-
-
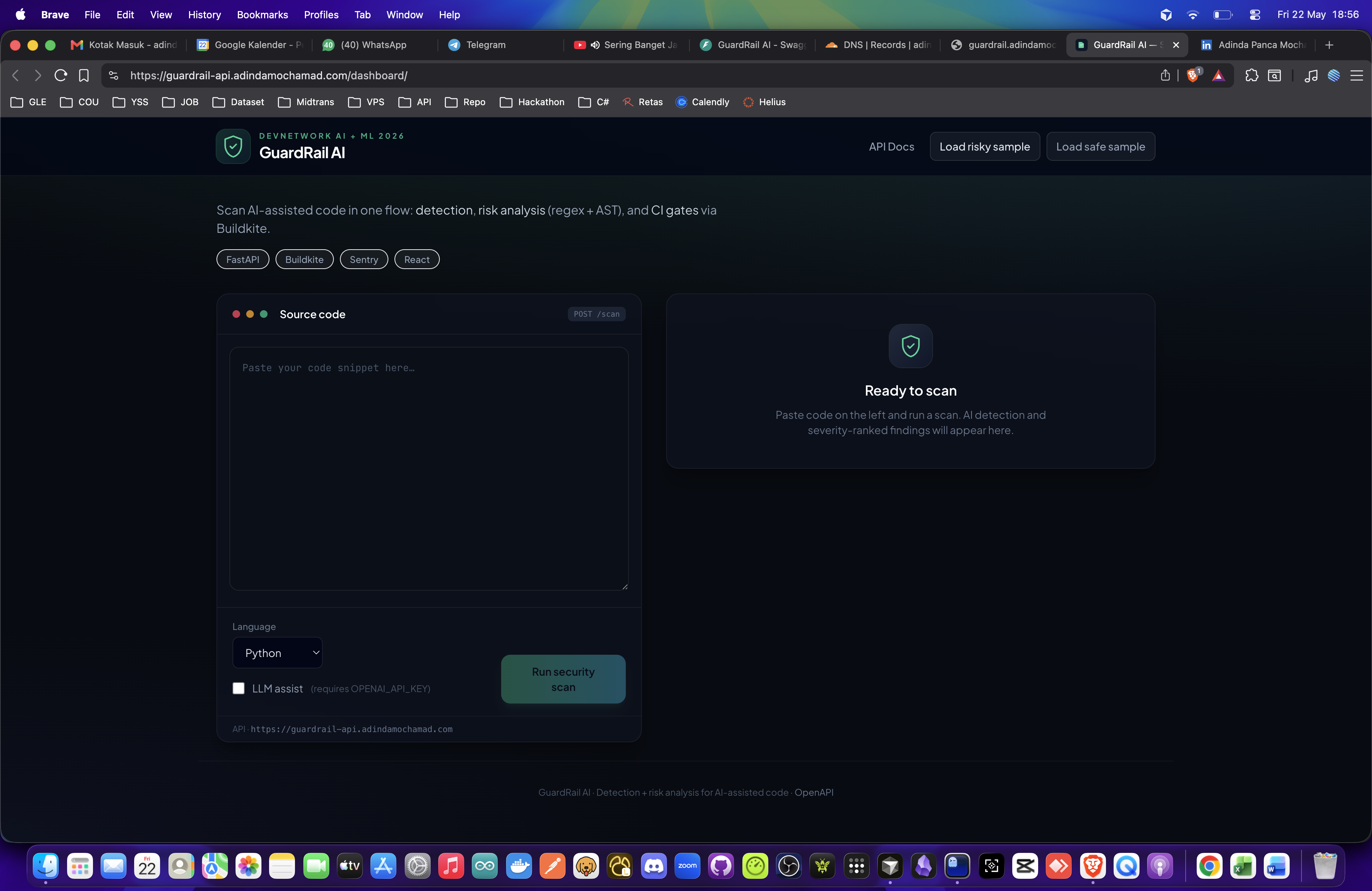
Dashboard — ready / empty editor
-
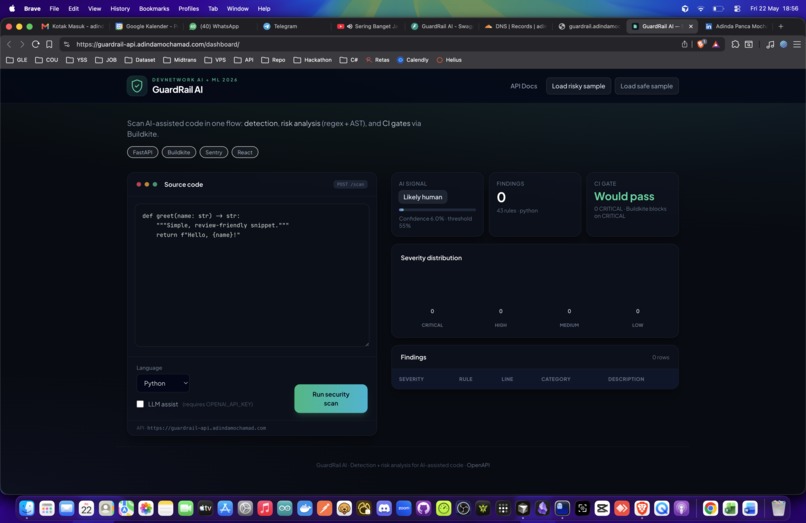
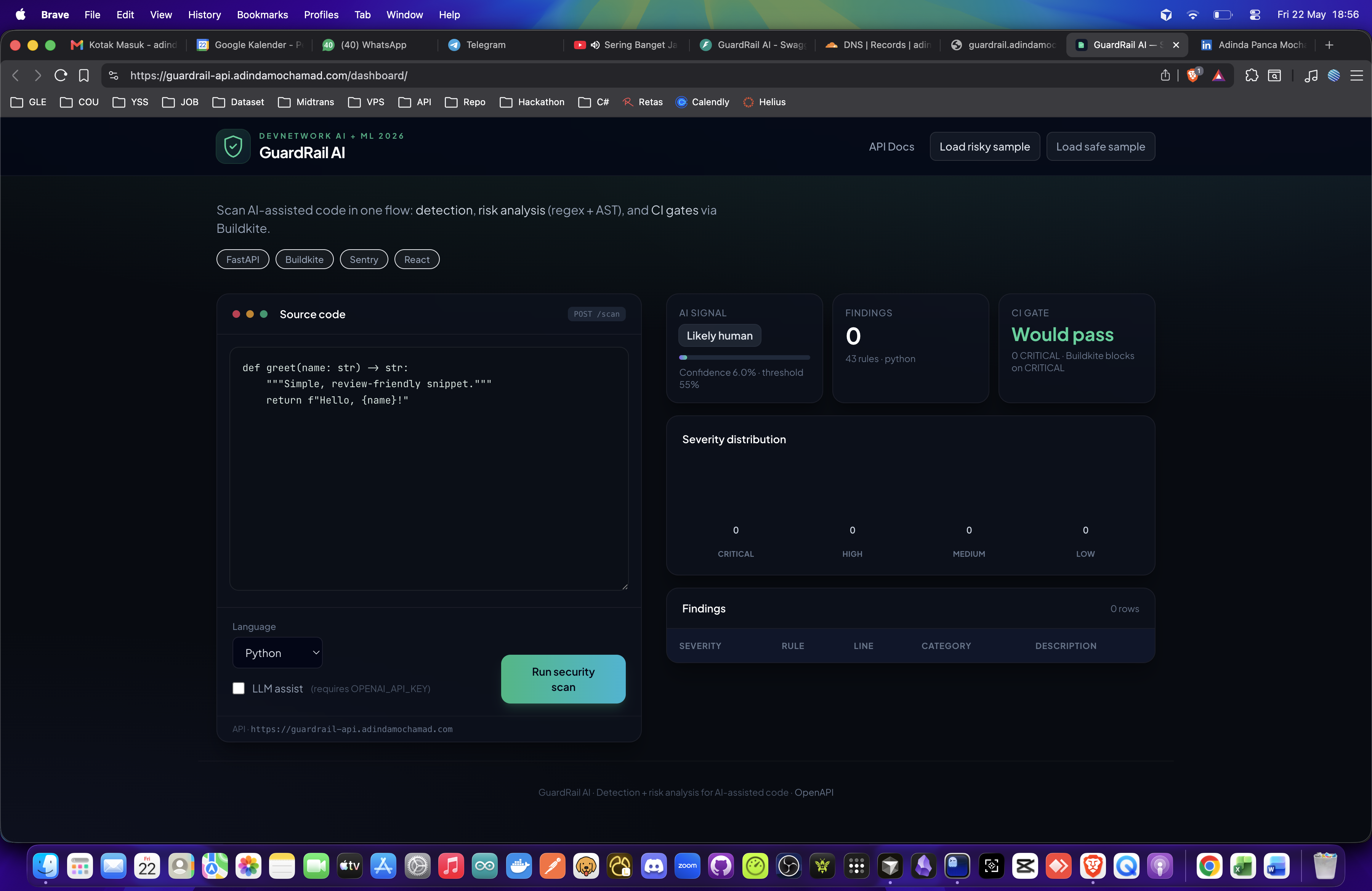
After scan — AI signal + severity chart
-
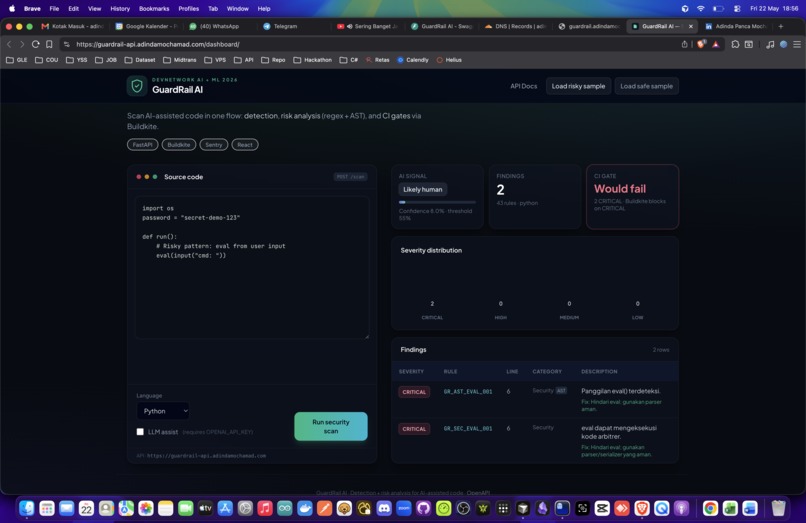
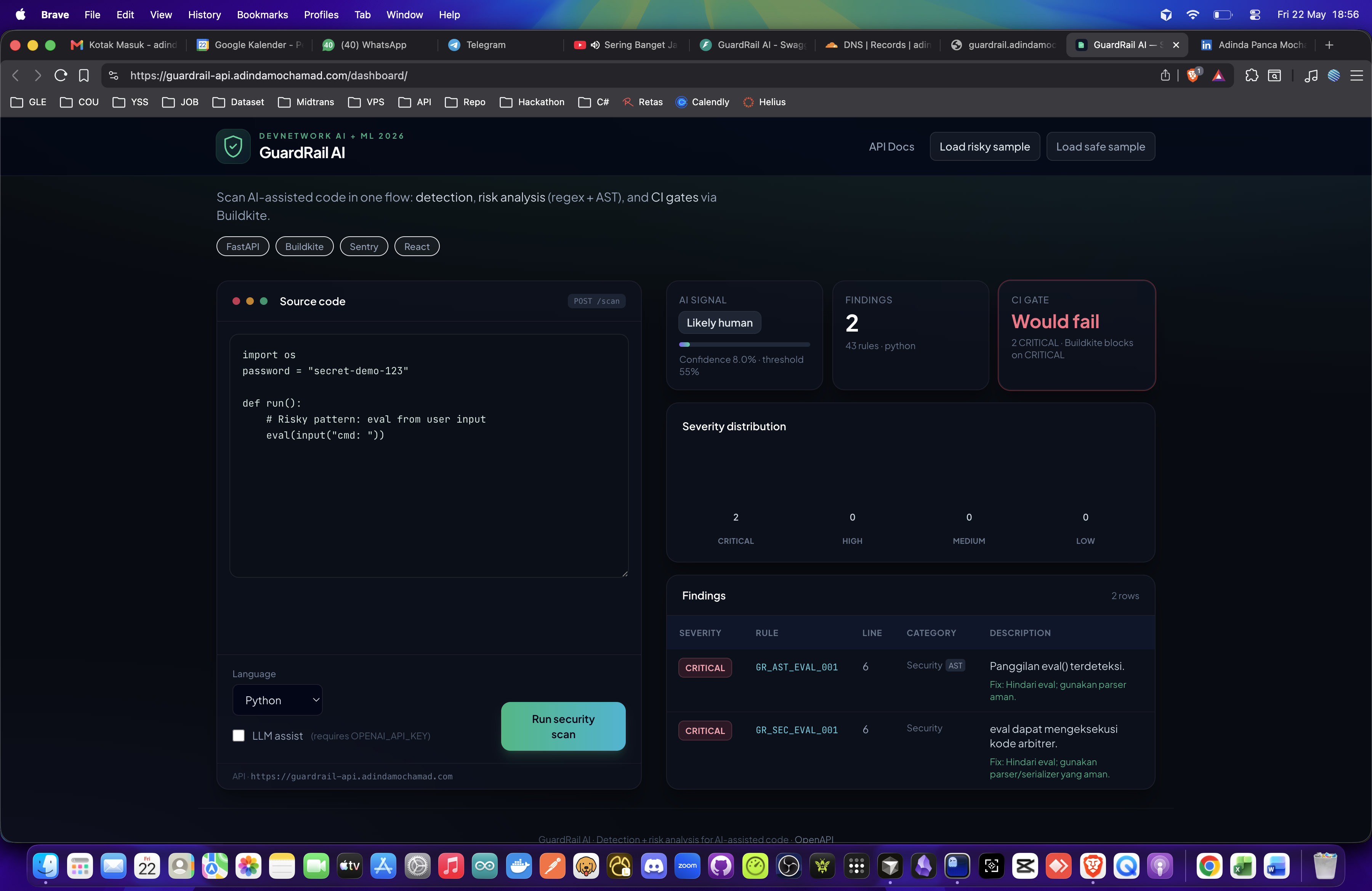
Findings table — CRITICAL row
-
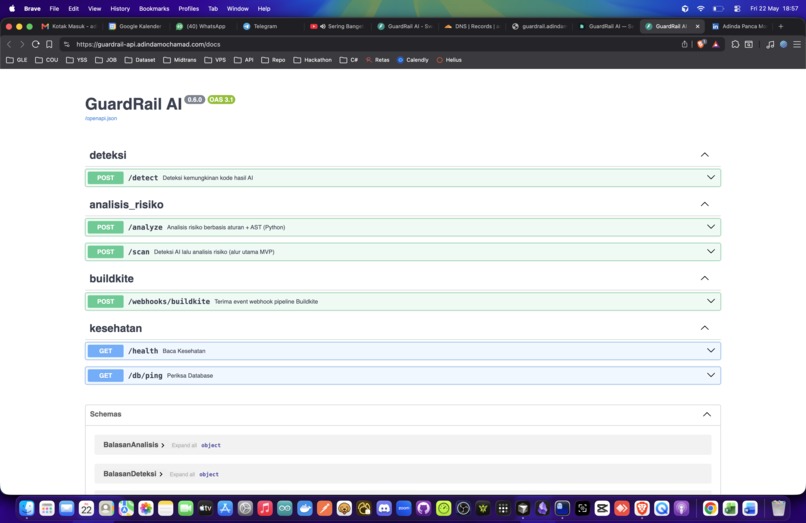
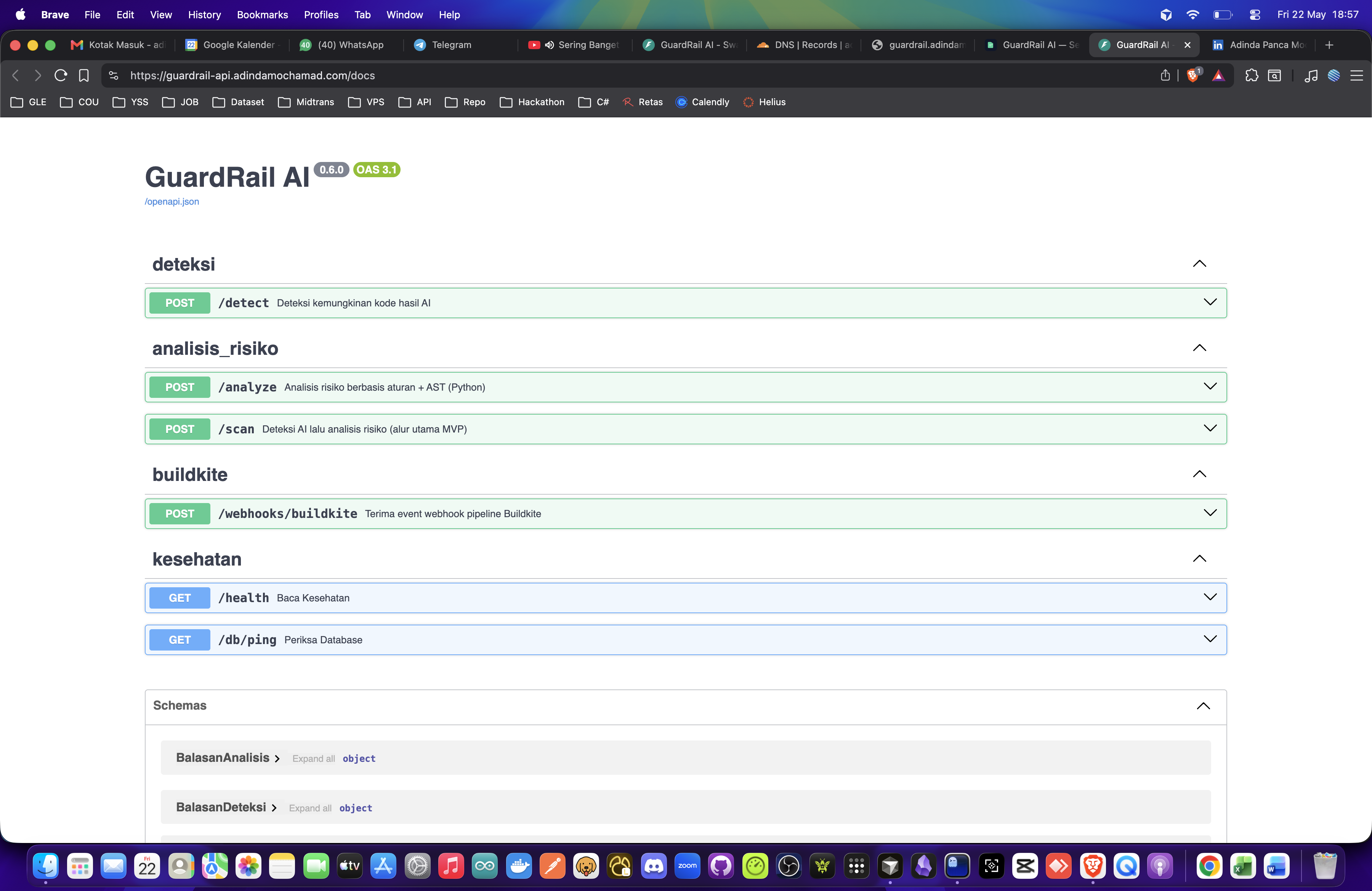
Swagger /docs
-
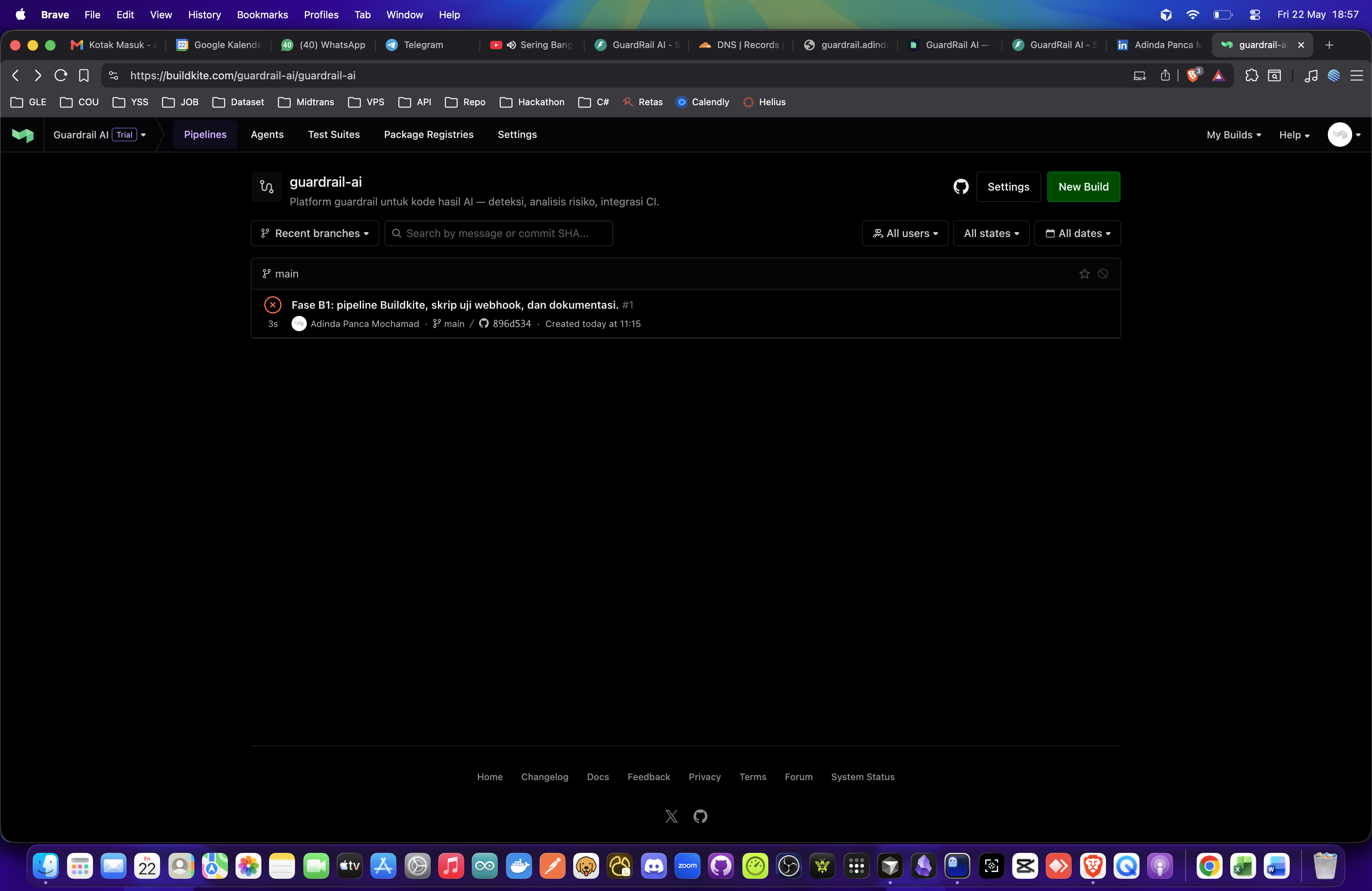
Buildkite — failed step + log
Inspiration
