-
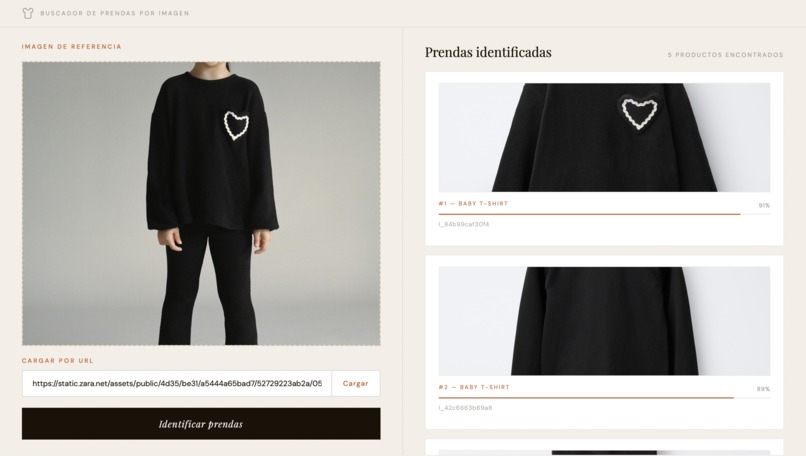
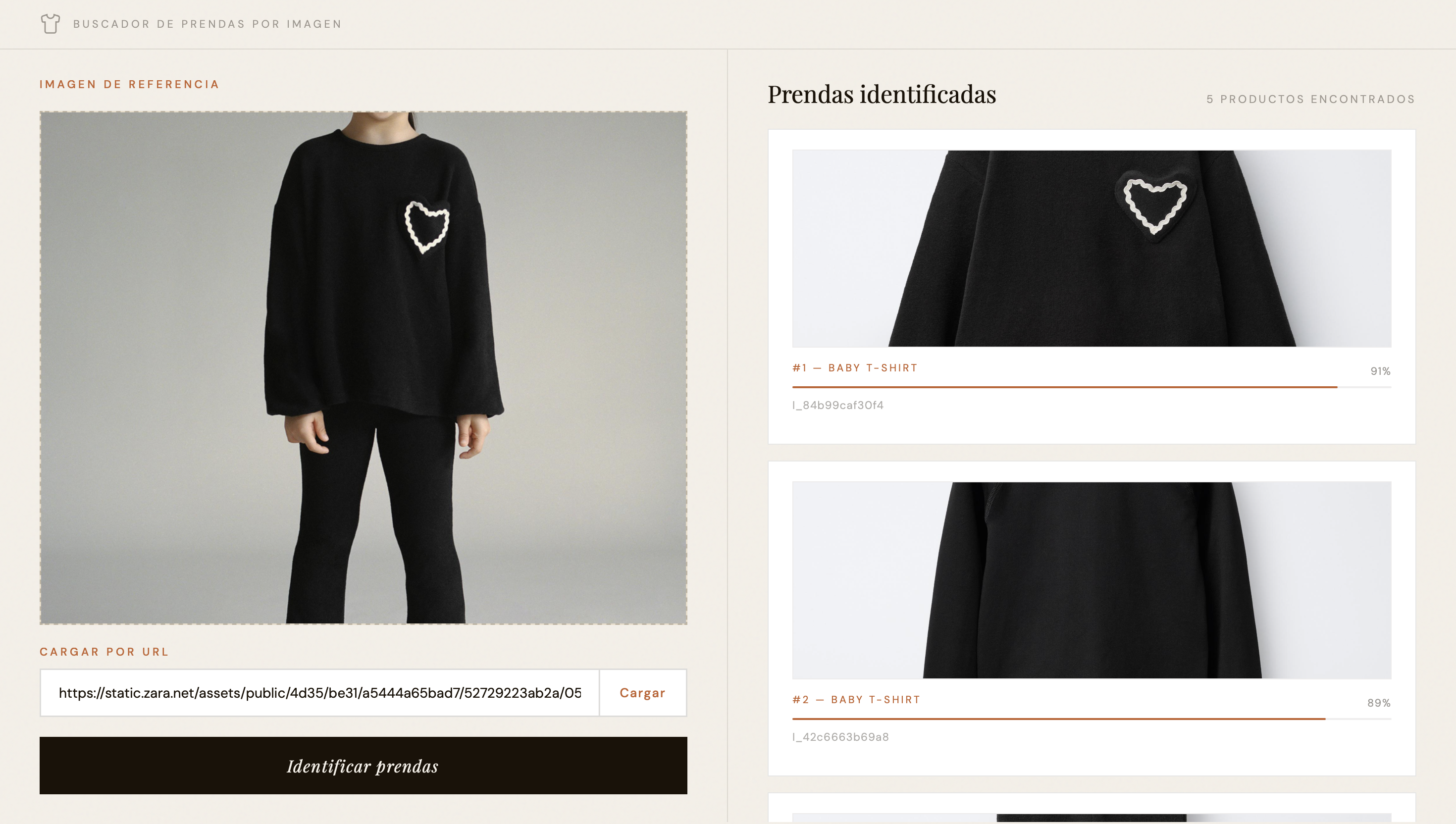
Demo de la web
👕 Pixel_hackUDC - Reto Inditex
💡 Inspiración
Nos enfocamos en el desafío técnico propuesto por Inditex: cómo la visión artificial puede ayudar a categorizar automáticamente un catálogo masivo. Quisimos entender las dificultades reales de entrenar un modelo que identifique prendas específicas en contextos de moda complejos.
🚀 ¿Qué hace?
El proyecto es una prueba de concepto que analiza imágenes de modelos para intentar segmentar y etiquetar las prendas que visten. Su objetivo es discernir entre diferentes tipos de ropa y asociarlas a una base de datos de productos mediante visión computacional.
🛠️ Cómo lo construimos
Desarrollamos un flujo de trabajo basado en:
- Python: Para el procesamiento de datos y orquestación del modelo.
- YOLO (You Only Look Once): Utilizado para la detección de objetos y la delimitación de las partes del cuerpo.
- CLIP: Para establecer la relación semántica entre los píxeles de la imagen y las descripciones de las prendas.
- Datasets: Realizamos una fase de limpieza y refinamiento sobre los datos proporcionados para intentar mejorar la coherencia del entrenamiento.
🚧 Desafíos que enfrentamos
- Restricciones de Hardware: Al no disponer de GPUs de alto rendimiento, trabajamos sobre CPU en Google Colab. Esto limitó drásticamente el número de iteraciones (epochs) y la profundidad del entrenamiento que podíamos alcanzar en el tiempo de la hackaton.
- Complejidad del Dataset: Nos encontramos con un dataset con mucho "ruido" (accesorios y elementos de fondo) que dificultaba la convergencia del modelo.
🏆 Logros de los que estamos orgullosos
- Haber logrado implementar un pipeline funcional de extremo a extremo (desde la carga de datos hasta la inferencia) bajo condiciones técnicas limitadas.
- Alcanzar un 28.55% de precisión, lo cual consideramos un punto de partida sólido.
📖 Qué aprendimos
Este reto fue una lección realista sobre:
- Optimización bajo mínimos: Cómo gestionar la memoria y los procesos de entrenamiento cuando el hardware es un cuello de botella.
- Análisis de datos: La importancia crítica de la calidad del dataset frente a la arquitectura del modelo.

Log in or sign up for Devpost to join the conversation.