-
-
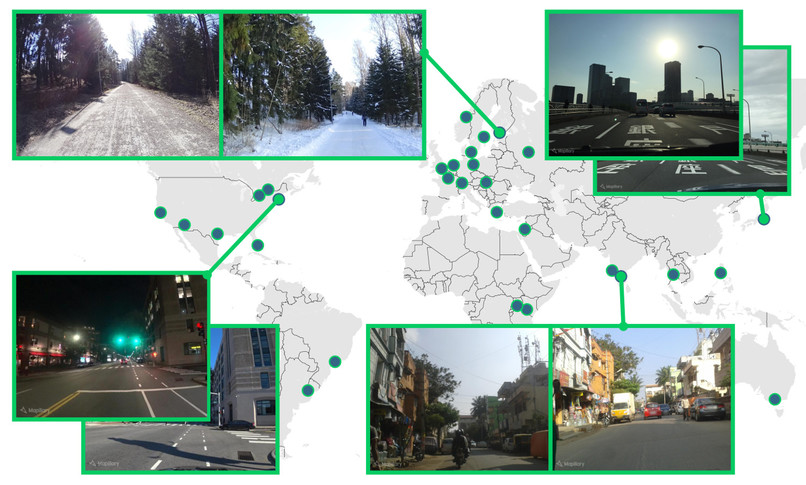
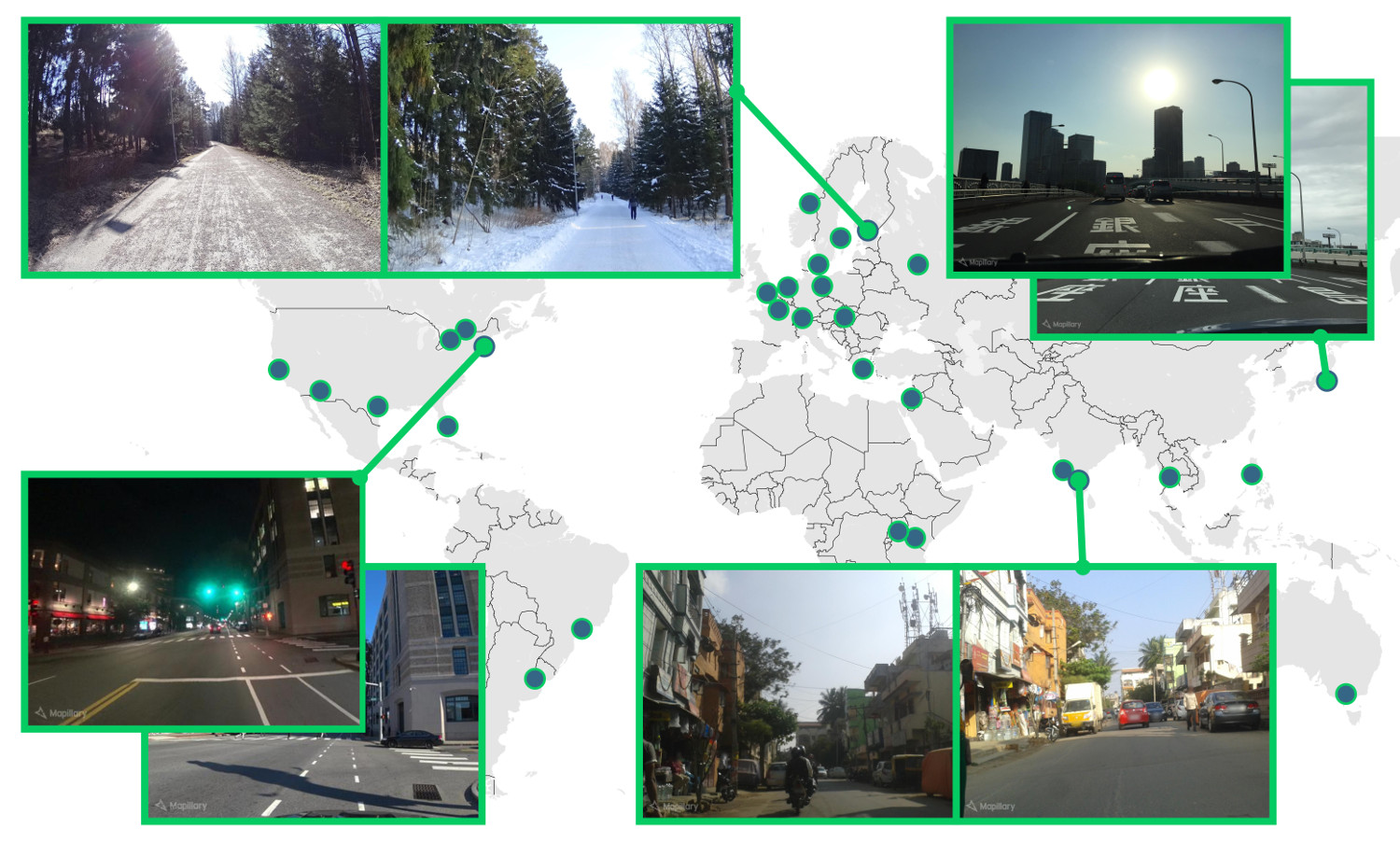
MSLS contains 1.6M images from 30 cities across varied conditions
-

The Dataloader transforms each image with gaussian noise and affine transformations
-
 GIF
GIF
Models trained on MSLS can produce smooth sequences/videos
-

The model can be moved to CPU and used to serve images generated on the fly
-
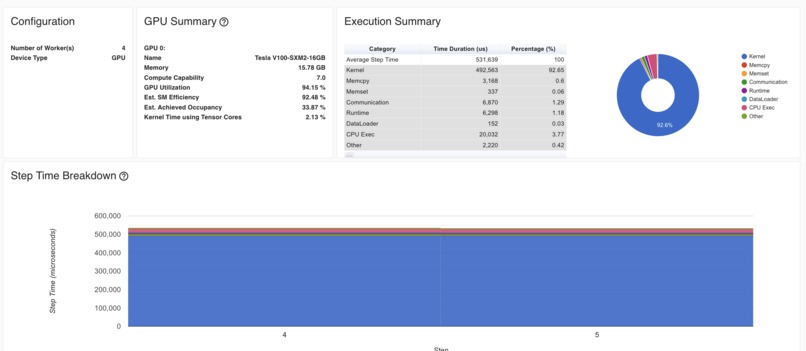
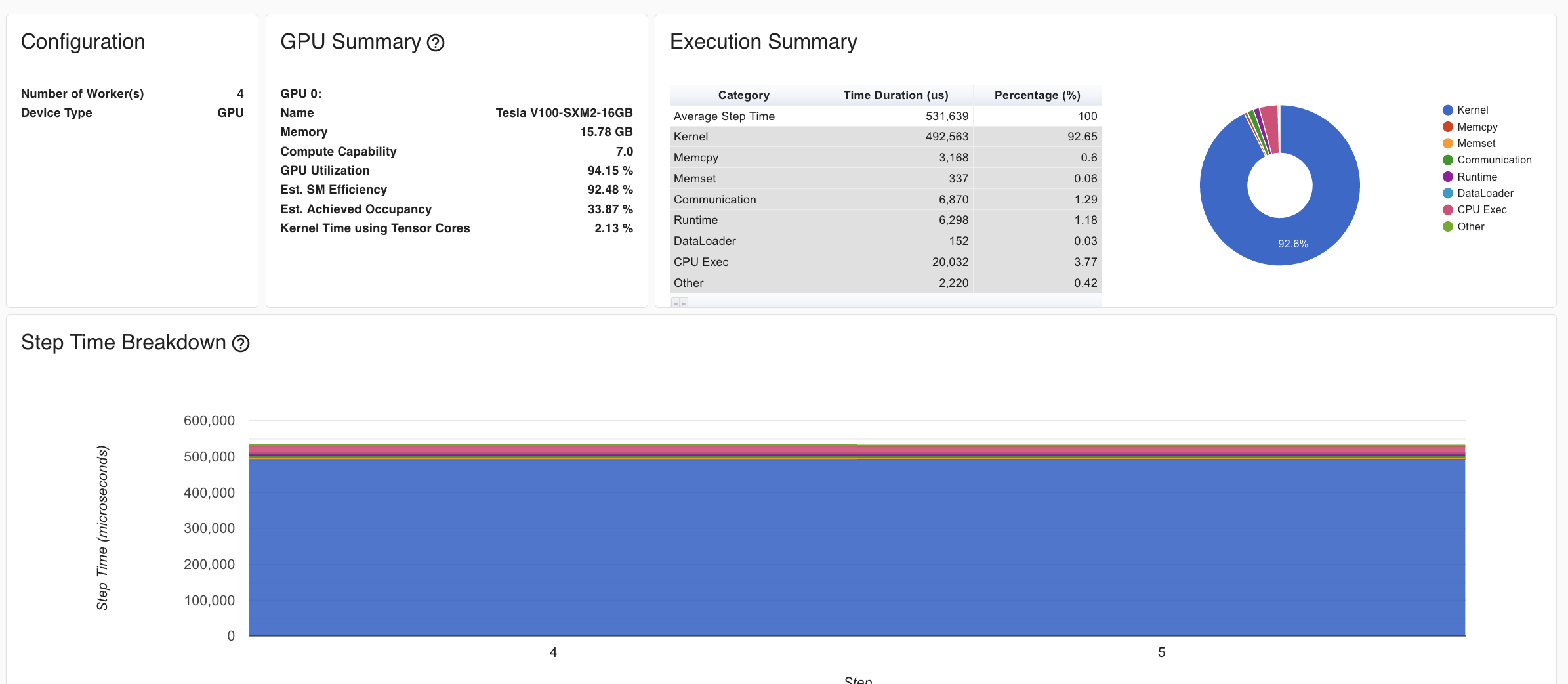
Tensorboard was used to profile models in development, and then used to record metrics for production models



The following contains snippets from my blog post here, feel free to read the full post for more detail.
Inspiration
For a few months now, I’ve wanted to create something like ThisPersonDoesNotExist for street scenes. It’s not a novel idea, and I’m certainly no ML engineer, but enough work has been done in this field that I was able to read up on the literature, implement generative models, and reason about architectural and performance tradeoffs. At a high level, my project involved re-implementing elements of two foundational papers in generative computer vision and then training that model on 1.2 million street-level images.
The DCGAN model architecture is quite "old", in Deep Learning time, 7 years is an eternity. As such, It suffers from stability issues, and doesn't produce the finest looking results. With that said, I wanted the challenge of writing the model code from scratch rather than pulling in a StyleGAN/StyleGAN2 (or another more modern architecture that was out of my depth to reason about).
What it does
In this project, I re-implemented elements of Ian Goodfellow’s Generative Adversarial Networks (2014) and Alec Radford’s Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks (2016) papers in PyTorch. Both papers are concerned with the development of GANs, Generative Adversarial Networks. I trained the model on a DL1 instance, and then serve an image gallery at the gallery.
How we built it
I used Terraform to provision a model training VPC on AWS. All training resources run in a single VPC with two subnets (1 public, 1 private) in the same availability zone.