More production code is written with Copilot, Cursor, and similar tools—often merged with less review than human-written changes. Classic SAST tools were not designed for “AI-shaped” code or commit metadata like co-author trailers. We built GuardRail AI to add a focused gate: detect likely AI authorship, run tailored security analysis, and fail CI when CRITICAL risks appear.
What it does
- Detect whether a snippet is likely AI-generated (heuristics, optional commit signals, optional LLM).
- Analyze with 30+ regex rules and Python AST checks, including rules tuned when code is treated as AI-generated.
- Scan end-to-end via
POST /scan(React dashboard + public API). - Buildkite integration: pipeline
guardrail-airunsscripts/guardrail_ci_scan.sh; our production build failed with CRITICAL=3 (exit 1) when calling/scan—demonstrated in screenshots. - Observability: Sentry in production for runtime errors.
How we built it
- Backend: FastAPI, SQLAlchemy, SQLite, pytest (39 tests), ruff.
- Frontend: React, TypeScript, Vite, Tailwind—English dashboard calling the public API.
- Deploy: VPS + nginx; API at
guardrail-api.adindamochamad.com, dashboard at/dashboard/. - Quality:
make qa— lint, tests, and production frontend build.
Challenges we faced
- Multi-service VPS layout (API on port 8008 behind nginx).
- CORS for separate dashboard origin.
- Two Buildkite paths: webhook annotations vs hard CI fail via exit code—we implemented and documented both.
- Honest metrics: mini eval on 8 labeled samples (62.5% accuracy, 100% precision, 25% recall)—not marketed as 85%+ without more data.
What we're proud of
- Live demo judges can try in the browser.
- Buildkite proof: red pipeline step on CRITICAL findings.
- Open API: Swagger
/docsforPOST /scan. - 39 automated tests and reproducible eval script in the repo.
What we learned
Labeled evaluation must come before strong accuracy claims. A single /scan endpoint keeps the dashboard and CI consistent. Sponsor tech (Buildkite) needs a demonstrated run, not only README text.
What's next
- Larger labeled dataset and optional LLM in CI.
- Persist scan history for AI vs human trends.
- Hud.io SDK when access is available.
Impact
Teams can block eval, unsafe exec, and similar patterns before merge when adopting AI-assisted development workflows.
Built With
- buildkite
- fastapi
- nginx
- openai
- pytest
- python
- react
- ruff
- sentry
- sqlalchemy
- tailwindcss
- typescript
- vite


Log in or sign up for Devpost to join the conversation.