-
prediction_draft2
-
prediction_result1
-
prediction_draft1
-
loss1
-
interest_rate_VS_close_prices
-
loss2
-
loss_table1
-
loss_table2
Inspiration
As the digital currency market develops, we will inevitably be involved in the torrent. We hope to use our knowledge to explore the changing trends behind digital currencies.
What it does
We hope to use LSTM models to predict the future price trend of digital currencies.
How we built it
Data is collected and preprocessed
Through the API documentation provided by the application, use URL and HTTP requests to specify the type of data we want to obtain (including Timestamp, Open, High, Low, Close) and the date range (we took the data of one year in "days" ). Then use the requests library to send a request, get the JSON format data returned by the API and save it to a CSV file.
Through the function "preprocess_data", we process the time series data into a format suitable for training an LSTM (Long Short-Term Memory Network) model:
We extract features and targets and normalize the feature data by instantiating a MinMaxScaler object and fit_transform. Then create a time step for the LSTM model to ensure that each feature data "X[i]" corresponds to a target variable "y[i]". Finally, use the train_test_split function to divide the training set and the test set, and the proportion of the test set is initially set to 80%. And set random seeds before partitioning and scramble the data to ensure the reproducibility of each partitioning result.
It returns the features and targets of the divided training and test sets, which will be used to train the LSTM model and evaluate model performance.
Finally, we use the LSTM model to train the preprocessed data and visualize the final results.
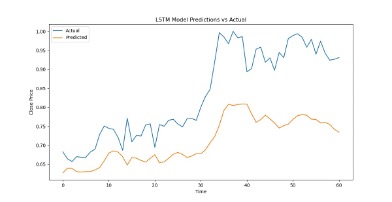
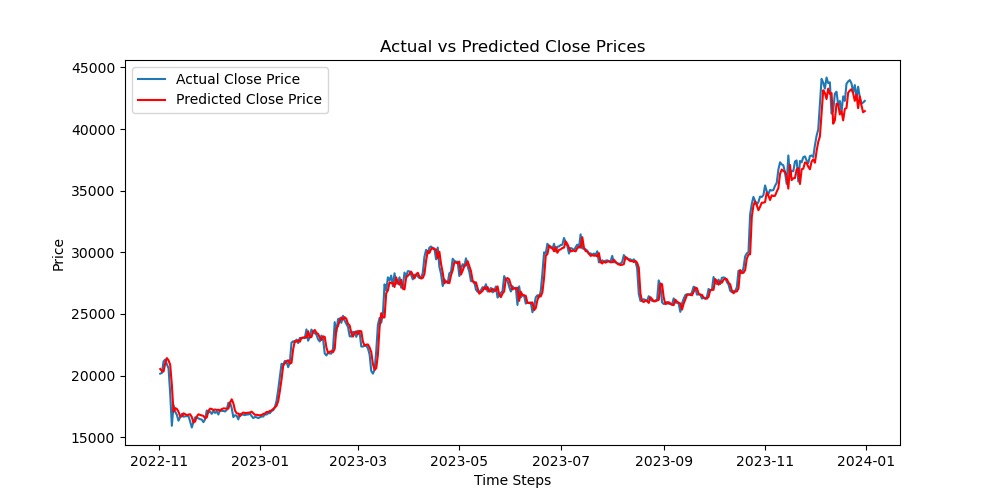
Model implementation is complete or nearly complete We used the “closing price” in the training set, brought the data into the LSTM model, and obtained a prediction result. Imgur After that, we tried to consider non-price factors. We used the "interest rate" announced