-
-
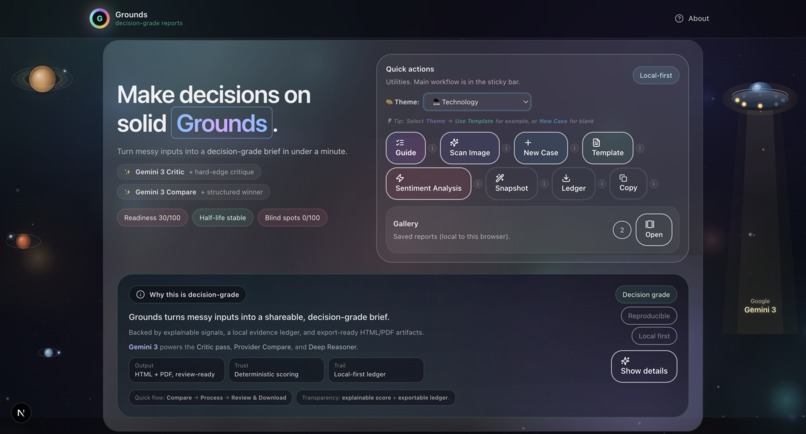
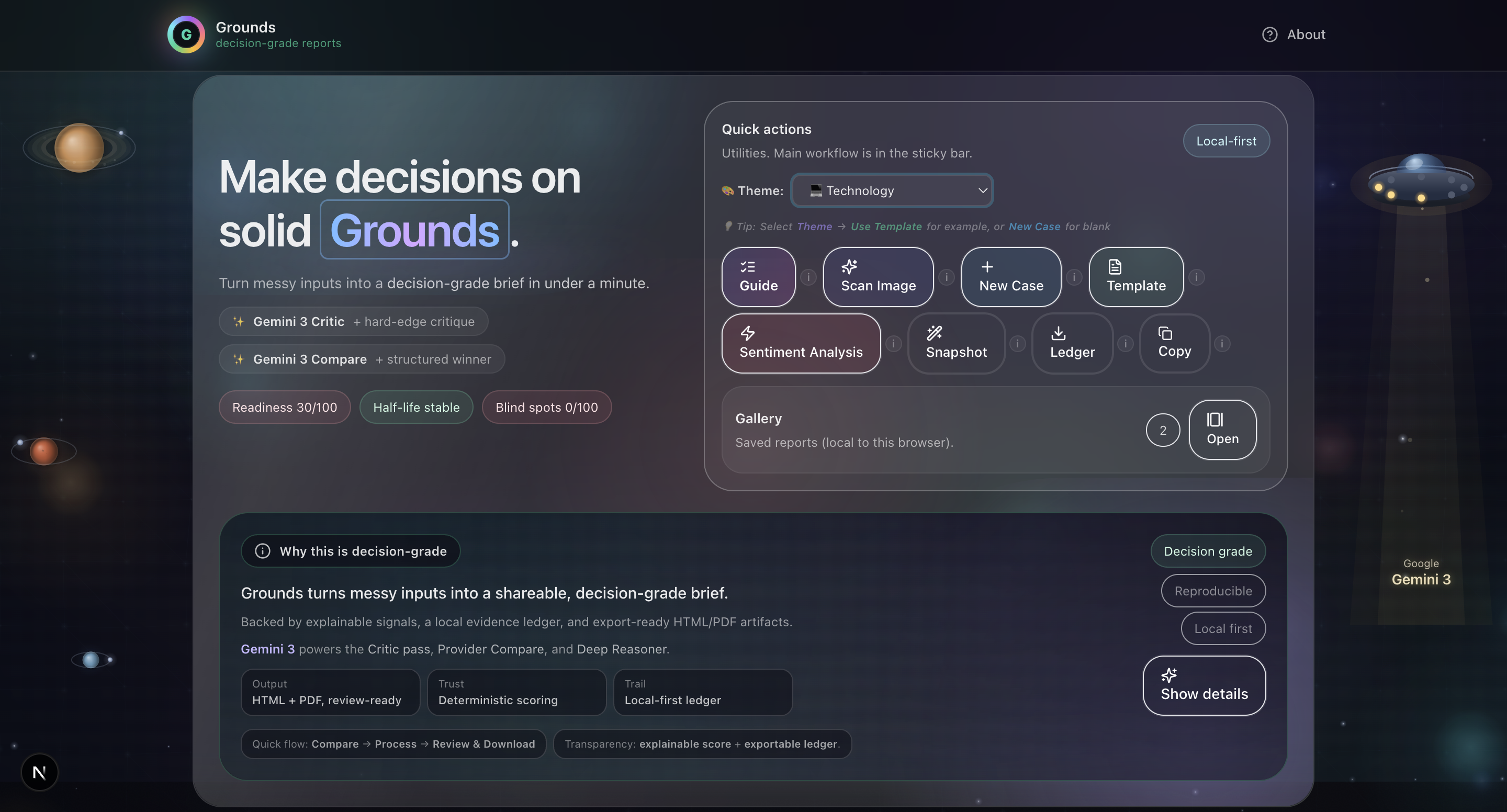
Grounds home dashboard. Start a decision case, run Critic/Compare/Deep Reasoner, and export a decision-grade brief with full audit trails.
-
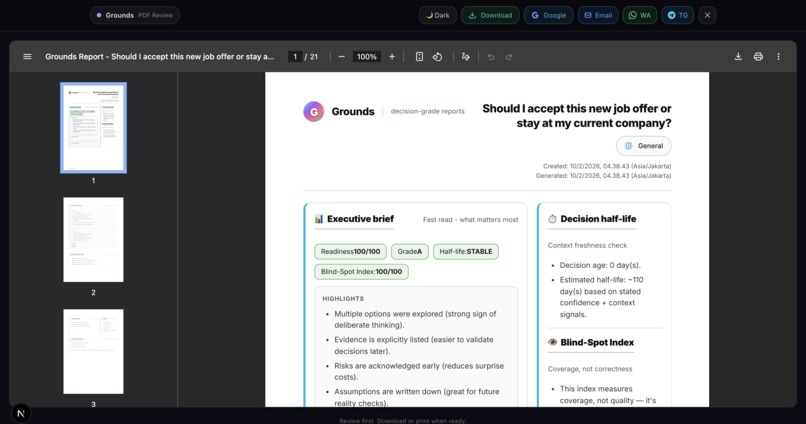
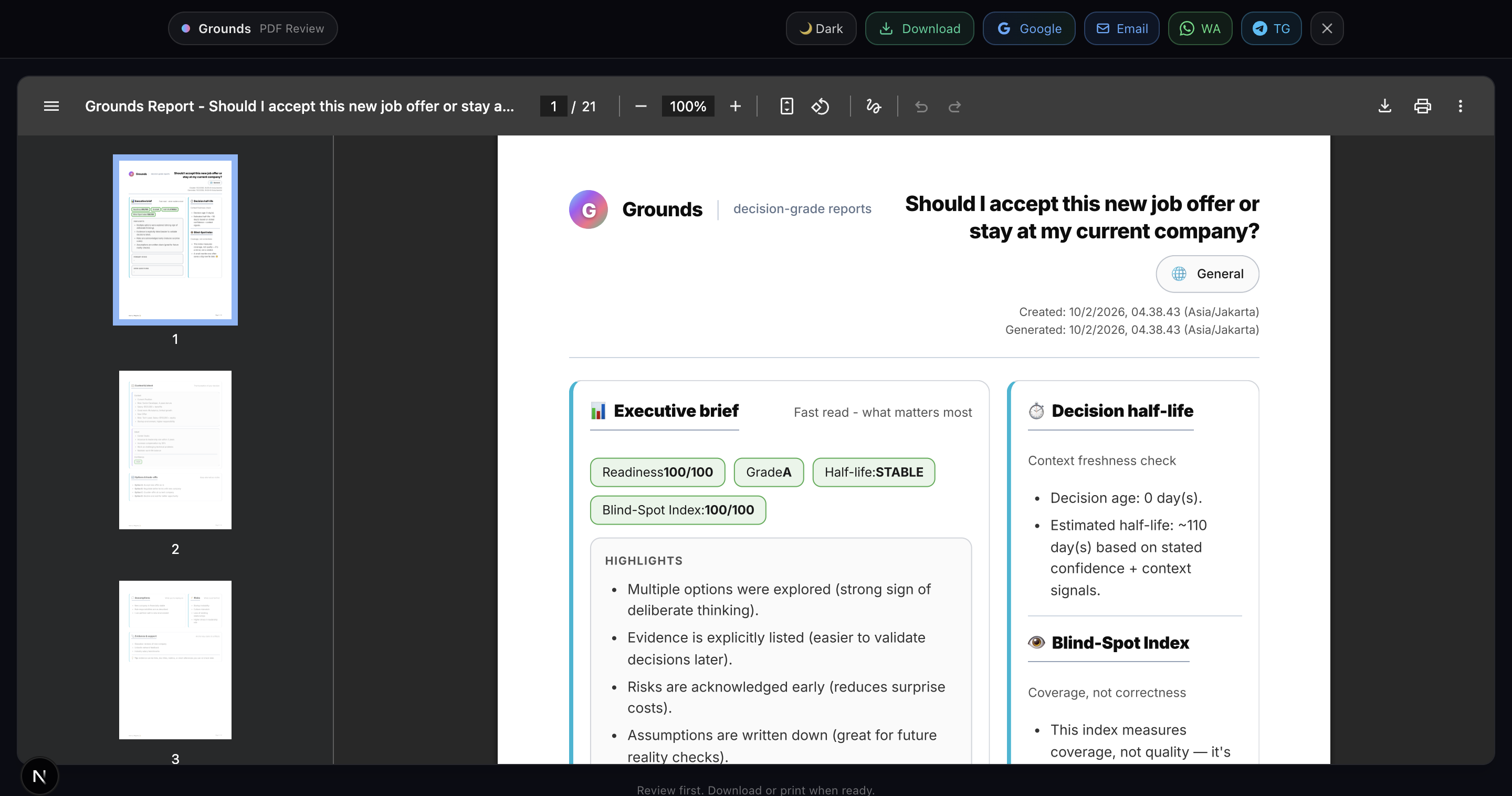
Sample output: Grounds Report (PDF)
-
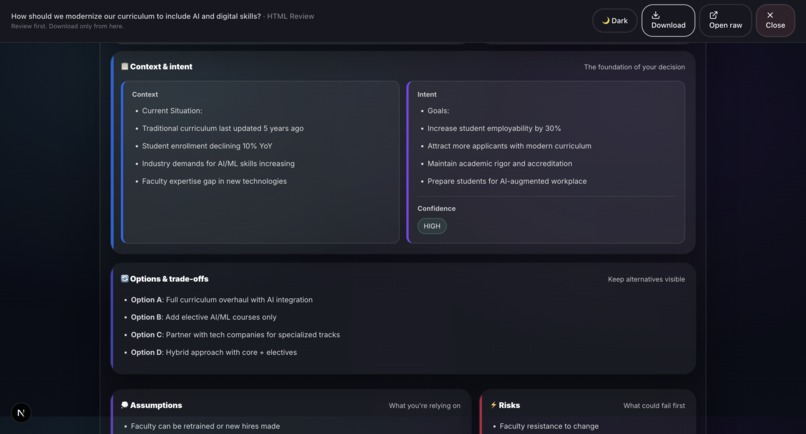
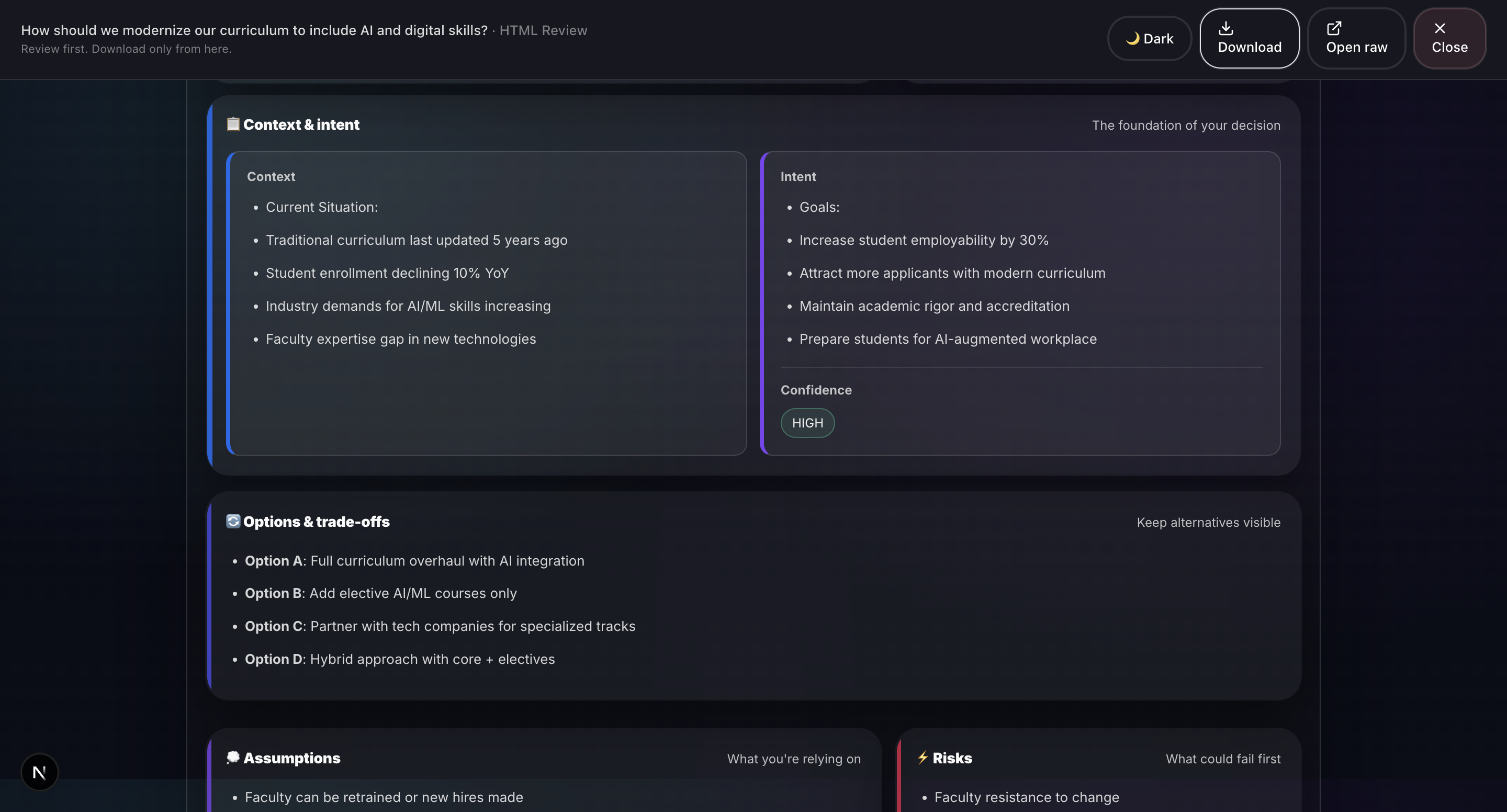
Sample output: Grounds Report (HTML)2
-
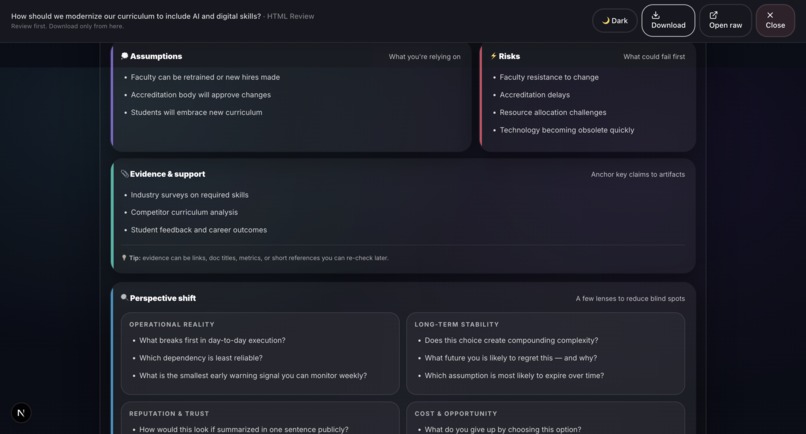
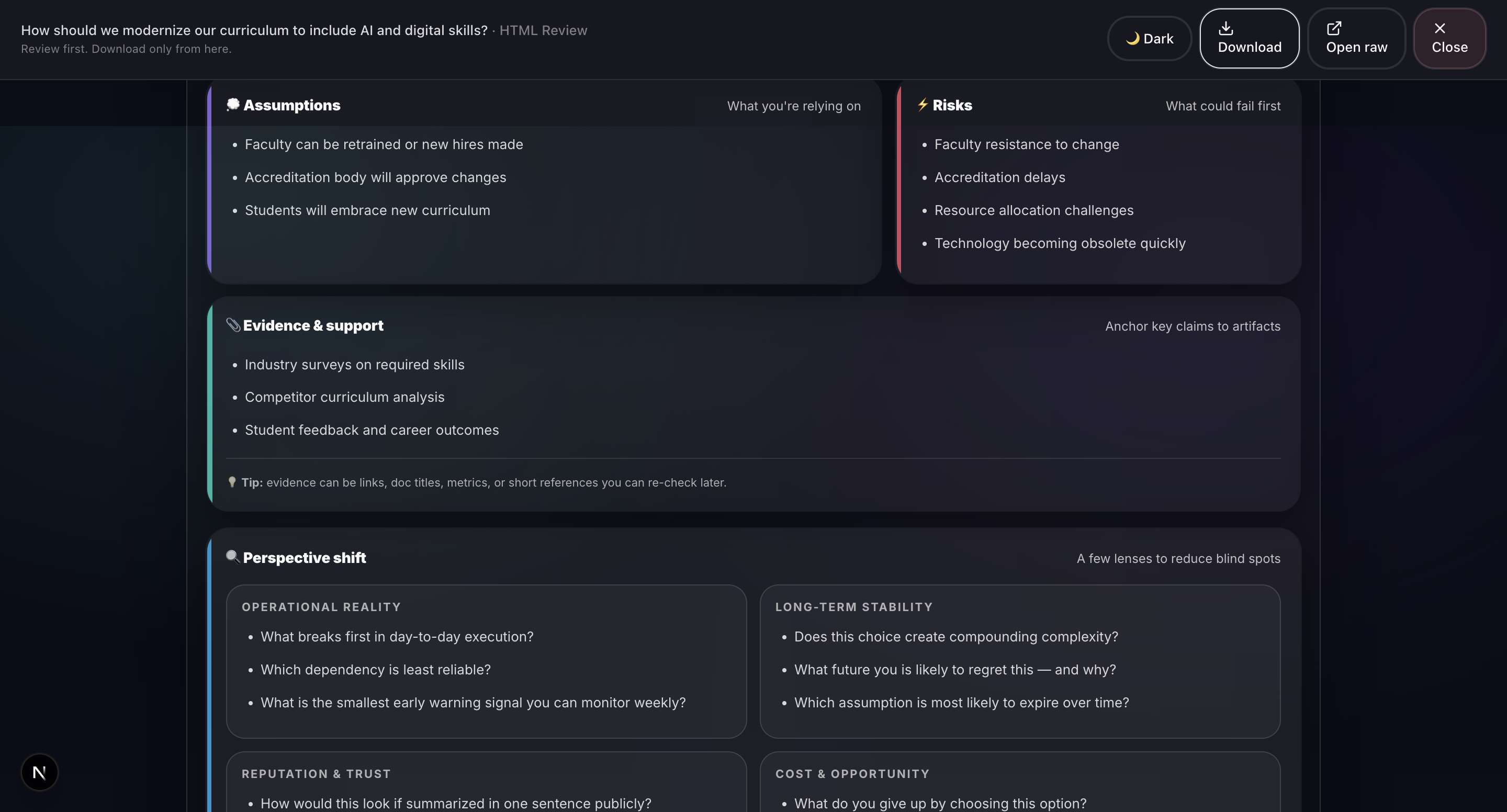
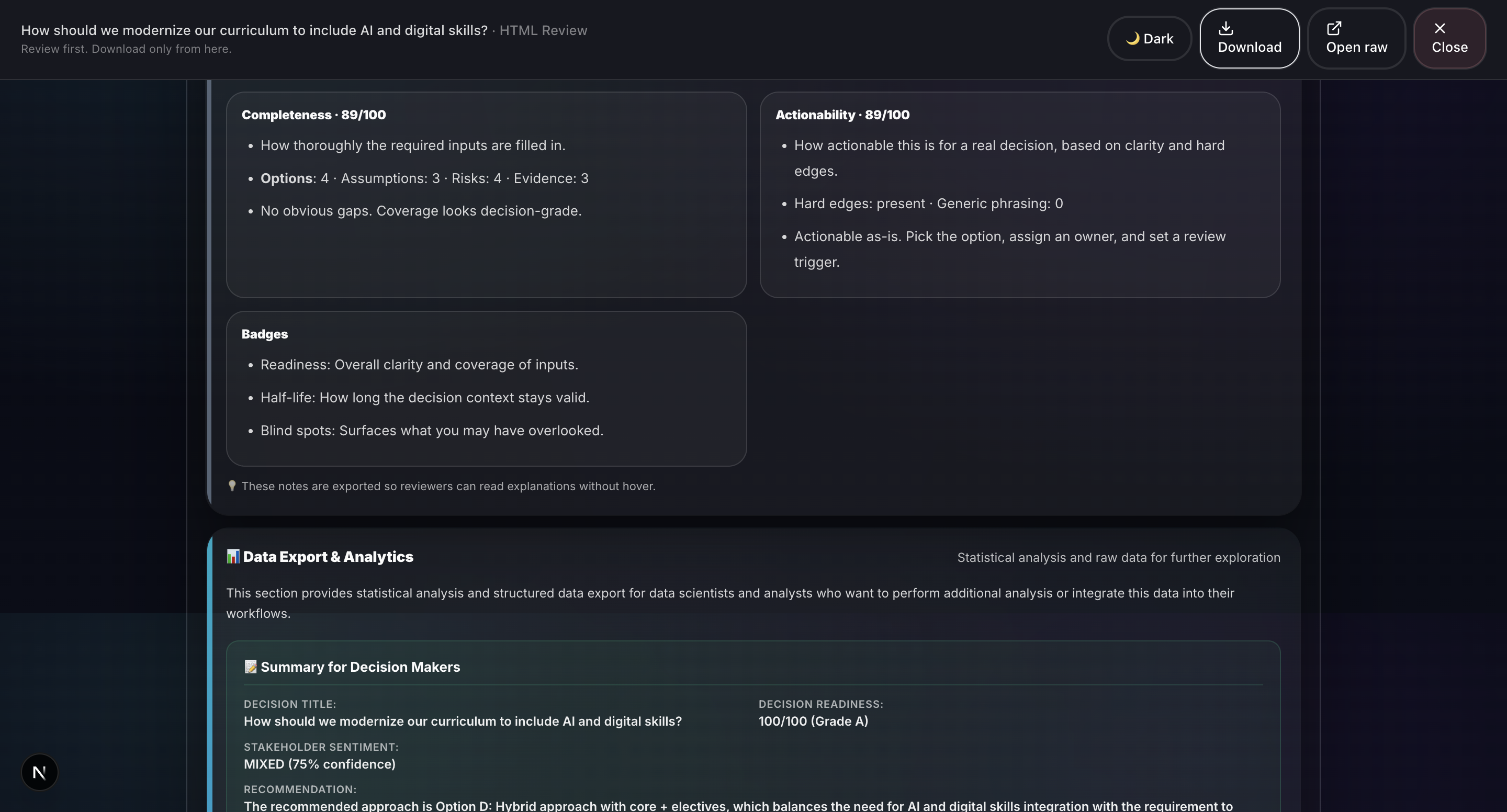
Sample output: Grounds Report (HTML)3
-
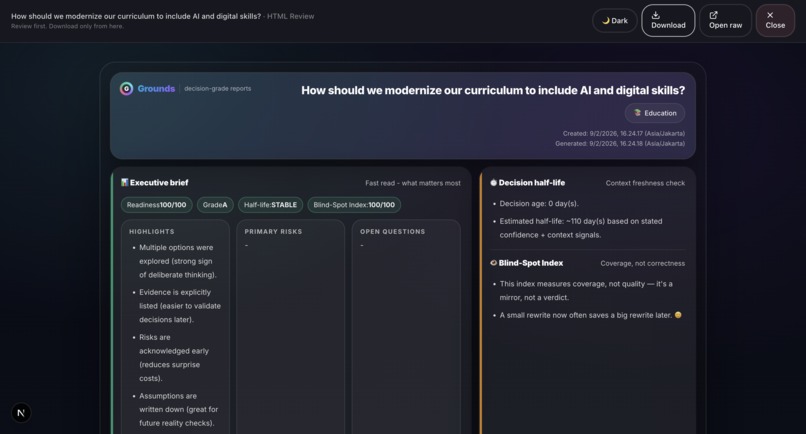
Sample output: Grounds Report (HTML)1
-
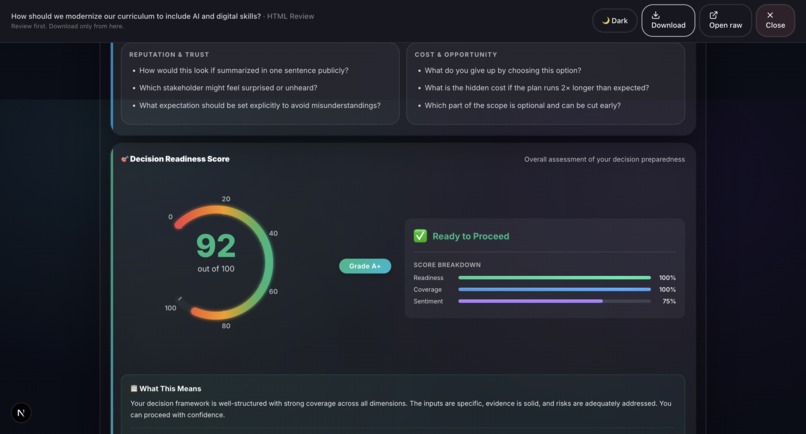
Sample output: Grounds Report (HTML)4
-
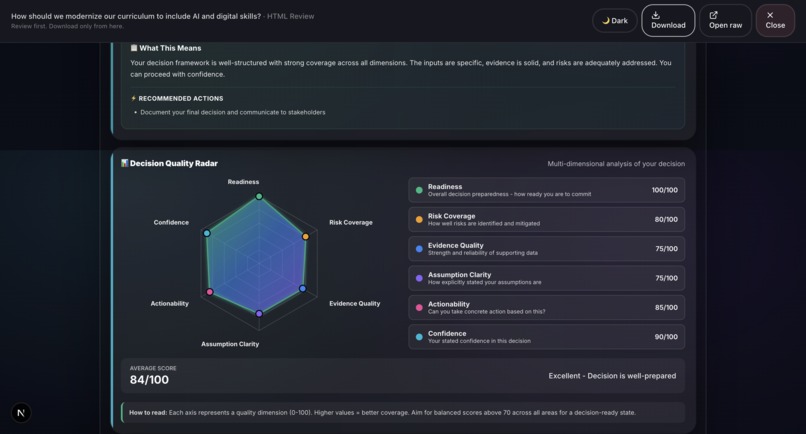
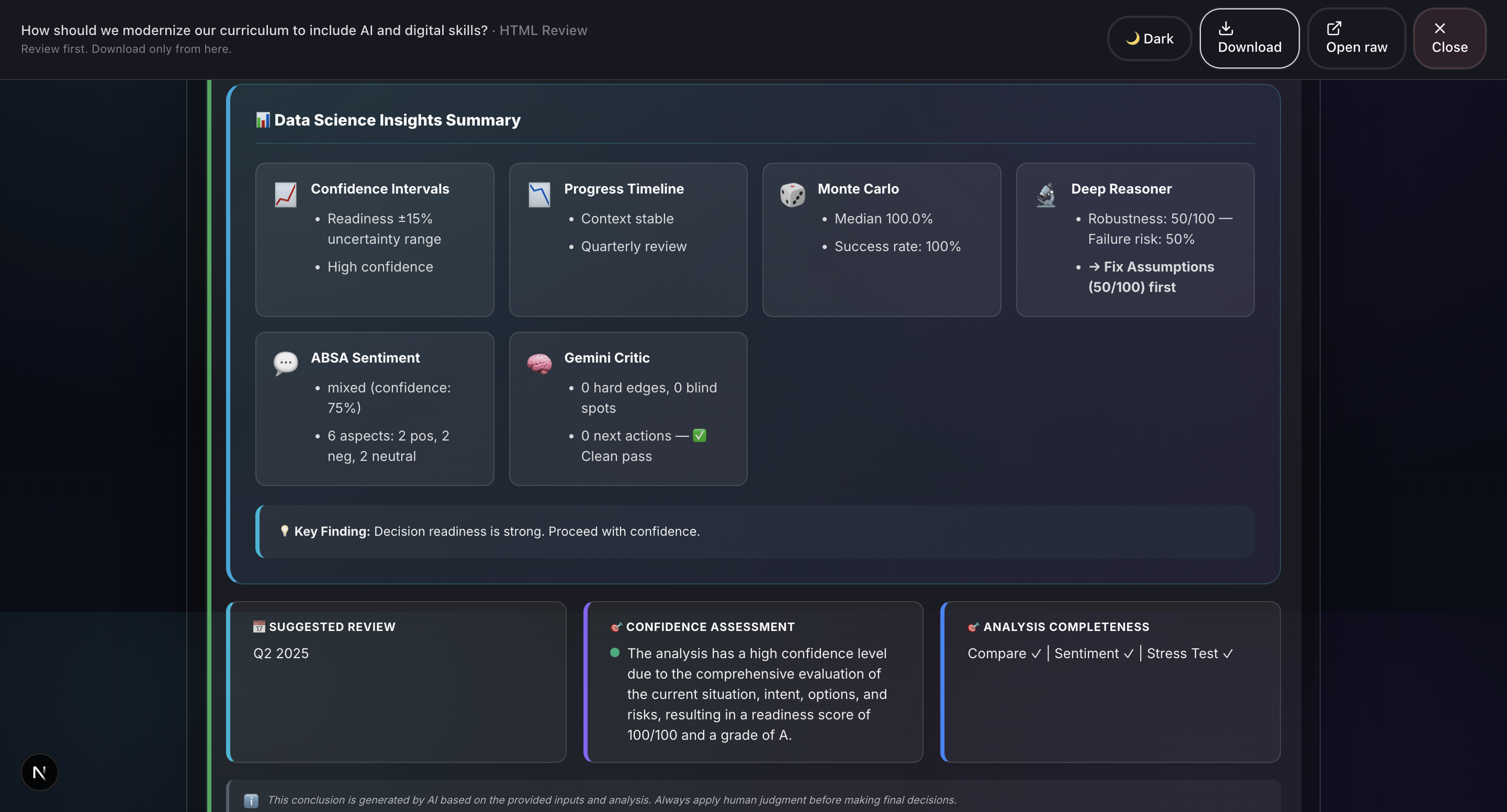
Sample output: Grounds Report (HTML)5
-
