Inspiration
The top 0.1% of importers run on global trade fabric. Walmart has Flexport. Apple has Maersk. A guy buying 500 lithium cells from Shenzhen has Google and a freight broker who returns calls on Tuesdays.
That asymmetry is the entire problem. Every piece of intelligence a Fortune 500 importer pays six figures a year for (real supplier discovery, live tariff math, chokepoint risk, modality optimization) is technically deliverable to a single buyer. Nobody has built it because the unit economics never worked. With cheap agentic models, that just changed. We built Habibti to connect one small importer to the same trade fabric the top of the market already operates inside.
What it does
You type a sentence. 500 lithium batteries from china to la by aug 30, $80k. Thirty seconds later you have three ranked options.
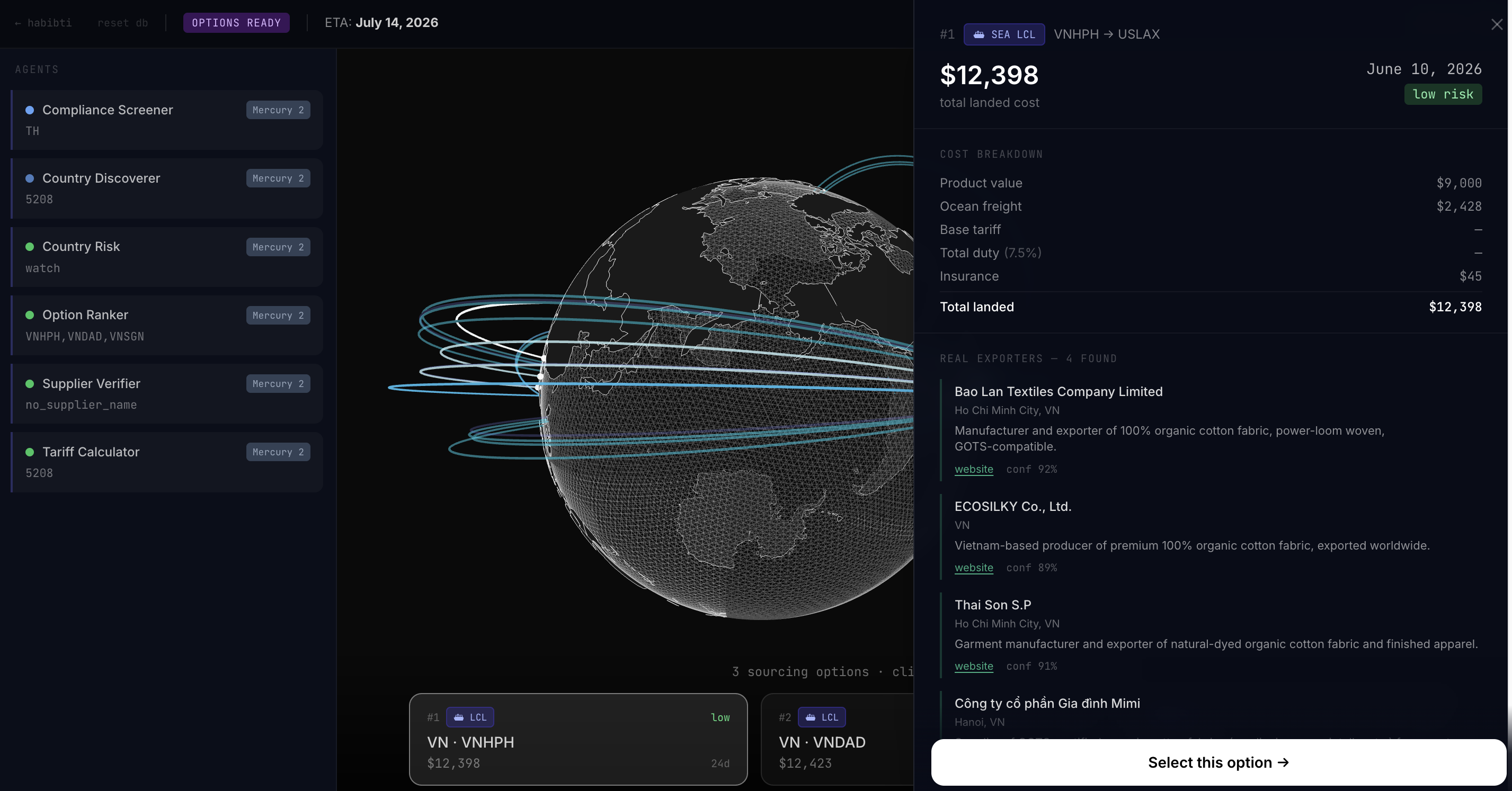
Each option carries a real exporter with a verifiable URL, a full landed-cost breakdown (product, duty, freight, insurance, broker), a route through the actual maritime chokepoints your cargo will physically traverse, per-leg risk analysis, and the shipping modality (FCL, LCL, or Air) that wins on cost while still meeting your deadline. The whole thing renders on a live globe as the agents complete.
