Inspiration
Heart disease remains one of the leading causes of preventable death, and a lot of the signals are already present in routine measurements (vitals, basic lab values, and ECG-related indicators). We wanted to build something that makes risk screening feel instant and accessible – something you can demo in seconds but also scale to batch screening.
What it does
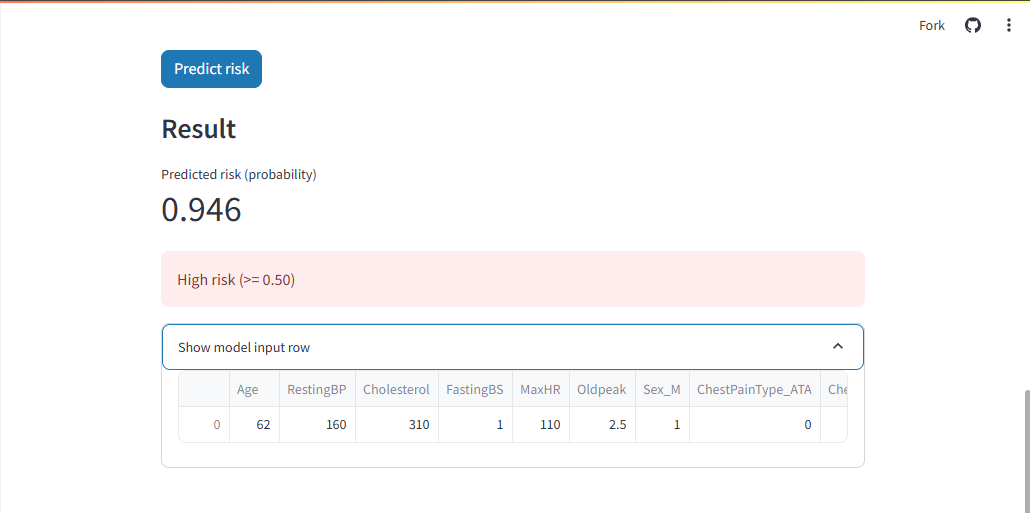
Heart Attack Risk Prediction App (HARPA) predicts the probability of heart disease from routine clinical + ECG-derived features.
- Single-patient mode: enter patient values in a clean web form and get a risk probability + a configurable decision threshold.
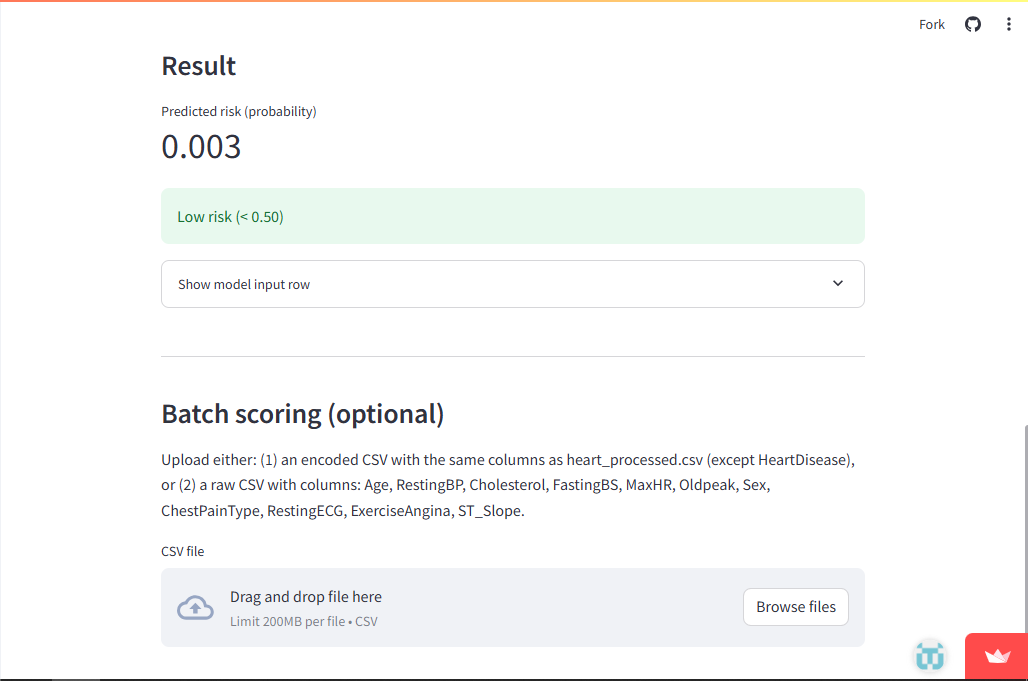
- Batch mode: upload a CSV to score many rows at once and download a scored file.
How we built it
- Started with a processed tabular dataset that I downloaded into my local (heart_processed.csv) and explored feature quality and class balance.
