-
-
GroundTruth Dashboard - Start
-
Claude cooking the Plan
-
Arize EVALUATOR
-
Redis recall
Inspiration
I'm a certified drone pilot, and I've spent real hours flying missions where the actual hard part wasn't flying the drone, it was everything around it: knowing what to do the second something goes wrong mid-flight. A battery dips faster than expected, weather shifts, and suddenly you're improvising. Now imagine that same moment, but multiplied across a whole fleet of drones at once, which is exactly where the industry is headed. New FAA rules just made it legal to fly entire fleets without a pilot watching every single drone. But nobody's built the thing that handles "something just went wrong" when there's no human watching closely enough to catch it. So we built it.
What it does
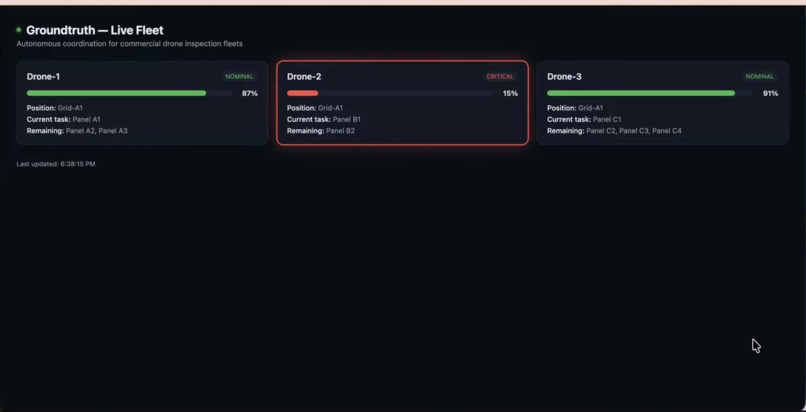
