-time streaming
- Developed comprehensive testing suite with 14+ test modules
- Automated deployment with one-liner setup scripts
Challenges I ran into
Technical Challenges:
- Streaming Complexity: Implementing robust SSE streaming with proper error handling and message ordering
- Local Model Performance: Optimizing inference speed while maintaining quality on consumer hardware
- RAG Efficiency: Balancing embedding quality with startup time for large rule files
- Cross-Platform Setup: Creating idempotent installation scripts that work reliably across macOS, Linux, and Windows
- Tool Call Parsing: Implementing reliable extraction of function calls from streaming LLM responses
Design Challenges:
- Context Management: Determining optimal chunking strategies for different file types
- UI Responsiveness: Maintaining smooth user experience during heavy AI processing
- Offline UX: Designing intuitive interfaces that work without external dependencies
Solutions Implemented:
- Custom SSE event ordering and buffering system
- Intelligent embedding caching with hash-based invalidation
- Fallback mechanisms for artifact generation when LLM responses are unparseable
- Comprehensive error handling with graceful degradation
- Modular tool architecture enabling easy extension and testing
Accomplishments that I'm proud of
🎯 Complete Offline Capability: Successfully implemented a fully functional AI agent that requires zero internet connectivity after setup
⚡ One-Liner Installation: Created automated setup scripts that go from zero to running application in minutes across all major platforms
🔧 Robust Tool System: Built a extensible framework where AI can reliably invoke structured functions with proper error handling
📊 Production-Ready Architecture: Implemented comprehensive database migrations, testing suite, and error handling
🎨 Intuitive User Experience: Designed a clean, responsive interface that makes AI interaction natural and transparent
📈 Performance Optimization: Achieved efficient local inference with smart caching and context management
🛡️ Security & Privacy: Ensured complete data privacy with no external API calls and proper input validation
💪 Comprehensive Testing: Built extensive test coverage with 14+ test modules covering all major functionality
📦 End-to-End Workflow: Successfully automated the entire journey from brainstorming to submission-ready artifacts
What I learned
Technical Insights:
- Local AI Viability: Modern consumer hardware can effectively run capable language models for real-world applications
- RAG System Design: The importance of chunking strategies, embedding model selection, and caching for responsive local search
- Streaming Architecture: SSE provides excellent user experience for AI interactions when properly implemented with ordering and error handling
- Tool Calling Complexity: Reliable function extraction from LLM outputs requires robust parsing with multiple fallback strategies
Product Development:
- Offline-First Benefits: Users highly value privacy and reliability that comes with local-only operation
- Setup Experience: First-run experience is critical - automated setup significantly reduces adoption friction
- Transparency Matters: Showing AI reasoning and tool execution builds user trust and understanding
- Context is King: Quality of AI responses heavily depends on intelligent context management and retrieval
Project Management:
- Iterative Testing: Continuous testing across platforms prevented integration issues
- Modular Architecture: Well-defined interfaces between components enabled parallel development
- Documentation: Comprehensive documentation and examples are essential for complex systems
What's next for HackathonHero
Immediate Roadmap (P0):
- 🎨 Rule Chunk Highlighting: Visual indicators showing which rules influenced AI responses
- 📊 Enhanced Artifact Management: Advanced editing and versioning for generated artifacts
- 📈 Model Benchmarking: Automated performance testing across different hardware configurations
- 🧠 Rolling Summarization: Memory-efficient handling of long conversations
- 🔧 Inline Tool Results: Direct visualization of tool execution results in the chat interface
Advanced Features (P1):
- 🤖 Autonomous Planning: Multi-step reasoning loops that break down complex goals automatically
- 💻 Code Scaffolding: Safe, scoped code generation with diff preview and validation
- 🎯 Domain Adaptation: Specialized prompts and tools for different hackathon categories (AI/ML, Web3, IoT)
- 📱 Mobile Optimization: Progressive Web App enhancements for tablet and mobile use
- 🔍 Advanced Search: Semantic search across chat history and artifacts
Platform Expansion (P2):
- 🌐 Multi-Model Support: Integration with additional local LLM providers (LM Studio, llama.cpp)
- 🎨 Theme System: Customizable UI themes and accessibility improvements
- 📊 Analytics Dashboard: Local usage insights and productivity metrics
- 🔗 Integration APIs: Webhook support for external tool integration
- 🏗️ Plugin Architecture: Community-contributed tools and extensions
Research & Innovation (P3):
- 🧪 Fine-Tuned Models: Domain-specific model adaptations for hackathon mentorship
- 📚 Knowledge Graphs: Advanced relationship modeling between concepts and artifacts
- 🎭 Multi-Agent Systems: Specialized AI personas for different roles (strategist, architect, presenter)
- 🔮 Predictive Features: AI-powered timeline estimation and risk assessment

Log in or sign up for Devpost to join the conversation.