How we built it
The architecture is a swarm. Every shipment runs through 30+ specialist agents arranged as a directed graph. Each agent owns exactly one decision and publishes a typed signal the next agent reads. There is no single big model doing sourcing. There is a fleet of cheap Mercury-2 calls, each around 2 seconds, orchestrated under a semaphore cap of 5 concurrent LLM dispatches.
The sourcing pipeline runs in phases. country-discoverer pulls UN Comtrade volumes and pre-filters sanctions. A fan-out runs tariff-calculator (Federal Register USTR data plus Section 301/232 math) in parallel with country-risk (30-day GDELT window), and a viability gate kills candidates that fail on duty, geopolitics, or transit. Surviving countries get compliance screened through GLEIF, UK Companies House, OFAC SDN, and the UFLPA Entity List. port-discoverer pulls every port for a country from UN/LOCODE (China alone has 369), ranks by capacity, enriches the top 5 with news, and Mercury picks the best 3.
Route planning is pure code. A graph search across 14 maritime chokepoints (Suez, Panama, Malacca, Hormuz, Bab-el-Mandeb, Bosphorus, Kiel, Sunda, Torres, Taiwan Strait, Cape of Good Hope, Cape Horn, Gibraltar) and 13 basins wired together by explicit adjacency, with each route scored so toll-heavy paths only win when they actually save the distance. supplier-discoverer uses Mercury with the OpenRouter web plugin to return 4-6 real exporters per country with evidence URLs. A second pass extracts actual $/unit prices from those listings so the product value is grounded in market data instead of Comtrade averages. leg-analyzer fans out per unique leg and pulls GDELT 14d and 90d, wave height vs climatology, AIS vessel density, JWLA war-risk zones, seasonal hazards, and bunker fuel price. freight-pricer evaluates FCL, LCL, and Air per route and returns the viable modality matrix. option-ranker synthesizes the final three with reasoning.
The frontend is a Three.js globe that draws one arc per route leg, with chokepoint waypoints rendered as amber markers as agents complete. Next.js 14, Drizzle, Postgres 16, Tailwind, Framer Motion.
Challenges we ran into
The hard part of this project was never any one agent. It was getting 30+ of them to actually work together.
Designing the contracts between agents. When agent A's output is agent B's input, the schema is the API. We rewrote those schemas constantly. The cost breakdown started as something the option-ranker computed inside its LLM call, until we realized Mercury was occasionally hallucinating freight numbers that contradicted the agent we already had for it. We pulled the math out of the model entirely. The orchestrator pre-computes the full OptionCandidate[] now, and Mercury only writes reasoning and ranks. That single boundary, what belongs to code and what belongs to the LLM, was the hardest design question in the project and the one we revisited the most.
Fan-out economics. A naive pipeline calls every agent for every candidate origin, which means burning supplier discovery on countries that will get ruled out two phases later for tariff or deadline reasons. We restructured around viability gates and deferred the expensive web-plugin calls until after route candidates were locked in. The pipeline now spends LLM budget only on countries that have a real chance of winning.
Deduplication. Three routes from China, India, and Vietnam all pass through Malacca. Naive fan-out analyzes that leg three times. We keyed leg-analyzer dispatches by a chokepoint signature so the same Suez transit gets one analysis no matter how many routes share it. Same logic for air routes (one per country regardless of how many seaports you'd otherwise emit duplicates for). This is the kind of optimization that doesn't matter at 3 agents and is the difference between a 30s pipeline and a 90s one at 30.
