-
Multi-provider configuration in Keywords AI
-
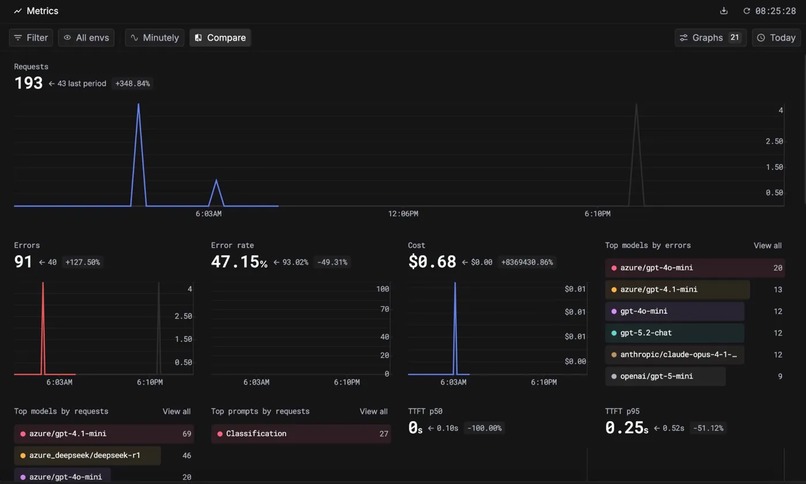
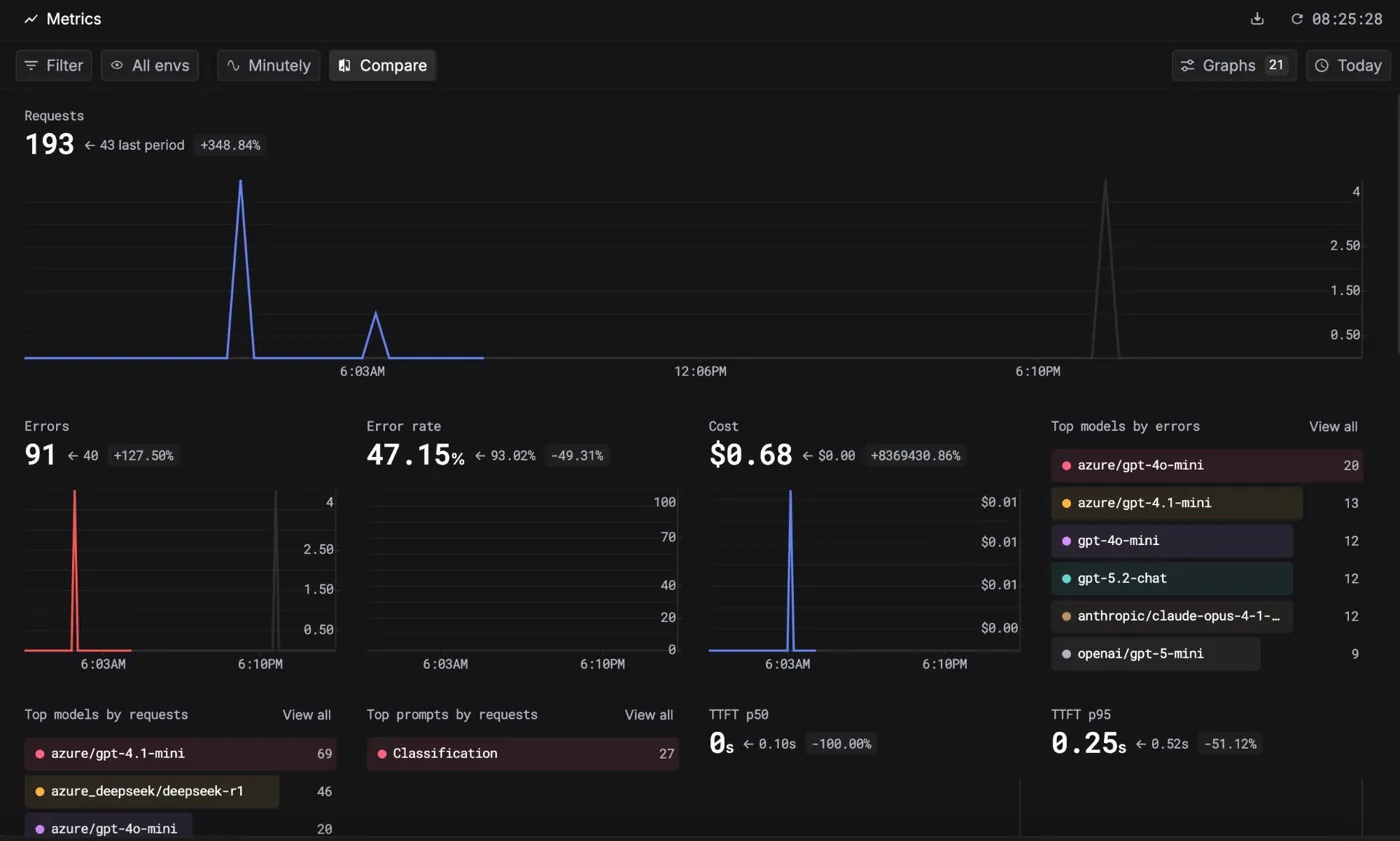
Real-time performance metrics from Keywords AI dashboard
-
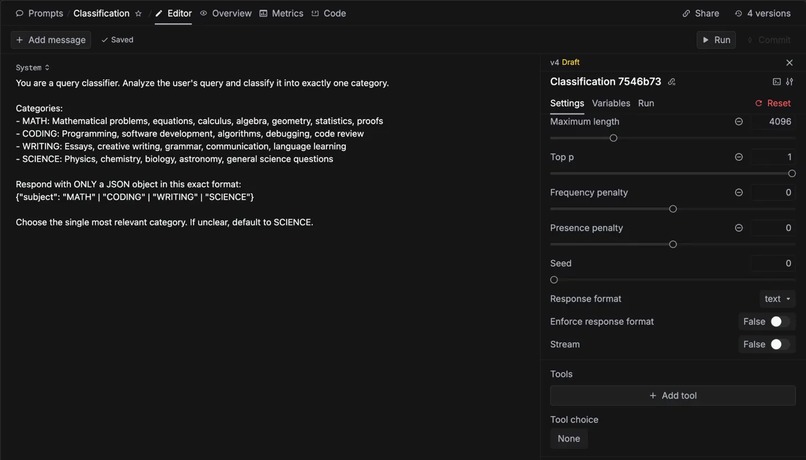
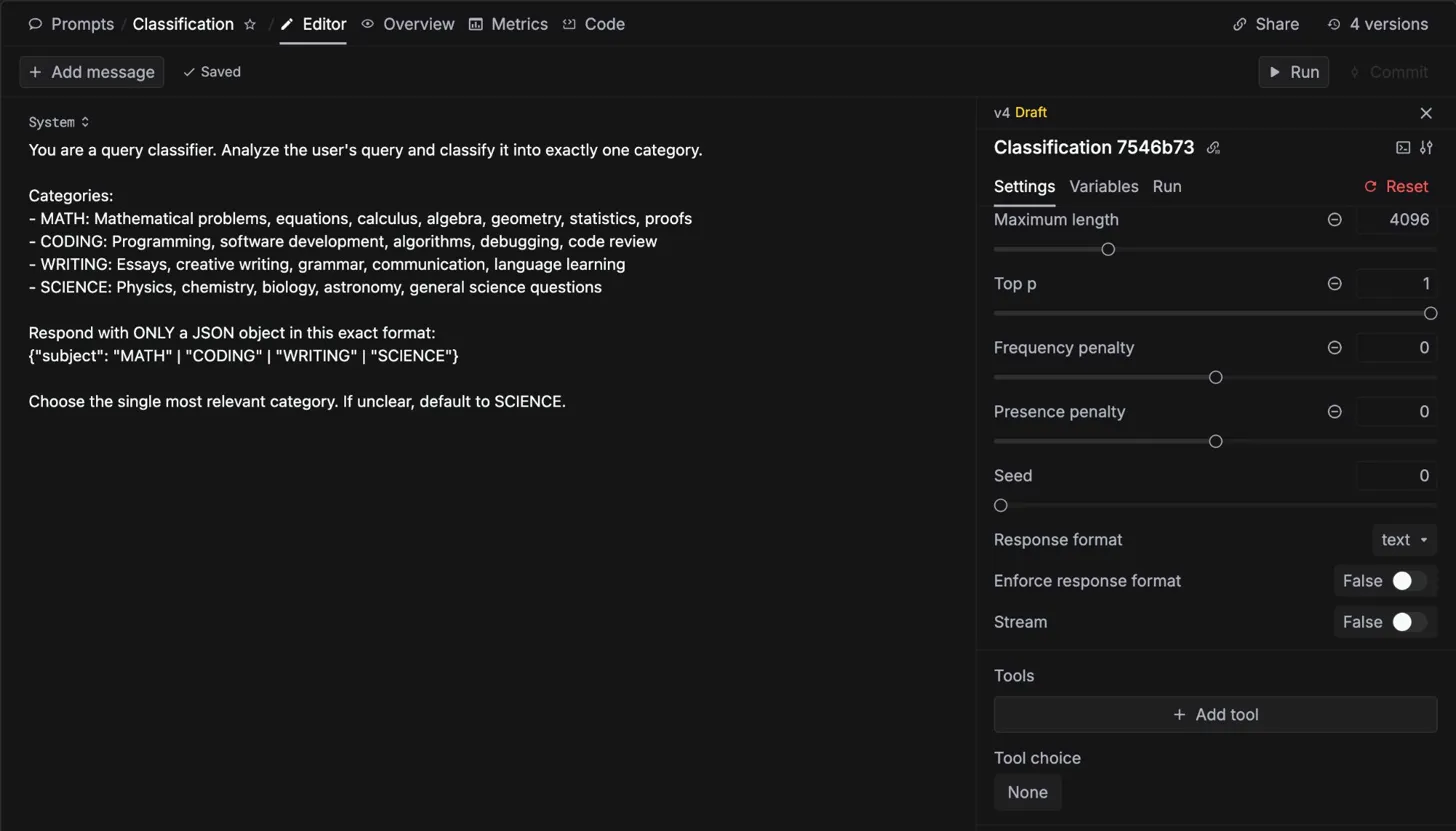
Classification system using Keywords AI Prompt Management
Gyst AI
An Adaptive Learning Engine That Transforms Study Material Into Personalized Mastery
Inspiration
Traditional study tools fall into two extremes: they either regurgitate material you already know or provide generic explanations that miss your specific gaps. Students spend hours reviewing concepts they've mastered while their real weak points go unaddressed.
