-
-
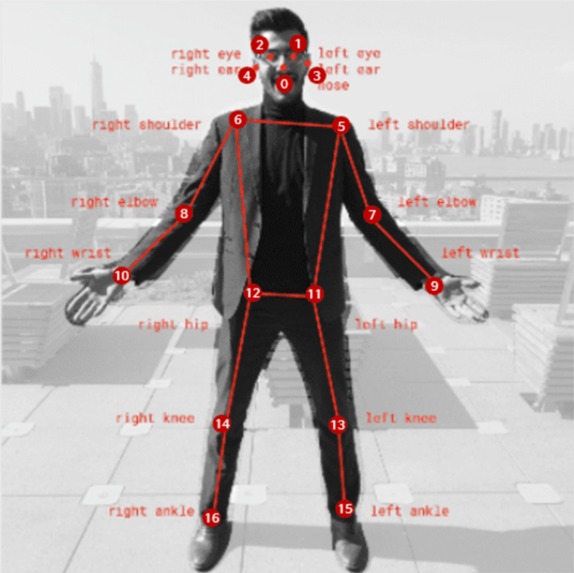
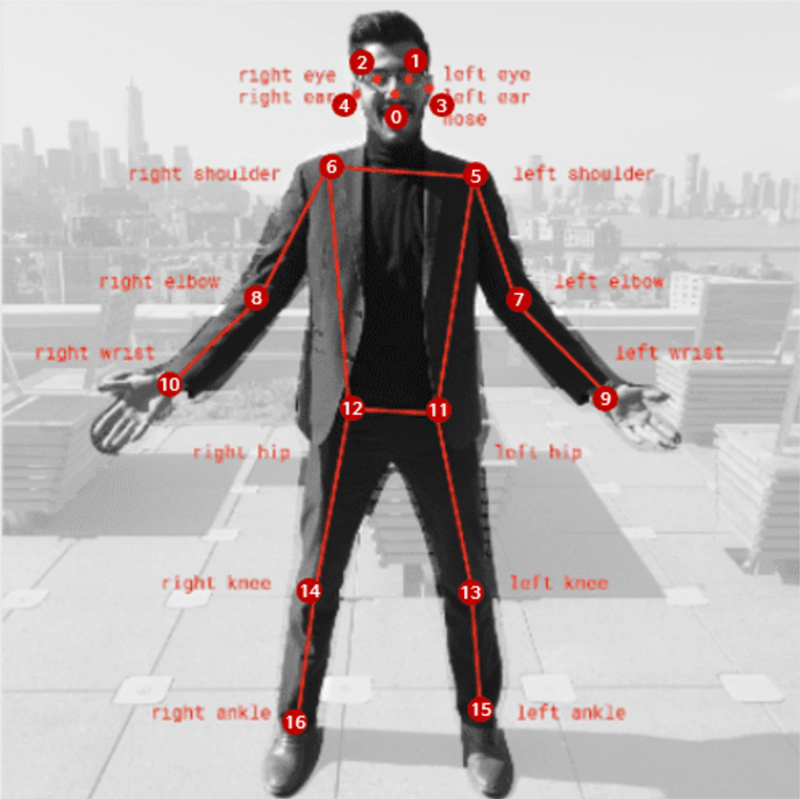
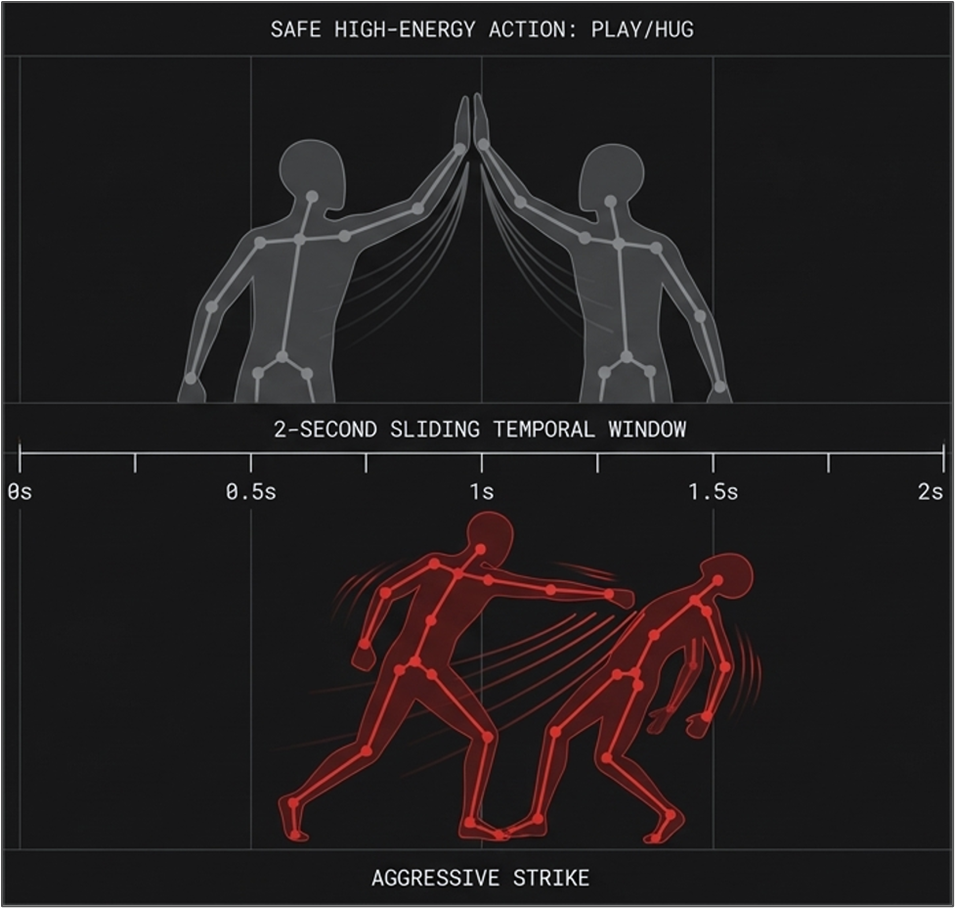
17 skeleton keypoints per person - the only data the classifier ever