-
-
Home
-
How It Works
-
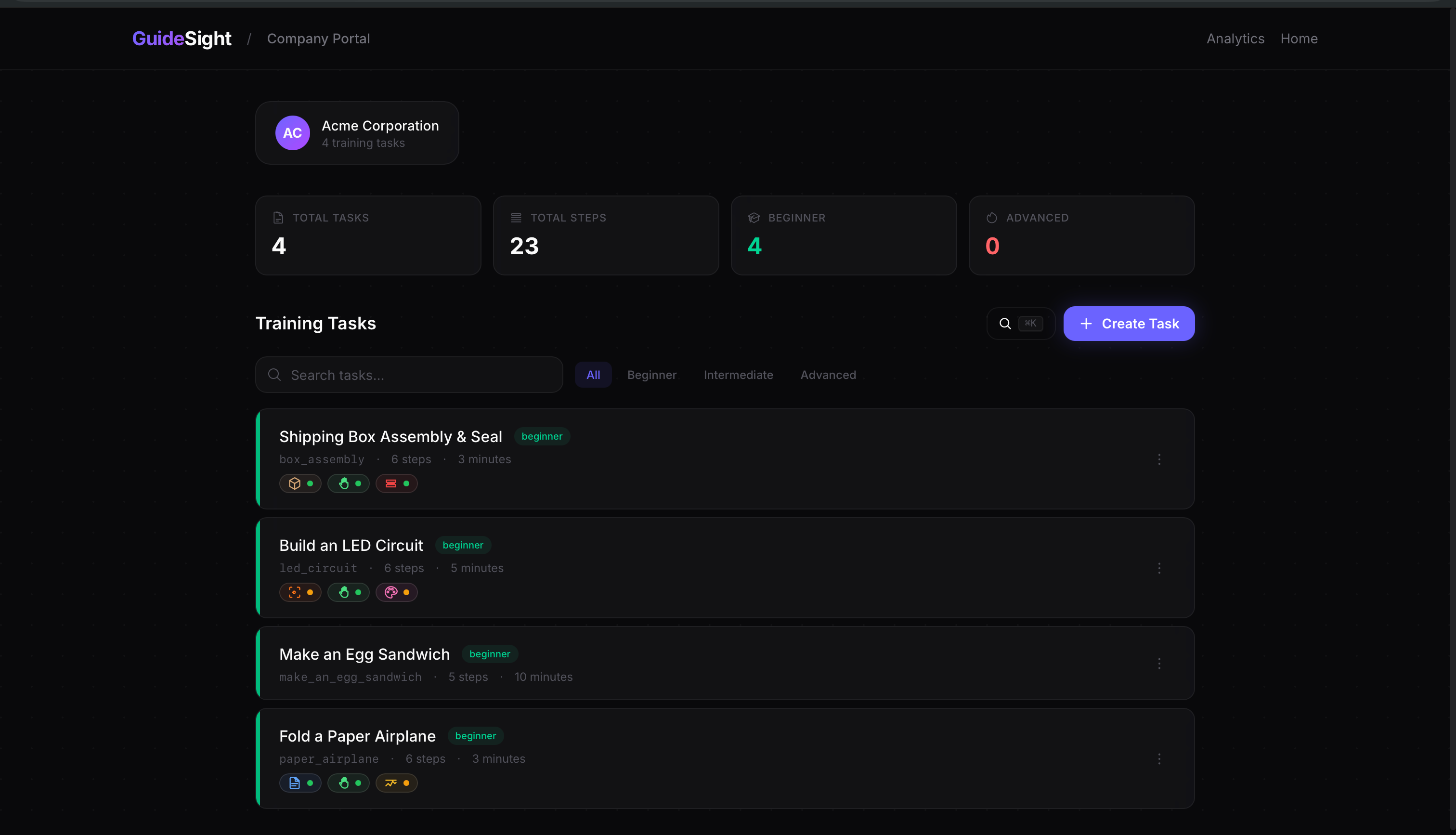
Admin Dashboard
-
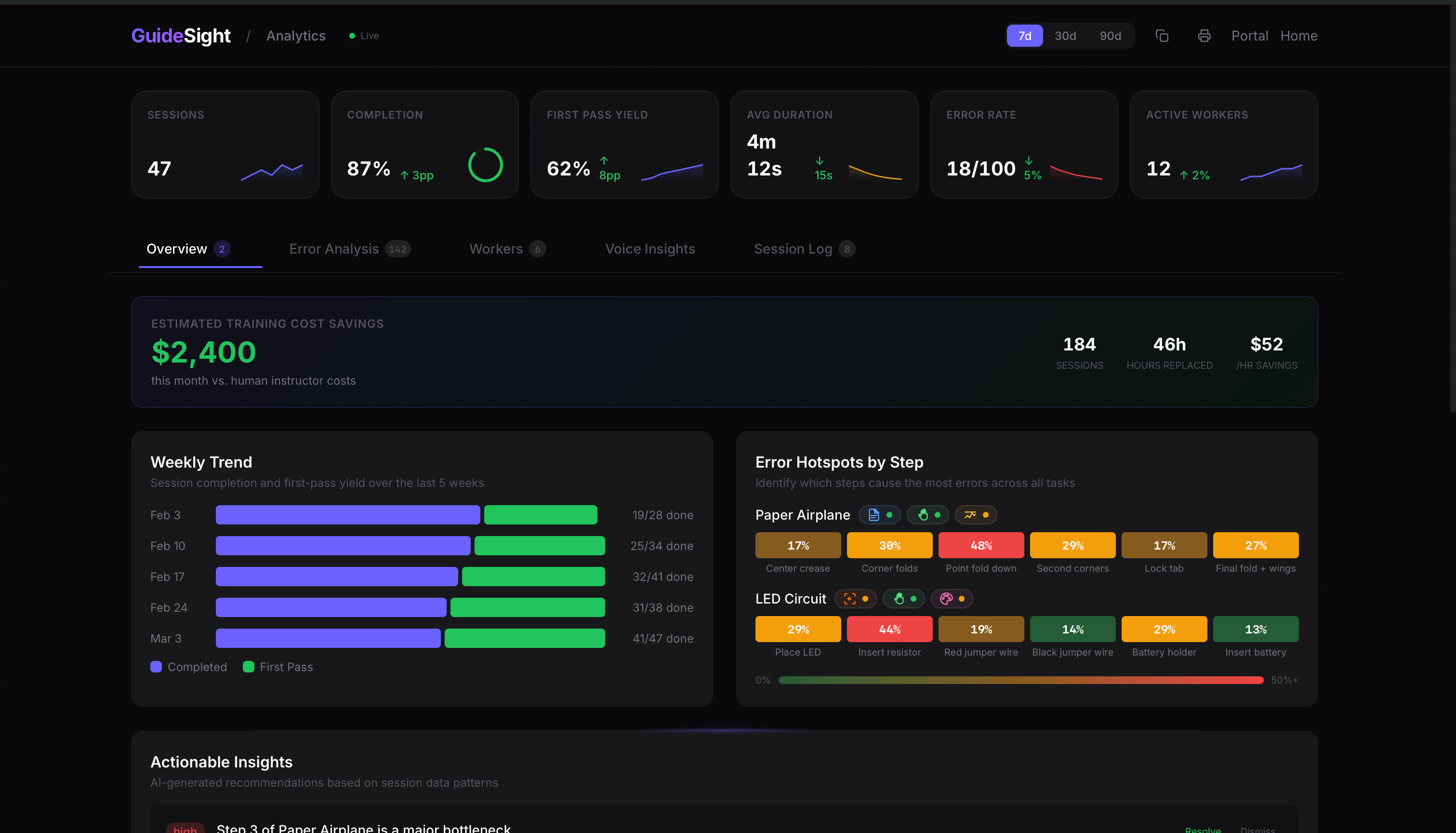
Analytics Dashboard
Inspiration
I worked in an Amazon warehouse last summer. My training was two days of watching videos, then I was on the floor. I was lucky, as a student they put me on easier tasks, so I didn't get hurt. But I watched coworkers who weren't as lucky. They'd been given the same rushed training, thrown into physically demanding roles, and within weeks some of them were injured. Back injuries from lifting wrong. Repetitive strain from packing technique nobody corrected. They'd miss shifts, fall behind, and eventually quit. Then the cycle started over with the next new hire.
