-
-
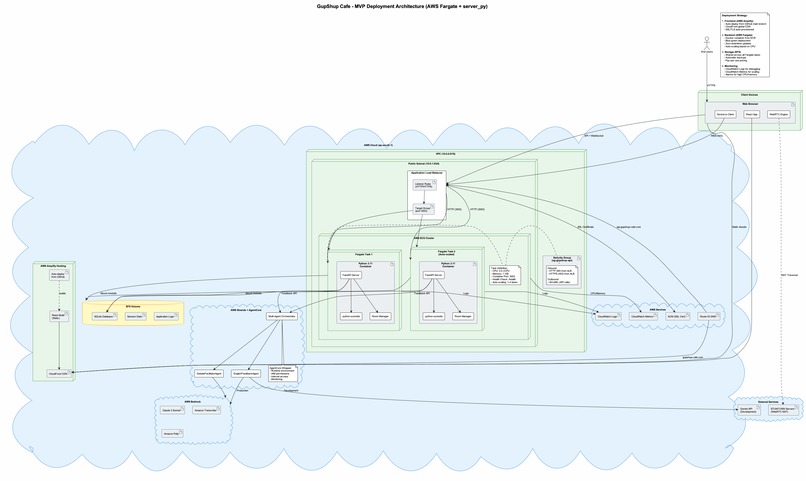
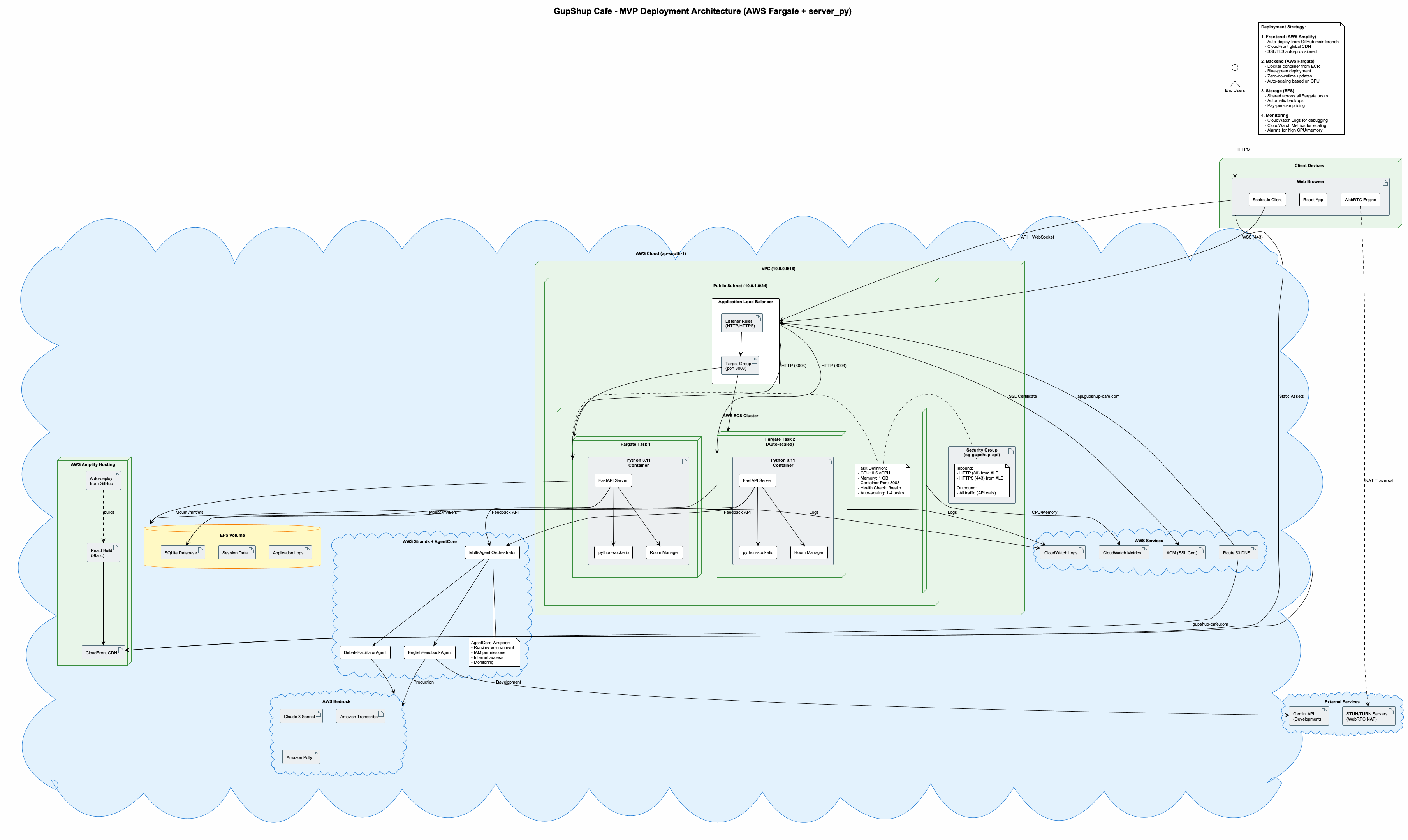
Deployment Diagram
-
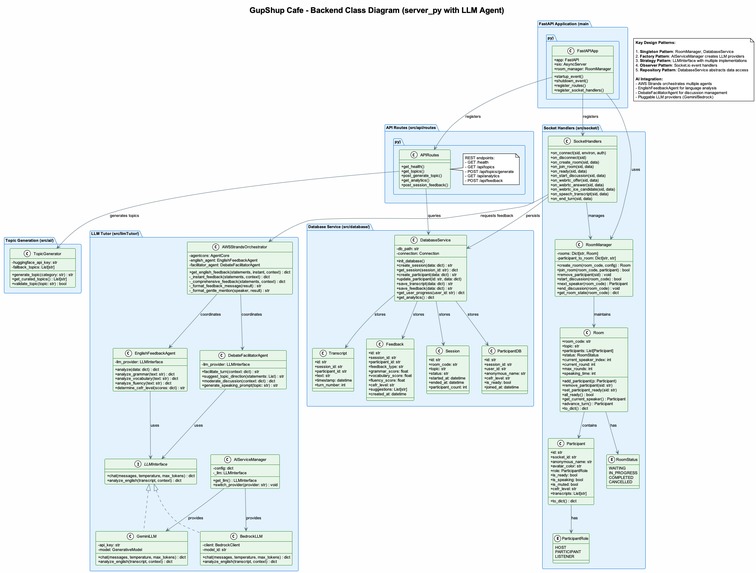
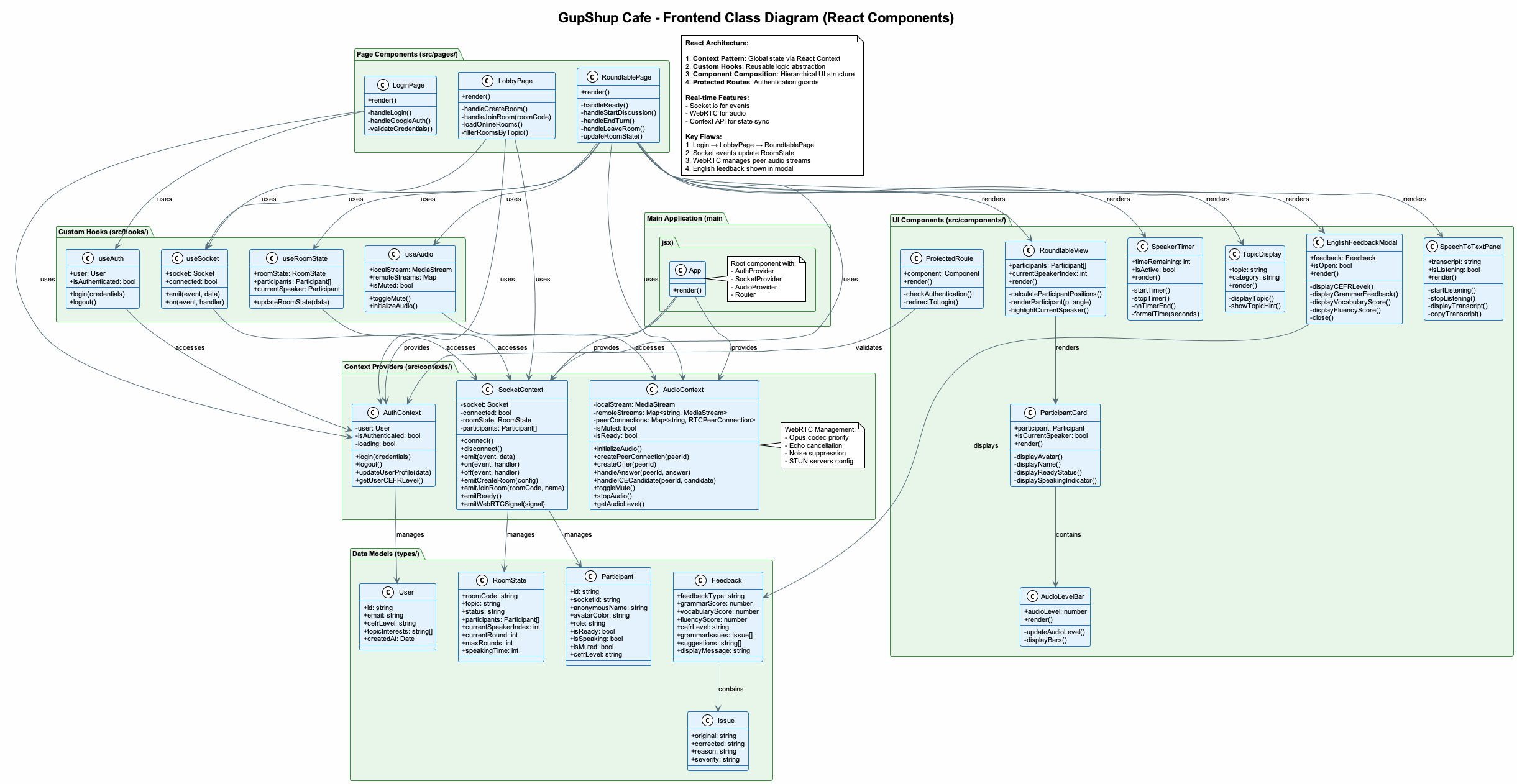