sees. No faces, no pixels, no identity.
-
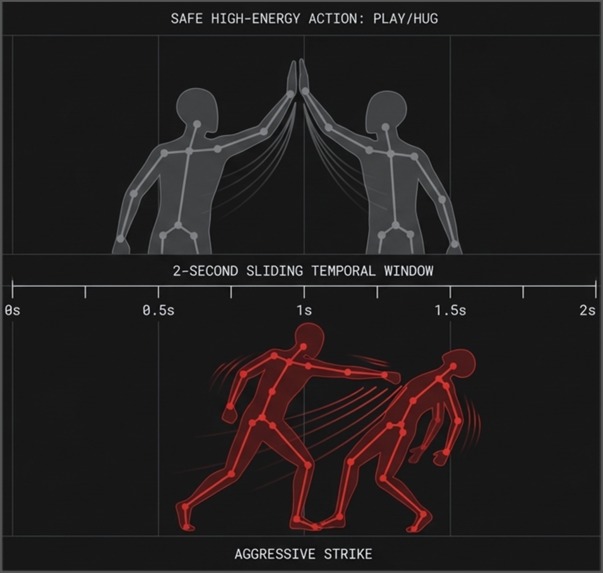
2-second sliding window: how the model separates safe high-energy play from actual aggression using skeleton motion only.
