-
-
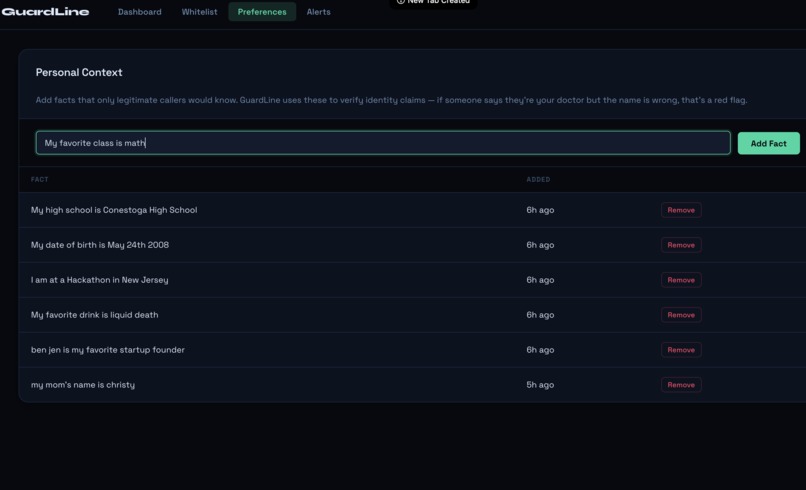
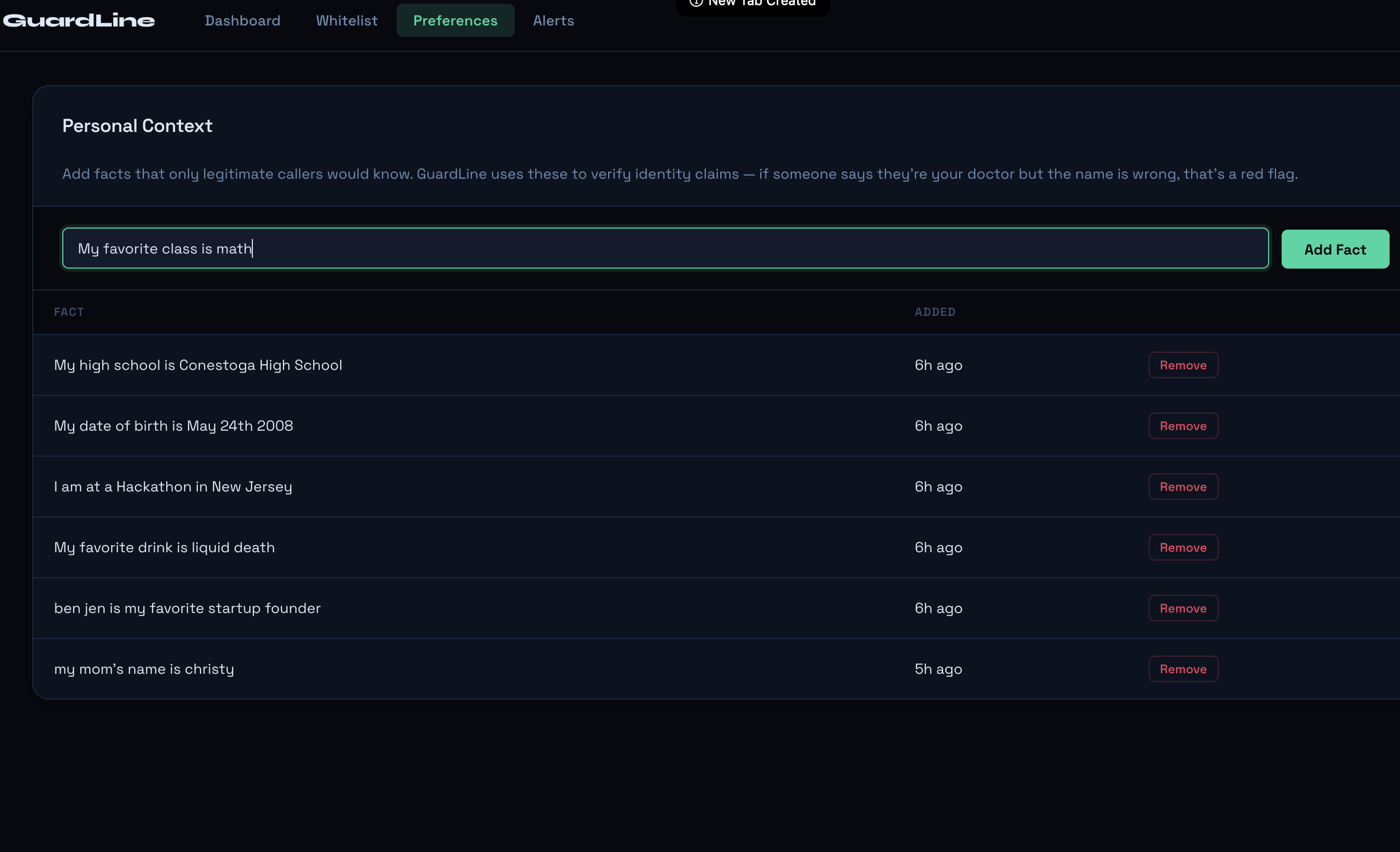
adding to the personal information/context
-
main website - sign up
-
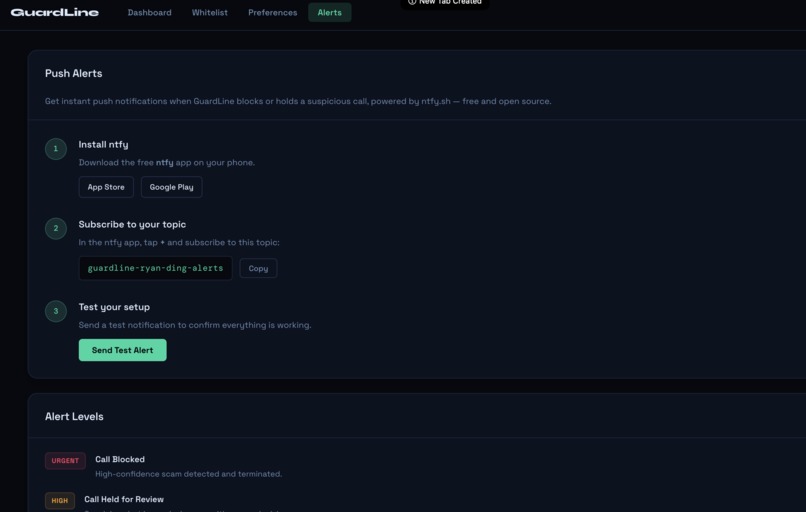
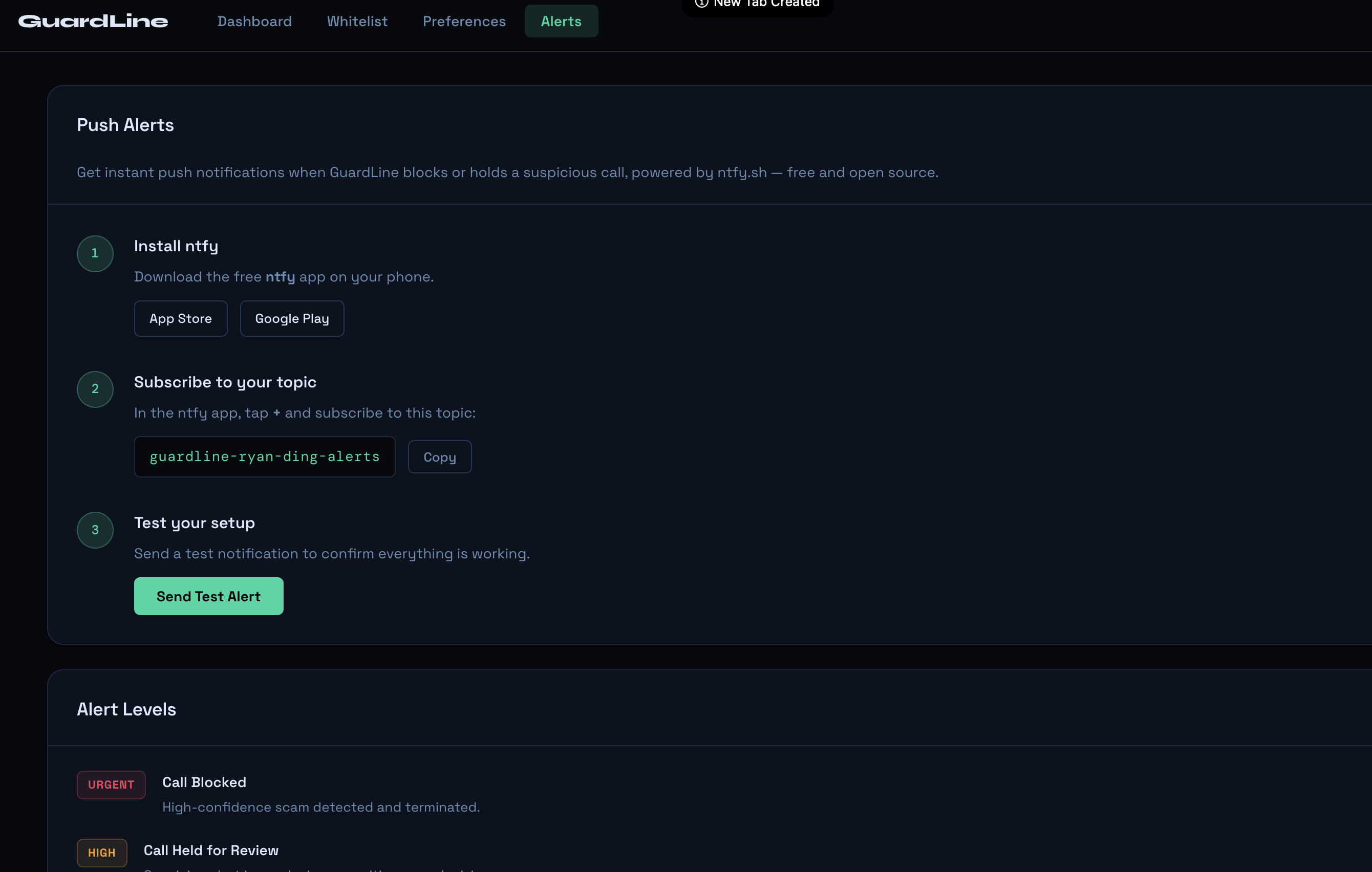
installing ntfy (notify app for loved one alerts)
-
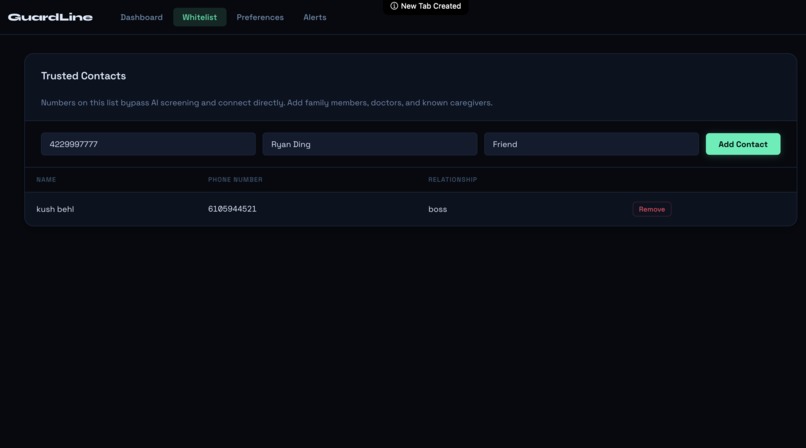
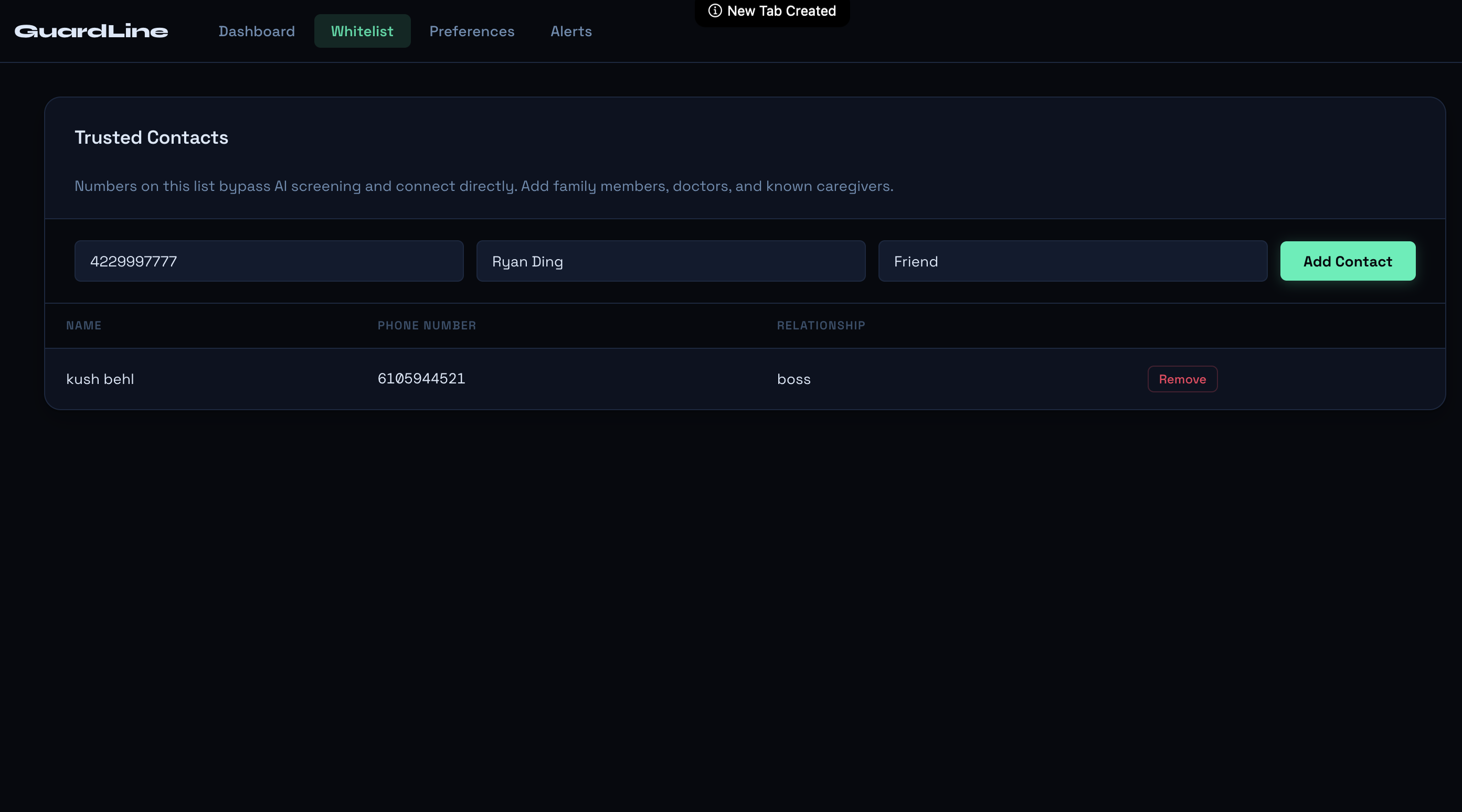
adding to whitelist
-
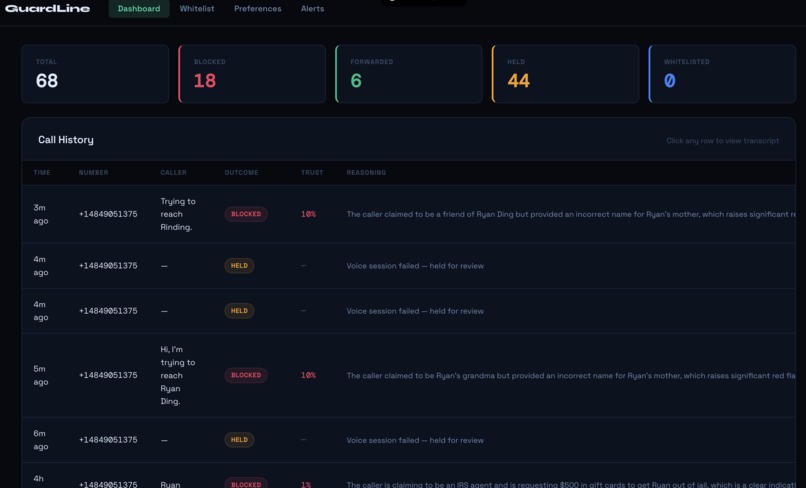
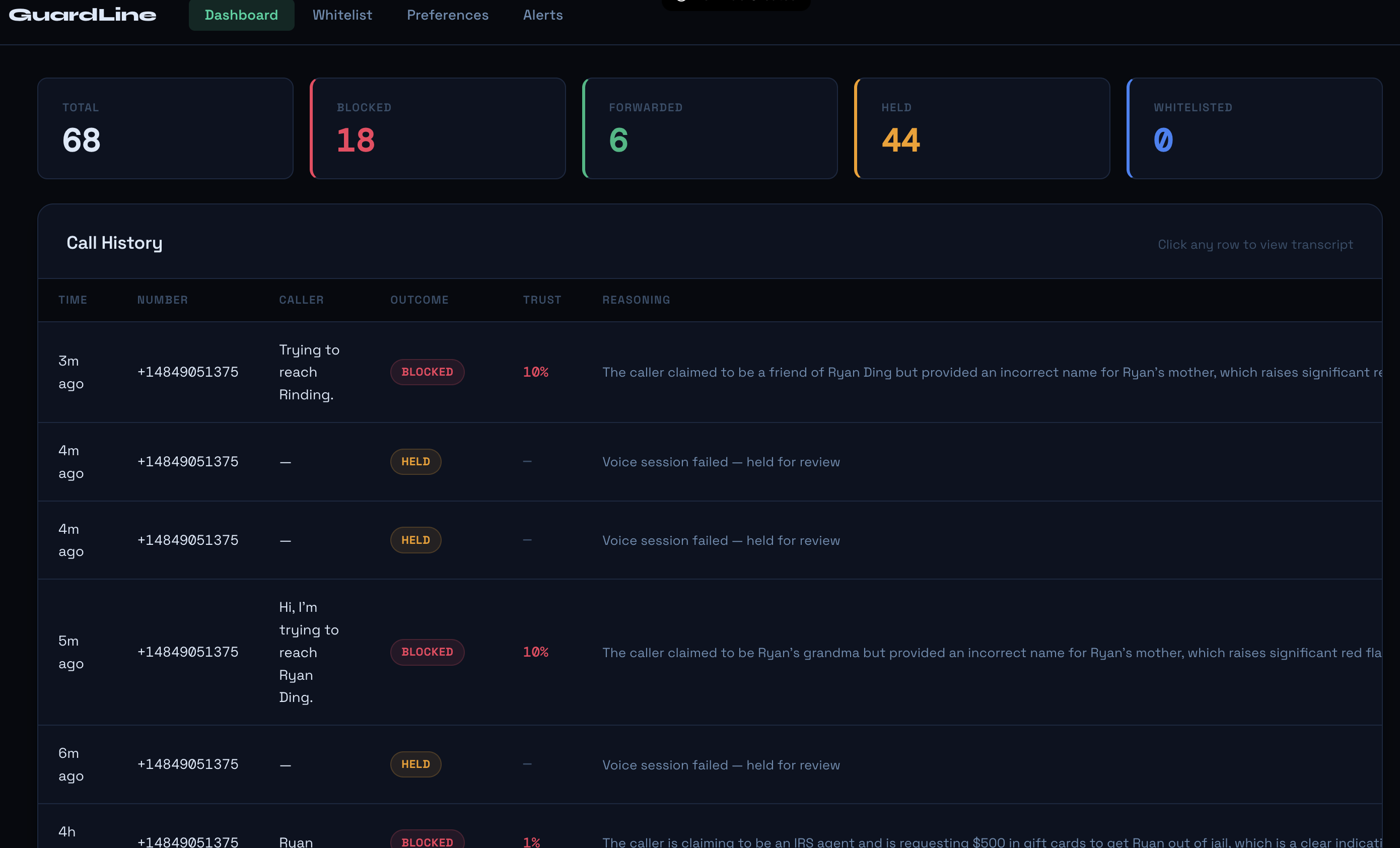
dashboard
Inspiration
Originally, when thinking about the first question, we considered building a live AI that would stay on a call and detect scams in real time. While this seemed appealing at first, after discussing it with our mentor Shreyas, we realized that to do that you would need to either continuously call in intervals