Gyst was born from a simple question: What if learning software could understand not just what you're studying, but what you actually struggle with? By analyzing your inputs—homework attempts, practice problems, or study notes—Gyst identifies your conceptual gaps and builds personalized content that focuses precisely where you need it most.
What It Does
Gyst is an adaptive learning system that operates in a closed feedback loop: analyze → teach → test → adapt. Each cycle refines your learning path based on demonstrated understanding, not superficial engagement.
Core Workflow
1. Input & Analysis
Users submit study material through text prompts, PDFs, or images (such as homework or exam attempts). An underlying LLM analyzes the input to:
- Identify the subject and relevant subtopics
- Assess demonstrated strengths and weaknesses
- Infer conceptual gaps from attempted solutions
2. Intelligent Model Routing with Keywords AI
A critical innovation in Gyst is its use of Keywords AI Gateway to route requests to specialized models based on content type. When you submit your study material, our classification system determines the category (Math, Coding, Science, or Writing) and routes to the optimal model:
- Deepseek-R1 for math and coding tasks
- GPT-4.1 for writing and science content
- Model-specific optimizations for quiz generation, response verification, and content creation
This ensures that each subject area is handled by the AI most capable in that domain, dramatically improving the quality and accuracy of generated content.
3. Structured Content Generation
The contents page presents results in three layers:
- What you are prepared for: topics where you demonstrate confidence
- What we can work on further: areas requiring additional focus
- Main learning content: a LaTeX-rendered article emphasizing weak areas while remaining comprehensive and well-structured
Supplementary videos and links adapt based on interaction signals like clicks and quiz performance. They can be disabled entirely based on user preference.
4. Interactive Learning & Persistent Notes
Users can ask follow-up questions directly within the content flow. Each session includes a persistent side-panel notepad styled like a lined notebook. Notes are automatically saved, persist across quiz attempts, and remain accessible from the main page.
5. Adaptive Assessment
Learning is reinforced through multi-format quizzes delivered in a clean pop-up interface:
- Multiple-choice questions
- Short-answer questions with semantic grading
- Domain-appropriate coding challenges
Open-ended responses are graded semantically using an LLM, capturing meaning rather than exact phrasing. Quizzes progress through three levels—Basic, Intermediate, and Advanced—with advancement requiring a 90% score at each stage. Achieving 90% at the Advanced level marks mastery and concludes the session.
🔧 How We Built It
Technology Stack
- Frontend: React with modern UI components, LaTeX rendering for mathematical content
- Backend: Node.js/Express with intelligent routing logic
- AI Infrastructure: Keywords AI Gateway for multi-model orchestration
- Document Processing: PDF parsing, image OCR, text extraction
Keywords AI Integration
Our implementation leverages three critical features of Keywords AI:
Keywords AI Organization ID: d8ab9b73-5450-4cd4-9343-ef558b2893e0
1. AI Gateway for Multi-Model Routing
Instead of using a single model for all tasks, we route requests to specialized models. A classification prompt determines the subject category, then sends subsequent requests to the model best suited for that domain. This approach dramatically improved content quality—math problems are solved by DeepSeek-R1, which excels at reasoning, while writing tasks go to GPT-4.1, optimized for language generation.
