-
-
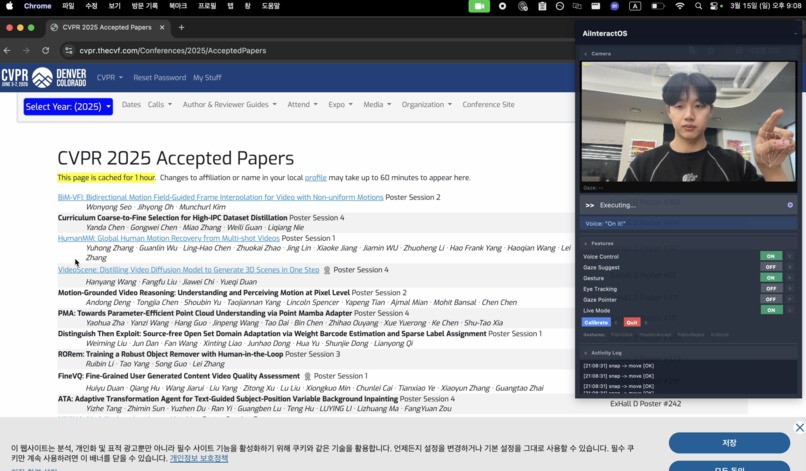
Gesture Control: Index Finger to Move Mouse, Fist to Click
-
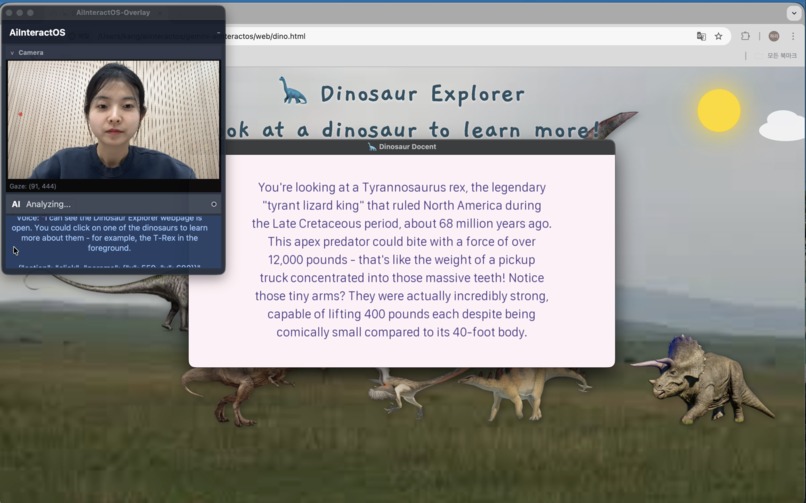
Gaze Control: Generate image
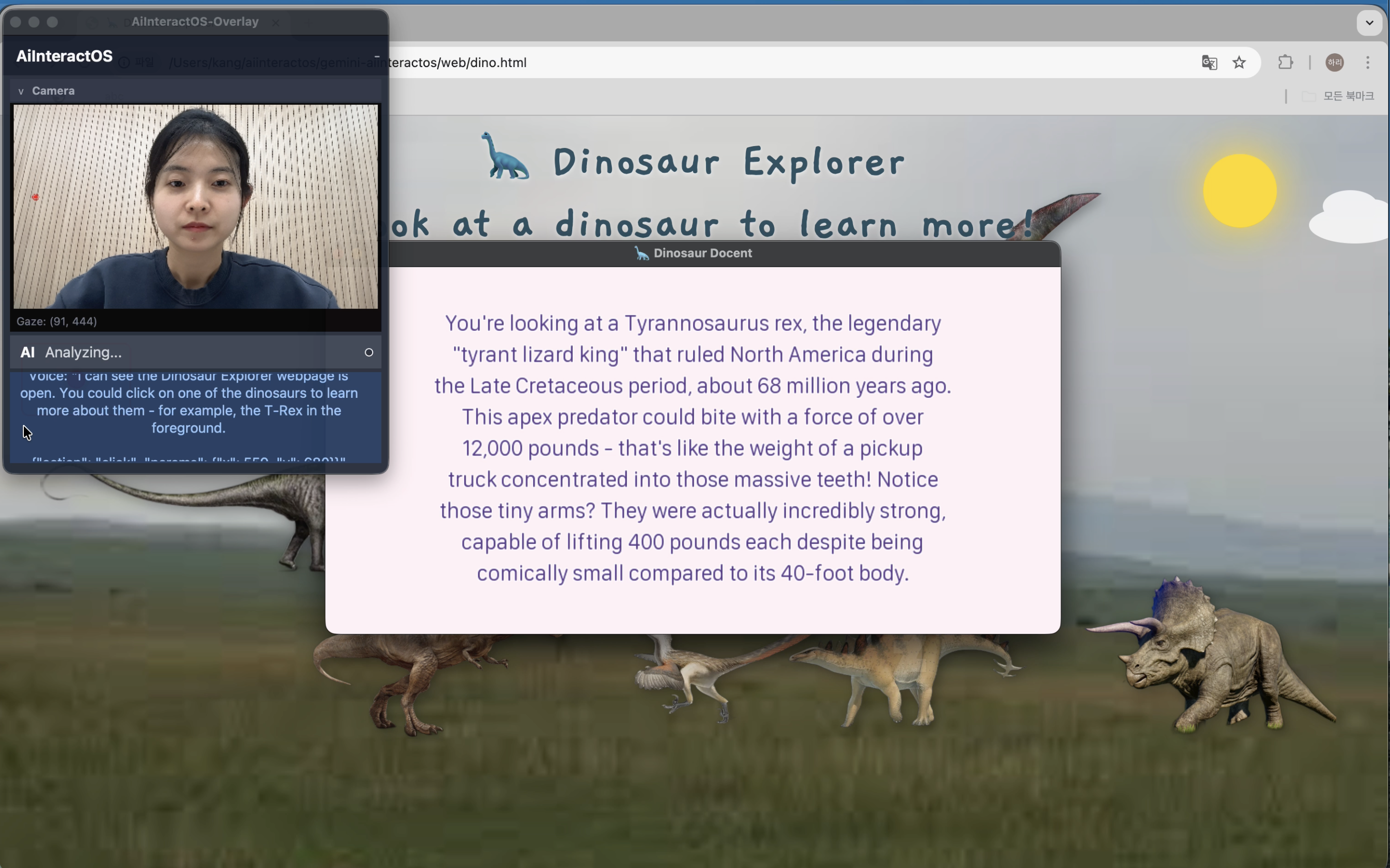
Inspiration
Have you ever felt that the traditional keyboard and mouse are bottlenecks to human thought? We drew inspiration from the futuristic interfaces seen in movies like The Avengers, where Tony Stark effortlessly interacts with his computer using only glances, gestures, and natural conversation.