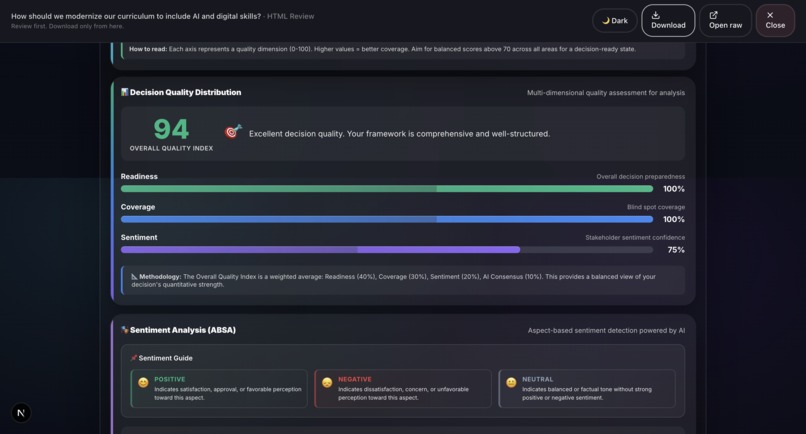
Sample output: Grounds Report (HTML)6
-
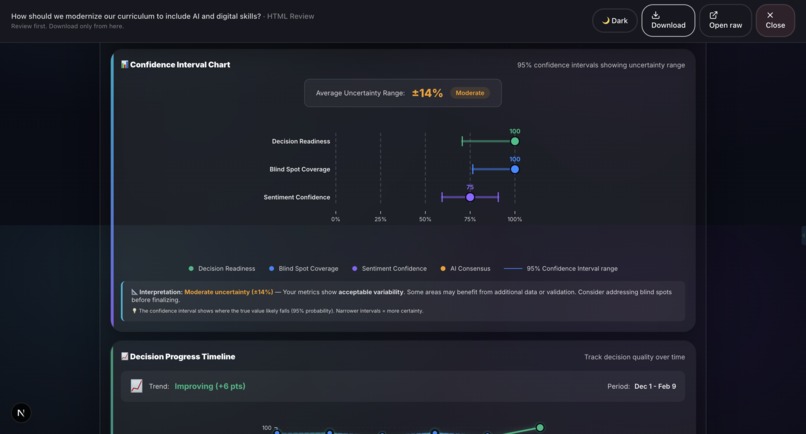
Sample output: Grounds Report (HTML)9
-
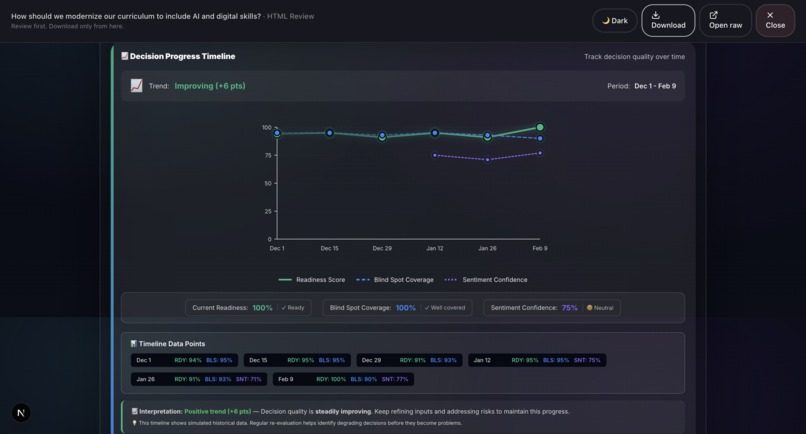
Sample output: Grounds Report (HTML)10
-
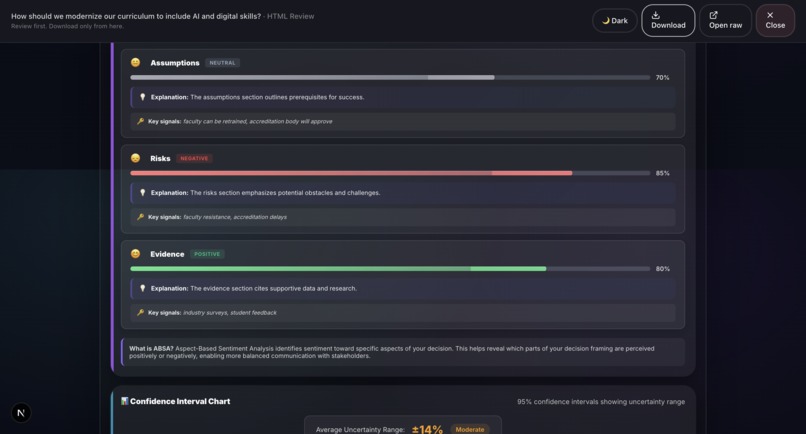
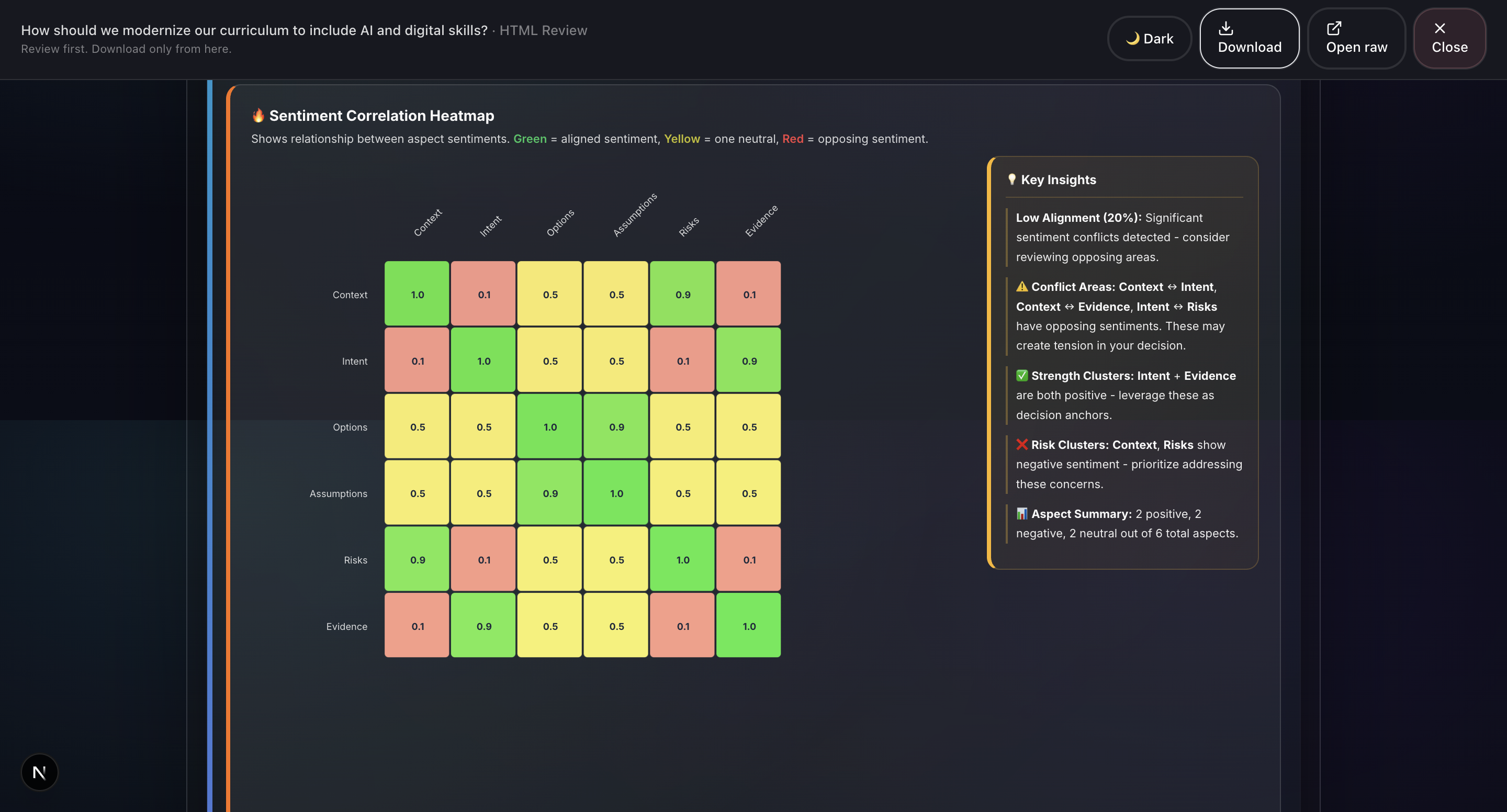
Sample output: Grounds Report (HTML)8
-
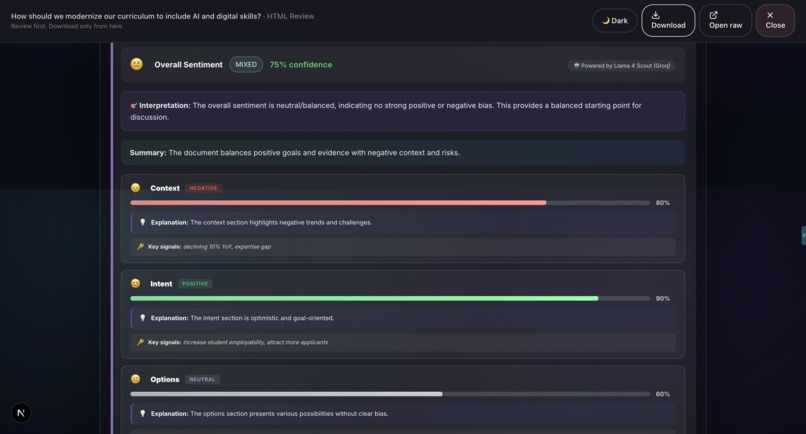
Sample output: Grounds Report (HTML)7
-
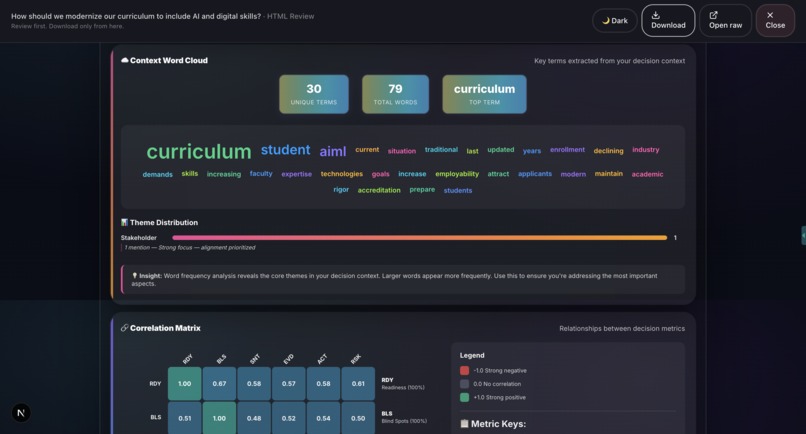
Sample output: Grounds Report (HTML)11
-
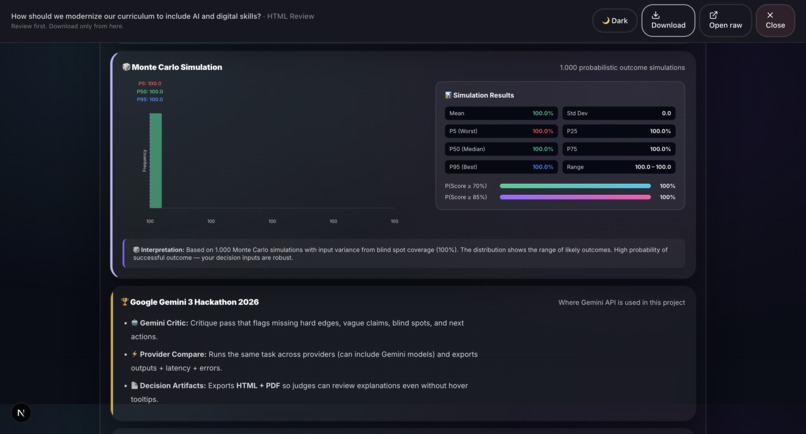
Sample output: Grounds Report (HTML)13
-
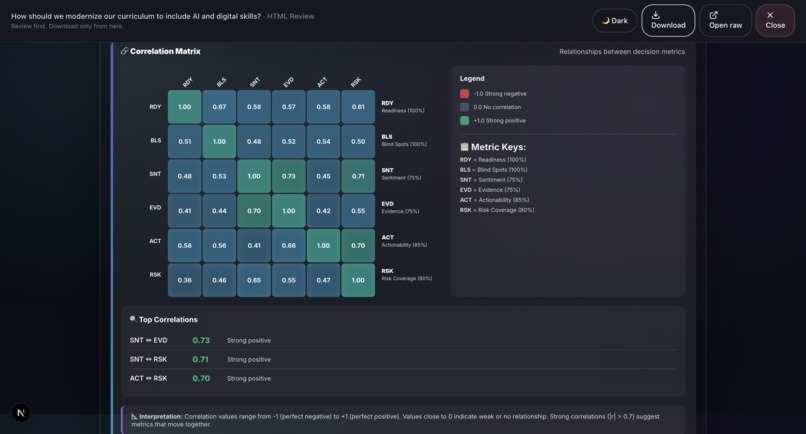
Sample output: Grounds Report (HTML)12
-
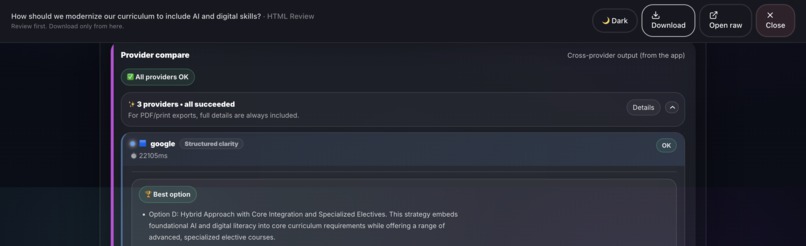
Sample output: Grounds Report (HTML)15
-
Sample output: Grounds Report (HTML)14
-
Sample output: Grounds Report (HTML)20
-
Sample output: Grounds Report (HTML)19
-
Sample output: Grounds Report (HTML)17