an AI with a mix of fast enough that it will act before the victim gets tricked, but slow enough that its computationally feasible, which raised these issues: It would be too computationally intensive with basically any balance, especially at a small scale, and it would cost more than the potential profit gained. It could raise privacy concerns with recording every single call and leave people irked. After further brainstorming, we shifted to designing a flexible AI receptionist that acts as a layer of protection against scam calls through prescreening. This would mean that it is fully transparent to the incoming caller, and also far less computationally intense as the API calls would be centralized around just the first few seconds of a call. In the end, this achieved the official goal of what we thought of in a more practical way. Additionally, we also considered an approach that would address the financial bottleneck rather than just the informational side, such as freezing bank activity or blocking transactions and actively disrupting suspicious calls. However, we ultimately decided against it because it would significantly reduce user autonomy, which goes against our overall vision. We also felt that overly aggressive actions like freezing accounts or interrupting calls could cross a line in how we treat users, and we do not want to design a system that treats people as lesser or strips away control in a way that feels dehumanizing.
What it does
Our product, GuardLine, has four core functionalities. The first layer, which is an AI-receptionist, receives the initial call to the Twilio line and streams it to a live server using WebSocket. From there, we are able to call the OpenAI API, and using the OpenAI Realtime voice model the caller is immediately greeted with a friendly “Hello, who are you trying to reach today?” The conversation relies on Realtime to transcribe and produce text-to-speech output to the potential caller.
The first step of the screening process checks if the caller is on the “whitelist”, or a list of known trusted contacts the recipient maintains and can easily add to in the web dashboard. If the caller is in the whitelist the call automatically bypasses standard procedure. Then the second step of the screening process begins: the assistant asks for the caller to identify the recipient’s name, key information that anyone with a valid reason for calling should be able to answer. The model incorporates fuzzy matching to make sure it is not extremely strict on pronunciation and spelling, as many callers may have differing accents or intonation. This weeds out a surprising amount of scam callers, especially those who are just calling random area codes and do not have the resources to do extensive research on victims.
However, for those scam callers who are able to get the target’s information as part of the setup, there is an additional pipeline that redirects the conversation to GPT-4o mini for our real-time analysis. While checking for scam patterns, manipulation tactics, logical inconsistencies and key information provided by the recipient, it also decides whether to continue asking custom probing questions based on the caller’s responses, testing claims a real caller would be able to answer but a scammer could not. This continues up to a maximum of five iterations, and if the model is in between the probability threshold of 0.65 (significant likelihood of a real caller, passes through to the recipient while notifying in app) and 0.15 (high likelihood of scam caller, declines call after giving reason) the model puts the call on hold, notifies the recipient and a loved one through the dashboard, and gives the recipient the choice to call them back. Every decision goes into the dashboard in live time, with confidence scores, reasoning, and color-coded flags. We have implemented a special notification feature via ntfy that alerts a loved one’s phone in case a suspicious call under review was taken by the recipient, for extra safety precautions.
