-
-
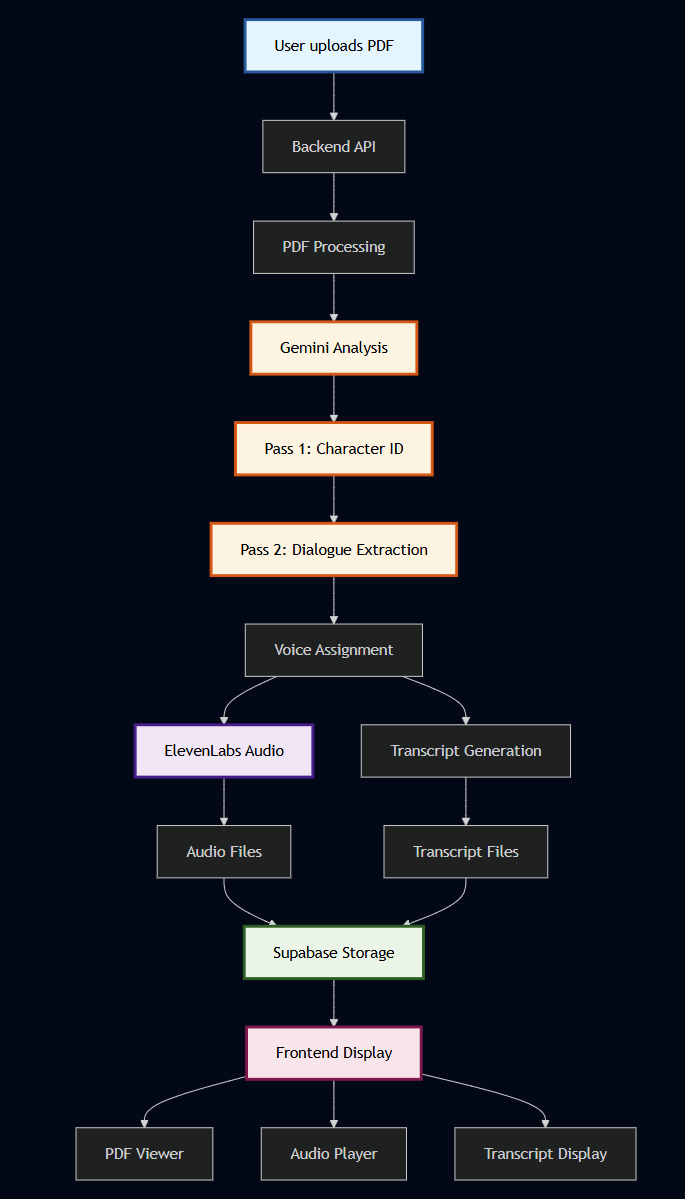
Manga Audio Pipeline
-
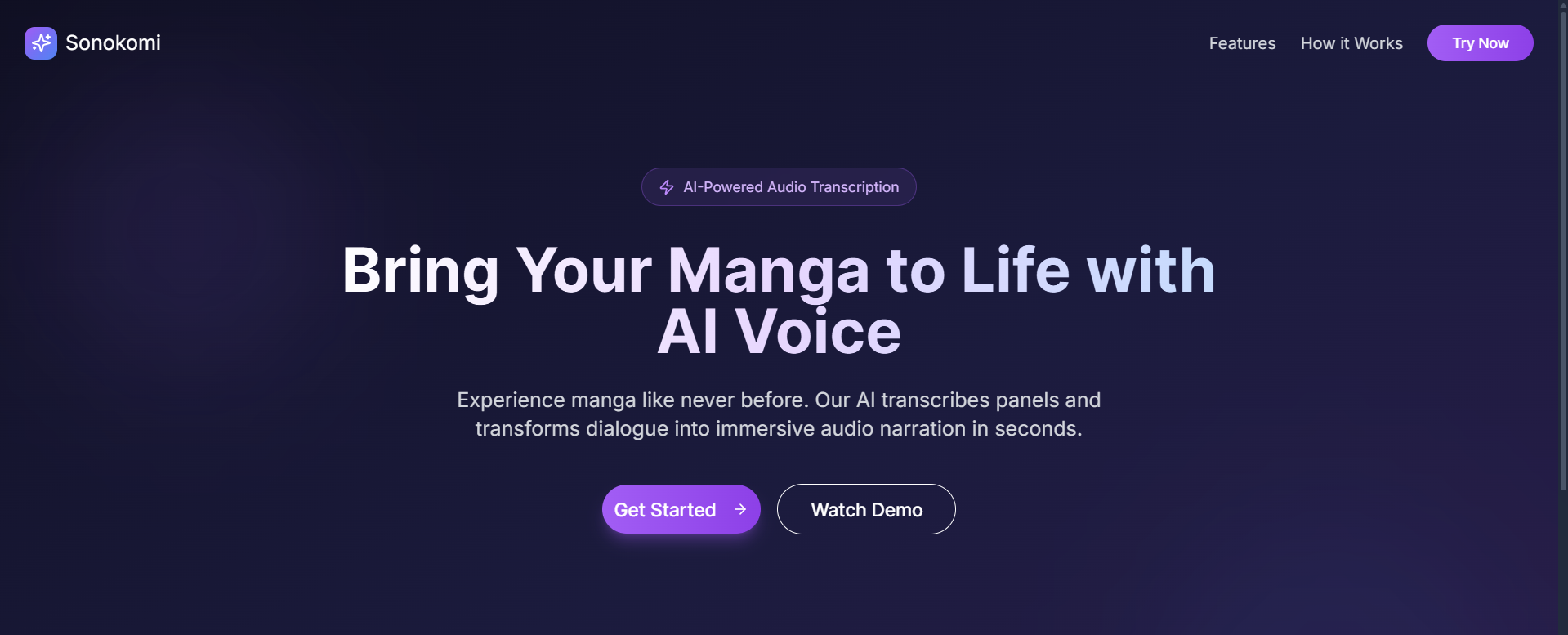
Landing Page
-

Landing Page (Continued)
-
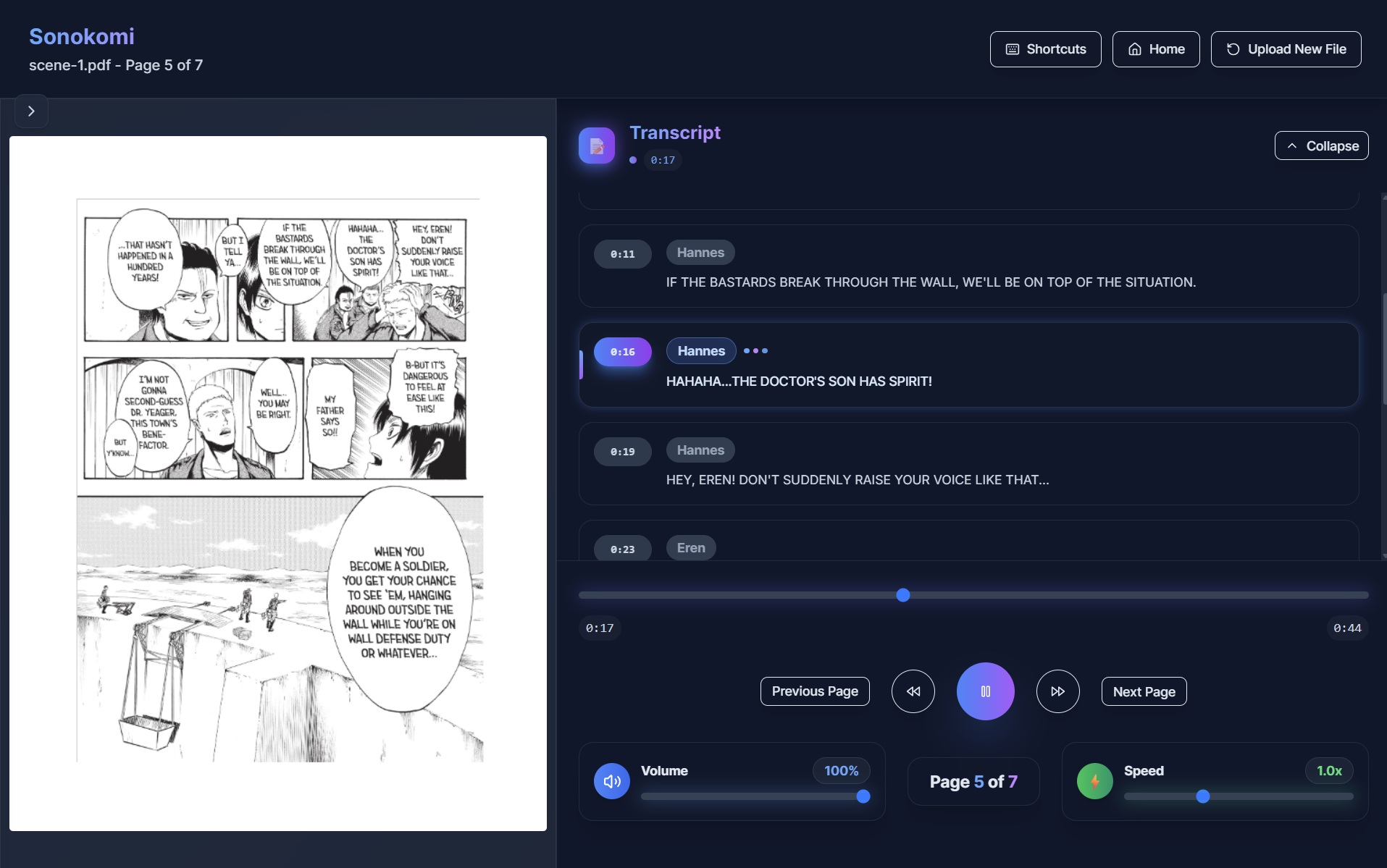
Narration Player
-
Keyboard Shortcuts Menu

Inspiration
Manga and comics are built on panel flow, visual cues, and emotion. These are elements that traditional screen readers miss, leaving visually impaired readers locked out of the story. We set out to translate that visual grammar into sound: detecting panels, speakers, and