-
-
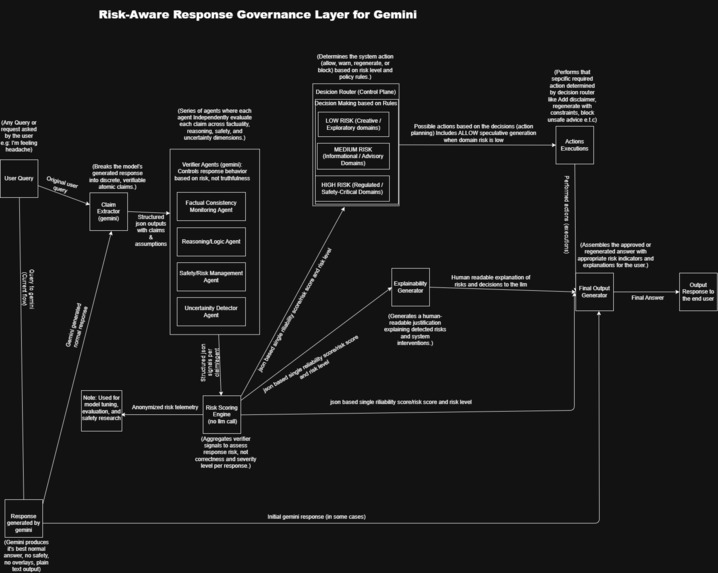
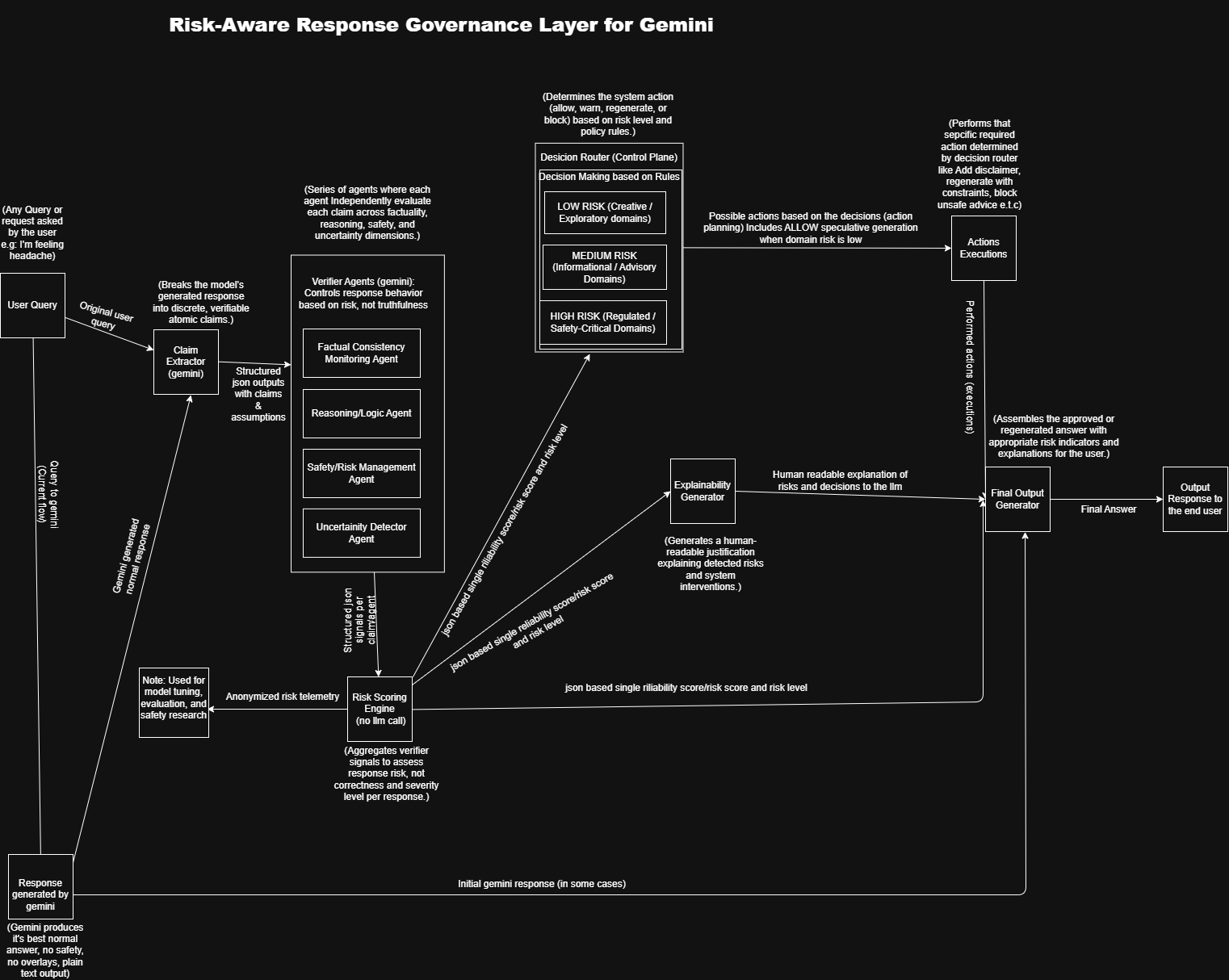
GRS System Design (Workflow)
Inspiration
Large language models are remarkably capable—and remarkably confident. They answer questions with authority, even when they're wrong.