-
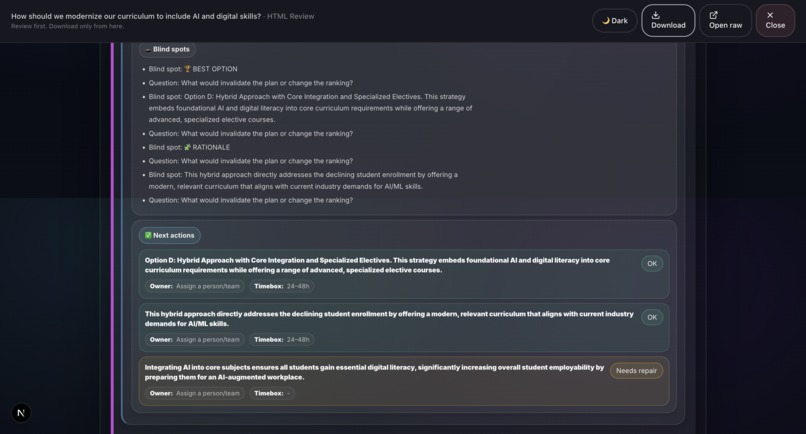
Sample output: Grounds Report (HTML)18
-
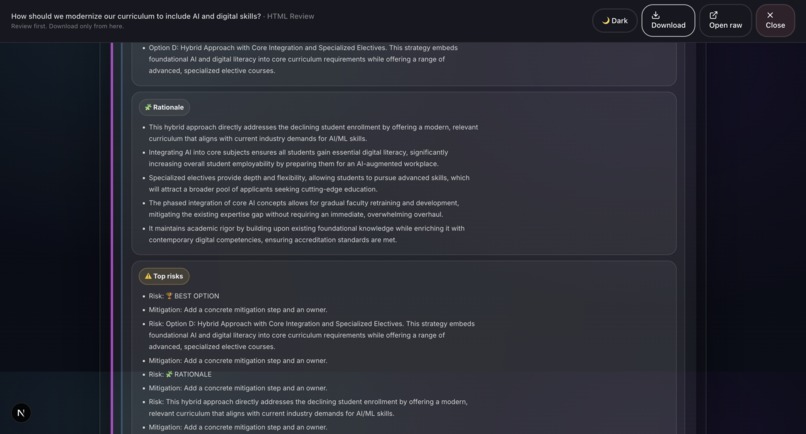
Sample output: Grounds Report (HTML)16
-
Sample output: Grounds Report (HTML)34
-
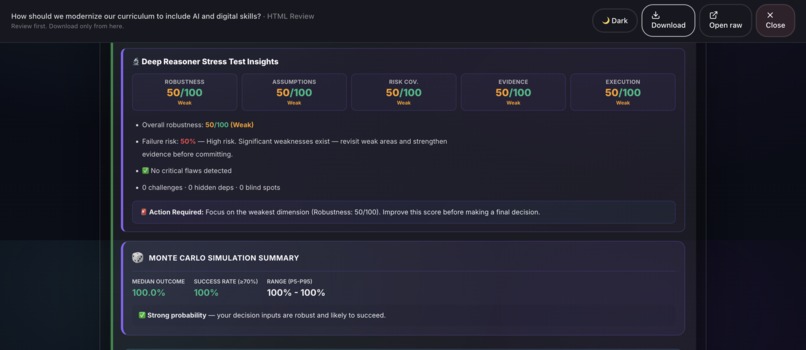
Sample output: Grounds Report (HTML)31
-
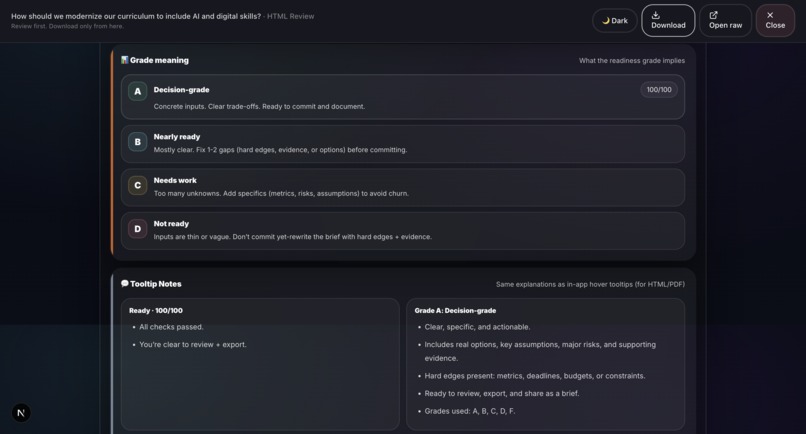
Sample output: Grounds Report (HTML)23
-
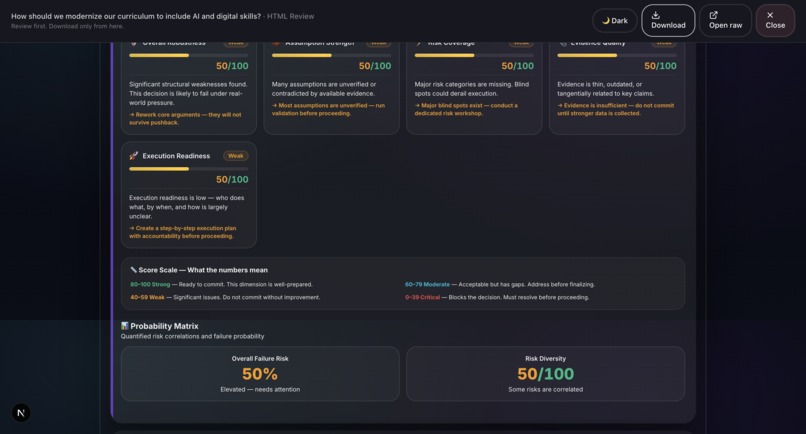
Sample output: Grounds Report (HTML)22
-
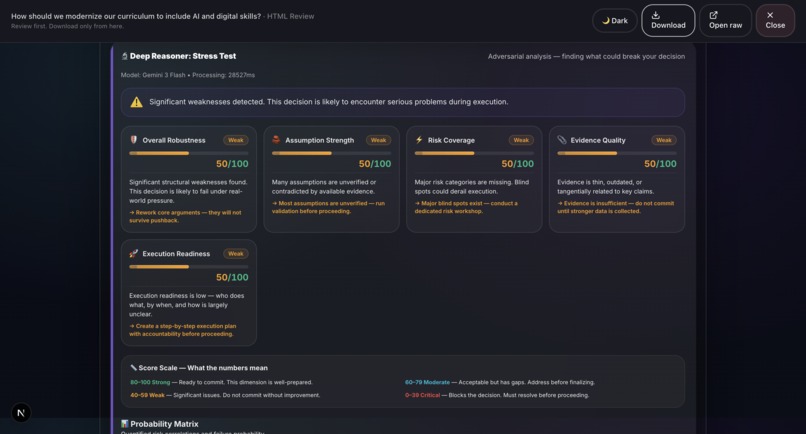
Sample output: Grounds Report (HTML)21
-
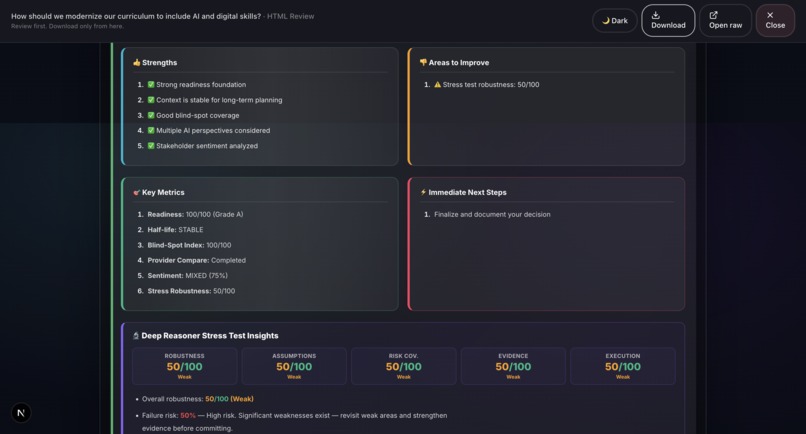
Sample output: Grounds Report (HTML)30
-
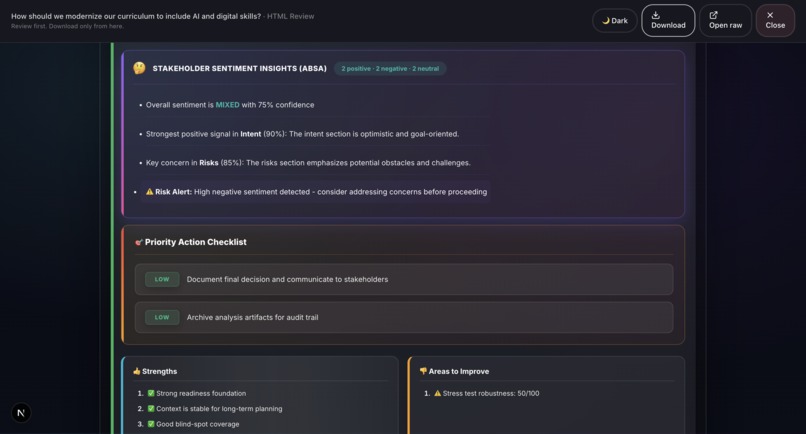
Sample output: Grounds Report (HTML)29
-
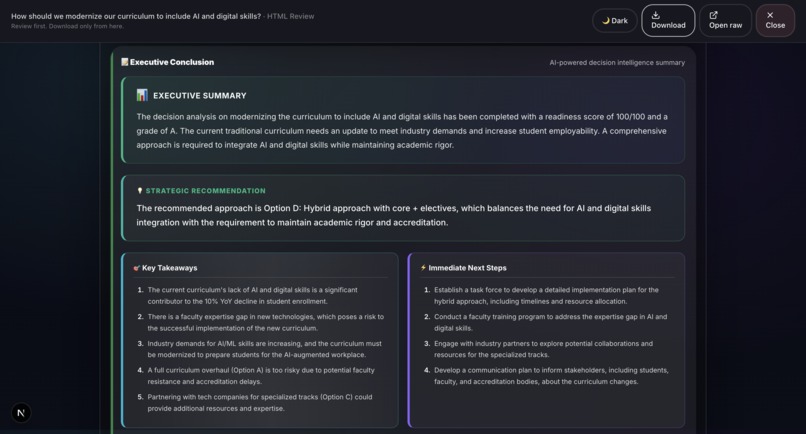
Sample output: Grounds Report (HTML)28
-
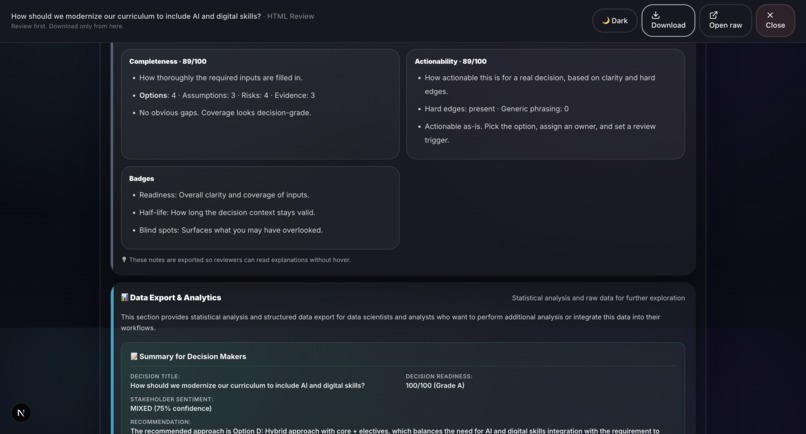
Sample output: Grounds Report (HTML)24
-
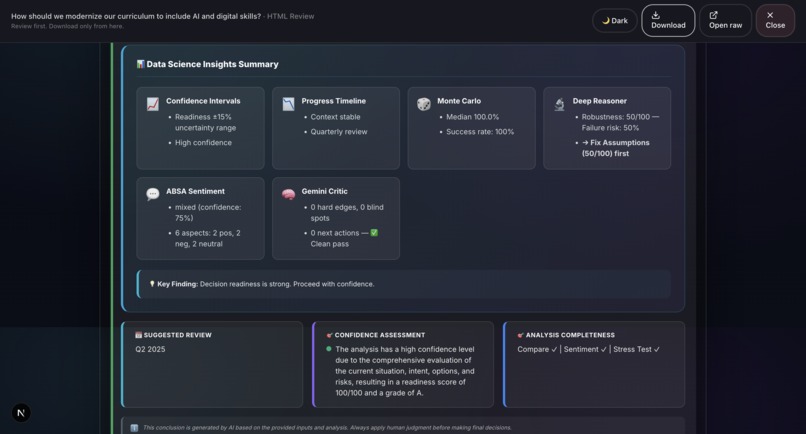