How we built it
After developing a framework that outlined how our product was to work, we used Claude Code to identify crucial strengths and weaknesses using a SWOT plan to improve upon our existing brainstorming. We came up with a 7-step plan for features that we wanted implemented in our product, and tackled one step at a time: project infrastructure, database layers, twilio calling, OpenAI realtime API, WebSocket layer, Dashboard API, AI Screening, SMS Alerts, and Dashboard database connection. We ended up using multiple major libraries and APIs that we have never coded in before, and in the process of using each we learned as much as we could about the documentation before coding prototypes. We built upon these prototypes by iterating through suggestions with Claude code, until we made solid progress on each of the 7 features. The backend was written through Express and TypeScript, our database ran through SQLite, and we developed a full-stack dashboard.
Challenges we ran into
We have never worked with Twilio before, so to begin with we had to get familiar with it so we could interact with it and have our code run when we called the phone. That took a good amount of testing, and when it finally responded we all celebrated, even though it led to another code error. Using an LLM for real-time speaking and understanding is not something we had tried to implement before, so figuring out things like timing between responses, the optimal prompt, and how to get the LLM to respond properly were all things we needed to tweak so it would feel more natural. We had many difficulties regarding the seemingly minor decisions made by the OpenAI Realtime model and the decision model. For example, we had to specifically code in fuzzy matching because it’s not realistic to assume the caller will be able to pronounce a name 100% correctly every time, so we added in a 70% matching criteria through consonant sounds. Many times, the API was difficult to work with, so we had to hard code in 3 second pauses between AI responses to prevent interruptions and talking over during the conversation. We had to switch from Claude Sonnet to GPT-4o mini as the decision-making model to optimize our credit usage. Additionally, the API keys for Anthropic were highly variable and rarely succeeded in a full run, so we made the decision to switch to higher consistency. Our models were interpreting our prompts as a script rather than asking fluid questions, so we worked around heavily on them until we got a satisfactory result: custom questions, adequate delay between responses, natural tone of voice, good judgment of scam calls, and justification for the decision.
Accomplishments that we're proud of
Dynamic responses!! Since we are using an LLM depending on what it detects ex. If its an IRS agent scam, it will report that it was false impersonation of a government official. OR if we say it was Ryan Ding’s boss the AI will ask specifically which projects, if we say it is Henry Pei’s girlfriend the AI will ask details about the date and whether their is a clear value ask. We’re proud of how we store everything and have it explained out in our UI. It displays and stores the full reasoning behind the confidence score, what it noticed, and what the caller said is stored. So it allows the person to go back, look at it, and review reasoning AND be notified if its a likely scam. Our relationships with mentors. We’ve honestly spent hours and hours learning about all the amazing things our mentors did, and we’e found the experience really fulfilling not just in the product we built but all the amazing people and ideas we learned about! Our workflow. We effectively used GitHub to have each of us build mini parts of the functionality, which bought us both time and saved us some money on API calls :). But in all seriousness, our entire workflow and ideation process was really comprehensive and we’re proud of our teamwork.
What we learned
The basics behind Twilio and how to interact with it to have code work on calls Working explicitly with the openAI API in code Creating extensive full stack projects across multiple workflows The impacts of scam calls and new approaches to scam calls The extent to scam calls past just elderly people (especially in businesses) Networking!
What's next for GuardLine
We would love to push it fully into a mobile app and integrate it on IOS / Android. It’s all fully functional, but seeing it work native on its platform would be the logical next step. Train and optimize models for cost and effectiveness, while also setting up routine different question options and keeping it as variable as possible Integration with other apps ex: door dash so the driver does not get notified Customize multiple more different paths to optimize for minimum call time for fully innocent calls, while also creating as much friction as possible for scammers Our minimum viable product currently consists of only the prescreening stage, but we would be eager to integrate the AI receptionist as a mediator of the subsequent conversation between the elderly individual and the caller to act as an additional failsafe to prevent malicious attacks. The AI receptionist would serve the function of moderating the conversation and flagging any behaviors with malicious intent, and ending the call if such behaviors are identified.
Built With
- claude
- express.js
- openai
- react
- sqlite
- twilio
- typescript

Log in or sign up for Devpost to join the conversation.