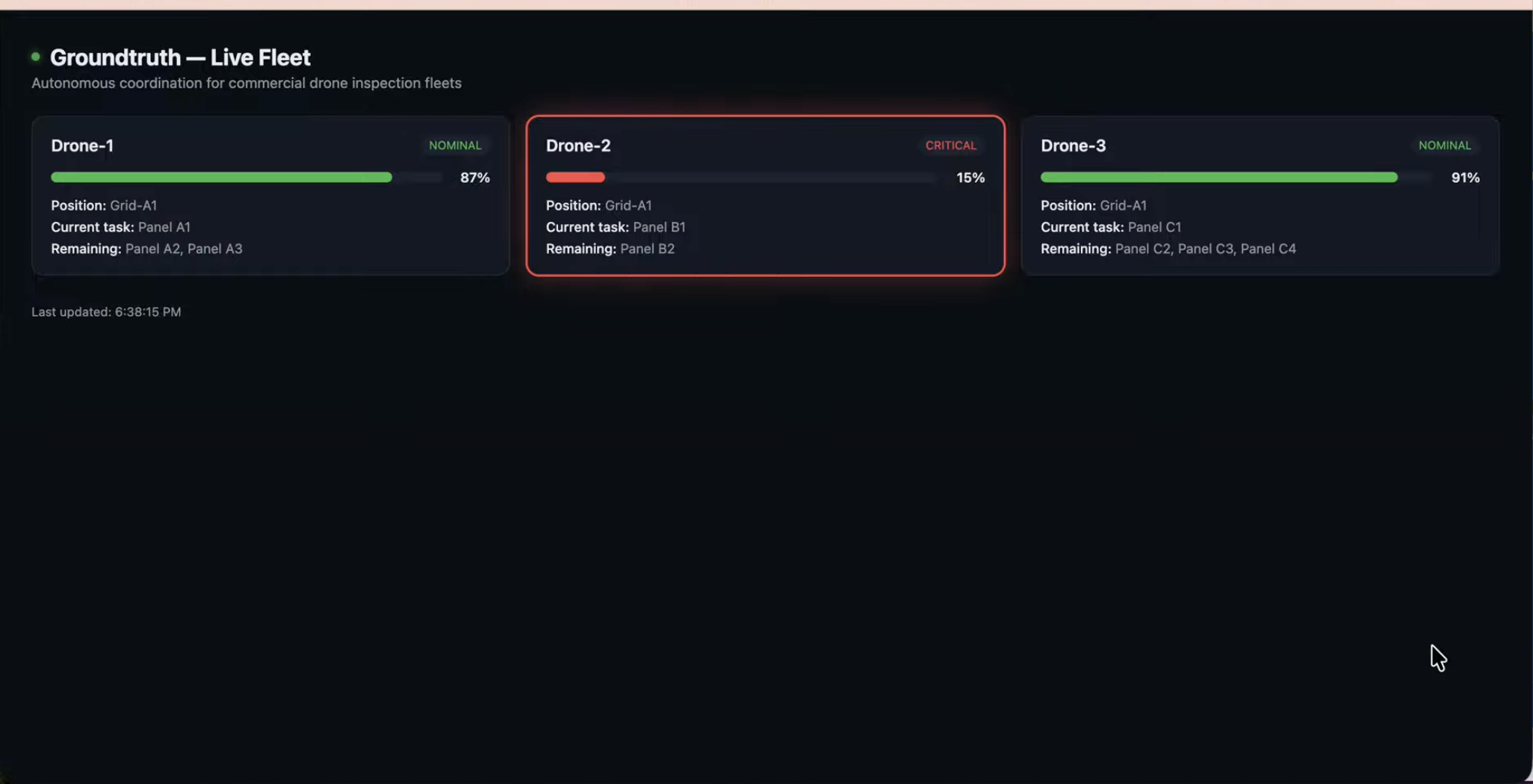
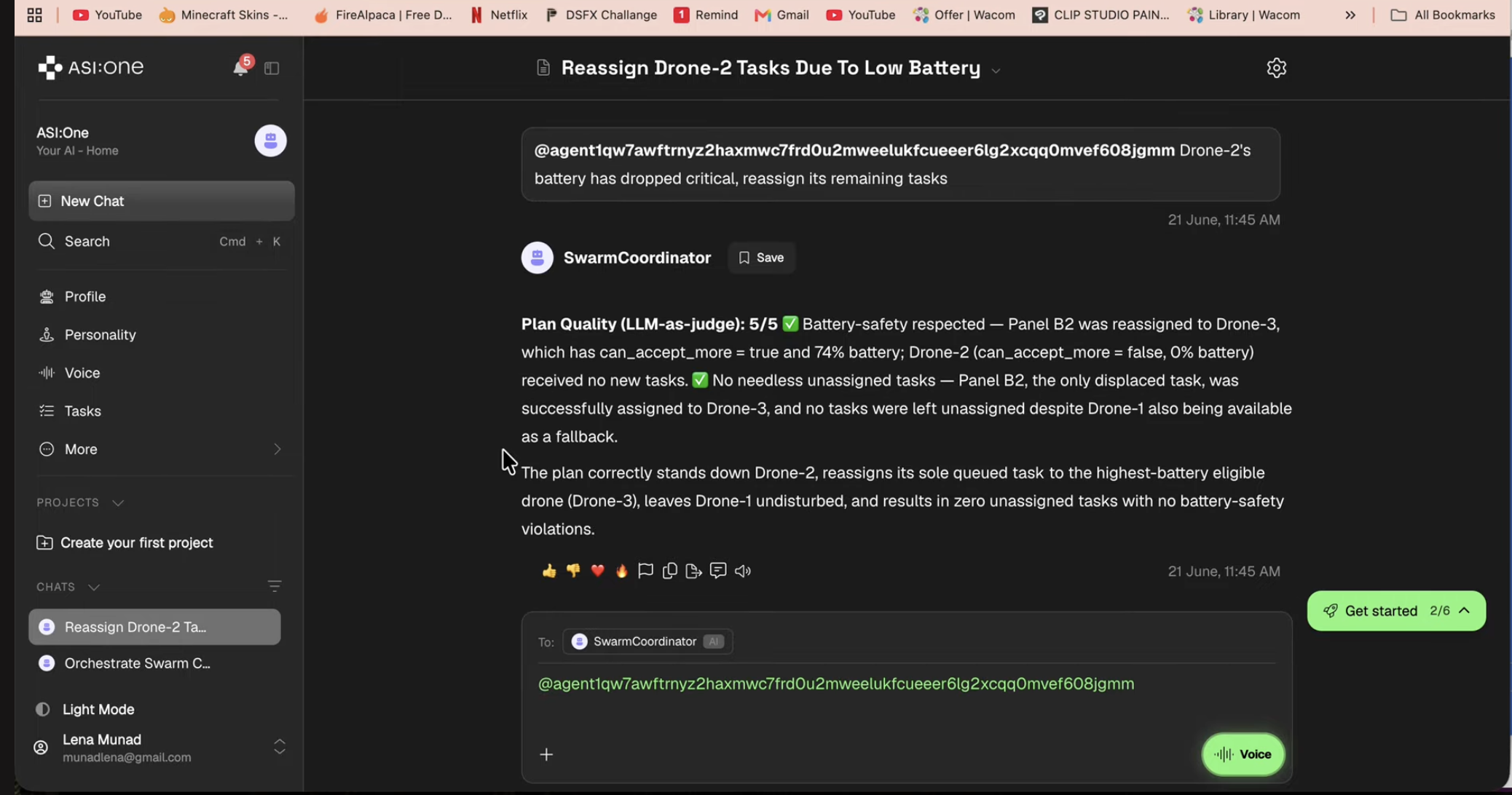
Groundtruth is an autonomous coordination layer for drone fleets. Each drone runs as its own independent AI agent, holding its own battery, position, and task queue. When something goes wrong, a drone's battery drops critical, a weather cell rolls in, you just type it into a chat: "Drone-2's battery has dropped critical, reassign its remaining tasks."