Sample output: Grounds Report (HTML)32
-
Sample output: Grounds Report (HTML)33
-
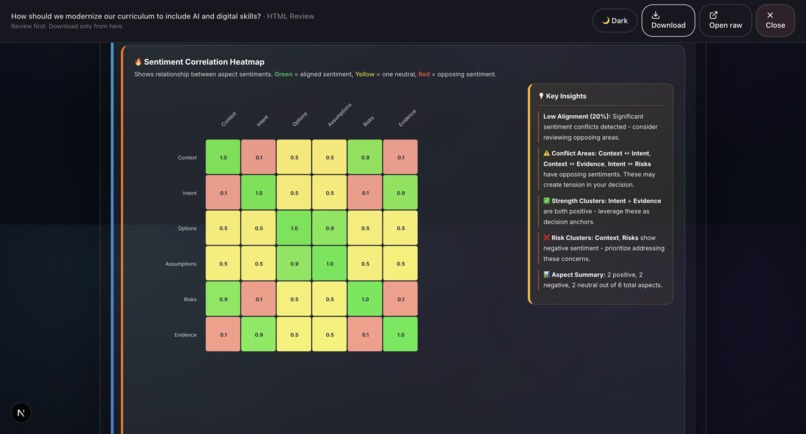
Sample output: Grounds Report (HTML)26
-
Sample output: Grounds Report (HTML)27
-
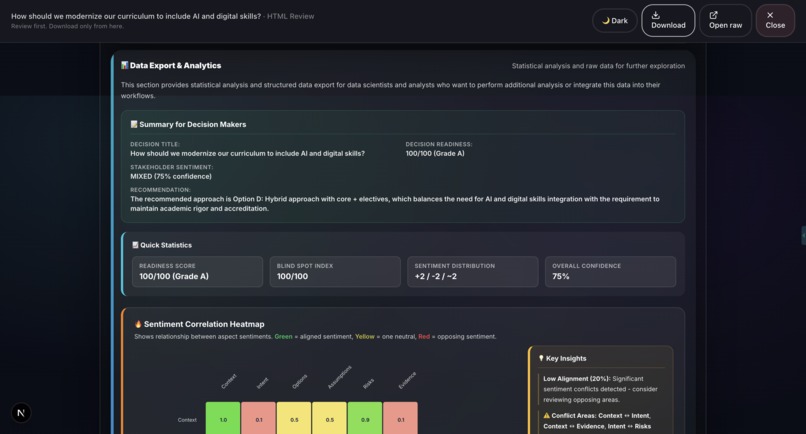
Sample output: Grounds Report (HTML)25


Inspiration
Every day, teams make high-stakes decisions using gut instinct, scattered notes, and no audit trail. Strategy often fails not because execution is weak, but because bias goes unchecked, the problem is framed poorly, and debate stays unstructured. Meetings turn into opinion contests. Evidence gets buried in chat threads. Assumptions stay implicit instead of written down. When outcomes disappoint, nobody can reconstruct what was known, what was assumed, and why the decision felt right at the time.
