-
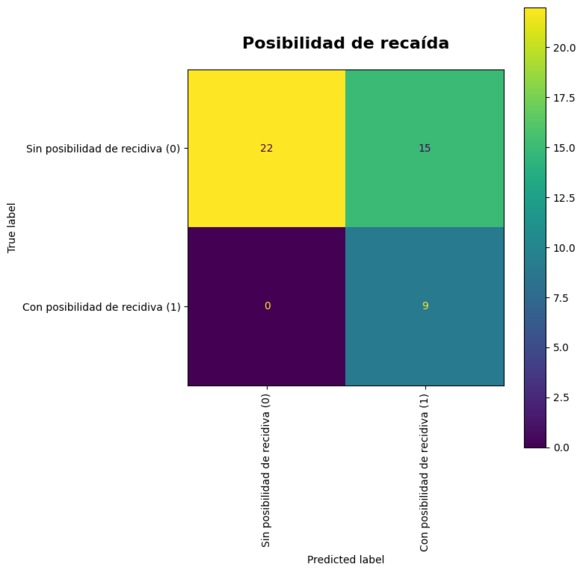
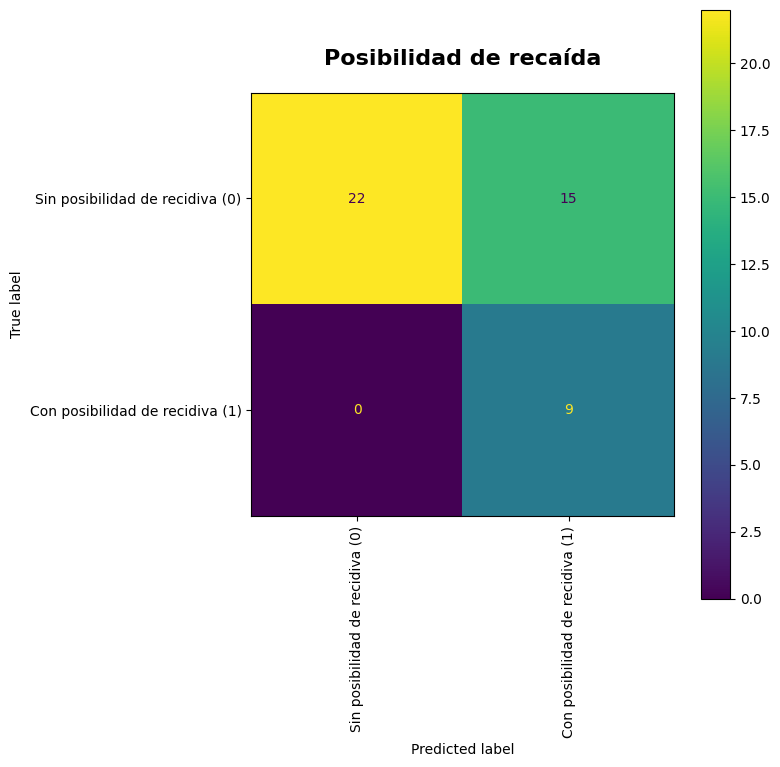
Resultados obtenidos con nuestro modelo
-
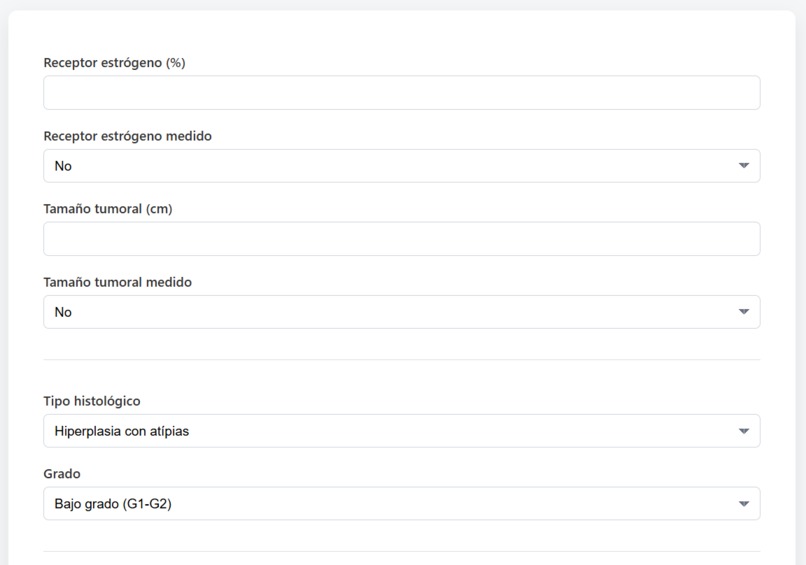
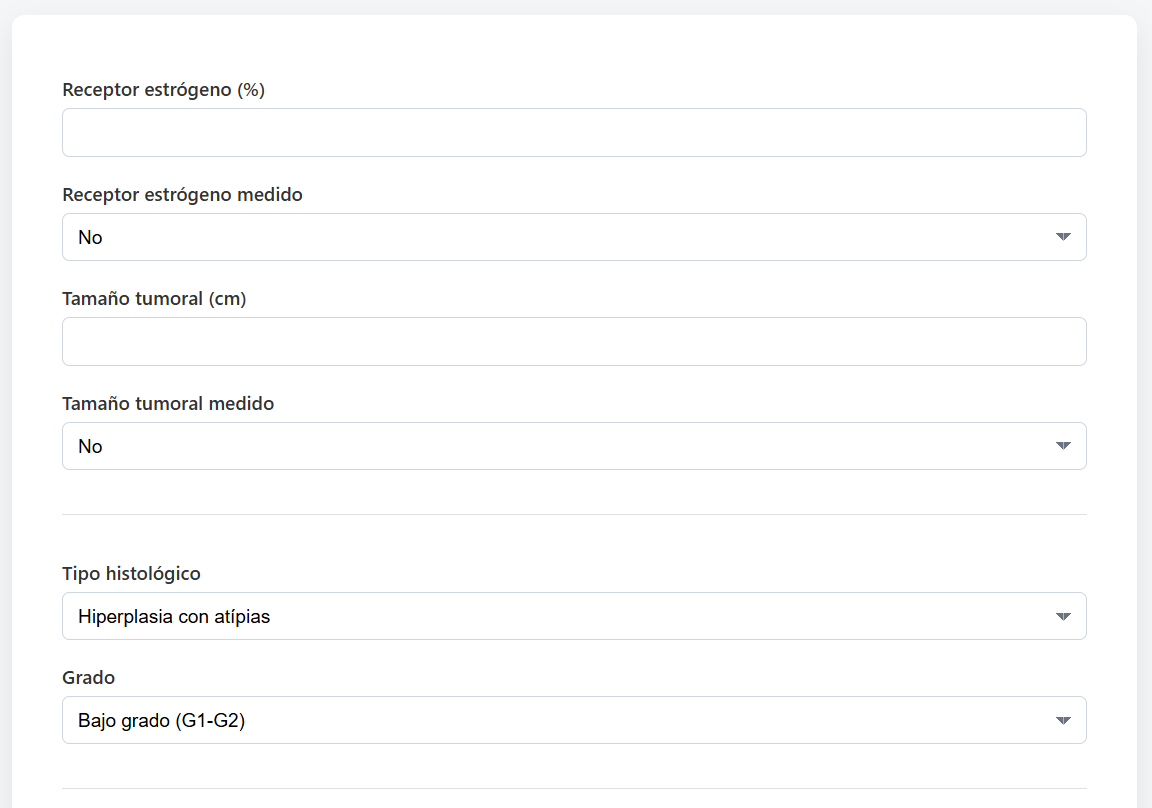
Ejemplo de una parte del formulario desarrollado
ML Predictivo: Recaída en Cáncer de Endometrio
Inspiración
La inspiración fundamental de este proyecto radica en la oportunidad de generar un impacto significativo y tangible en el pronóstico y el manejo del cáncer de endometrio.