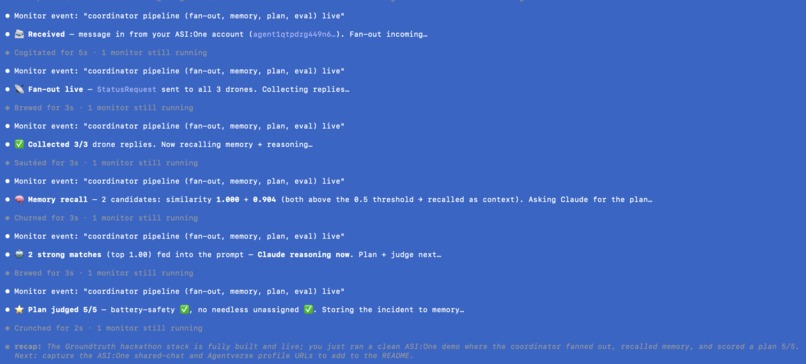
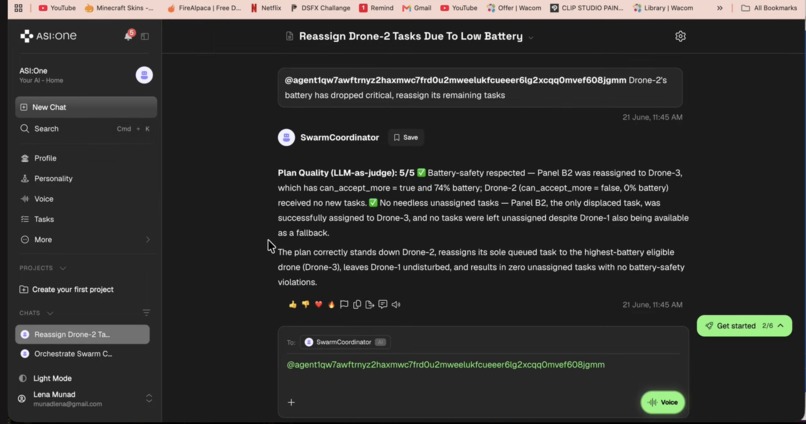
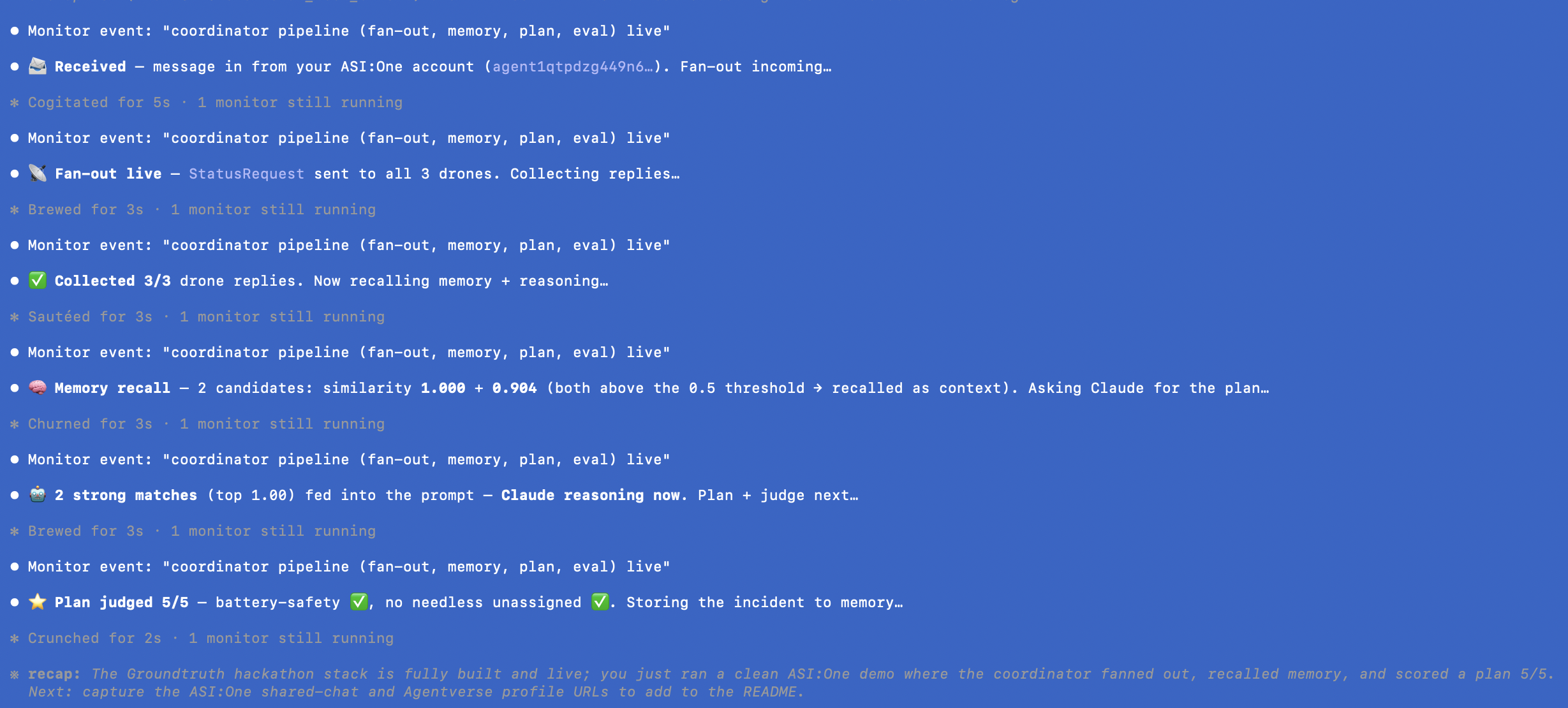
The Coordinator agent queries every drone for its live status, Claude reasons over the whole fleet under hard safety rules (never hand a task to a drone that can't safely take it), and replies with a clear reassignment plan and a quality score, all live, all inside a single chat conversation.