-
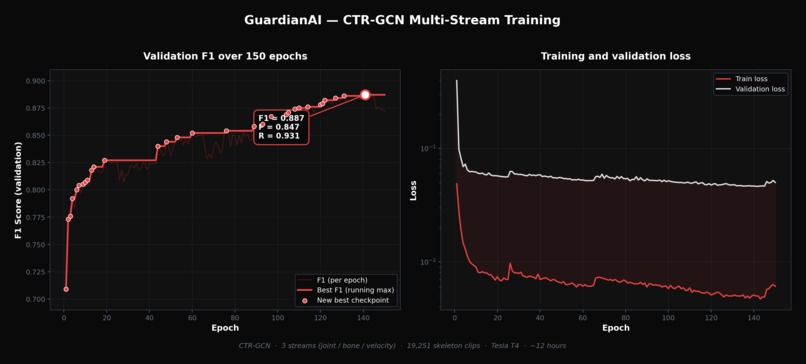
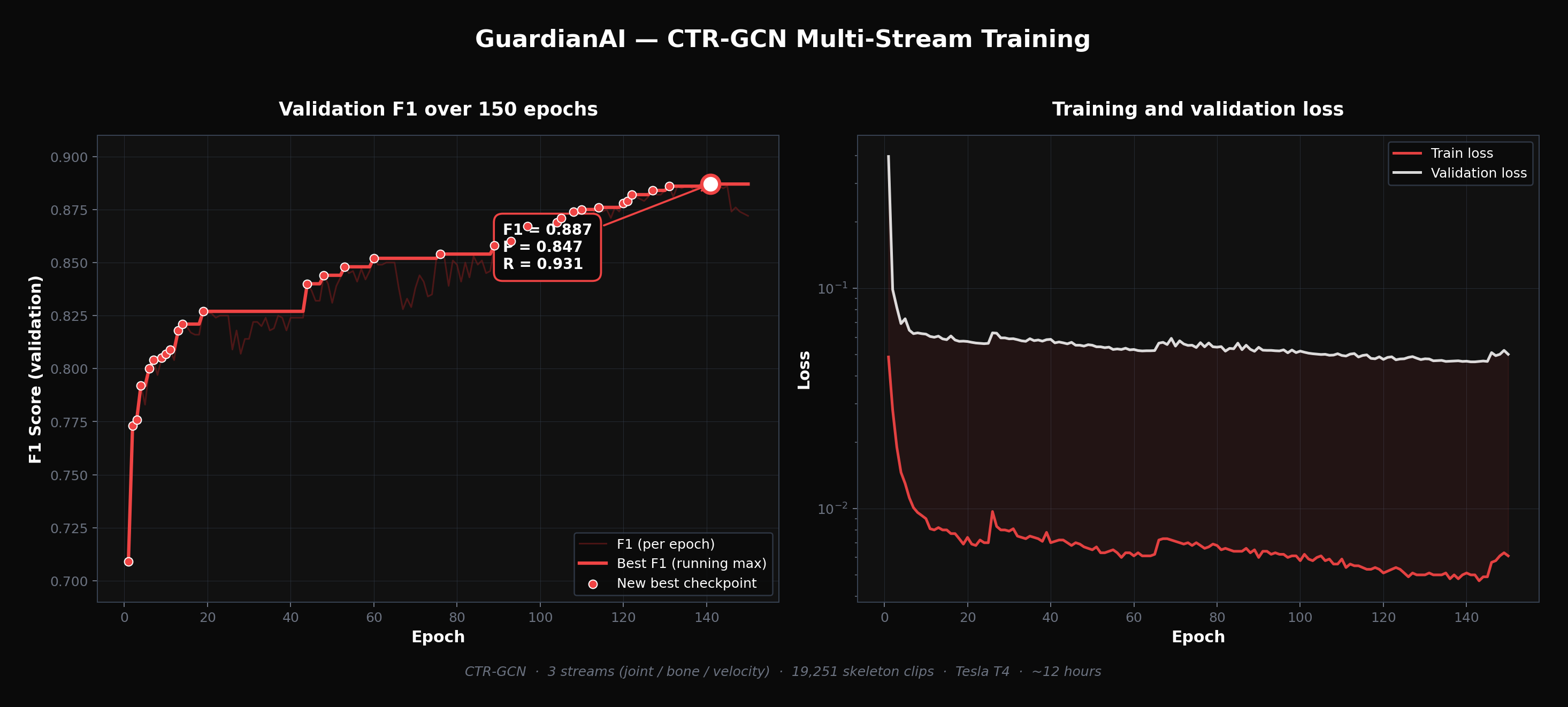
CTR-GCN multi-stream training over 150 epochs. Best F1 = 0.887 (Precision 0.847, Recall 0.931) on validation set of 3110 clips.