Grounds fixes this by turning decision-making into a repeatable, decision-grade workflow with structured debate, bias checks, and an auditable decision log. It is a decision intelligence workspace powered by Google Gemini 3, built to support human judgment, not replace it. Instead of producing a single one-shot answer, Grounds helps you compare options, surface blind spots, stress-test assumptions, and generate outputs you can defend, share, and revisit.
"A mirror, not a verdict."
What it does
Grounds is a decision intelligence platform that transforms unstructured decision inputs into professional, exportable reports backed by Gemini 3.
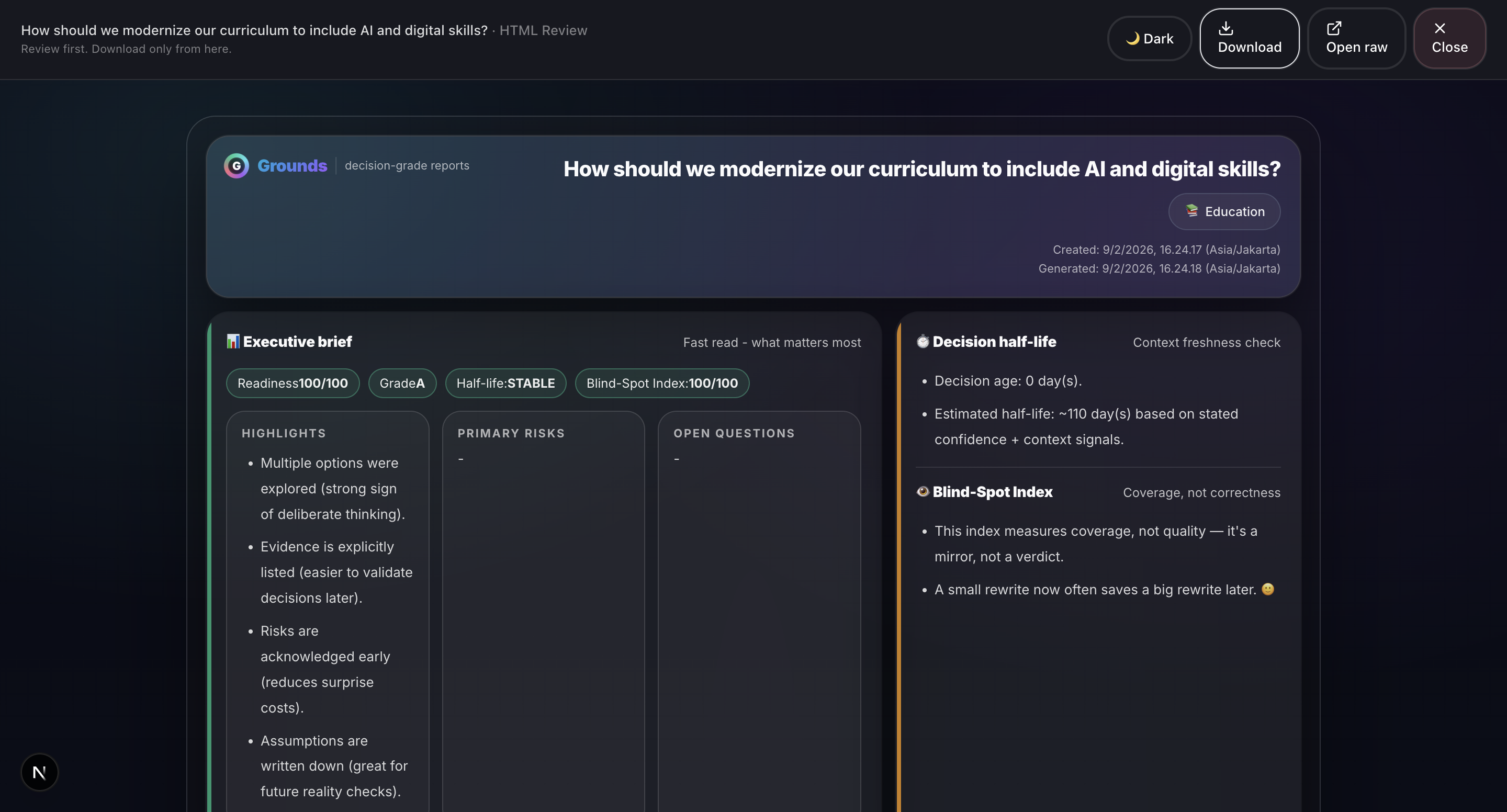
Core Workflow (8 Steps)
- Theme Selection: 11 domain-specific templates (Technology, Healthcare, Finance, Legal, etc.) with pre-built case studies and recommendations.
- Input Collection: Structured fields for Context, Intent, Options, Assumptions, Risks, Evidence, Outcome, and Confidence level. Supports voice input and document scanning via Groq Vision.
