

Inspiration
The FDA's adverse event database has over 11.5 million serious drug interaction reports. We ran a live query and searched for warfarin + ibuprofen four different ways — generic names, brand names, salt forms, and natural language. The same two drugs returned results ranging from 1,532 down to 1. It was clear that the drug interaction systems lacked standardization and we wanted to solve this.
What it does
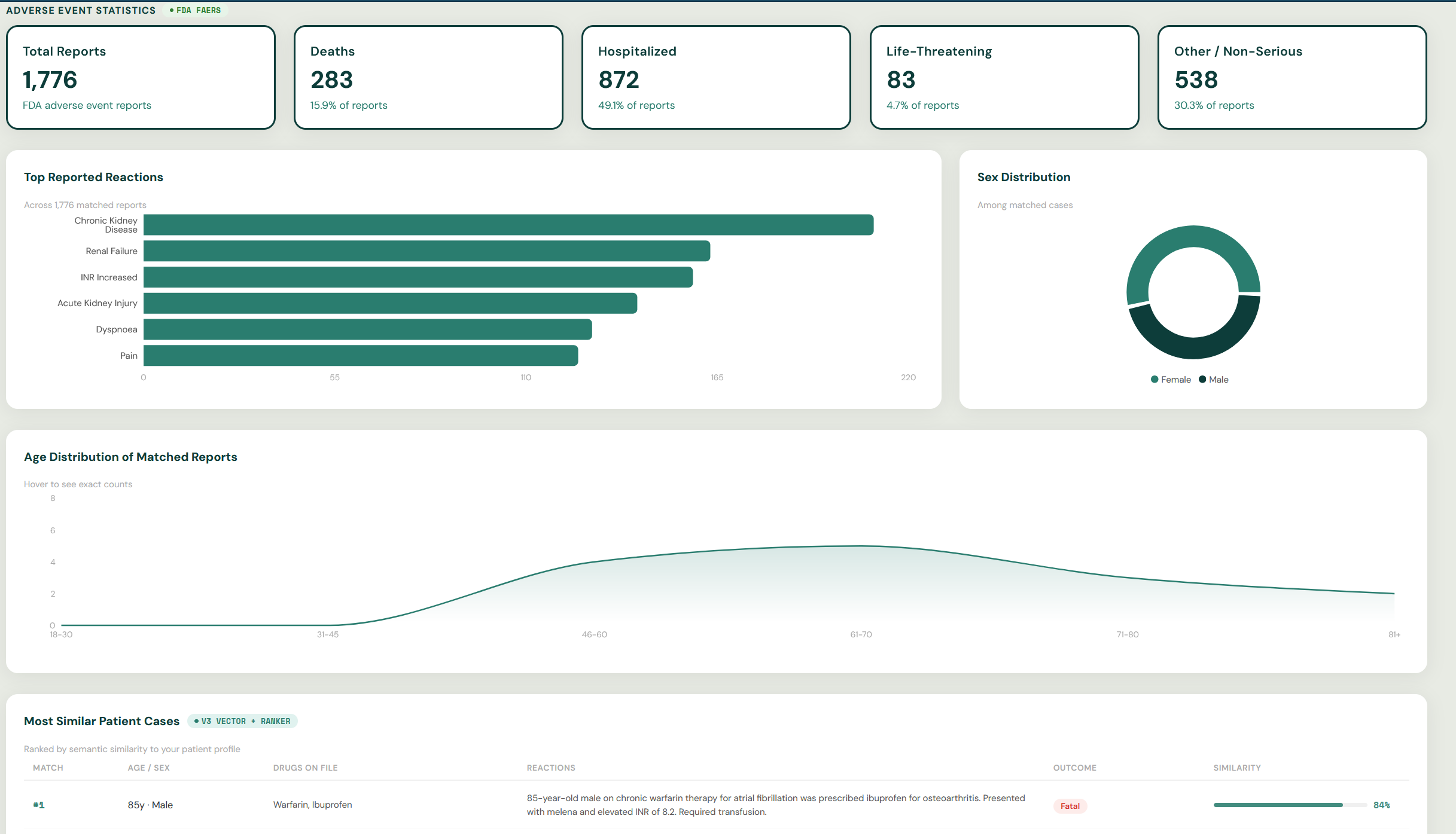
RxGuard is a semantic search engine over the FDA's Adverse Event Reporting System (FAERS). It lets drug safety researchers and clinical pharmacists investigate medication interaction signals using natural language — no medical terminology required. Instead of keyword matching, RxGuard understands that "Coumadin," "warfarin," and "blood thinner" all mean the same thing, surfacing cases that traditional search misses entirely. It returns a full signal investigation report: case counts, a , the five most semantically similar real FAERS case reports ranked by cosine similarity, and a side-by-side comparison showing exactly how much keyword search leaves on the table.
