-
-
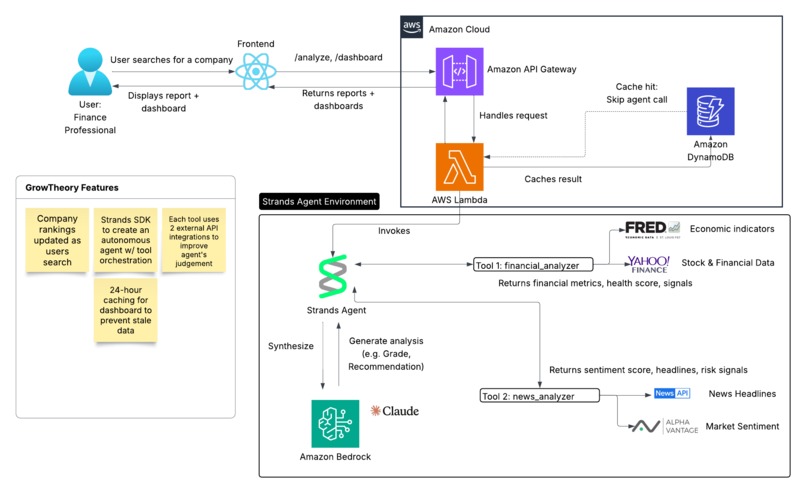
Architecture Diagram
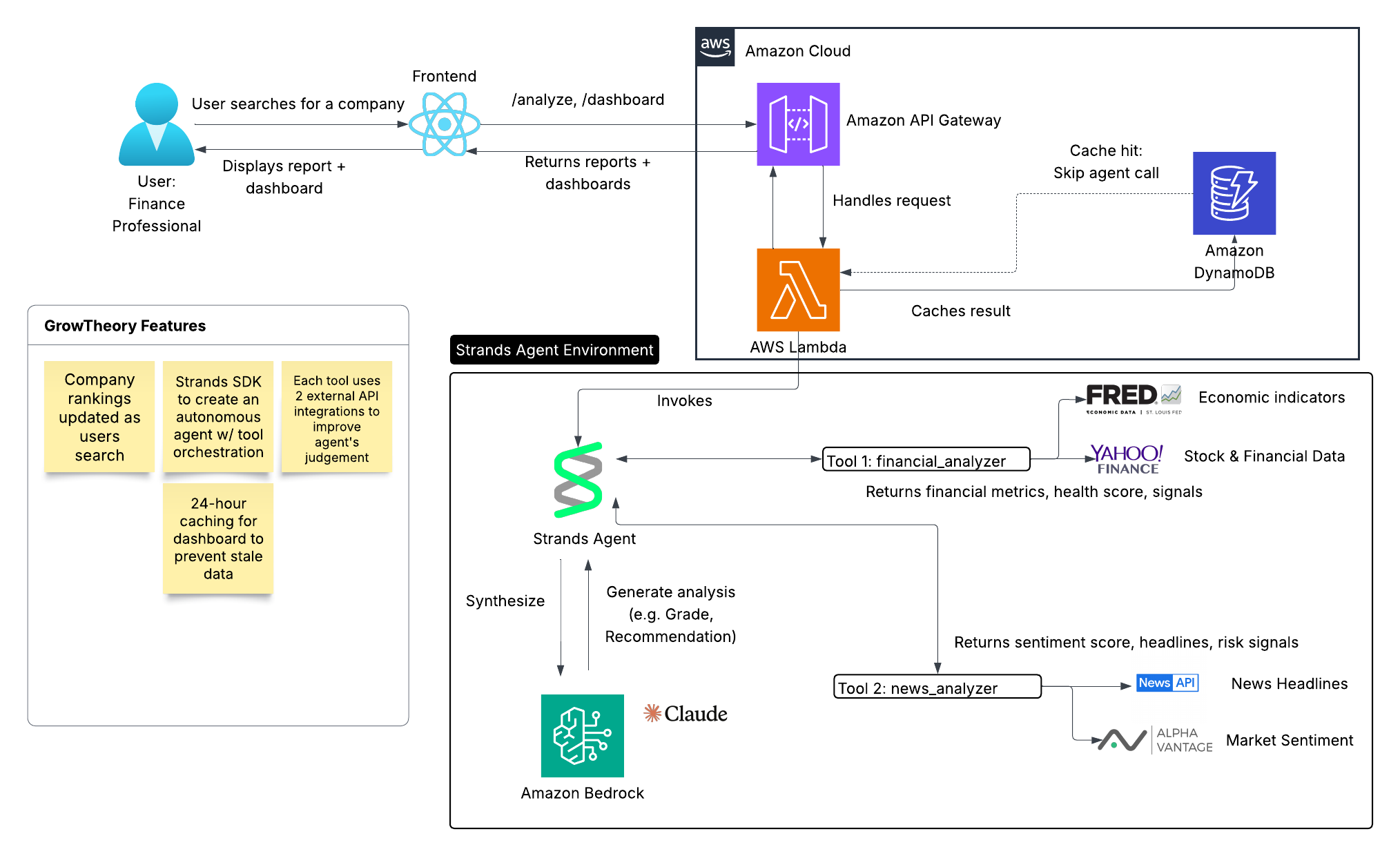
GrowTheory: Real-Time Investment Intelligence
Inspiration
We noticed a fundamental problem: financial analysts spend hours synthesizing data from multiple sources like stock prices, economic indicators, market sentiment, new. The data exists everywhere, but nobody automates the synthesis. We wanted to build an AI system that could do in seconds what typically takes hours of manual work.
