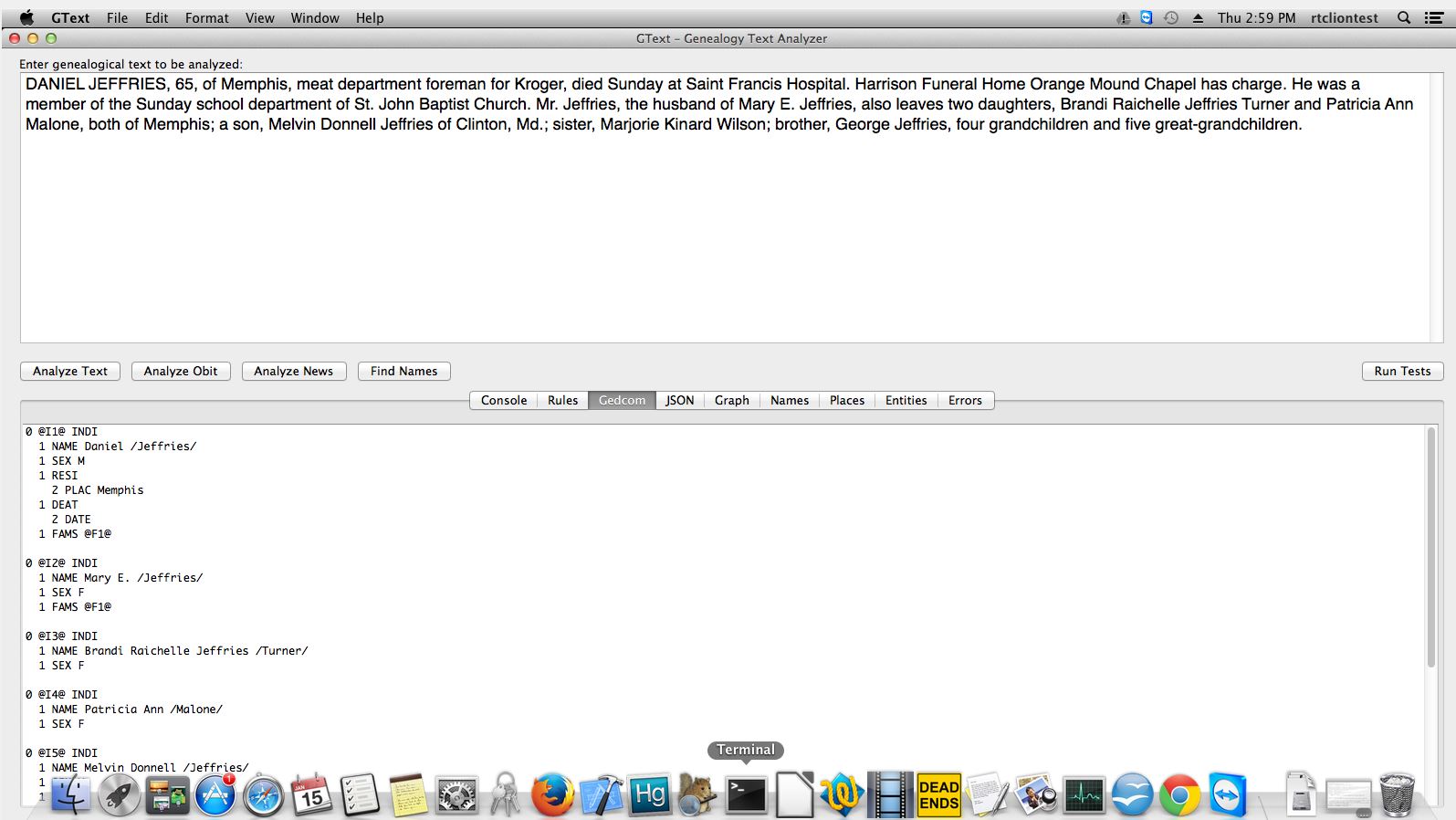
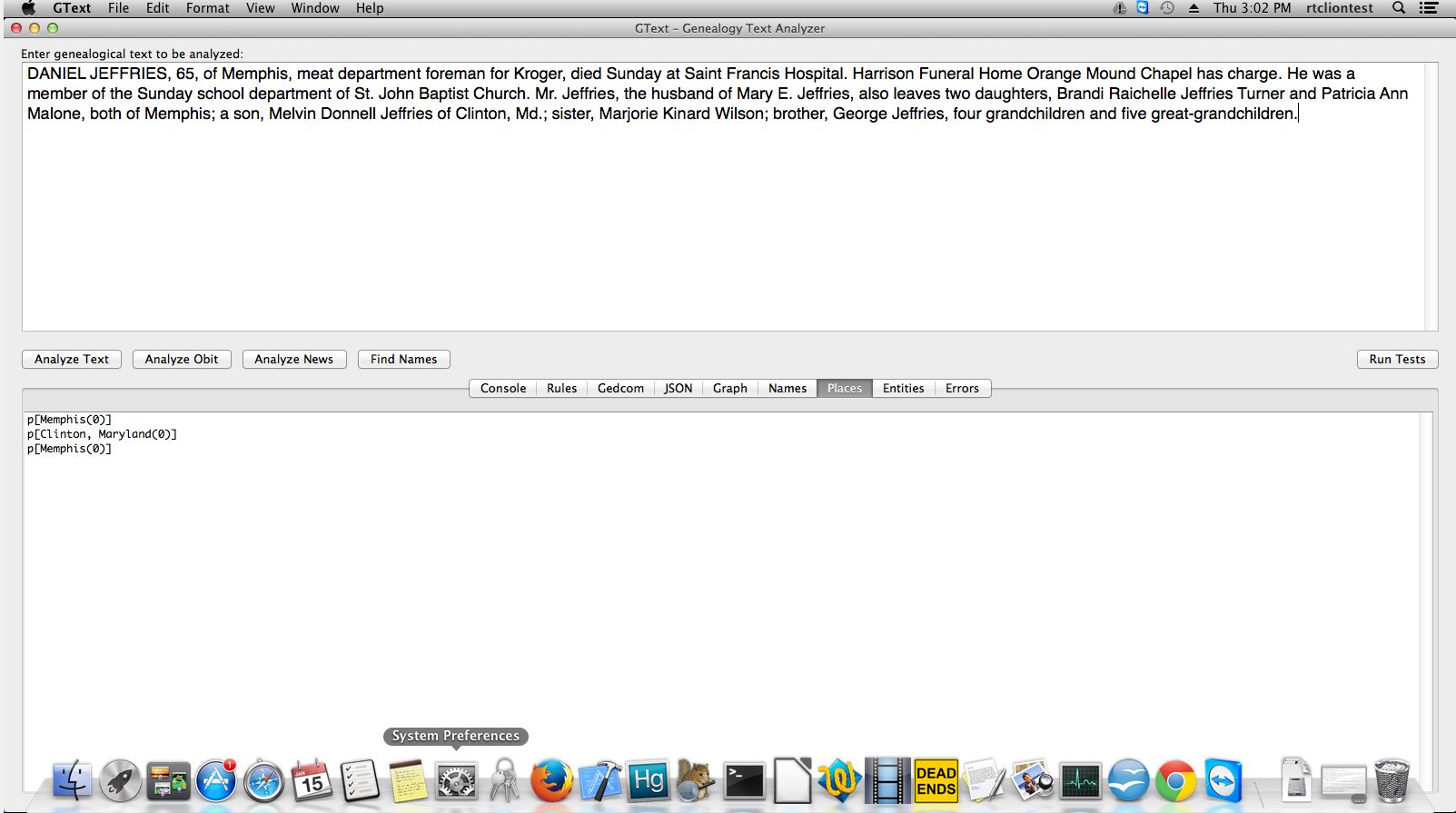
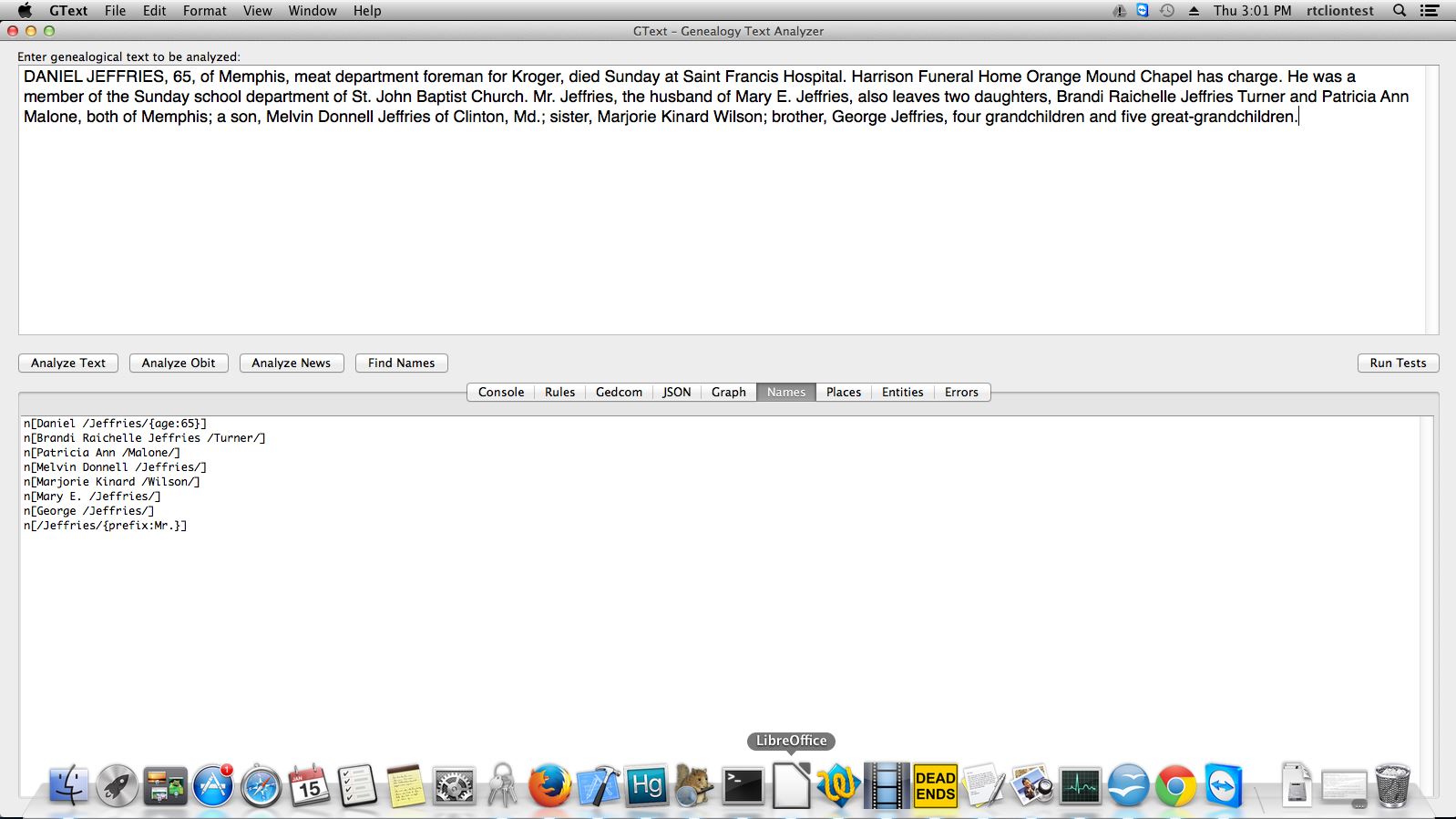
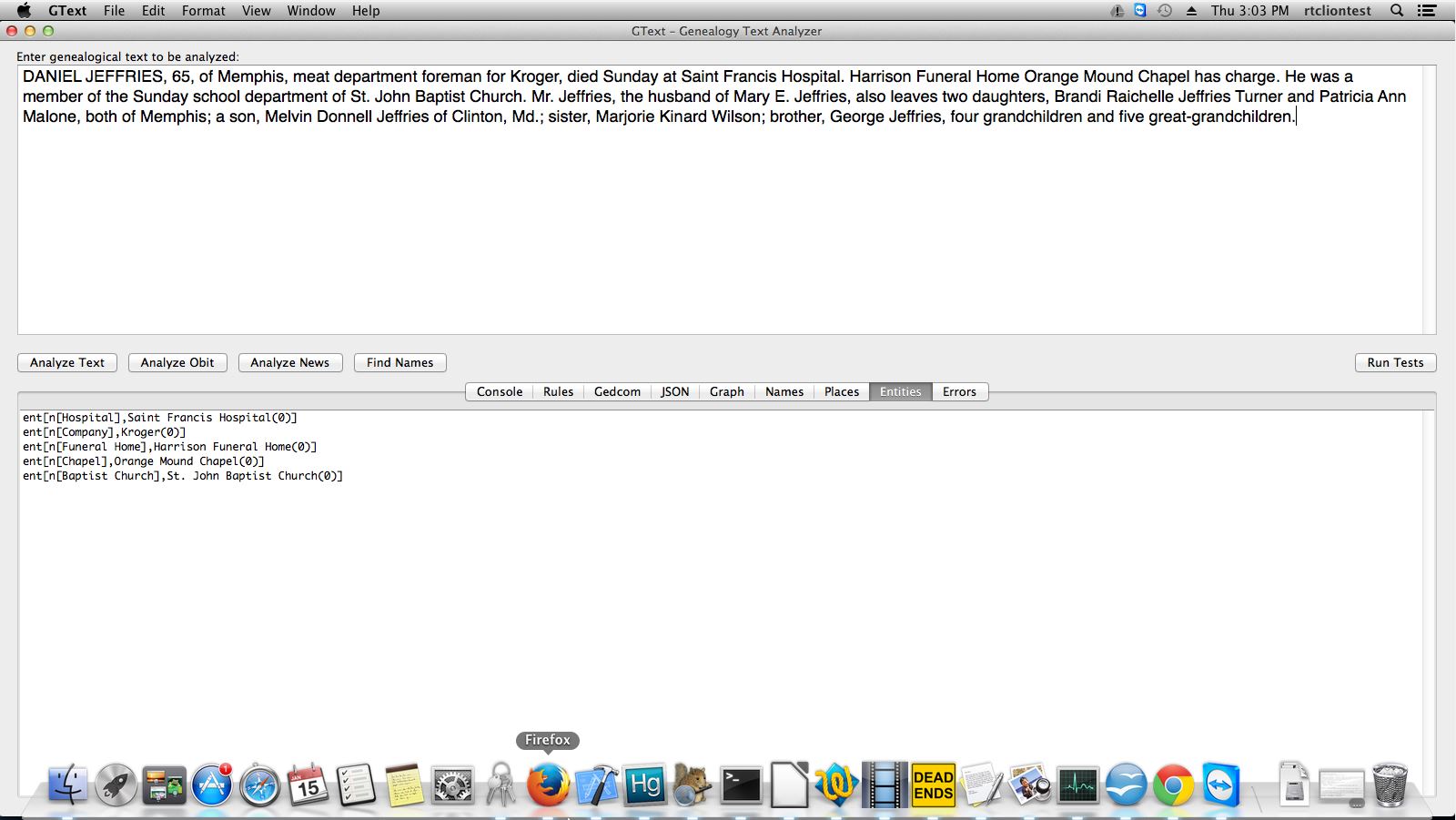
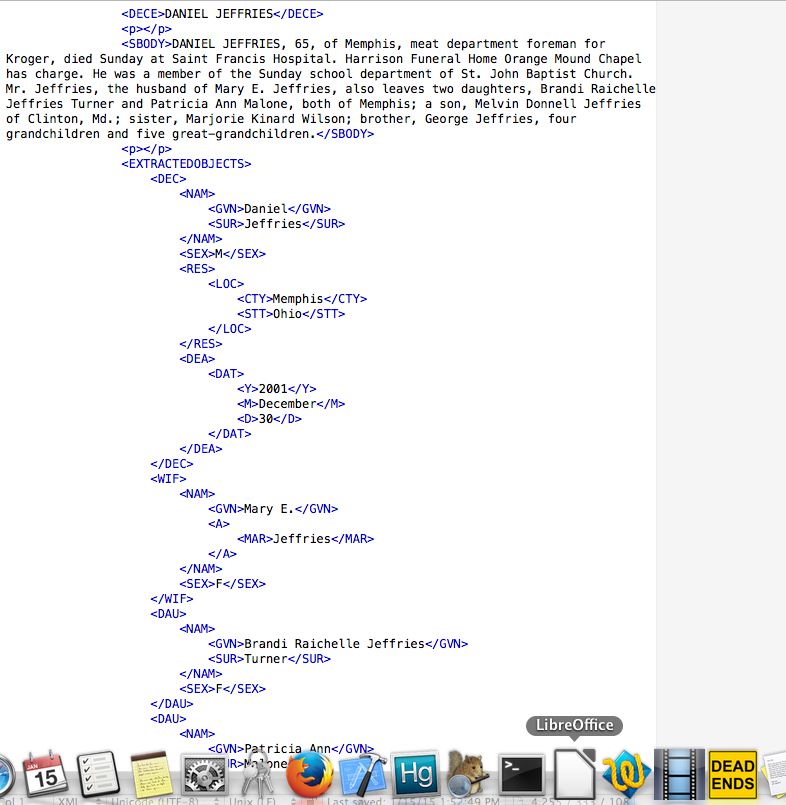
The inspiration came from looking for women's maiden names. One of the most unused sources of that information is her parent's obituary. The software was first developed to gather that information in a normalized way that full text search just can't match.
The engine is now very robust and functional. The remaining development is to run enough data through it and enhance the rule sets and data dictionaries to become more and more accurate at extracting the correct data.
The most impressive feature is that the system can understand and extract relationships between people. For example it can maintain relationships between husband and wife, father and children, etc. It can even maintain the relationship between a person and the boat they arrived on when extracting immigration records.
By changing dictionaries and rule sets the engine can be used to extract information from text in other languages or other industries like legal and medical.
The target market is mainly businesses that gather and sell data to customers. It is also possible that it will be released as a service where a person could make a pdf of a book and submit it online for OCR and name extraction from the new digital data for pennies a page. Eventually it would make sense to approach law firms to help automate extracting data from documents during legal proceedings.
Built With
- familysearch
- genealogybank
- objective-c
- xcode

Log in or sign up for Devpost to join the conversation.