How we built it
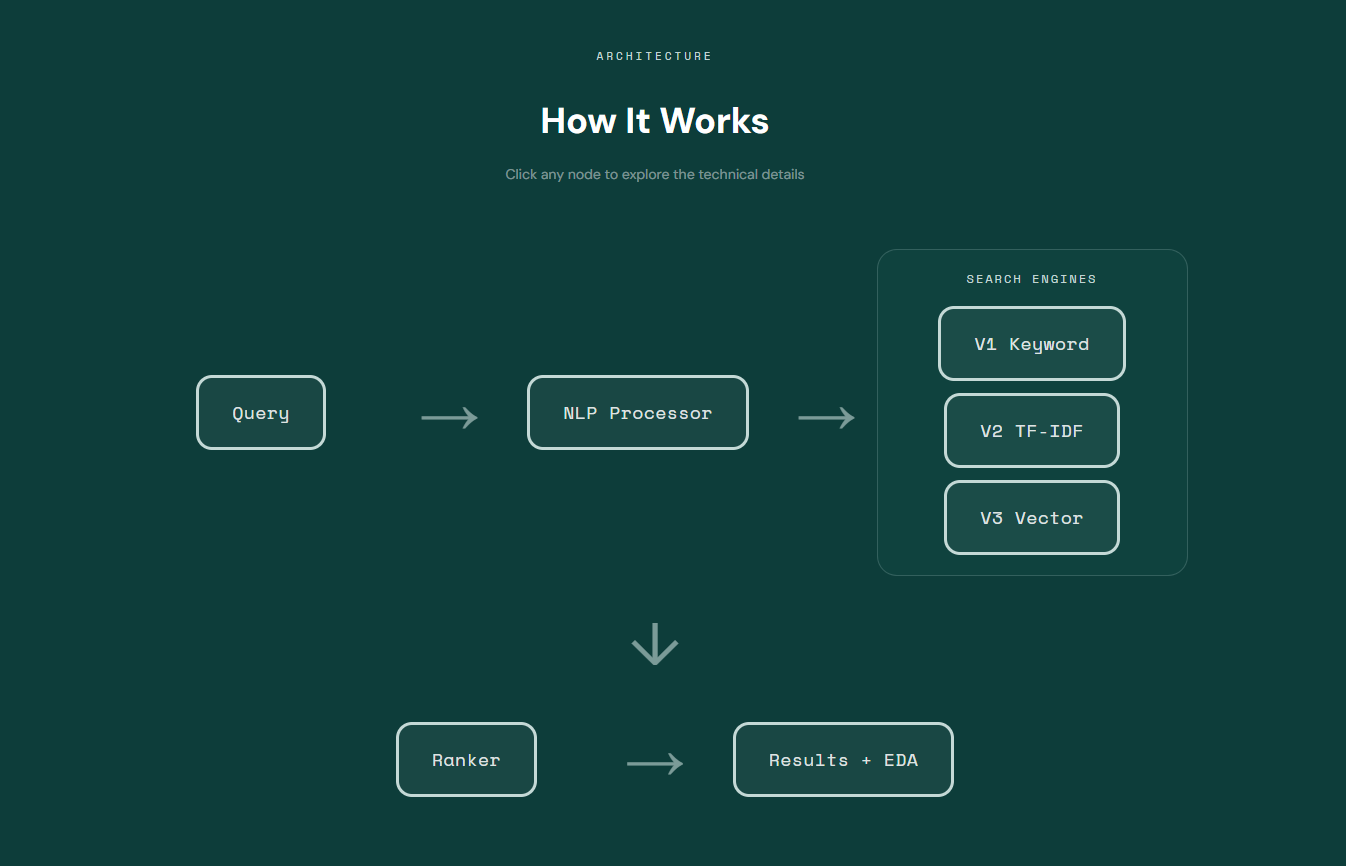
We built a four-stage data pipeline: pulling serious adverse event reports from the openFDA API across 70 high-risk drug classes, cleaning and normalizing drug names across brand names, generics, salt forms and misspellings, embedding all report narratives as 384-dimensional dense vectors using sentence-transformers, and loading them into a ChromaDB vector store designed for Actian VectorAI DB deployment. The frontend is Streamlit. Signal quantification uses the Reporting Odds Ratio, a standard pharmacovigilance disproportionality metric. The full stack is React and Python, with Sphinx Copilot handling exploratory data analysis and statistical validation.
Challenges we ran into
FAERS is messier than any documentation suggests. The same drug appears under dozens of name variants, salt forms, foreign spellings, and typographical errors across 11.5 million reports. Building a normalization pipeline robust enough to handle all of these without silently dropping edge cases took significant iteration. MedDRA terminology added another layer — American researchers searching "gastrointestinal hemorrhage" get zero results because the correct MedDRA term uses British spelling. Every layer of vocabulary mismatch we fixed revealed another one underneath it.
Accomplishments that we're proud of
We were able to vectorize medical data which had numerous variables in it and still able to semantically search for top matches from the dataset accurately. Integrated contextual RAG over the FDA Adverse Event Reporting System to retrieve historically similar cases using: Current medications, Pre-existing conditions, and Newly prescribed drug. We also avoided black-box AI patterns in a safety-critical domain, by showing similar cases, as well as directly pulling metrics from real data.
What we learned
Keyword search doesn't just return fewer results — it returns a systematically biased subset, and the bias is invisible to the researcher. Nobody knows what they're missing because the missing cases never appear. We also learned that the ingredients for this solution have existed for years sentence transformers, vector databases, the openFDA API. The problem wasn't technical. It was that nobody had connected them to this specific use case. Sometimes the most impactful thing you can build at a hackathon isn't a new technology, it's applying existing ones somewhere they've never been pointed.
What's next for RxGuard
Expanding coverage to the full FAERS database beyond the current 70 drug classes. Adding patient-profile-filtered search so a clinician can ask for cases matching a specific patient — elderly, renally impaired, on four concurrent medications. Incorporating regimen-level analysis that looks at triplet and quadruplet drug combinations, not just pairs. Longer term, on-premises hospital deployment where HIPAA compliance requires that patient medication queries never leave the network — which is exactly the architecture Actian VectorAI DB was built for.



Log in or sign up for Devpost to join the conversation.