What We Built
GrowTheory is a financial intelligence platform powered by an AI agent that orchestrates multiple data sources to deliver company analysis instantly. When a user searches for a company, the system checks for cached results (< 24 hours). If found, it returns instantly. If not, a Strands agent activates and calls two specialized tools:
- Financial Analyzer: Pulls hard metrics (revenue, profit margins, market cap) from Yahoo Finance and pairs them with economic context (unemployment, average wages) from FRED
- News Analyzer: Gathers quantitative market sentiment from AlphaVantage and scans headlines with NewsAPI for operational signals (hiring, layoffs, crises)
The agent synthesizes this data into a professional investment report. Results are cached in DynamoDB for 24 hours to prevent redundant API calls. A dashboard displays all analyzed companies with smart pagination.
How We Built It
We used AWS Lambda with Python for the backend, DynamoDB for persistent caching, and the Strands SDK to orchestrate the agent with Claude 3.5 Haiku as the reasoning model. The frontend is React + Javascript. We integrated four external APIs: Yahoo Finance, FRED, AlphaVantage, and NewsAPI.
The architecture hinges on a dual-layer caching strategy: Lambda memory caches the dashboard for 5 minutes, while DynamoDB caches full company analyses for 24 hours with TTL expiration. This reduced API calls by approximately 90% for repeat queries.
What We Learned
Agentic AI Architecture: We deepened our understanding of how agents work, specifically the relationship between tools, prompts, and model reasoning. The agent isn't just a wrapper around tools; it's a coordinator that decides which tools to call, in what order, and how to synthesize their outputs. Getting this right requires clear tool descriptions and disciplined prompt engineering.
Smart Caching is Essential: With potentially thousands of invocations daily, naive API calls would be prohibitively expensive and slow. Our dual-layer caching strategy proved crucial. Lambda memory provides microsecond-level caching for the dashboard, while DynamoDB handles long-term persistence.
Data Standardization Throughout the Pipeline: The hardest challenge was maintaining consistent data formats as information flowed from APIs through the agent to the frontend. Yahoo Finance returns revenue in raw dollars (sometimes millions, sometimes billions). The agent needs to understand this. The frontend needs to parse it. This entire flow sometimes presented tons of challenges in understanding how our data is transformed by the inference model, and at times we had to really trace down the flow of data to present everything properly.
Tools vs. Agent vs. Prompt Clarity: We initially struggled with responsibilities. Should the tool handle formatting or the agent? Should the agent parse output or just pass it through? We learned that clarity comes from strict separation: tools normalize and validate data, agents coordinate and reason, prompts enforce structure. When we forced the agent to output with exact labels ("Annual Revenue:", "Market Cap:"), the frontend could reliably parse with regex. This standardization across unstandardized inputs became our secret weapon.
Challenges
1. Data Format Inconsistency: APIs return data at different scales and in different units. We solved this by creating normalized output at the source (the tools), not downstream.
2. Agent Output Reliability: Left to its own devices, the agent would generate verbose, unstructured responses. We solved this with strict prompt formatting and exact output labels.
3. Graceful Degradation: If one API fails, should the whole system fail? We designed each tool to return a "status" field (complete/partial/failed), allowing the agent to provide analysis even with incomplete data.
4. Cost and Performance: Multiple API calls per query would be expensive and slow. Our dual-layer caching strategy reduced API calls by 90%, addressing both concerns.
The biggest insight: agentic systems require discipline across every layer: tool design, prompt engineering, caching strategy, and data standardization. It also demystified agentic AI for us a ton, and give us insights into the kind of real power it has when you harness it. Everyone knows the power of LLMs for general purpose stuff like chatting with Claude, but in combination with APIs, it amplifies the power of automation by an extraordinary degree.
Built With
- amazon-dynamodb
- amazon-web-services
- lambda
- python
- react
- strands

Log in or sign up for Devpost to join the conversation.