In most contexts, this is a minor annoyance. In high-liability domains—medical advice, legal guidance, financial recommendations—it's dangerous. A confident wrong answer about medication dosage, contract interpretation, or investment risk can cause real harm.
We asked: What if we could observe, measure, and control AI reliability before responses reach users?
Not fix hallucinations—that's an unsolved research problem. But govern them. Detect risk. Make decisions. Take action.
That's what GRS-Gemini does.
What It Does
GRS-Gemini is an application-layer governance system that sits between Gemini and end users. Every response goes through an 8-stage pipeline:
- Generation — Gemini produces a raw response
- Claim Extraction — Response is broken into atomic, verifiable claims
- Verification — 4 specialized agents detect reliability failures
- Risk Scoring — Each claim receives a numeric risk score (0-100)
- Decision Routing — System determines action: ALLOW, WARN, REGENERATE, or BLOCK
- Explainability — Human-readable explanation is generated
- Regeneration — If needed, response is regenerated with constraints
- Final Output — Governed response is delivered
The LLM detects. The system decides.
How We Built It
We designed GRS-Gemini with separation of concerns:
- Gemini handles intelligence — Generation, claim extraction, verification analysis, explanation generation
- Deterministic code handles decisions — Risk scoring uses explicit formulas, not AI judgment. Same input → same decision. Every time.
Architecture highlights:
- 6 hallucination classes with explicit definitions (Factual, Assumption, Contradiction, Overconfidence, Fabricated Source, Ambiguity)
- 4 specialized verification agents (Fact Verifier, Logic Checker, Confidence Calibrator, Safety Agent)
- Risk scoring with domain multipliers (Medical/Legal/Financial = 1.5x)
- Graduated intervention (not binary allow/block)
- Full observability and audit trail
Tech stack:
- Python 3.10+ with type hints
- Google Gemini API for all LLM operations
- Flask for demo UI
- Pydantic for data validation
- 334 tests for reliability
Challenges We Faced
Challenge 1: Determinism vs. Intelligence
We needed verification to be intelligent (catch subtle issues) but decisions to be deterministic (reproducible, auditable). Solution: Let Gemini identify problems, but use explicit scoring formulas for routing.
Challenge 2: Graduated Response
Binary allow/block is too crude. A slightly uncertain medical answer needs a warning, not blocking. Solution: 4-action system (ALLOW, ADD_WARNING, REGENERATE, BLOCK) with risk thresholds.
Challenge 3: Explainability Without Re-evaluation
The explainer must explain decisions without second-guessing them. Solution: Pure translation layer—takes risk signals and decision codes, outputs human-readable text. No LLM calls, no new analysis.
Challenge 4: Demo Reliability
What if Gemini API is unavailable during a demo? Solution: Fallback mode with cached responses for all 12 demo scenarios.
What We Learned
Governance ≠ Censorship — Smart governance enables more use cases, not fewer. By adding a safety layer, enterprises can deploy AI in domains they'd otherwise avoid.
Honesty builds trust — We're explicit about what we don't solve: no truth guarantees, no bias elimination, no professional replacement. Judges and users respect boundaries.
Structured output is essential — Gemini's JSON mode made our pipeline possible. Every stage produces parseable, typed data.
Same input → same output matters — For enterprise deployment, reproducibility isn't optional. Temperature=0 throughout.
What We Didn't Solve
We're honest about our boundaries:
- Not a truth engine — We detect risk signals, not absolute correctness
- Not a professional replacement — Medical/legal experts still needed
- Not bias elimination — Governance layer, not training intervention
- Not 100% accurate — Probabilistic verification
We govern outputs, not reality.
Built With
- css
- flask
- google-gemini-api
- html
- javascript
- pydantic
- pytest
- python

Log in or sign up for Devpost to join the conversation.