Inspiration
Walking through our university hallway one day, I saw two students corner a third. Shoulders shoved, words kept low enough that no teacher could hear. Later that morning, another situation in the bathroom. These things happen constantly and nobody catches them in time.
Our institution runs the KiVa program, a Finnish anti-bullying system. The data behind it is real: around 10% of all students are bullying victims. We have a psychologist, we have protocols. But when I asked her directly, she confirmed what nobody talks about openly: the system only activates after a victim comes forward themselves. Detection is reactive by design.
That's the gap GuardianAI was built to close. Not to replace the humans, but to give them eyes where they currently have none.
What it does
GuardianAI connects to any standard IP camera and analyzes footage in real time. First, YOLOv11-Pose extracts 17 skeleton keypoints per person. No pixels, no faces, just coordinates. Then a CTR-GCN graph neural network classifies the motion across three streams: joint positions, bone vectors, and velocity. When the model detects a high-confidence incident, strikes or shoves or sustained physical dominance, an alert fires simultaneously to the web dashboard and a Telegram bot. The responsible adult, whether that's a psychologist or administrator, gets notified within about one second of the event.
The whole pipeline runs across three parallel threads: capture, process, encode. End to end latency is under one second.
How we built it
Our first approach was pixel-based and it failed completely. The model overfit to lighting and clothing, flagged kids playing around as aggressors, and ran too slow to be useful. Wrong foundation entirely.
The pivot was to strip everything down to skeleton data. When you feed joint coordinates into a graph neural network instead of raw frames, the model learns actual movement patterns rather than visual noise. That shift fixed the speed, fixed the generalization, and as a side effect made the whole system privacy-preserving by architecture rather than by policy.
For training data we used RWF-2000, UBI-Fights, and NTU RGB+D as the public base. But public fight datasets are filmed in open spaces with decent lighting, nothing like a real corridor. So we supplemented with real-world corridor footage, faces fully anonymized, to close that domain gap.
Stack: PyTorch and YOLOv11 for the model side, Next.js for the dashboard, aiogram for the Telegram bot, running on an Ubuntu server.
Best checkpoint: F1 of 0.887, Precision 0.847, Recall 0.931.
Challenges we ran into
Data was the hardest problem. Public datasets lie in a sense: they're clean, well-lit, filmed from eye level. Real corridors are narrow, crowded, shot from ceiling angles. No benchmark shortcut exists for that kind of domain shift, you just have to collect real data.
Getting the CTR-GCN multi-stream fusion right took multiple full training cycles. Graph topology, train/val split integrity, shape consistency between training and inference. Each one had to be audited and fixed before the numbers started making sense.
Accomplishments that we're proud of
We got to F1 of 0.887 on the final checkpoint with Recall at 0.931, meaning the system catches the vast majority of real incidents. We built a complete end-to-end pipeline from IP camera to dual alert in under one second. The project earned 2nd place at Infomatrix Asia among international teams, which gave us external validation that the approach actually holds up. And throughout all of it, zero face data is stored or transmitted at any point.
What we learned
The biggest lesson wasn't technical. The right abstraction matters more than the right model. 3D CNN on raw pixels isn't just a worse version of skeleton-based GCN, it's a fundamentally different and wrong framing of the problem.
We also learned that you can't skip real-world data collection. You can read every paper and train on every public dataset, but if the domain doesn't match, the model doesn't transfer. That gap only closes one way.
What's next for GuardianAI
Summer 2026 we're adding a fourth stage to the pipeline on top of pose, tracking, and classification. X3D-S reading gestures like clenched fist versus open hand, and early stress signals on top of the existing keypoints.
The rules we've set for ourselves: on-device inference only, nothing stored, ethics-board approval required before any deployment.
The goal isn't surveillance. It's giving a psychologist a 30 second head start.
Built With
- aiogram
- api
- bot
- css
- ctr-gcn
- next.js
- numpy
- opencv
- postgresql
- prisma
- python
- pytorch
- react
- tailwind
- telegram
- typescript
- yolov11


Log in or sign up for Devpost to join the conversation.