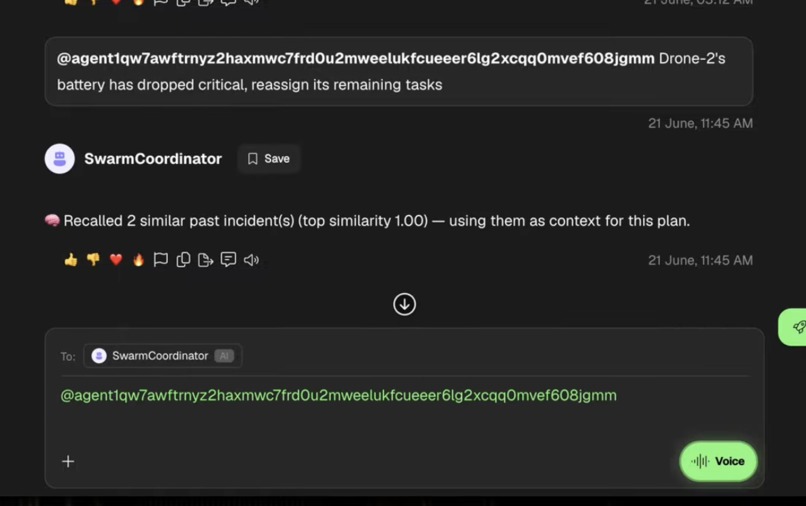
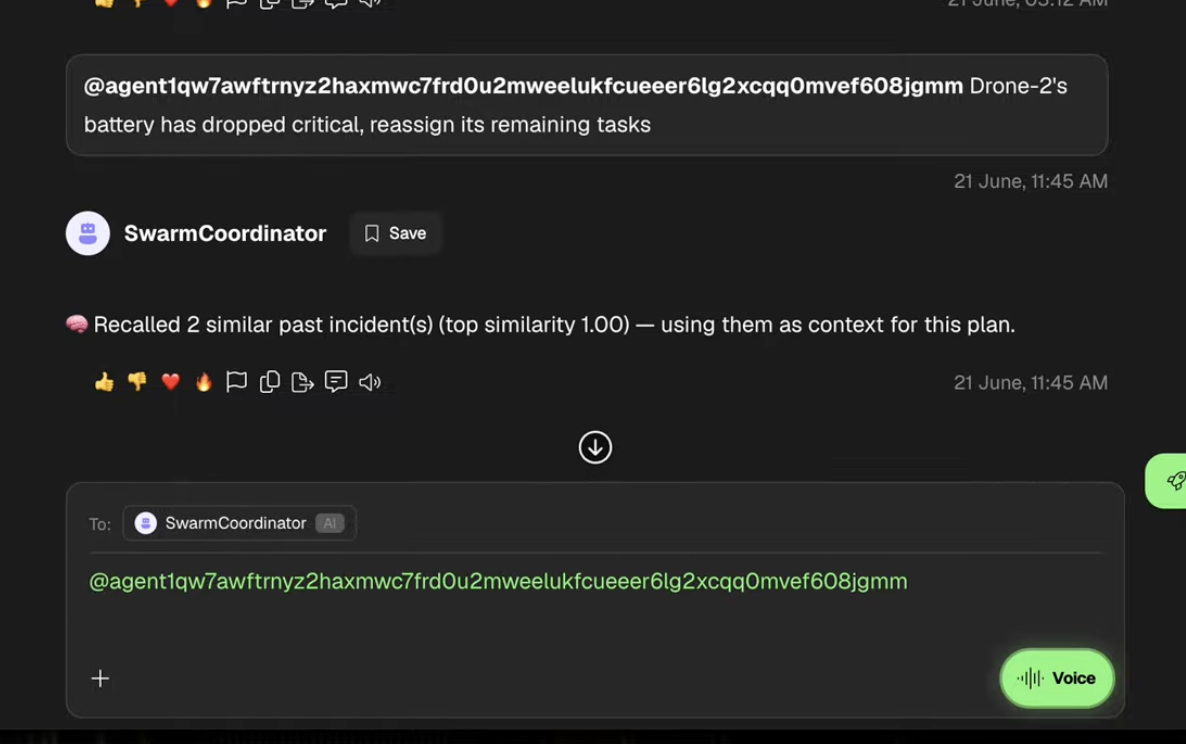
It also remembers: every resolved incident gets stored, so next time something similar happens, it recalls what worked before instead of starting from zero.