Architecture 2
-
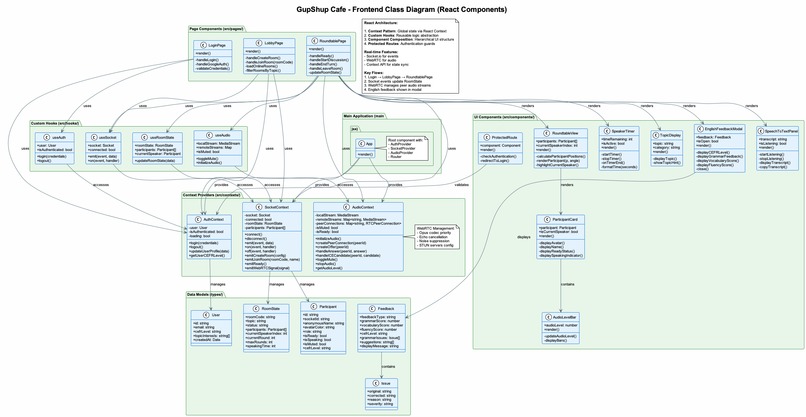
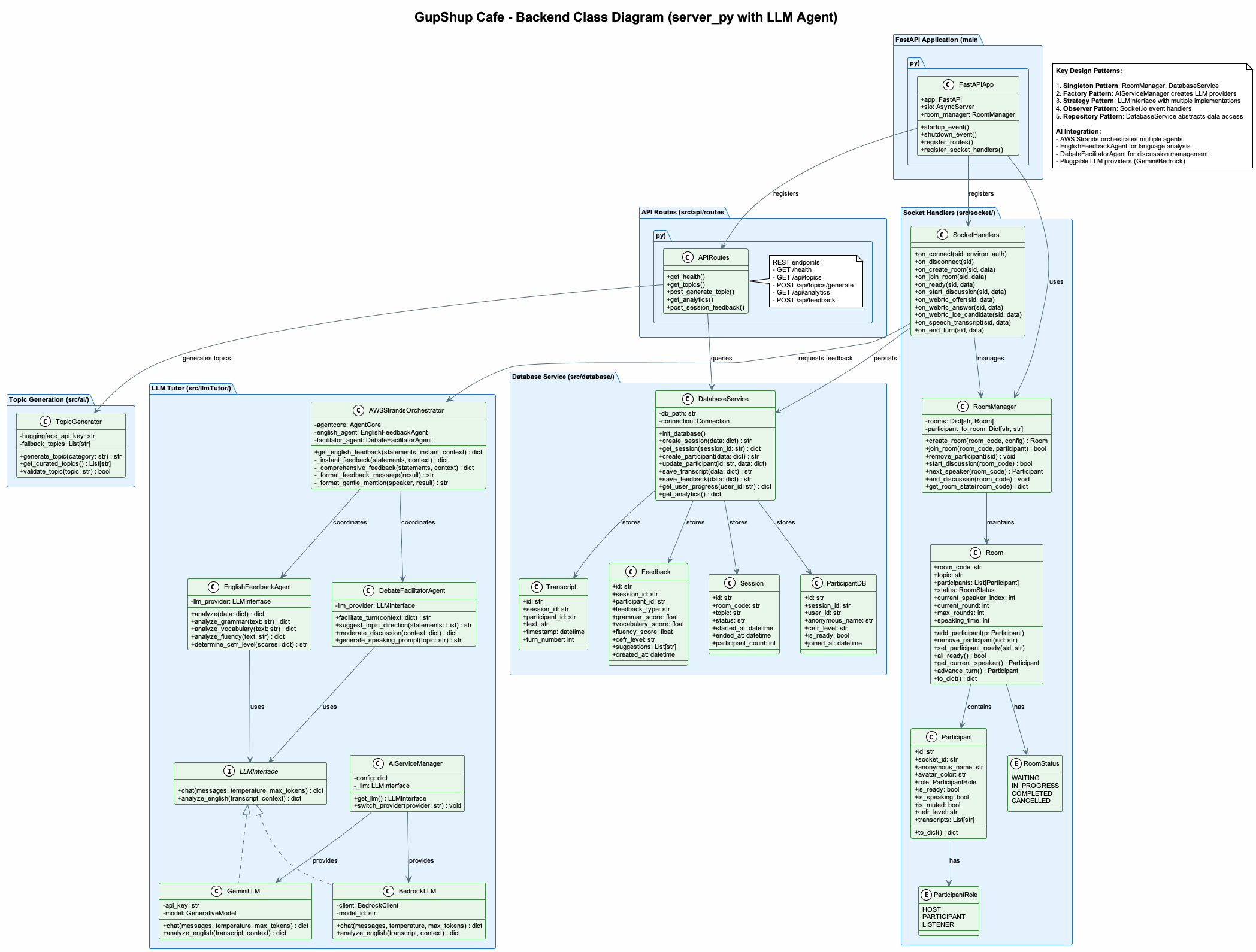
Architecture
-
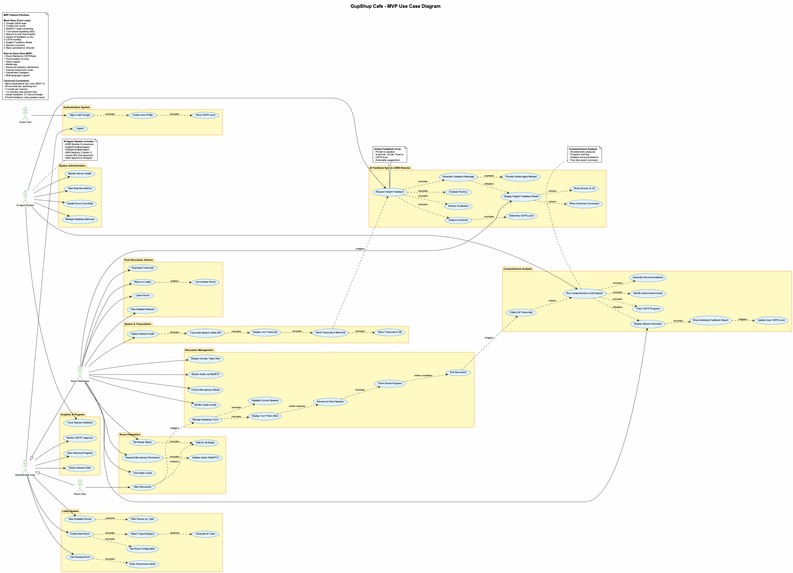
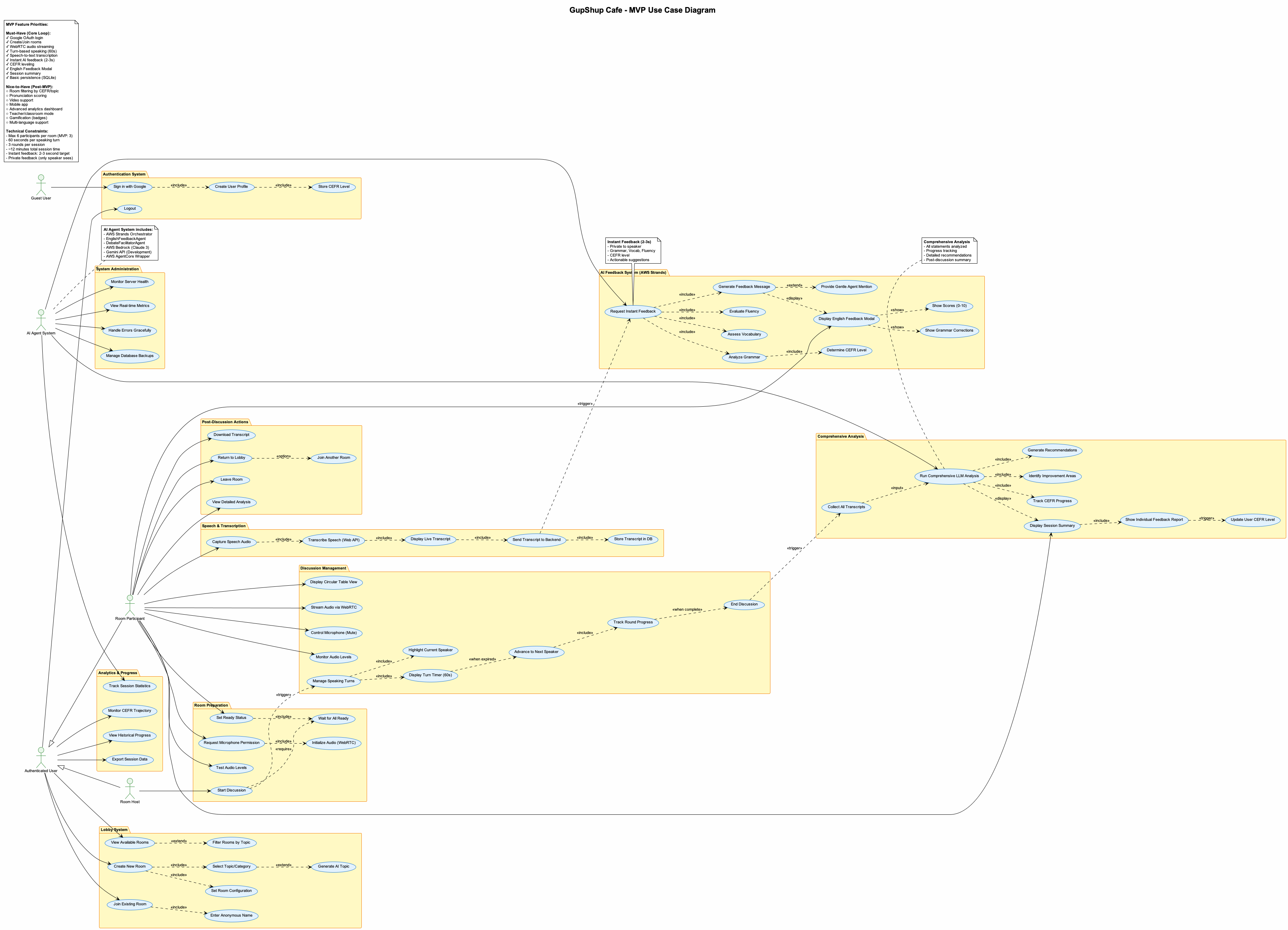
Use case diagram
Gup-Shup Café — the NavGurukul team story
We are the small technical team at NavGurukul Foundation for Social Welfare — building Gup-Shup Café to help our 1200+ girls across 9 campuses get fast, joyful, and measurable gains in spoken English. Below is the story of why we started, what the platform is, how we built the first prototype, the real problems we hit, what made us proud, what we learned, and the concrete next steps to turn this into a campus‑wide programme that helps more girls get from B2 to C1.