Geometry the LLM cannot do. Our first pass asked Mercury to plan routes. It would route Shanghai to Rotterdam directly across continental Asia. We tore it out and built the entire geometry layer ourselves: 14 chokepoints with bounding boxes and connectivity, 13 basins with explicit adjacency, antimeridian-aware bbox overlap so a trans-Pacific leg doesn't falsely intersect the Persian Gulf. The Red Sea has to dead-end at Suez. Enclosed seas have no adjacency and must enter via a gate. None of these are things you can prompt your way out of.
Real suppliers, not hallucinated ones. Mercury alone returns plausible-sounding exporter names that don't exist. We benchmarked the approaches: Mercury alone hit 3 out of 8, Mercury plus the web plugin hit 7 out of 8 with real verifiable URLs. Then we cross-verified the top result against GLEIF for a registry-backed confidence flag. Then we caught that Mercury was occasionally returning US firms when asked about Peruvian exporters and tightened the prompt. Real suppliers with real URLs was a multi-pass problem.
The modality matrix. A "route" used to mean a sea route. Then we added air courier and LCL consolidation, and suddenly each (country, port) candidate had to become 1-3 candidates depending on which modalities were viable. Rewiring the ranker, the cost breakdown, the UI, and the route_data JSONB shape to handle this without double-counting (showing the ranker both an option and its own alternatives) took two passes to get right.
Cost discipline at every layer. Two-tier cache (LRU + Postgres) on every external source. Port resolutions cached for a year on success. Mercury responses cached on the prompt hash. We treated every API call like it cost real money because it did.
Accomplishments that we're proud of
A swarm of 30+ agents that actually run end-to-end in 30 seconds. Real suppliers with verifiable URLs. A pure-code router that gets Shanghai to Rotterdam through Malacca, Suez, and Gibraltar in the right order, every time. A modality matrix that picks FCL, LCL, or Air automatically based on cargo weight and deadline. A live globe that draws the route progressively as the agents finish. A three-tier port resolver that handles the gaps UN/LOCODE inexplicably leaves (USMIA is just missing from the canonical dataset).
But the thing we're proudest of is the architectural bet. We built this on the premise that a swarm of small specialist agents would beat one big model at this kind of work, and it does. Every agent has its own prompt, its own retry policy, its own fallback, its own validation schema. When something breaks you fix one agent, not the whole prompt. The pattern scales: adding a new data source means adding a new agent, not refactoring an existing one.
What we learned
A swarm of small cheap agents beats one big model. The architectural advantage compounds. Isolated context, isolated failures, isolated cost.
Pure code wins where determinism matters. Routes, distances, tariff math, chokepoint geometry. None of these belong in an LLM. LLMs win where judgment matters: picking 3 of 369 ports, ranking 10 modality-expanded options across cost and risk, choosing a supplier. Getting that boundary right was 80% of the design work.
Latency is wall-clock, not retry count. Compound retries are how you turn a 60-second budget into a 180-second one. Every external call in the system has a hard wall-clock bound.
The asymmetry between the top 0.1% of importers and everyone else is not a hard problem anymore. It's a build problem. We built it in a weekend.
What's next for Habibti
Live freight indices. Our distance-based model is a strong approximation but Freightos FBX would replace it with real spot rates.
Bill of lading data. ImportYeti or Trademo would let us show actual shipment history for a candidate supplier, not just registry verification.
Direct supplier contact. Today we surface real exporters with URLs. Next we want to send the RFQ for you and rank the responses.
Beyond US imports. The pipeline is destination-agnostic in principle. We want to open it up to EU, UK, MENA importers next.
A real freight forwarder integration. At the bottom of every ranked option is a "book this" button that should actually book it. That means a Flexport-style API integration or a direct relationship with a forwarder who'll accept programmatic bookings. That's the moat.
Built With
- drizzle
- gdelt
- mercury-2
- next.js
- postgresql
- typescript
- un/locode






Log in or sign up for Devpost to join the conversation.