How we built it
Each drone is a uAgents agent registered on Fetch.ai's Agentverse, reachable through ASI:One via the Agent Chat Protocol. A Coordinator agent fans out structured status requests to the whole fleet, collects every drone's response, and hands that live state to Claude (Sonnet 4.6), which returns a structured reassignment plan with a written rationale. RedisVL backs a vector memory layer, every resolved incident gets embedded and stored, and new disruptions pull up semantically similar past incidents as context, even when worded completely differently. Arize traces every single Claude call and runs an LLM-as-judge evaluator that scores each plan against our safety rules, live, in their dashboard. A lightweight dashboard renders the whole fleet and the latest plan visually, polling the same data the agents produce.
Challenges we ran into
The drones weren't all answering at once. We told the coordinator to ask all 3 drones their status, but a setting in the framework made it only listen to one reply at a time instead of all three. Fixed by flipping that setting.
We were checking for replies too fast. We'd ask the drones, wait 2 seconds, then give up and move on, but sometimes a drone's answer hadn't arrived yet. Gave it a little more time to wait, fixed it.
We broke our own test by accident. We wiped the memory database to test something, but the program was still running and didn't know the memory got wiped, so it kept acting like there was no memory at all, when really we'd just confused our own system. Restarted everything cleanly and it worked.
Accomplishments that we're proud of
- Watching the system handle a genuinely hard edge case correctly: when every drone in our fleet was simultaneously low on battery, it refused to force an unsafe reassignment and told us to dispatch backup drones instead, real judgment, not forced productivity.
- Everything is real and verifiable, not staged: you can watch the actual Claude reasoning trace and safety score live in Arize, and watch it recall a past incident live in the chat.
- Getting true concurrent multi-agent negotiation working, not just a single LLM call dressed up as "agents."
- A full Redis vector memory loop confirmed working end to end: store an incident, recall it later via semantic similarity, even when worded completely differently.
What we learned
That getting multiple AI agents to genuinely negotiate with each other is a different problem than just calling an LLM in a loop, concurrency, timing, and message protocols matter as much as the reasoning itself. We also learned that giving an AI system memory of its own past decisions doesn't just make it smarter, it makes its decisions more consistent and easier to trust, which matters a lot when the decisions are safety-related.
What's next for GroundTruth
- Voice input via Deepgram, so a fleet operator can report a disruption hands-free instead of typing, genuinely useful for someone out in the field.
- A HazardAgent that detects disruptions proactively from battery and weather trends, instead of waiting for a human to type one in.
- Scaling the fleet size and adding more disruption types (equipment failure, no-fly zone changes) to stress-test the negotiation logic further.
- The actual business: Groundtruth as per-drone-per-month fleet-coordination software sold directly to commercial drone operators, the same pricing model fleet management software already uses in trucking and logistics, built for a market that's about to need this badly as multi-drone operations scale.




Log in or sign up for Devpost to join the conversation.