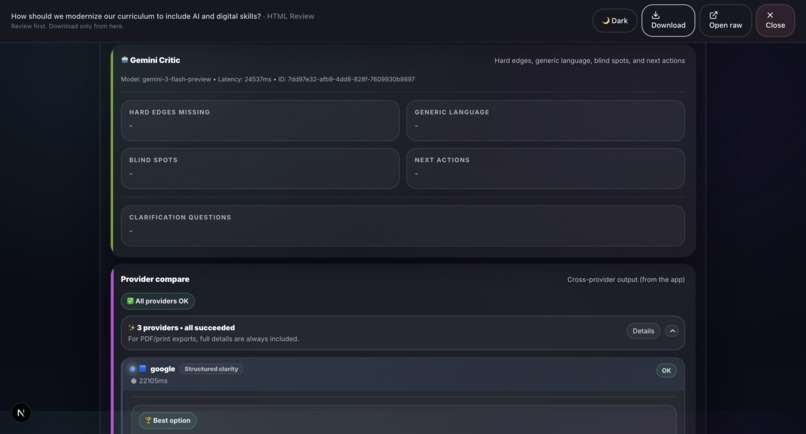
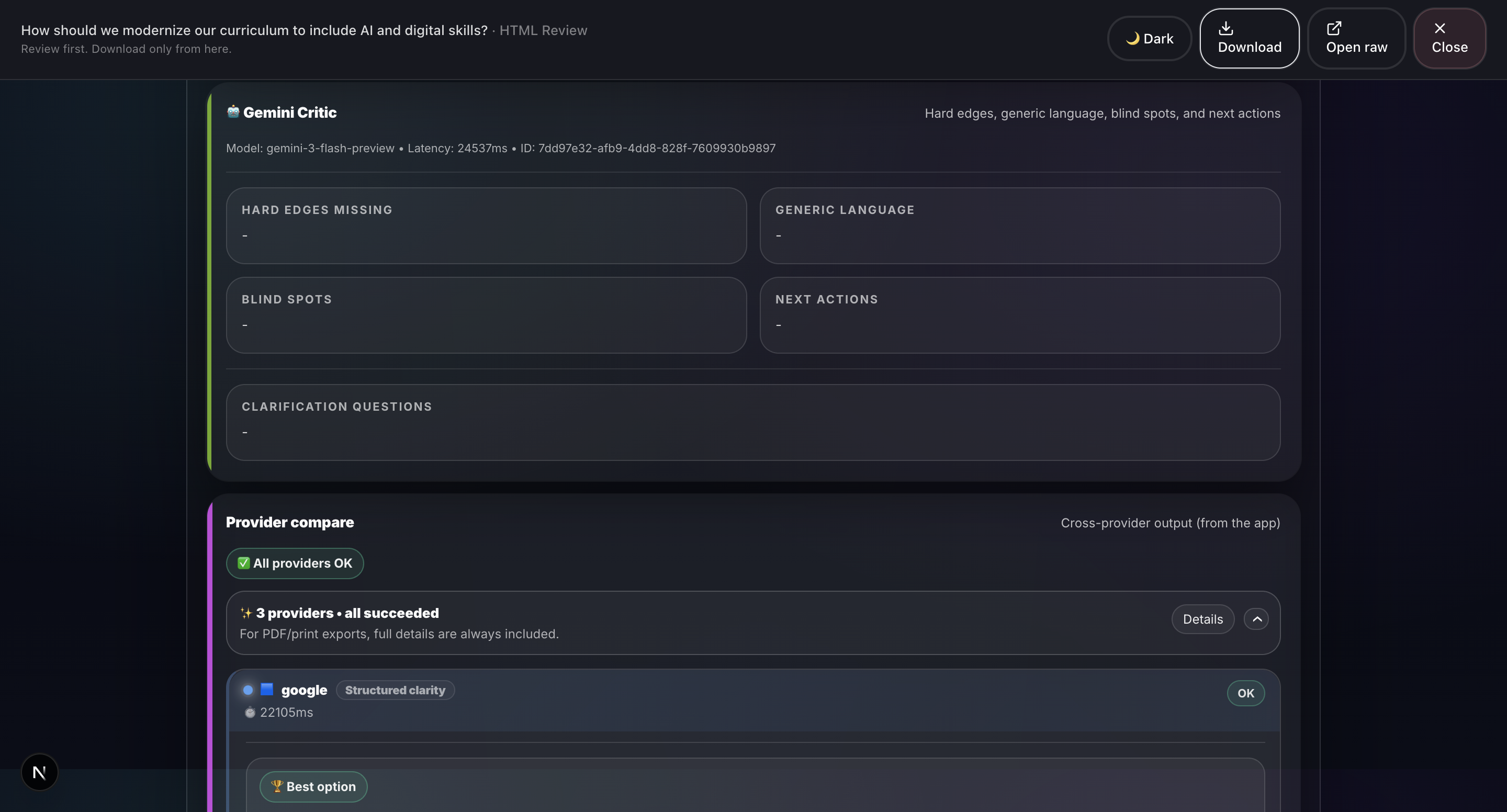
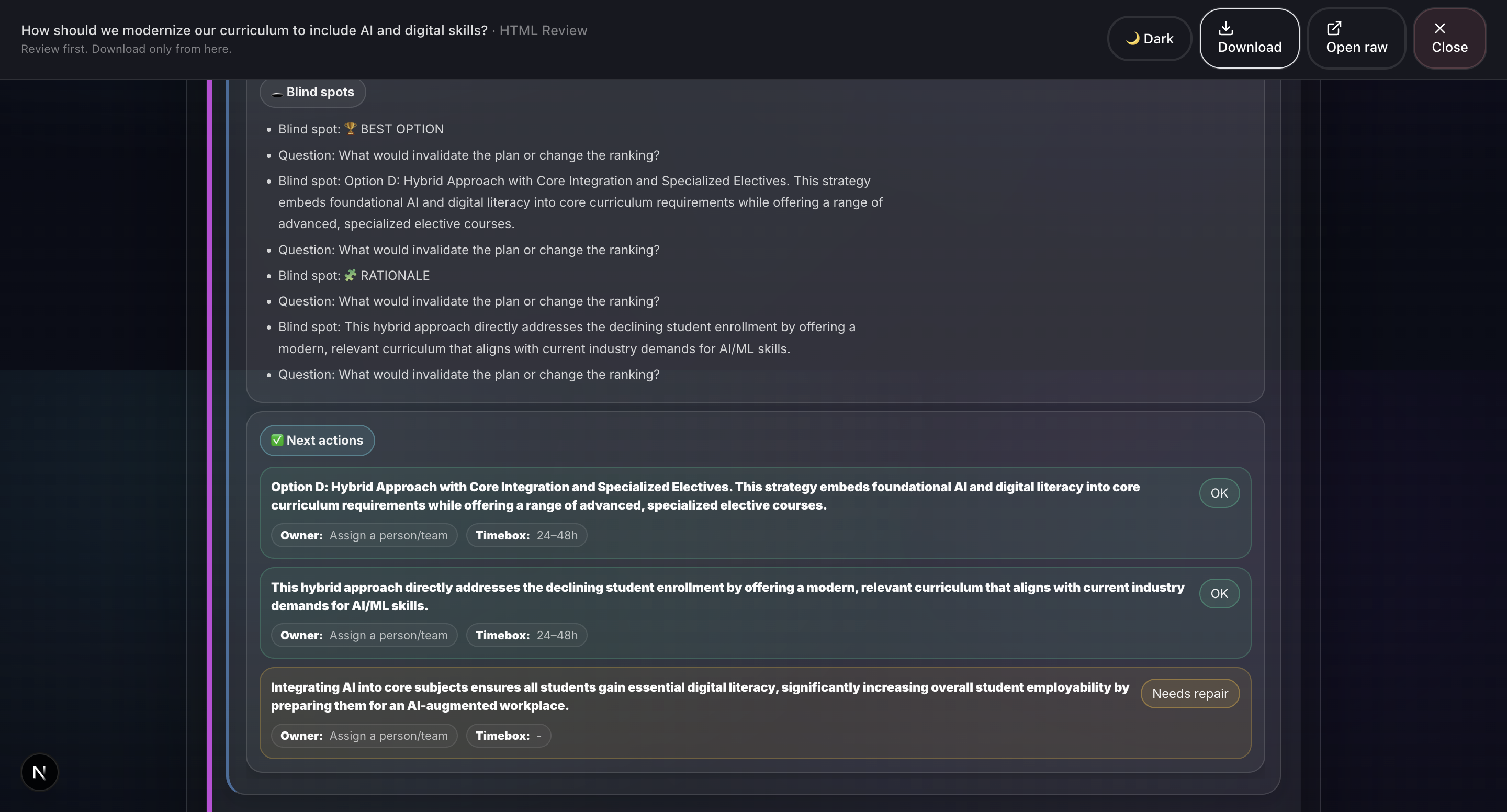
- Gemini Critic: Gemini 3 performs structured critique identifying Hard Edges Missing, Generic Language, Blind Spots, and Next Actions.
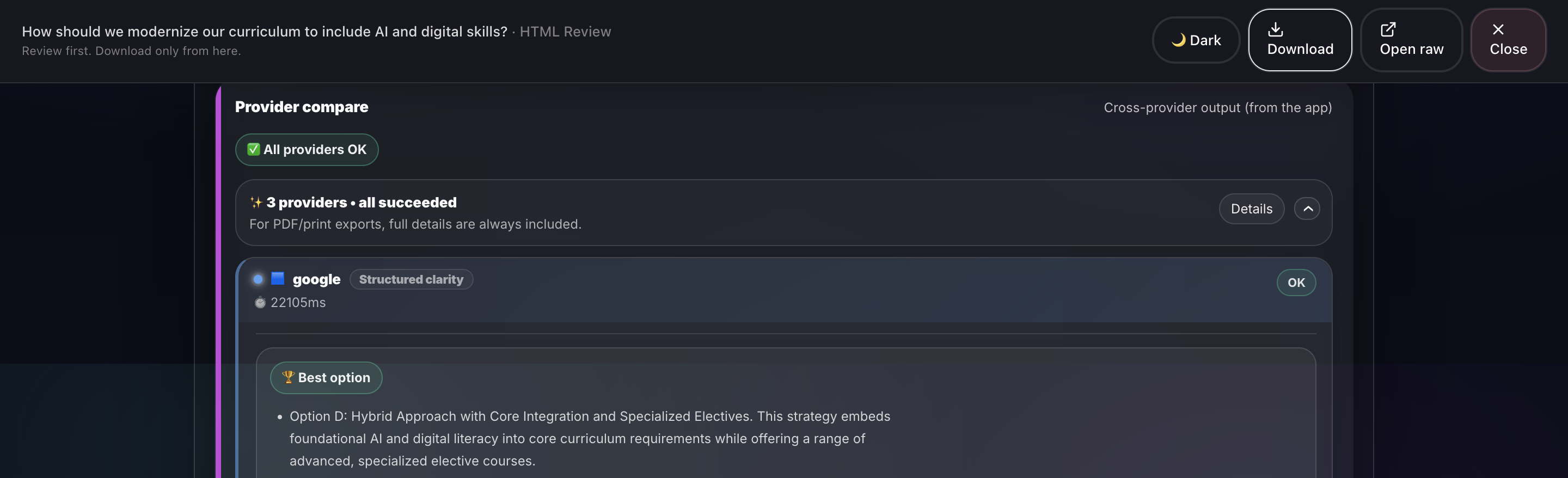
- Provider Compare: Multi-AI validation across Google Gemini, Groq, OpenRouter, and OpenAI with latency benchmarking and winner selection.