tone, then rendering them as expressive, scene-aware audio. The result preserves narrative pacing, character voices, and atmosphere, an experience that feels like “hearing” the page turn. As lifelong manga fans, we’re building this so everyone can enjoy the medium at its fullest.
What it does
Our project's name, Sonokomi, is a blend of the Japanese words for sound (sono) and comic (komi), perfectly capturing our mission. Sonokomi bridges the gap between visually impaired readers and the world of manga. It uses AI to interpret panels in order, dialogue, and emotions, transforming each page into a vivid audio experience with expressive narration and distinct character voices. The tool preserves pacing, tone, and atmosphere, letting blind and low-vision users hear the story unfold as if they were reading it themselves.
How we built it
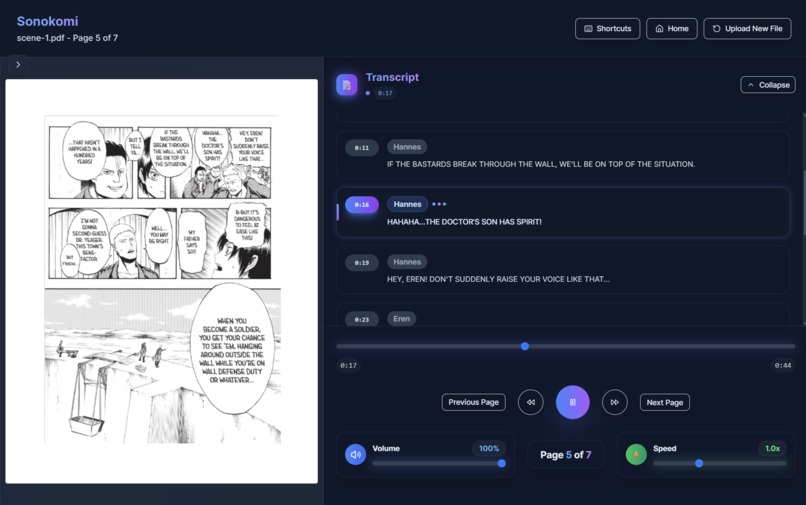
Frontend: Next.js 15 with React 18, TypeScript, and Tailwind CSS. Used Radix UI components for accessibility and custom audio player with Web Audio API integration.