Somos plenamente conscientes de la delicadeza y la profunda trascendencia que el cáncer tiene en la vida de los pacientes y sus familias. Por ello, nuestro objetivo no es solo desarrollar un modelo algorítmico, sino también contribuir a:
- Mejorar el Seguimiento Clínico: Proporcionar una herramienta que complemente la experiencia clínica.
- Optimizar las Intervenciones Terapéuticas: Facilitar decisiones más informadas y potencialmente más tempranas, mejorando los resultados de salud a largo plazo.
Este proyecto representa nuestro compromiso personal y técnico con la aplicación de Machine Learning como un catalizador para la mejora continua de la salud pública y la oncología de precisión.
¿Qué hace?
El proyecto implementa un modelo de Machine Learning (ML) diseñado para la predicción temprana de la recaída en pacientes diagnosticadas con cáncer de endometrio.
Funcionalmente, el sistema toma un conjunto de datos clínicos y patológicos clave de la paciente y calcula la probabilidad de que esta experimente una recurrencia oncológica. El objetivo es ofrecer una herramienta de soporte a la decisión clínica para la estratificación del riesgo.
¿Como lo hemos desarrollado?
El proyecto se construyó siguiendo un flujo de trabajo estándar en Machine Learning:
- Preparación de datos: Procesamiento y limpieza del dataset clínico limitado.
- Ingeniería y selección de características (Feature Selection): Análisis exhaustivo de las variables para identificar el subconjunto de características más predictivas y relevantes.
- Modelado: Entrenamiento y evaluación de algoritmos de clasificación, enfocándonos en Support Vector Classifier (SVC) y Random Forest.
- Optimización: Búsqueda exhaustiva de los hiperparámetros óptimos para cada modelo.
- Despliegue básico: Creación de una interfaz Front-End para interactuar con el modelo entrenado, demostrando su funcionalidad como prototipo.
Desafios encontrados
El desafío más significativo fue la escasez de datos clínicos disponibles para el entrenamiento, un obstáculo frecuente en la investigación médica. Esto nos obligó a:
- Gestionar el riesgo de overfitting debido al tamaño limitado del dataset.
- Realizar una Ingeniería de Características mucho más detallada y rigurosa para extraer el máximo valor de las variables existentes.
- Dedicar un esfuerzo considerable a la Selección de *Features* para garantizar que el modelo se mantuviera robusto y generalizable con el mínimo de datos de entrada.
Logros obtenidos
Estamos particularmente orgullosos de:
- Lograr un modelo funcional: Desarrollar un modelo predictivo que demuestra un rendimiento prometedor a pesar de las limitaciones del dataset.
- Dominio de la optimización (Hyperparameter Tuning): La exploración exhaustiva de todas las posibles combinaciones de hiperparámetros para SVC y Random Forest, lo cual fue clave para maximizar la precisión.
¿Que hemos aprendido?
Los aprendizajes clave se centraron en:
- Gestión de datos escasos: Entender las técnicas necesarias para trabajar con datasets médicos limitados.
- Profundización en algoritmos: Dominar la implementación y el ajuste fino (tuning) de clasificadores de ML complejos como SVC y Random Forest.
- Desarrollo Web para ML: Adquirir experiencia práctica con el diseño web (front-end) necesario para crear una interfaz accesible que consume el modelo de predicción.
Punto de mejora
- Validación externa y aumento de datos: Colaborar para obtener un dataset más amplio y diverso que permita una validación más robusta del modelo y poder afinar este aún más.
- Mejora del Despliegue: Desarrollar una aplicación web más robusta y segura (integrando el back-end y la API del modelo) para su potencial uso en entornos clínicos desplegando este servicio en la web.

Log in or sign up for Devpost to join the conversation.