That experience stuck with me. When I started researching the problem, the numbers confirmed what I'd seen firsthand: 40% of warehouse injuries happen in a worker's first 90 days. 60% of warehouse turnover happens in the same 90 days. That's not a coincidence; it's a training problem. Each worker who quits costs $10,000 to replace. A 100-person warehouse loses $450,000 a year just on turnover. And there are 370,000 warehouse jobs sitting unfilled right now.
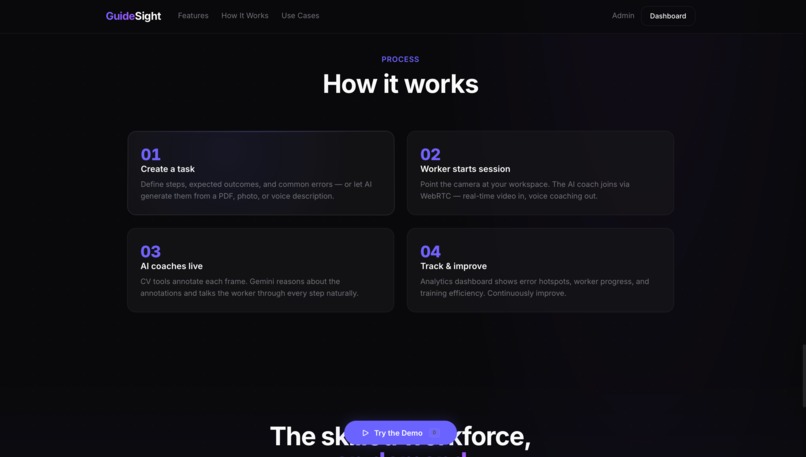
The existing solutions (training manuals, instructional videos, platforms like Squint and DeepHow) are all static. They show you what to do, then walk away. None of them can see whether you're actually doing it right. The real solution is a human coach watching every worker, but that doesn't scale. So I built an AI that does exactly what a human coach would do.
What it does
GuideSight is a real-time AI coach that sees through the worker's camera and talks them through physical tasks. It watches their hands, checks their technique, catches mistakes before they become injuries, and verifies every step is done correctly. No buttons, no turn-taking, continuous bidirectional voice and vision.
How we built it
Gemini 2.5 Flash Live API for real-time bidirectional audio+video coaching. Claude as an independent visual gatekeeper — every time Gemini tries to advance a step, the current frame goes to Claude for verification to prevent hallucinated completions. OpenCV + MediaPipe for hand tracking annotations. Stream Video SDK for WebRTC transport. React + TypeScript frontend with a live AI pipeline debug panel. Flask token server. All three services deployed on Google Cloud Run.
Challenges we ran into
- Gemini confirmation bias: the AI confirmed what the task said SHOULD happen instead of what it ACTUALLY saw. Solved with Claude as an independent visual verifier — "Gemini coaches, Claude verifies."
- Low-resolution WebRTC frames: the agent received 480x360 frames making spatial details hard to verify. Improved with higher quality JPEG encoding and resolution constraints.
- 2-minute video session limit: Hard Gemini Live API constraint. Solved with automatic session resumption.
- Step skipping: Gemini would jump ahead to later steps. Solved with sequential enforcement — can only complete the current step.
Key insight
Gemini is great at reasoning and conversation but hallucinates spatial details. Rather than fighting this with prompting, we added an independent verification layer. The same principle as having a supervisor double-check a trainee's work.