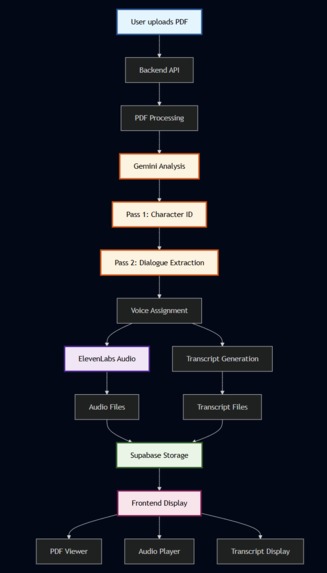
Backend: FastAPI with Python featuring a two-pass AI processing pipeline:
- Pass 1: Gemini 2.0 Flash Lite analyzes all pages simultaneously to identify consistent characters across the entire scene, building a comprehensive character map for voice consistency.
- Pass 2: Gemini 2.5 Pro processes individual pages with character context for accurate dialogue extraction, ensuring precise speaker attribution and emotional nuance.
- Audio Enhancement: Gemini 2.0 Flash Lite adds ElevenLabs' v3 audio tags to every dialogue line, analyzing emotional context and delivery styles for professional voice acting quality.
ElevenLabs Integration:
- Character voice assignment with persistent voice IDs across pages and scenes
- Multi-speaker dialogue generation using ElevenLabs v3 Text-to-Dialogue API
- Applies appropriate voice settings for whispered dialogue, excited speech, dramatic pauses, and character-specific emotional delivery
- Real-time transcript generation with precise timestamps for each dialogue line
- Outputs both individual page audio files and combined scene audio for seamless playback
Challenges we ran into
Processing manga scenes proved complex due to inconsistent character appearances, overlapping speech bubbles, and unconventional right-to-left layouts. Single-page processing broke character consistency, while full-scene analysis lost dialogue order, pushing us to design a two-pass system for global context and local precision. Getting Gemini to correctly assign dialogue bubbles to specific characters also required fine-tuning prompts and using Gemini Pro for improved visual grounding and attribution accuracy.
Accomplishments that we're proud of
- Mastered Gemini 2.5 Pro's Maximum Potential: Leveraged Gemini 2.5 Pro to its full capabilities while understanding and working around its limitations in manga settings, particularly with complex visual layouts and character attribution challenges.
- Immersive Emotional Dialogue Generation: Successfully integrated ElevenLabs to create deeply immersive, emotionally-rich dialogue that captures the nuanced tone and atmosphere of manga scenes with professional voice acting quality.
- Solved Complex Design Problems with Two-Pass Architecture: Designed an innovative two-pass system that overcomes the fundamental challenge of maintaining character consistency while preserving dialogue accuracy - a problem that single-pass approaches cannot solve.
- Accessibility Innovation: Built the first tool that makes manga accessible to visually impaired users through high-quality audio narration with character differentiation, breaking barriers in entertainment accessibility.
What we learned
- Web Audio API complexity and browser audio handling challenges
- Computer vision limitations with complex visual layouts
- Accessibility-first design creates better experiences for all users
- Audio-visual integration importance for complex content consumption
What's next for Sonokomi
Immediate: Enhance Gemini’s precision for dialogue attribution, refine the two-pass processing pipeline for faster scene analysis, and improve real-time synchronization between text, voice, and panel transitions. Add progress tracking and richer accessibility feedback for screen readers.
Advanced: Assign voice IDs dynamically based on character age, tone, and emotion using a wider range of ElevenLabs voice variations. Incorporate ambient sound understanding to recreate environmental layers like rain, wind, and cityscapes for immersive storytelling. Introduce voice-controlled navigation so users can switch panels, replay lines, and explore scenes entirely hands-free.
Long-term: Support multi-language narration to reach a global audience, enable batch processing for entire manga volumes, and build community sharing for accessible story collections. Eventually, open an API marketplace allowing developers and publishers to integrate Sonokomi’s AI narration engine into other visual storytelling platforms.
Built With
- css
- elevenlabs-api
- fastapi
- git
- google-gemini-ai
- json
- mp3-audio-processing
- next.js
- postgresql
- python
- react
- supabase
- typescript







Log in or sign up for Devpost to join the conversation.