-
-

function to find similarity
-
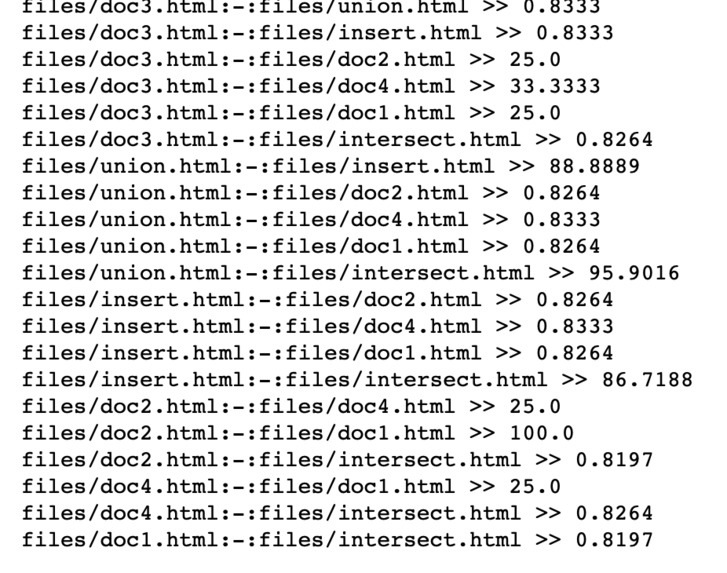
result of files similarity score

Inspiration
With the large number of documents on the Internet, there is an increasing need to be able to automatically process those documents for information extraction, and similarity clustering. The structural information is an important clue as to the meaning of documents. Identifying documents that are structurally "similar" in each other, is an important mechanism to related similar documents that may have sufficiently different content as to make text-based similarity mechanisms nonfunctional.
What it does
The tool compares two HTML files to each other, generates the bag of paths from root node to leaf nodes or till the level that user configured (considering root node at level 0), and calculate their similarity score.
How we built it
After going through different research papers, and different algorithms, I've chosen simple algorithm to get the similarity of two HTML file in order to get result on short span of time.
For building, I used my skill on Python language and its great library for parsing HTML files, which is BeautifulSoup.
Challenges we ran into
The main challenge during this project is the time constrain. And other challenges that I faced are understanding the research paper during first time.
Accomplishments that we're proud of
After intensive reading and thinking, I was able to choose one algorithm in order to achieve goals in short span of time.
What we learned
The main thing I learnt is the importance of teammate to achieve the end result when time is the limit.
What's next for Group / Classify Documents Based on Structure
Current tool is able to get the similarity score between two files. The next for this tool are
- make a clusters files based on the similarity score
- user friendly UI
- try out other algorithms which I left out due to time constrain.
Built With
- jupyter
- python

Log in or sign up for Devpost to join the conversation.