Why? — the heart of the project
- The problem: residential students can speak, but “correct” English (grammar, sentence structure, fluency under pressure) is still a barrier. Mentors and Associates also struggle to give high-quality, consistent corrections at scale.
- The idea: use AI to provide personalised, instant, non-judgemental correction and coaching inside safe peer groups so each student gets many short practice opportunities.
- The social design: anonymous, peer-group discussions (a “table” in the Café) let students practise without fear of judgement while the AI gives clear, simplified feedback tailored to each learner.
- The impact hope: we’ve seen students reach CEFR level B2 in 5–6 months; with sustained, daily practice and targeted AI feedback we aim to increase the percentage who reach C1.
We do this because minutes of guided speaking — with kind, actionable correction — compound quickly.
What? — Gup-Shup Café, at a glance
Gup-Shup Café is a community-driven discussion, debate and practice platform designed specifically for language learners, with these distinctive characteristics:
- Community + anonymity: students join tables anonymously to discuss, roleplay, or debate topics.
- Fair participation: turn-based speaking control and visual cues ensure everyone gets their chance.
- Instant corrective feedback: AI agents provide simplified, scaffolded feedback tied to CEFR objectives.
- Gamified & low-friction: short micro-sessions, upcoming streaks and friendly rewards to motivate daily practice.
- Multi-modal: voice-first experience with text fallbacks, transcriptions, TTS playback and visual highlights.
- Mentor-in-the-loop: mentors can review flagged sessions, add corrections, and run focused interventions.
- Progress tracking: CEFR-aligned rubrics (A1 → C2) map session data to measurable goals.
This is not just “another meeting app” — it is designed for learning, equity, and scale.
How? — technical stack, architecture and the experience flow
High-level tech choices (prototype → path to production)
- Frontend: React 18 + Vite + Tailwind (mobile-first, accessible UI)
- Backend: FastAPI (Python) + python-socketio for realtime messaging
- Real‑time voice: Socket.io signaling + WebRTC for low-latency voice when available
- STT (speech-to-text): Web Speech API in prototype; plan to evaluate Indian-accent tuned models in the future
- TTS: Zoe’s TTS for agent audio replies in the prototype
- Agent / LLM: AWS Strands + Gemini for development experimentation; AWS Strands + Bedrock-hosted models for production-grade calls
- Database: SQLite for quick prototyping (we’re rethinking this for scale: Postgres or RDS recommended)
- Deployment: Backend on EC2 ; Frontend on AWS Amplify; S3 storage for audio blobs
- Socket-based connections: Audio mesh over Socket based connections.
- UX: short, 3–7 minute practice “tables”; turn timer, visual speaking queue, and instant AI feedback card after each turn
- Pedagogy native: CEFR mappings for feedback so corrections map to competence goals (e.g., grammar, lexical range, coherence)
Typical session flow (what a student experiences)
- Student notices online waiting rooms aligned with their topics of interest and CEFR levels. She joins the room with an anonymous name.
- Anonymized participant handles are shown; the session starts when all the participants are ready. Waiting participants join a roundtable along with a facilitator agent and an English feedback agent.