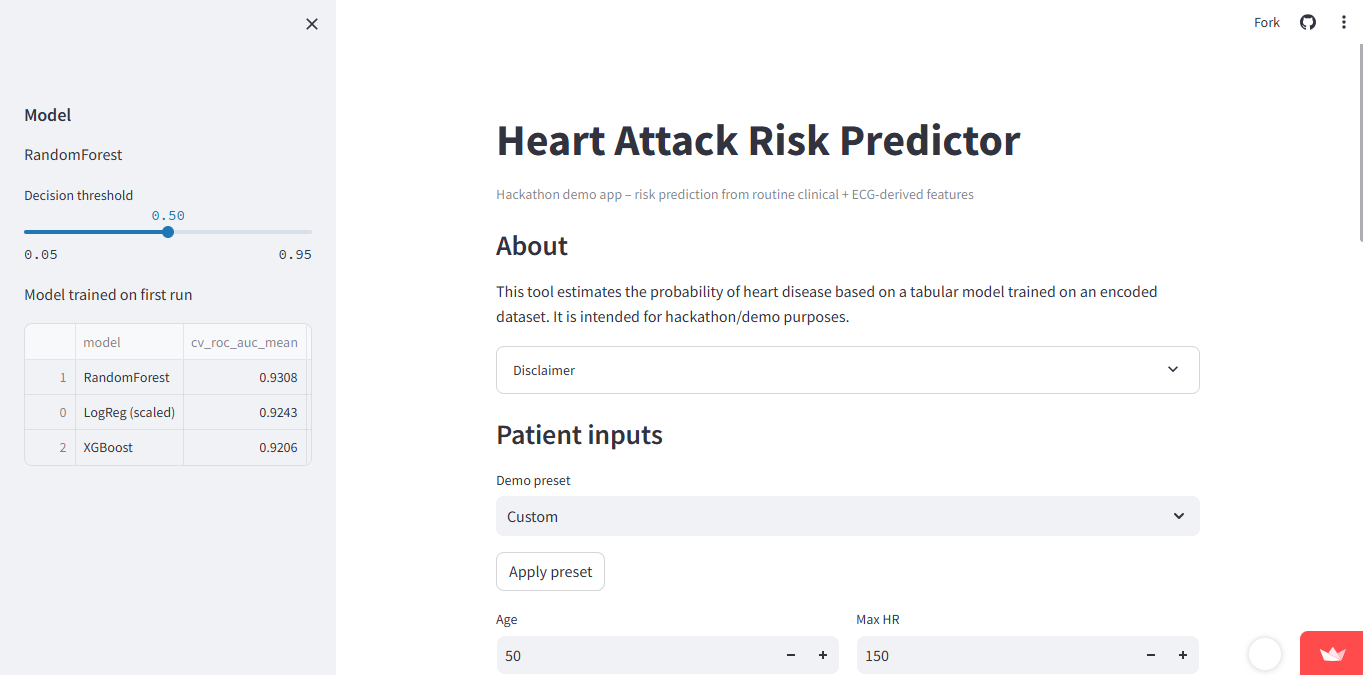
- Trained and compared multiple ML models (Logistic Regression, Random Forest, XGBoost) using stratified cross-validation and standard metrics (ROC-AUC / PR-AUC / F1).
- Picked the best-performing model and wrapped it in a Streamlit web app.
- Made deployment easy by enabling auto-training on first run (so the app can work even if the serialized model artifact isn’t committed).
Challenges we ran into
- Making sure the web app input schema exactly matches the encoded training features (one-hot columns and boolean flags).
- Balancing hackathon speed with “realistic” product needs: calibration/thresholding, clear messaging, and safe disclaimers.
- Deployment constraints: keeping the repo lightweight and ensuring the dataset path works in cloud hosting.
Accomplishments that we're proud of
- A working end-to-end product: data → model selection → deployed web app.
- A demo-friendly UX with presets that tell a story (low-risk vs high-risk examples).
- Batch scoring with downloadable results, which makes it useful beyond a single demo input.
What we learned
- Cross-validation + multiple metrics give a much more reliable picture than a single train/test score.
- Turning an ML notebook into a deployable product mostly comes down to reproducibility: consistent feature encoding, stable paths, and a predictable runtime environment.
- For risk prediction, probabilities + threshold controls are more useful than a hard yes/no output.
What's next for Heart Attack Risk Prediction App (HARPA)
- Add stronger interpretability (global + per-prediction explanations).
- Add better input validation and medical-friendly ranges/units.
- Improve probability calibration and support clinical-style risk bands (low / medium / high).
- Expand to more datasets and add monitoring for bias and drift.
Built With
- github
- numpy
- pandas
- python
- scikit-learn
- streamlit
- xgboost



Log in or sign up for Devpost to join the conversation.