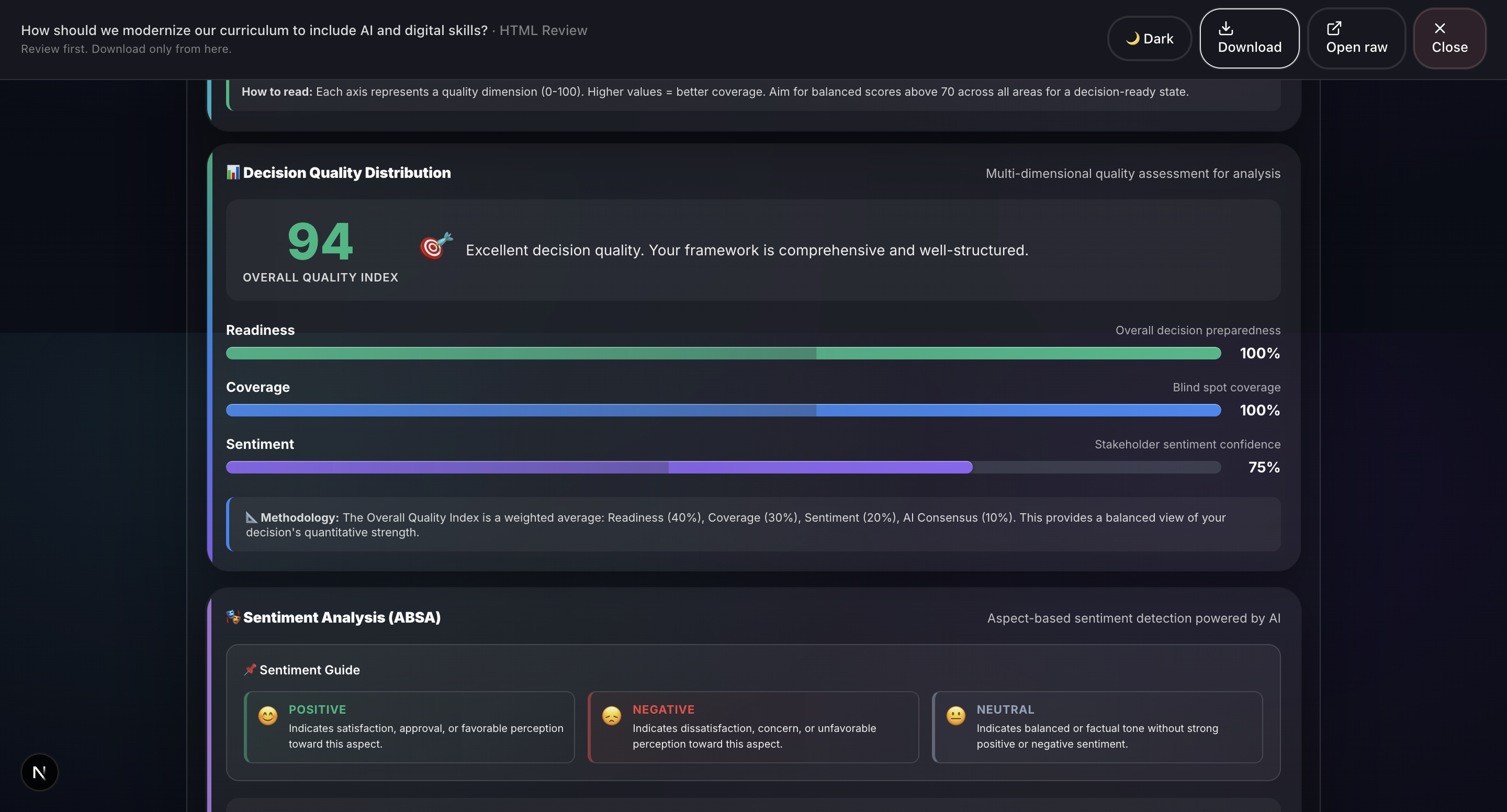
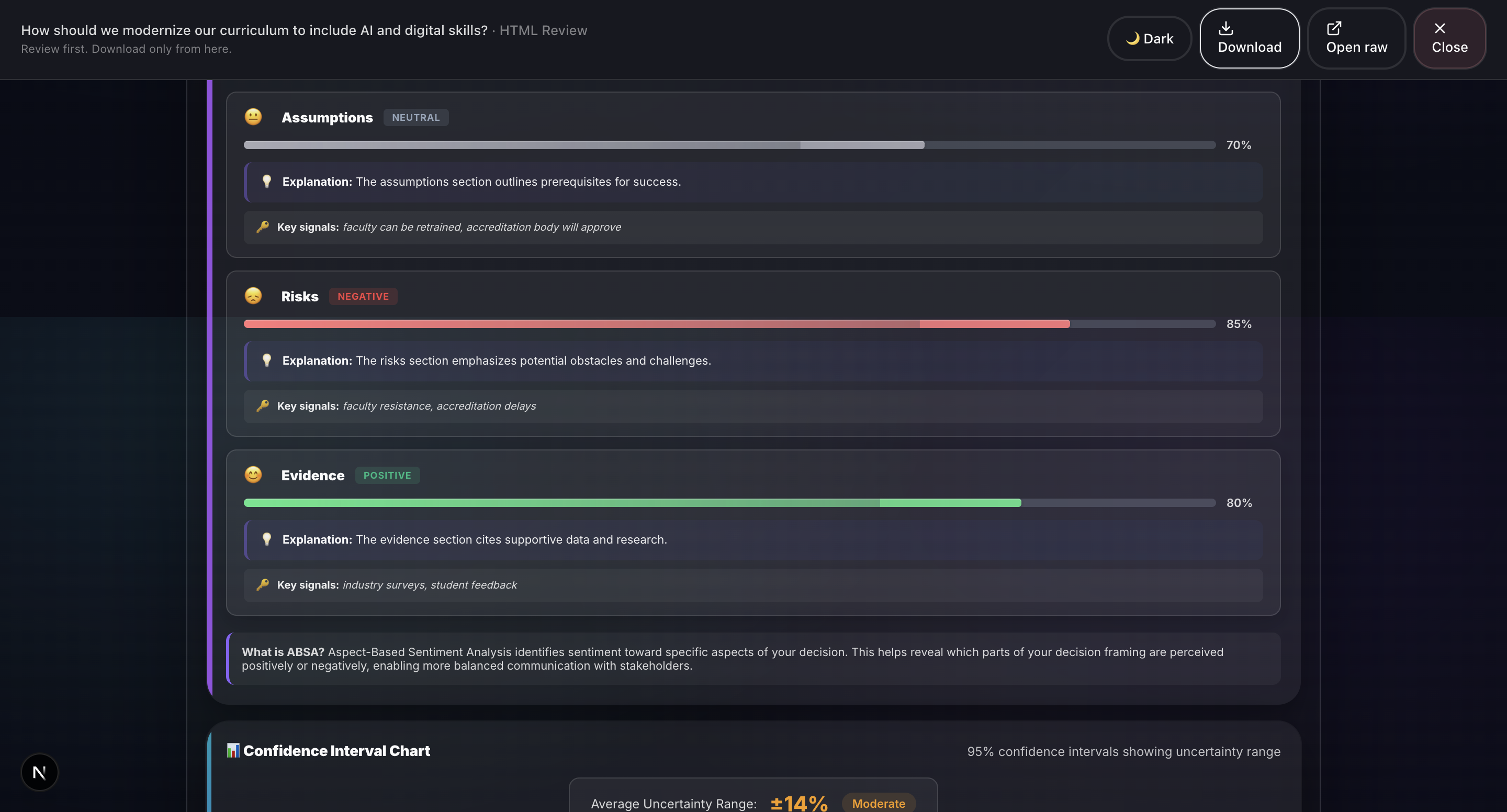
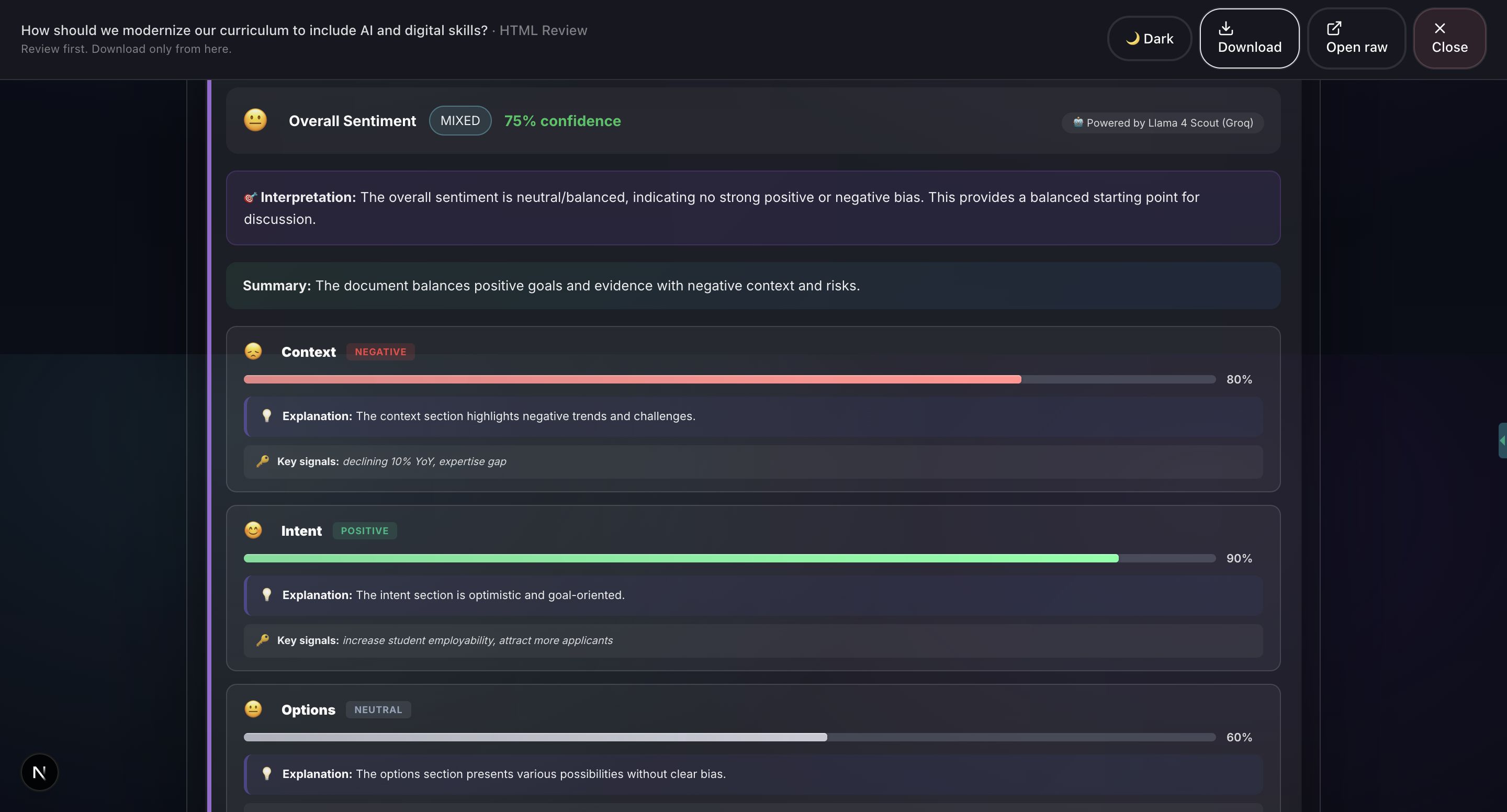
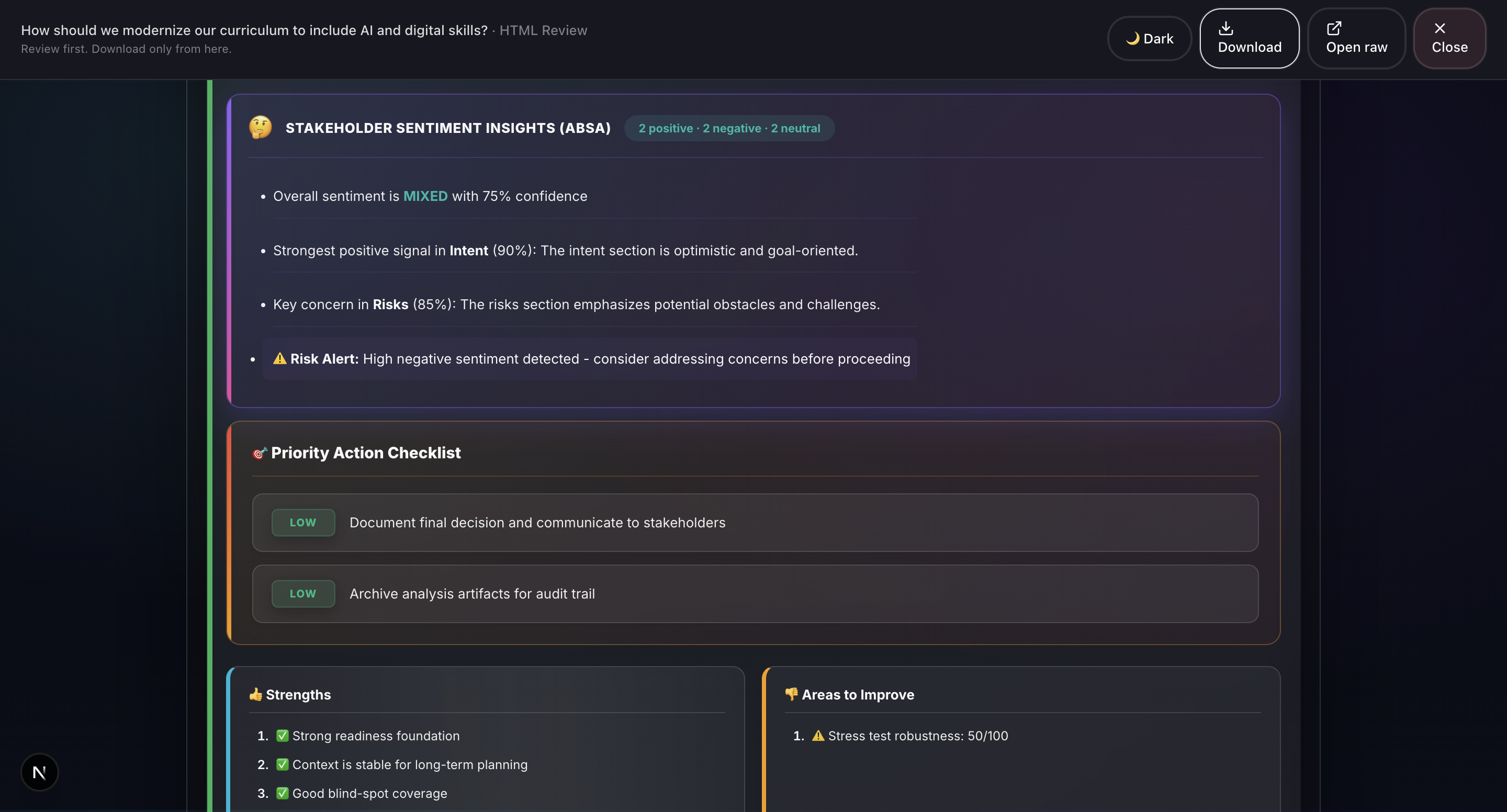
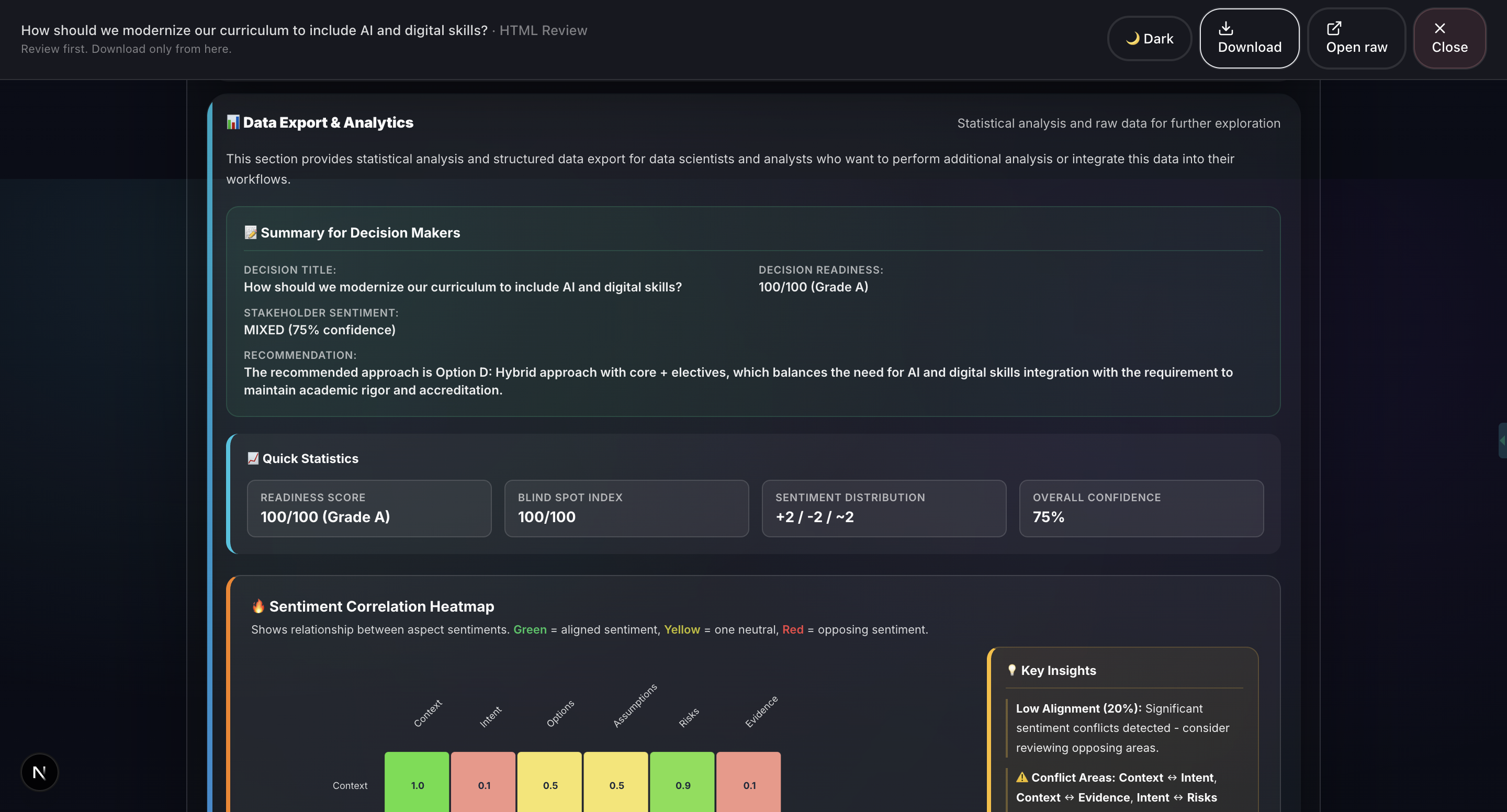
- Sentiment Analysis (ABSA): Aspect-Based Sentiment Analysis evaluates emotional tone across different decision dimensions.