- Students speak in turn (WebRTC streaming if available; otherwise chunked audio uploads).
- Each turn is transcribed (STT) and sent to the LLM agent.
- English Feedback Agent returns: (a) an instant feedback after the speaking turn of the student is over — simplified corrections, 1–2 model sentences, and CEFR-aligned suggestions. (b) Provides a summary of learnings for every student at the end of the discussion. Facilitator Agent joins the rounds and takes turns to speak - mainly exploring common points around the table and suggesting creative directions. It takes inputs from the English feedback agent to provide English-related insights.
- TTS plays the agent reply for the group; students can view the transcript and feedback card.
- Future progress tracking for mentors.
Design decisions we made
- Feedback must be tiny, private, instant & actionable.
- Use of AWS Strands for leveraging custom MCP tools like generate_topic, generate_order_of_speaking, etc. to provide the complete end-to-end context to the agent.
- Mentor-augmented agentic AI tool - mentors can join along with the students to encourage English learning
- Pedagogy alignment with the CEFR standard.
Challenges we ran into (real, immediate, and solvable)
LLM hallucination and sensitive outputs
- Unconstrained LLM replies can drift into unsafe or incorrect territory.
- Mitigation: strict prompt engineering, fine granularity on English feedback, use of database to store and supply context and use of AWS Strands.
Mentor-augmented AI agent tool
- Mentors feared replacement or poor pedagogy.
- Approach: position AI as co-teacher, provide mentor review tools, let mentors edit and approve agent templates.
Measuring meaningful learning gains
- Minutes spoken ≠ improvement in CEFR level.
- Solution: define CEFR-linked micro-assessments and pre/post speaking rubrics (mentor‑scored) for pilots.
Accomplishments we're proud of (small wins that matter)
- Built a working prototype during the AWS hackathon that: streams audio → transcribes → routes to an LLM agent → produces TTS reply + a concise feedback card.
- Implemented CEFR-aligned feedback templates so corrections are pedagogically meaningful, not just grammatical nitpicks.
- Designed and demoed an anonymous, turn-based table UI that stakeholders found inviting and relevant.
- Produced low-bandwidth fallbacks (short replies, text-only mode) so more students can access practice.
What we learned (technology, pedagogy, ethics)
Technical:
- Build modular integrations: keep STT, LLM, and TTS replaceable so we can swap providers as we optimize cost and accuracy.
- Short audio turns reduce ASR error and user friction — design for bite-sized practice in a game-like setup.
- SQLite is fine for prototyping, but we need transactional guarantees, concurrency and analytics scale: Postgres or RDS next.
- Use of sockets for dedicated connections.
- Use of Agentic tools like AWS Strands, Amazon AgentCore, MCP, etc.
- Group dynamics matter: anonymity and fair speaking turns dramatically increase participation from quieter students.
Ethical & operational:
- Consent, transparent retention, and human escalation are non-negotiable for student safety.
- Human-in-the-loop is essential — the system amplifies, not replaces, human mentors.
- Measure learning outcomes, not just usage.
What's next for Gup-Shup Café — pragmatic roadmap and pilot plan
Short-term pilot (0–3 months) — a concrete, measurable pilot
- Deploy to 2 campuses (select one high-connectivity and one low-connectivity) with 60–100 students total.
- Cohort & timeline:
- Pre-test (CEFR speaking rubric, mentor-scored).
- Daily 5–10 minute micro-sessions, 3× per week encouraged.
- Post-test (same CEFR rubric) and mentor assessments.
- Metrics:
- Engagement: weekly active users, average session length, retention.
- Learning: number of students reaching CI, time delta to reach C1, pre/post CEFR delta, pronunciation subscores, correct use of targeted grammar structures.
- Mentor impact: time saved, number of escalations, quality of human interventions.
Closing reflection — the human story behind the code
We built Gup-Shup Café because we wanted a safe place for our students to practice out loud without fear. The prototype shows that AI — when constrained by pedagogy, ethics and mentor oversight — can multiply mentor time and help many more girls practice the kind of corrected, scaffolded speaking that pushes learners from B2 toward C1.


Log in or sign up for Devpost to join the conversation.