I deployed the following instances to the VPC’s private subnet and accessed them via SSH through a jump-instance deployed to the public subnet.
training-prod — An EC2 instance for running deep learning models, either DL1 or a cost-comparable GPU instance (for development/testing). In either case, the instance is running a variant of the AWS Deep Learning AMI.
training-nb — A small SageMaker instance used for interactive model development, model evaluation, and generating plots.
metrics — A small EC2 instance used to host metrics containers. Most charts in the infrastructure, performance, and profiling section come off of these applications. Specifically, this machine ran: Tensorboard — A tool for visualizing machine learning metrcs during training. Grafana — An analytics and monitoring tool. I configured Grafana to visualize machine-level metrics from our training instances (e.g. HPU/GPU/CPU usage, diskio, etc.)
imgs-api — A small, CPU EC2 instance for hosting our model API. Runs a Flask app that serves images and gifs for the gallery.
Each of these instances has access to an AWS Elastic Filesystem (EFS) for saving model data (e.g. checkpoints, plots, traces, etc.).
Using EFS saved me hours of data transfer in development and allowed me to pass model checkpoints between machines (i.e. between training-prod and training-nb). However, because EFS can be quite slow compared to EBS or local storage, the actual training data was saved to a gp3 volume attached to my training instance and then passed to local-storage and then the HPU during training.
Challenges we ran into
Overall, most of the complications in this project were on the original model development side. I spent a good amount of time optimizing the model for GPU instances in Jan. 2022 before moving it over to the HPU in Feb. 2022.
For example, during development, the actual forward and backward passes were quite fast. However, on an un-optimized disk, the millions of calls to PIL.open() to generate samples started to make the dataloader a bottleneck.
I tried tweaking the number of dataloader workers and their pre-fetch factors, generating an hd5 dataset, writing my own dataloader, and even installing a SIMD fork of PIL to increase image processing performance (at the time I didn't know SIMD PIL was a default in Habana containers!). Luckily, this problem was resolved by better disk, and creating a larger model (i.e. scaling to 128^2)
Accomplishments that we're proud of/What we learned
I'm proud of the performance testing and problems I solved. I fee; like I'm walking away with a better sense of ML training infrastructure than I had a month or so ago. Also, I haven't written any ML code since 2014, so it was important for me to learn a bit about the model, the model architecture, optimizers, etc before really getting going on the hackathon project. Some of the improvements I don't think I would have been able to diagnose before 6 weeks ago seem obvious now.
On the Model/ML Side:
Using HMP/AMP — Automatic Mixed Precision (AMP) allows for model training to run with FP16 values where possible and F32 where needed. This allows for lower memory consumption and faster training time, but several weeks ago I had no intuition about this.
How trainable parameters flow through a model, what makes a model "larger" or "smaller", how a "simple" model like DCGAN can be manipulated to have it accept different sized inputs. It's nice to occasionally do some mathematical reasoning.
These are minor details in the overall scheme of the project, but I wrote some really nice code for doing Spherical Interpolations between frames to create GIFs. I also wrote some nice code for Parzen Log-Liklihood Estimation to try to validate the GANs outputs. Both of these are interesting topics and I could do a lot of further work on either.
On the Infra Side:
Upgrade EFS to EBS — Regrettably, an EFS file system can only drive up to 150 KiB/s per GiB of read throughput (may have changed, I saw some new AWS EFS blogs in the last week, haven't read them yet). To alleviate this issue, I attached a gp3 (8000 iops, 1000 MiB/s) volume to my training instance(s). Although EBS is more expensive, the decision paid for itself by saving hours of idle GPU/HPU time.
Intuition about Distributed Data Processing — In isolation, distributed data processing doesn’t improve the model’s training performance, but it does lend towards a more robust training environment. For the most part, I do Ops, not ML, thinking of training as a distributed system was helpful
What's next for Street-Scenes DCGAN
I really like the idea of serving images in real time, and I think I've coded out a fine framework for training the model to serve. There are some obvious flaws, like the image generation time is slow, the API is very bare-bones, etc. These aren't too hard to fix.
But this isn't so interesting to fix right now, I think given a bit more time and resources, I'd like to drop in a more-modern GAN architecture so I can get more reliably "nice" looking images.
Built With
- amazon-web-services
- grafana
- tensorboard
- terraform



Log in or sign up for Devpost to join the conversation.