At the same time, we wanted to address a real-world challenge: accessibility. Many users with limited mobility struggle to interact with computers using traditional input devices such as keyboards and mice. What if a computer could understand our intentions naturally—by observing where we look, how we move our hands, and what we say?
This vision led us to create GGS (Gaze Gesture Speech). Our goal was to build a system that connects human intent directly with computer actions through natural multimodal interaction, making computing more intuitive, efficient, and accessible for everyone.
What it does
GGS is an AI-powered multimodal interface that allows users to control their computers without relying on traditional physical inputs. Instead, it interprets three natural forms of human interaction:
- Gaze Tracking: Identifies exactly which element on the screen the user is looking at.
- Gesture Recognition: Interprets simple hand motions such as snapping fingers to confirm or pinching to scroll.
- Speech Commands: Understands natural language instructions to perform tasks.
For example, when a user looks at a web form and snaps their fingers, GGS analyzes the screen context and automatically fills the form using AI. Tasks that usually require several manual steps—like reading an email, summarizing it, and drafting a reply—can be completed within seconds.
By combining gaze, gesture, and speech into a unified interaction model, GGS significantly reduces friction between human intent and computer execution.
How we built it
We built GGS by integrating real-time computer vision pipelines with the Amazon Nova AI ecosystem.
Input Pipeline
We used OpenCV and MediaPipe to capture real-time multimodal signals:- Face Mesh for gaze tracking
- Hand landmarks for gesture recognition
Core AI Engine (Amazon Nova)
- Amazon Nova Act analyzes the screen, detects UI elements, and executes automation tasks.
- Amazon Nova 2 Lite handles reasoning and contextual understanding.
- Amazon Nova Sonic enables fast, natural speech interaction.
Framework Integration
We extended the open-source trycua (Computer-Use Agent) framework to support multimodal inputs and connect them with our AI pipeline.
Multimodal Intent Fusion
To prevent accidental actions, we implemented a custom weighted probability model. Instead of relying on a single input, the system calculates a combined confidence score using gaze, gesture, and speech signals.
The system executes an action only when the combined confidence exceeds a threshold:
$$ Intent = w_g Gaze + w_h Gesture + w_s Speech $$
If:
$$ Intent > 0.85 $$
then the Nova Act agent executes the automation task. This approach significantly reduces false positives and ensures that system actions feel intentional and natural.
Challenges we ran into
Gaze Calibration Drift
Tracking eye movement using a standard webcam is noisy and unstable. We implemented a dynamic smoothing algorithm to stabilize cursor positioning over UI elements.Multimodal Synchronization
Aligning gaze location, gesture timing, and speech commands within milliseconds required careful pipeline orchestration to ensure the system interpreted the user's true intent.Latency Optimization
Initially, waiting for the LLM to analyze the screen and return an action took over 5 seconds. By optimizing prompts for Nova 2 Lite and reducing visual data payloads, we reduced end-to-end latency to under 2 seconds.
Accomplishments that we're proud of
- Achieving >95% gesture recognition accuracy using only a standard webcam.
- Successfully connecting Amazon Nova reasoning with real-time OS-level UI control.
- Building a fully working multimodal interface prototype within a short hackathon timeframe.
- Reducing common workflow times by up to 90%+ in tasks like form filling and email handling.
What we learned
The Power of Nova Act
We discovered how powerful Amazon Nova Act is at translating visual UI layouts into actionable automation instructions.Software Can Compensate for Hardware Limitations
Through filtering, smoothing algorithms, and intent fusion models, we achieved reliable interaction using only commodity hardware.Accessibility Matters
During testing, we realized how transformative multimodal interfaces can be for users with physical limitations. This reinforced our motivation to build more inclusive computing systems.
What's next for GGS
This project is just the beginning. Our next steps include:
Expanding the Gesture Library
Supporting more complex gestures for tasks like video editing or 3D modeling.Edge AI Optimization
Moving the vision pipeline to edge NPUs to dramatically reduce latency and CPU usage.Open Source Contributions
We plan to release our multimodal extensions for thetrycuaframework so other developers can build gaze-and-gesture-based AI agents.
Our long-term vision is to evolve GGS (Gaze Gesture Speech) into a universal human-computer interaction layer where computers understand user intent as naturally as a human assistant.
Built With
- amazon-web-services
- bedrock
- boto3
- github
- javascript
- mss
- multimodal
- nova
- nova2
- numpy
- opencv
- pillow
- pyaudio
- pyautogui
- pynput
- python
- transcribe



Log in or sign up for Devpost to join the conversation.