Accomplishments that we're proud of
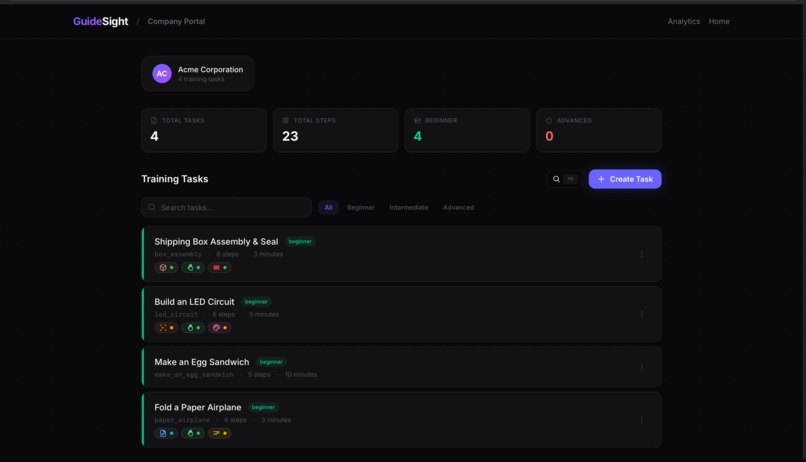
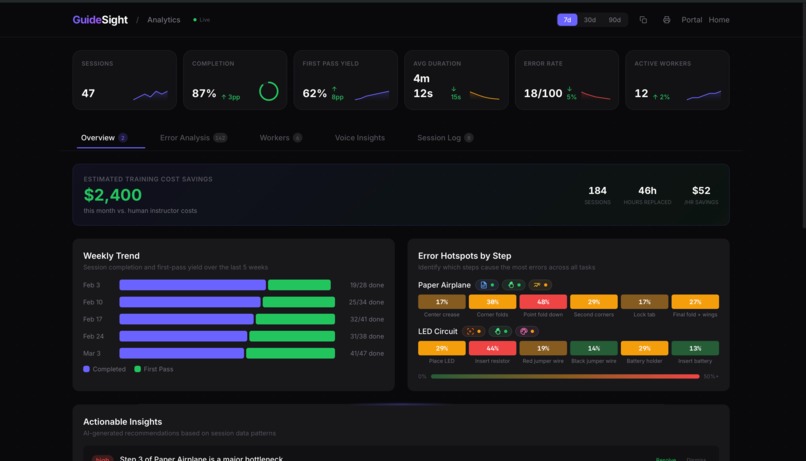
Real-time coaching that catches real mistakes — demonstrated by intentionally folding the wrong box flaps and having the verification layer reject the step. Task authoring system lets warehouse managers define any task. Analytics dashboard shows which steps workers struggle with most.
What we learned
Multimodal AI needs checks and balances. A single model coaching and verifying its own work will hallucinate. Splitting the roles, one model for real-time coaching, another for visual verification, produces reliable results.
Current limitations
- Verification latency: Each step verification takes 2-3 seconds as the frame is sent to Claude for analysis. In a fast-paced warehouse environment, this delay can feel slow. Optimizations like caching common visual patterns and reducing image payload size would bring this down.
- Camera angle sensitivity: The verification model sometimes struggles to confirm steps when the worker holds the object at an angle that doesn't clearly show the relevant detail. Prompting the worker to show their work more directly helps, but a production system would need to be more forgiving of natural camera positions.
- Gemini 2-minute session limit: The Gemini Live API drops video+audio connections after roughly 2 minutes. Our session resumption handles this transparently, but there's a brief interruption in coaching during reconnection.
These are engineering problems, not architectural ones. The core approach (real-time coaching with independent verification) works. With more testing and iteration, each of these can be tightened.
What's next for GuideSight
More task types for warehouse operations (palletizing, equipment maintenance, quality inspection). Wearable camera integration for hands-free coaching. Enterprise analytics for training gap identification.
Built With
- claude-(anthropic)
- flask
- gemini-2.5-flash
- google-cloud-run
- google-genai-sdk
- mediapipe
- opencv
- python
- react
- stream-video-sdk
- tailwind-css
- typescript
- vision-agents-(getstream)
- vite

Log in or sign up for Devpost to join the conversation.