Figure 2: Multi-provider configuration in Keywords AI
2. Prompt Management
The classification system uses Keywords AI's Prompt Management feature. Rather than hardcoding prompts across multiple files, we store the classification prompt centrally and reference it by ID. This allows us to:
- Iterate on prompts without redeploying code
- Maintain version control of prompt changes
- Assign specific models and roles to prompts
- Ensure consistency across all classification calls
The classification prompt uses GPT-4.1-mini with a system role, structured to return JSON identifying the category (Math, Coding, Science, or Writing). This ID-based approach eliminated prompt drift and simplified our codebase significantly.
3. Metrics & Monitoring
Keywords AI's dashboard provides real-time insights into:
- Error tracking: where requests fail and why
- Model performance: which models perform best for each category
- Token usage: cost optimization across providers
- Latency metrics: response times by model and prompt
This visibility was crucial during development. We identified that certain models were producing errors for edge cases, adjusted our routing logic, and optimized token usage by switching to more efficient models where appropriate.
Figure 3: Real-time performance metrics from Keywords AI dashboard
⚡ Challenges We Ran Into
1. Semantic Grading Accuracy
Open-ended quiz answers needed to be graded on meaning, not exact wording. Early attempts produced false negatives where correct answers using different phrasing were marked wrong. We solved this by implementing multi-shot prompting with example correct/incorrect pairs and asking the LLM to explain its reasoning before assigning a grade.
2. Model Selection Per Domain
Initially, we used a single model for all content. Quality varied dramatically—math solutions were mediocre, coding explanations were verbose, and science content lacked depth. Keywords AI Gateway solved this by enabling dynamic routing. Now DeepSeek-R1 handles quantitative reasoning while GPT-4.1 manages language-heavy tasks, resulting in measurably better outputs.
3. Content Overload
Early versions generated comprehensive articles that covered everything, diluting focus on weak areas. We refined the analysis pipeline to explicitly prioritize gaps, limiting comprehensive coverage to essential context. The result: learning content that respects the user's time by teaching what they don't know, not what they do.
4. Quiz Difficulty Calibration
Creating truly progressive difficulty levels was harder than expected. We implemented a feedback mechanism where quiz generation considers not just the topic but the user's previous performance, dynamically adjusting complexity. The 90% threshold ensures users genuinely master each level before advancing.
🏆 Accomplishments That We're Proud Of
- Closed-loop learning system that genuinely adapts to demonstrated understanding, not clicks or time spent
- Multi-model intelligence leveraging Keywords AI to route each task to the optimal LLM
- Semantic grading that evaluates understanding instead of memorization
- Clean, focused interface that avoids stereotypical AI aesthetics and stays out of the learner's way
- Persistent learning context through integrated note-taking that carries across sessions
📚 What We Learned
1. Specialization Beats Generalization
Using the right model for the right task produces dramatically better results than using one model for everything. Keywords AI's routing capabilities made this practical to implement.
2. Understanding Over Engagement
Most learning platforms optimize for time spent or interactions. We learned that rigorous testing—requiring 90% mastery before advancement—creates better learning outcomes even if it means shorter sessions.
3. Prompt Management Is Critical
Centralizing prompts through Keywords AI's management system eliminated inconsistencies and made iteration far easier. Being able to test prompt variations without redeploying code accelerated our development cycle significantly.
4. Observability Drives Quality
Keywords AI's metrics dashboard revealed patterns we wouldn't have caught otherwise—specific models failing on edge cases, token inefficiencies, and performance bottlenecks. This visibility was essential for building a production-ready system.
🚀 What's Next for Gyst
Spaced Repetition Integration
Implement scientifically-backed spaced repetition scheduling to reinforce mastery over time. Topics would resurface at calculated intervals to ensure long-term retention.
Collaborative Learning
Enable study groups where multiple users can work through material together, with Gyst adapting to collective strengths and weaknesses.
Curriculum Mapping
Align content generation with specific curricula (AP, IB, university courses) to create structured learning paths that follow established educational frameworks.
Performance Analytics
Build detailed progress tracking showing mastery trajectories, weak point trends, and predicted readiness for exams or assessments.
Multi-Modal Content
Expand beyond text to include generated diagrams, interactive simulations, and audio explanations for different learning styles.
✨ Conclusion
Keywords AI Organization ID: d8ab9b73-5450-4cd4-9343-ef558b2893e0
Gyst represents a shift from content delivery to genuine learning orchestration. By combining intelligent analysis, multi-model AI through Keywords AI, adaptive assessment, and rigorous mastery thresholds, we've built a system that respects learners' time and intelligence.
Rather than adding to the noise of generic study tools, Gyst cuts through it—focusing precisely on what you need to learn, testing rigorously to confirm you've learned it, and adapting continuously based on your demonstrated understanding.
Learning shouldn't be about time spent. It should be about mastery achieved. That's what Gyst delivers.
Tagline: Study smarter. Master faster.
Built With
- claudecode
- keywordsai
- lovable
- react
- supabase

Log in or sign up for Devpost to join the conversation.