-
-
Website homepage
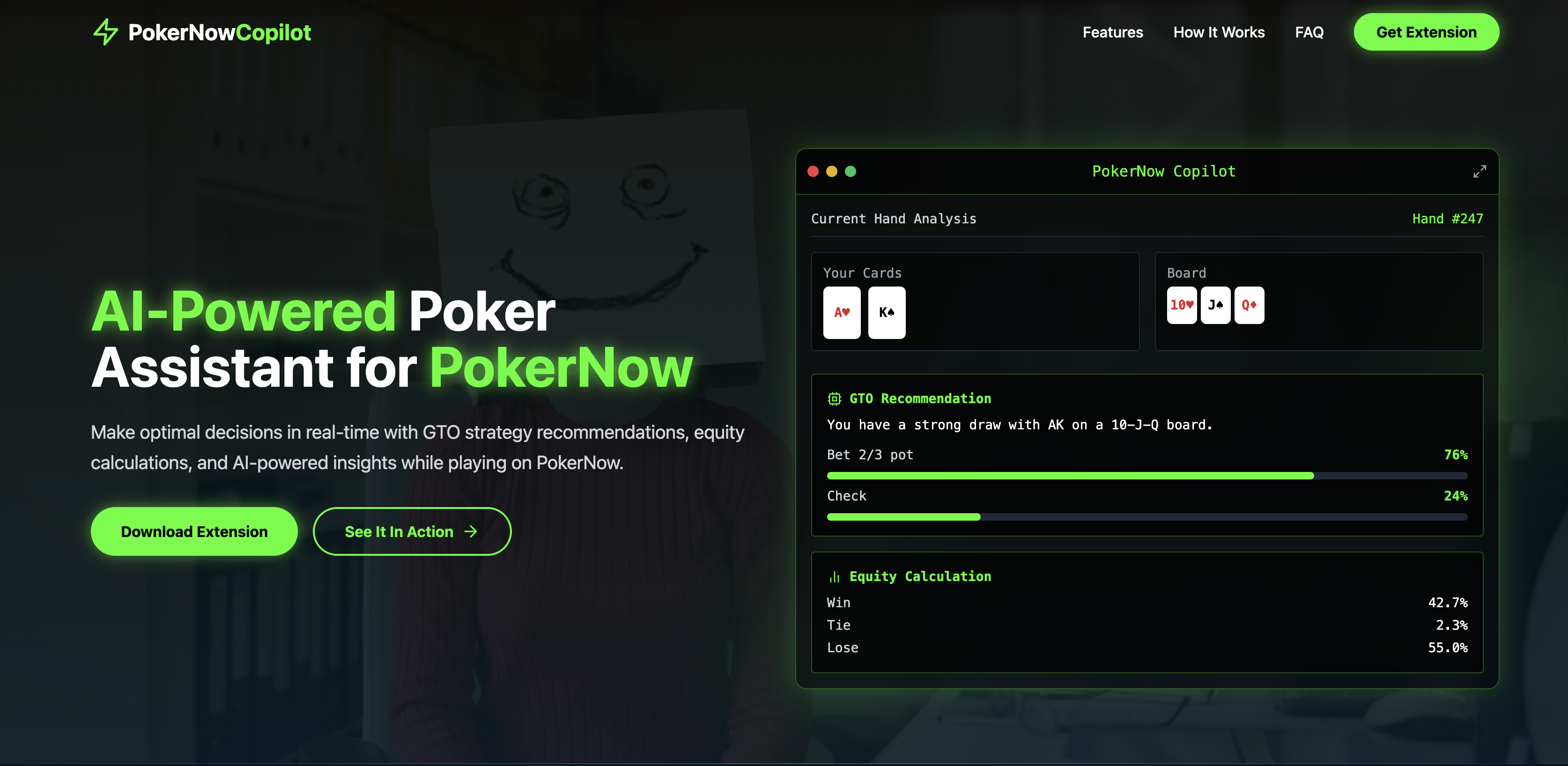
Inspiration
Competitive poker hinges on making small strategic edges that compound into significant long-term gains. While advanced GTO solvers exist, they’re either too slow for live play or demand deep domain expertise. We set out to democratize near-optimal decision-making by fine-tuning a large language model on PokerBench’s expert-annotated hand histories—and then bringing that intelligence directly to the table in real time.
What it does
GTO Copilot continuously watches your PokerNow session, extracts every hand state parameter (hole cards, community cards, stack sizes, blinds, pot size) via browser inspection, and feeds them into a 3-billion-parameter phi-3 model. It returns the ideal action—fold, call, or raise, which the user can then follow. A built-in Gemini-powered chatbot and Leaping AI voice agent explain the model’s reasoning in natural language for a truly interactive learning experience.
How we built it
First, we reverse-engineered PokerNow’s UI—using browser dev tools to pull card values, suits, pot and stack sizes—to stream game state into our pipeline. We then formatted those raw parameters into concise text prompts for our fine-tuned model. The core is phi-3-3B, fine-tuned with PEFT/LoRA on 500K+ labeled hand examples; mixed precision and gradient accumulation let us train on a single A100. For the “copilot” UI, we integrated Leaping AI as a voice agent and Dex to handle button clicks that fire our FastAPI /predict endpoint. Finally, we wrapped a Gemini chatbot around the same prompts so users can ask questions about the model decisions and get a clear, human-readable explanation.
Challenges we ran into
Translating raw DOM values into robust text prompts without losing context required custom parsers for card encoding and numeric fields. Early fine-tunes skewed toward over-folding in multi-way pots until we rebalanced our training set and tweaked LoRA hyperparameters. Integrating real-time voice feedback introduced latency spikes, which we solved by batching inference calls and pre-warming GPU memory. We also struggled for a while to find a trainable Monte Carlo algorithm, because there were not that many public ones (but in the end we managed to find one, albeit an old one).
Accomplishments that we're proud of
We achieved sub-200 ms end-to-end inference—fast enough for live browser play—and a 78 % top-1 match rate against expert labels. Users can now speak naturally to the copilot (“What should I do now?”), see a button-driven suggestion overlay, and dive into a Gemini-powered chat to understand the “why” behind each decision. All of this runs on a single‐server GPU instance, from data scraping through model serving. Above all, we are proud that we managed to finish this project on time, and we all had a ton of fun working on it.
What we learned
We discovered that structured decision tasks demand carefully crafted prompts—raw JSON dumps won’t cut it. PEFT/LoRA makes large models practical on limited hardware, but hyperparameter balance is crucial to avoid behavioral bias. Furthermore, integrating voice and chat interfaces emphasizes the need to optimize both latency and user experience through GPU batching, caching, and lightweight front-end parsers.
What's next for GTO Copilot
We plan to extend multi-street context by capturing action history and opponent tendencies, experiment with reinforcement learning from self-play, and offer quantized 4-bit model variants for ultra-low-cost cloud deployment. This will help the model adjust against aggressive/passive players, and also factor this into account when making its decisions. On the UX side, we’ll build a browser plugin HUD and mobile companion app so every player can carry GTO Copilot in their pockets!



Log in or sign up for Devpost to join the conversation.