-
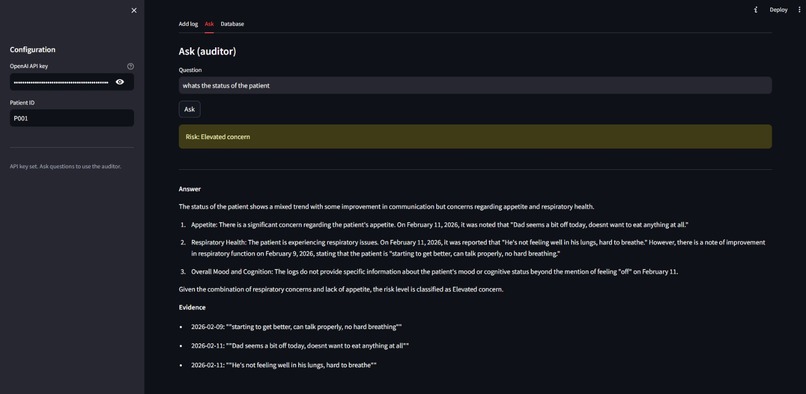
A screenshot of the insights that the AI can get from the database
GuardianRAG – Project Reflection
What Inspired Me
I recently spent some time at an adult day-care in Texas, and it hit me: we aren't failing our seniors because of a lack of heart, but because of a lack of clarity. Caregivers are doing the hard work, but their notes are often just emotional, messy logs where the 'red flags' get buried. A slight change in sleep or appetite might seem small in a daily note, but when those details get lost, we miss the window to help before things get bad.
I’m building a way to turn those scattered stories into actual data. Instead of just summarizing what happened, my tool uses anomaly detection to compare today’s notes against a person’s normal baseline. It catches those early ripples of risk and points to the evidence, so families and doctors can step in early. It’s about moving away from 'putting out fires' and toward actually staying ahead of a crisis
What I Learned
- RAG vs. longitudinal reasoning: Simple retrieval + answer isn’t enough; you need dated logs, temporal ordering, and explicit baseline comparison so the model can say “trending down since Feb 3” instead of generic advice.
- Risk in the loop: Letting the model classify risk from its own assessment (Stable / Elevated concern / Clinical attention advised/ Emergency) worked better than hardcoded keyword rules and kept the logic flexible.
- Evidence discipline: Forcing date + quote citations in the prompt and stripping markdown/asterisks in the UI kept outputs trustworthy and readable.
How I Built It
- Local MVP: No vector DB—logs stored as JSON per patient. FastAPI backend, Streamlit frontend, user brings their own OpenAI API key in the UI.
- Tabs: Add log, Ask (auditor), and a Database tab that shows all logs and the latest risk.
- Auditor flow: User asks a question , then backend loads logs (e.g. last 30 days), sends them sorted by date to the main model, then a small second call classifies risk from that assessment. Answer and evidence are parsed from the first response; risk comes from the classifier so the badge always matches the narrative.
Challenges I Faced
- Risk mismatch: The model sometimes wrote “Clinical attention advised” in the evidence but the UI showed “Stable” because risk was parsed from a single line. Fix: use the chat model to classify risk from the full assessment text instead of pattern matching.
- Noise in output: Bold markdown (
**) and extra symbols appeared in evidence. Added stripping of asterisks in the backend response and in the UI so display stays clean. - Scope: Keeping the MVP local (no vector DB, no embeddings) simplified setup and let me focus on the auditor logic and evidence flow first.

Log in or sign up for Devpost to join the conversation.