by the Federal Reserve and introduced it into the LSTM model to make the model richer, more reasonable, and more applicable to real-life situations. Imgur Imgur Imgur Imgur
Challenges we ran into
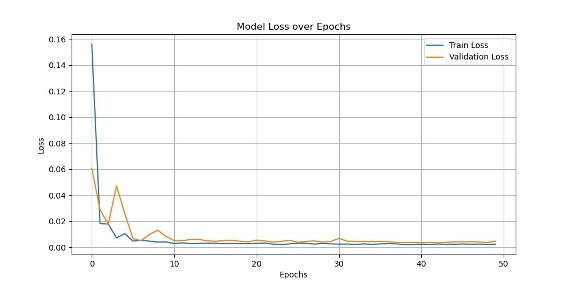
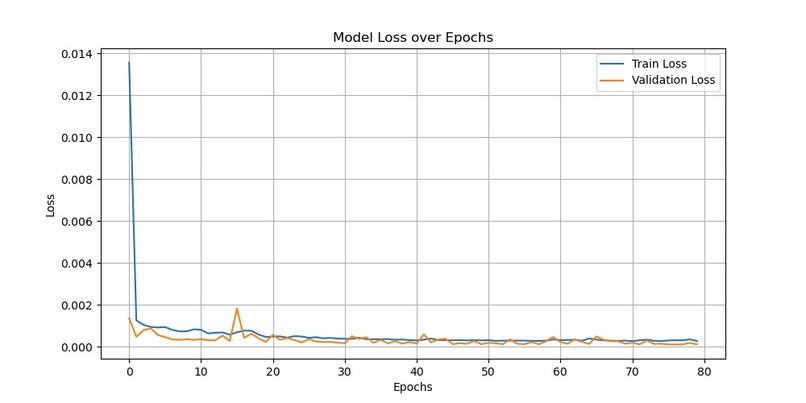
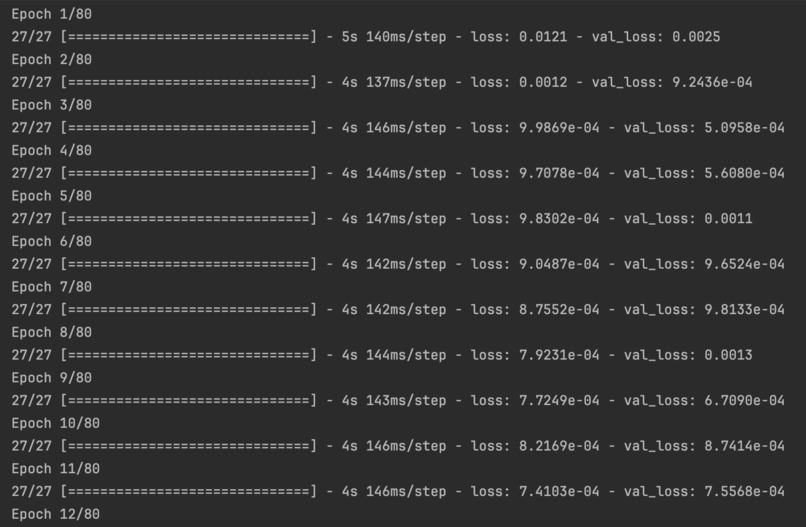
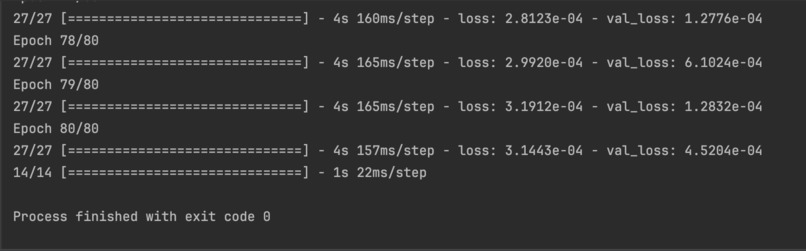
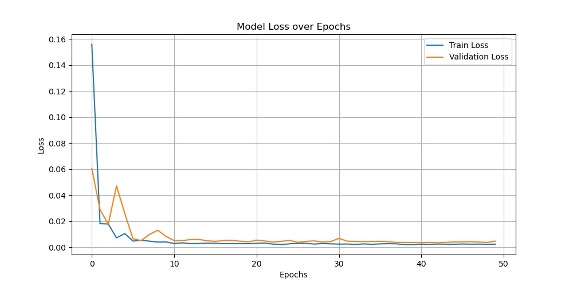
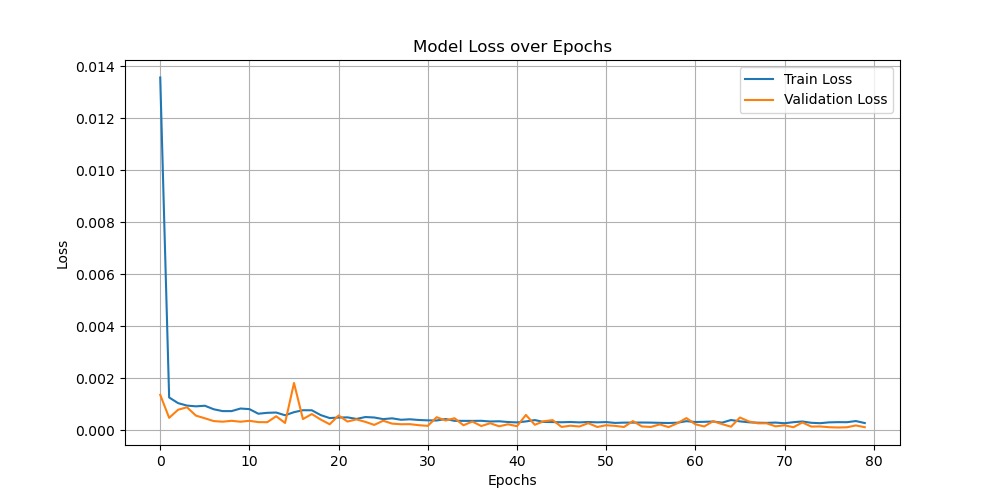
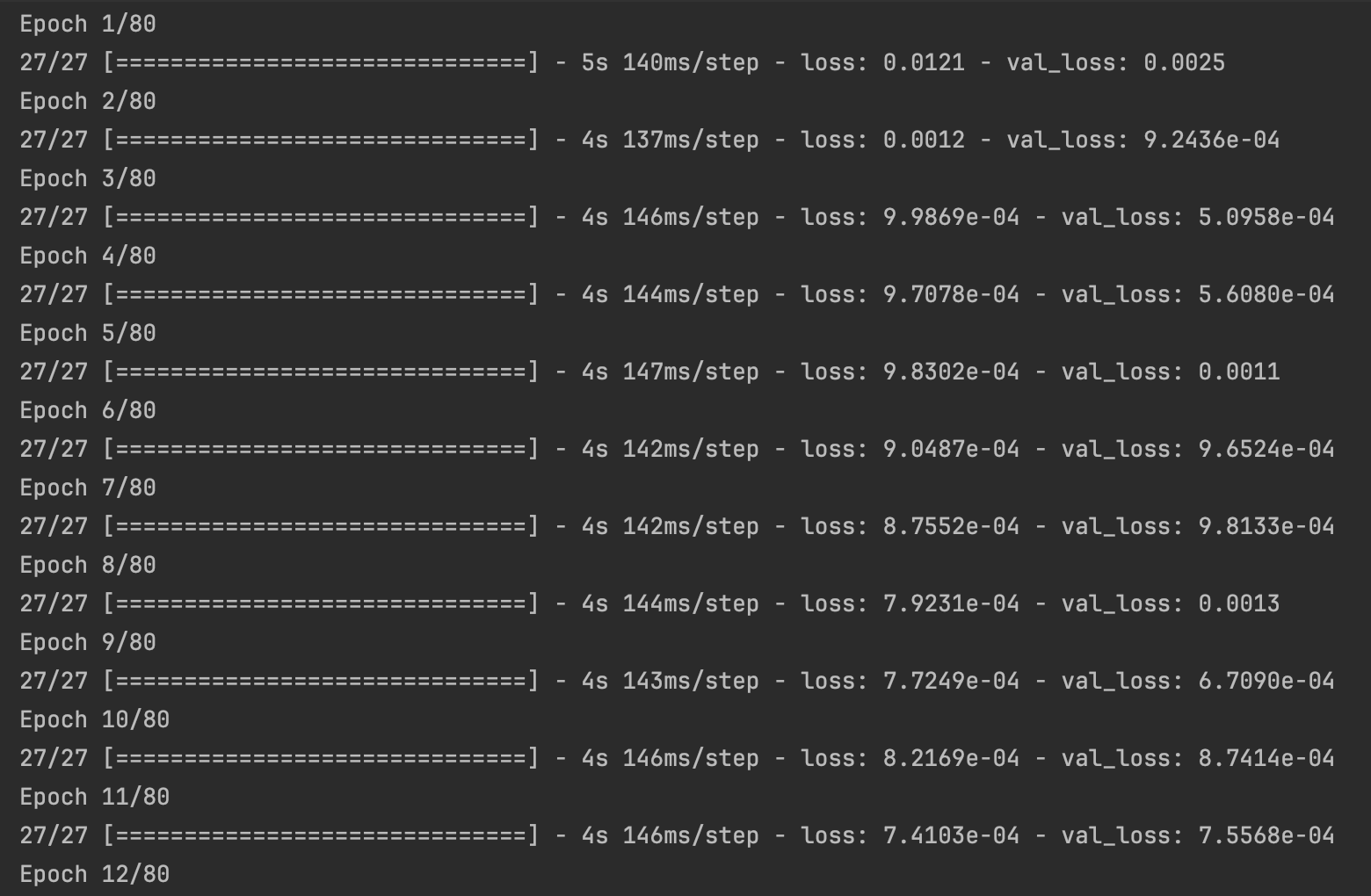
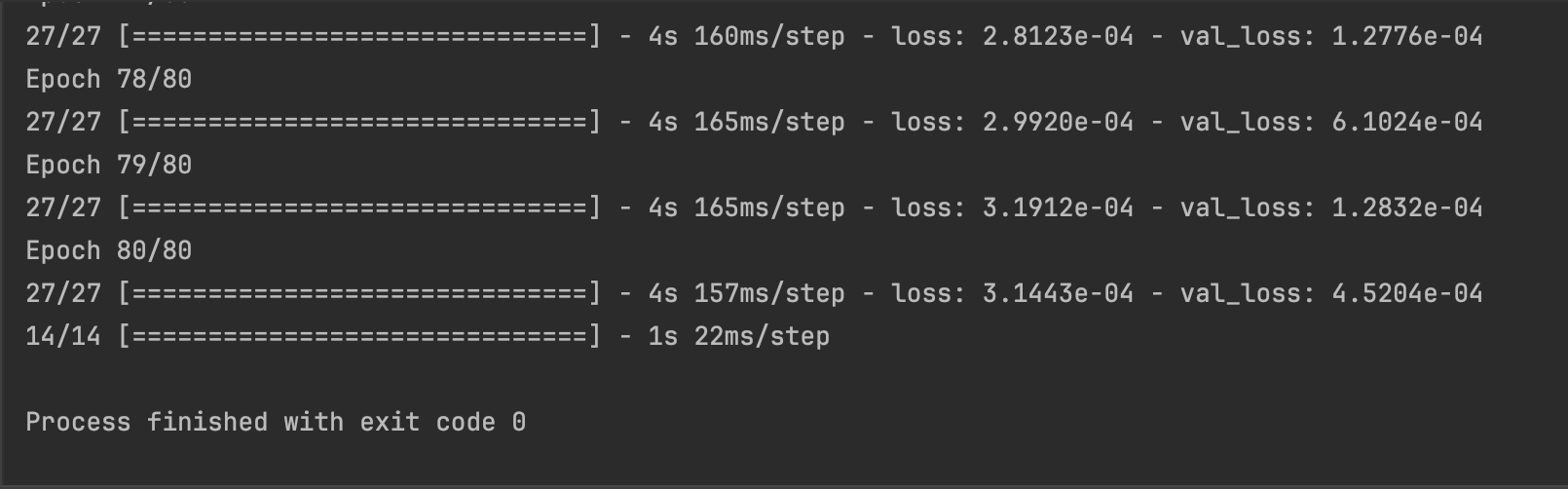
During our initial training, the loss was very large, even hundreds of millions. We try to regularize the target, and the loss is significantly reduced. And after visualizing the loss results, we found that this is in line with the ideal situation. Imgur
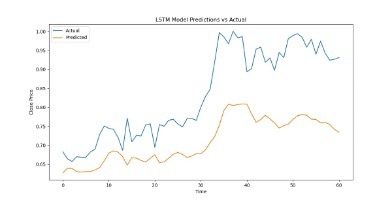
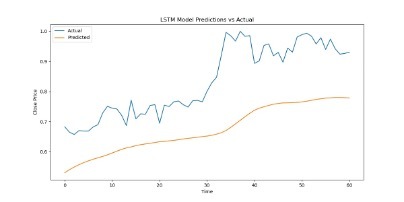
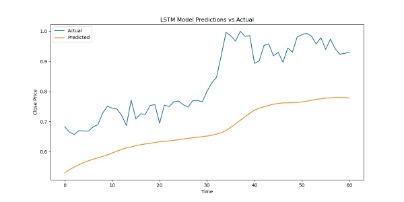
And when we output the test results, we found that the results were in an overfit state, so we added a dropout layer to solve the problem. For the problem of poor visualization of the fitting results, it is because the closing price data of train was regularized, but the closing price data of test was not. Therefore, we also regularized the data in the test set. Besides, we increased the number of training times and found that the effect would improve. Imgur Imgur Imgur
Accomplishments that we're proud of
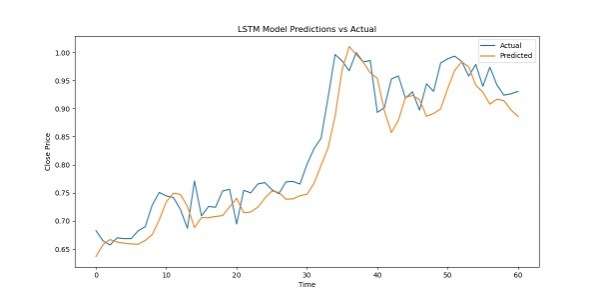
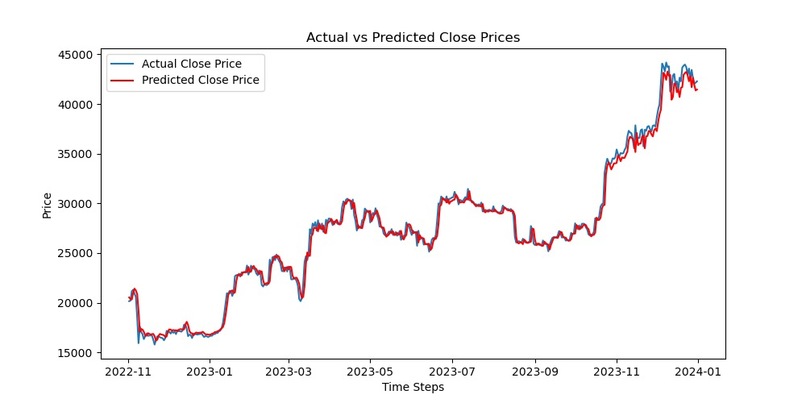
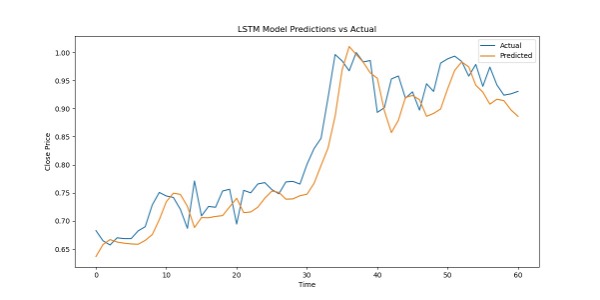
This is our prediction of future "closing price" based on historical " Open, High, Low, Closing price" data: Imgur
After that, we try to consider non-price factors, specific policy reasons were initially considered, but due to the short time, it was difficult to quantitatively integrate the policy into the model. Therefore, we used the "interest rate" published by the Federal Reserve. And we perform data cleaning: complete the ND data with the previous day's data. And since markets are closed over the weekend, there is no data, but that is not the case with digital currencies. We insert two rows of Friday's "interest rate" after each "Friday" to match the data format of the "seven days" of the week. Imgur
What we learned
Through this project, we learned the importance of preprocessing and feature selection in machine learning. Adjusting activation functions, such as switching between softmax and relu, yielded varied results, highlighting the sensitivity of neural networks to function choices. Our experiences also underscored the challenges of integrating non-price factors like interest rates into predictive models, necessitating innovative approaches to data integration and cleaning.
What's next for project
We will continue to work on finding feasible relevant policy data, quantifying it and introducing it into our optimized LSTM model. At the same time, we will also try to change the model architecture to further improve the comprehensiveness and accuracy of model predictions.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Log in or sign up for Devpost to join the conversation.