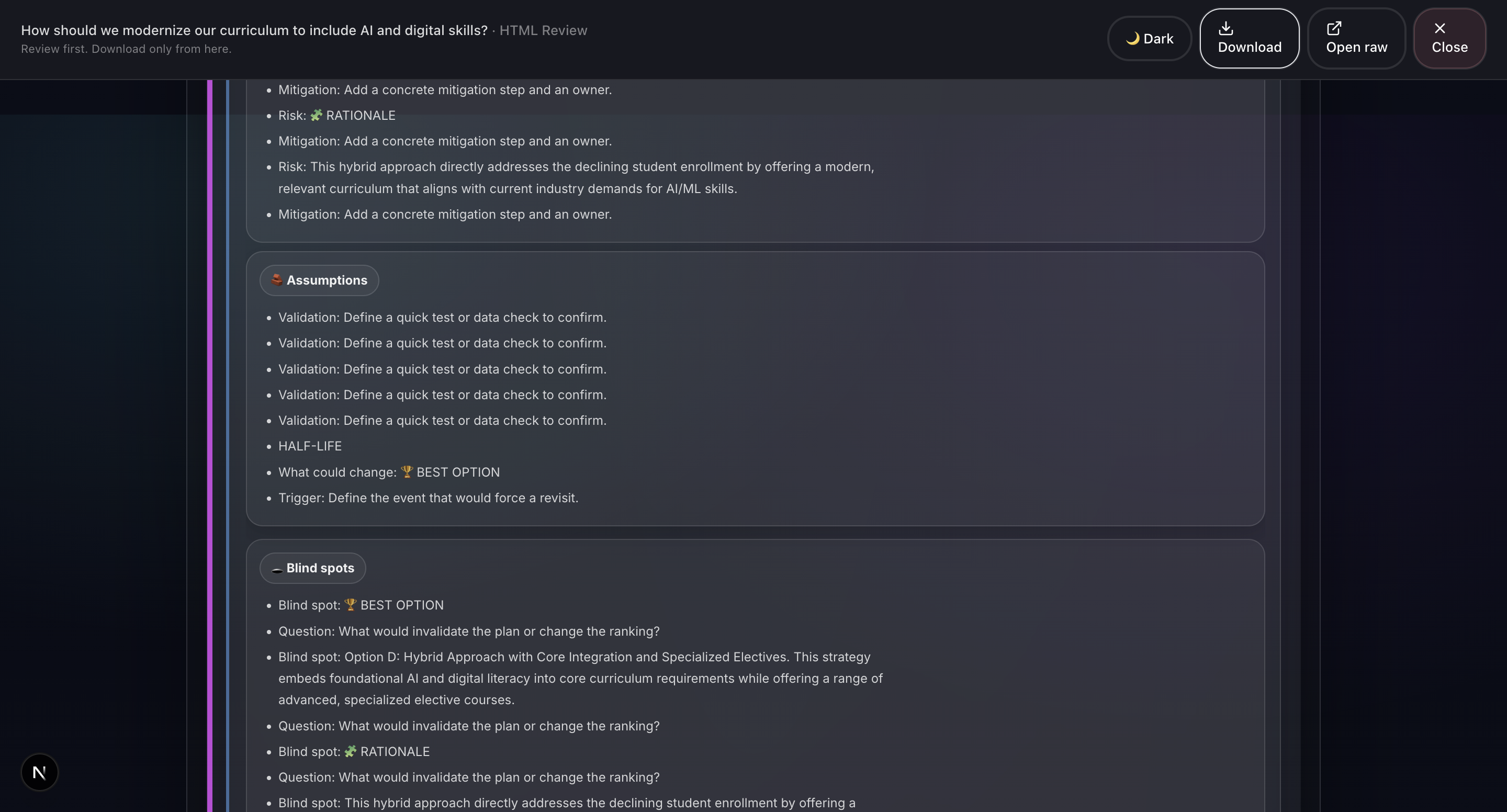
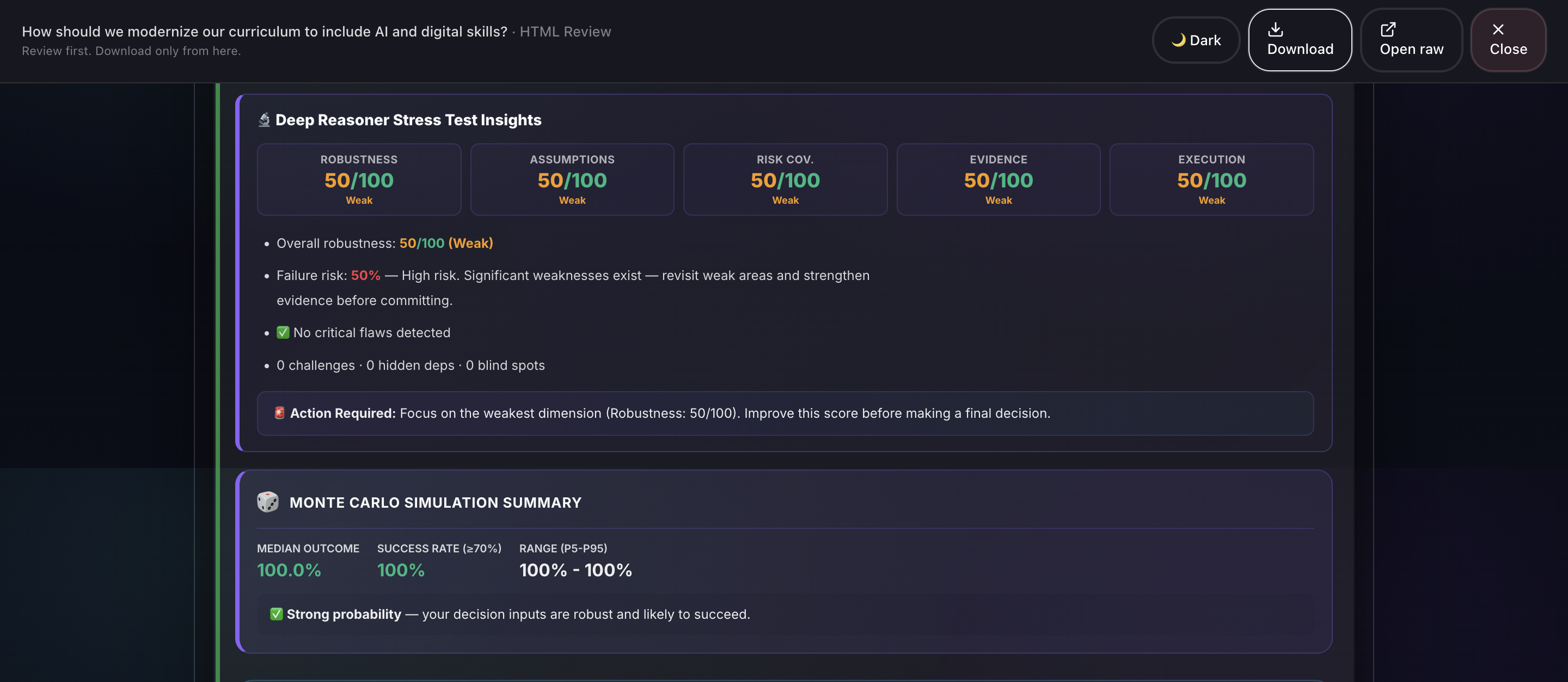
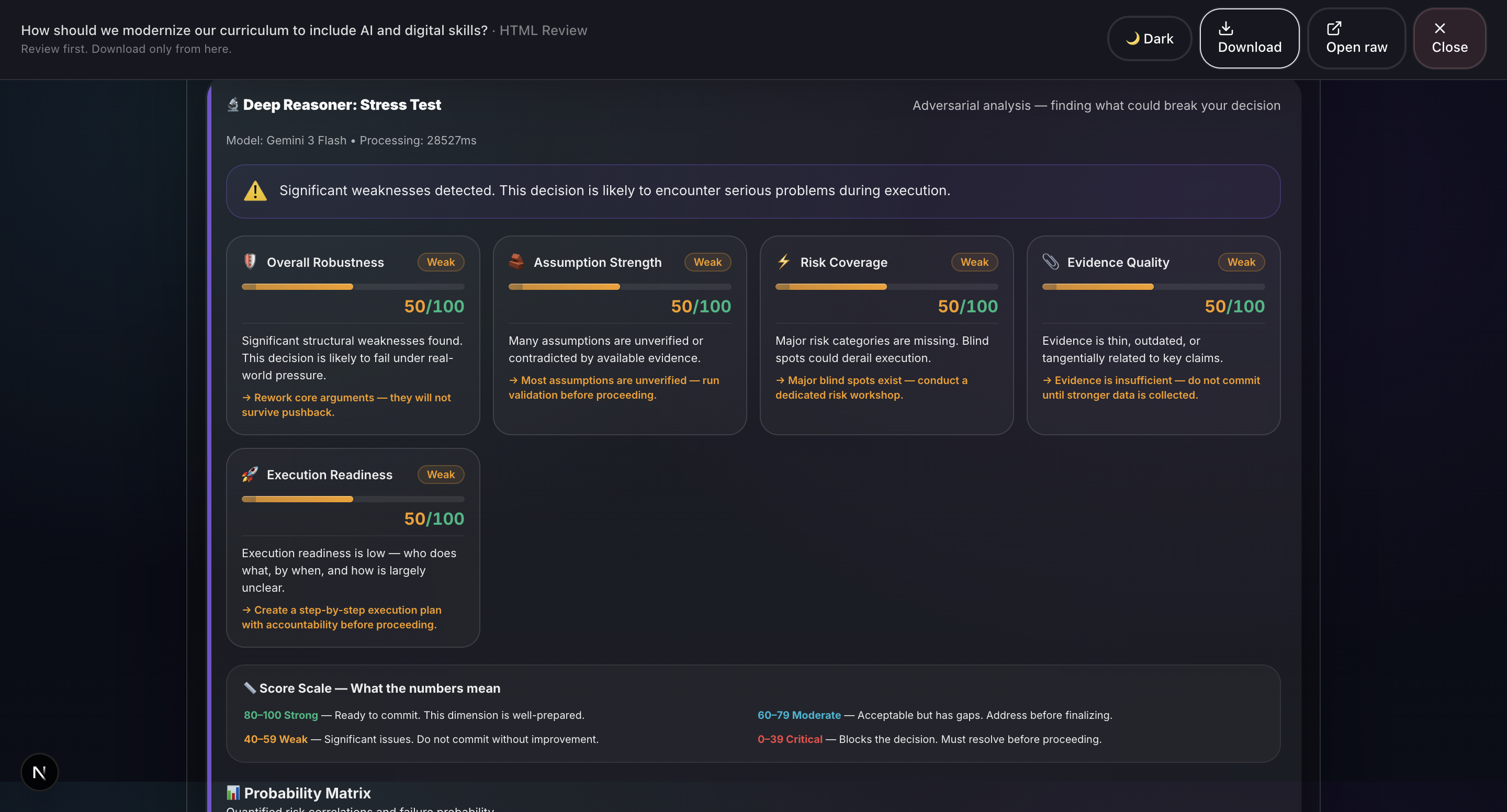
- Deep Reasoner Stress Test: Adversarial AI powered by Gemini 3 that attacks every assumption, finds hidden dependencies, generates Devil's Advocate challenges, and produces a 5-dimension robustness score.
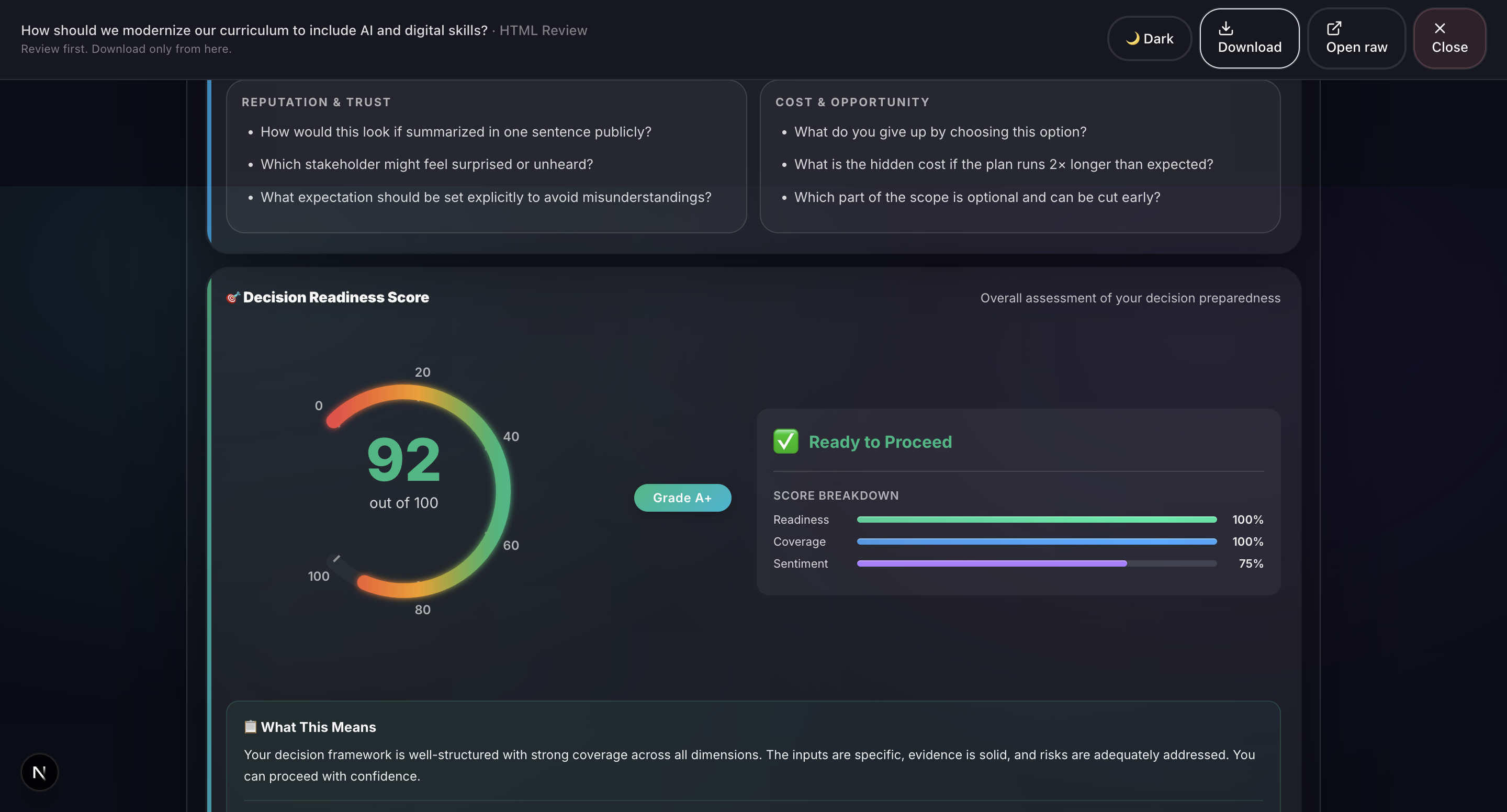
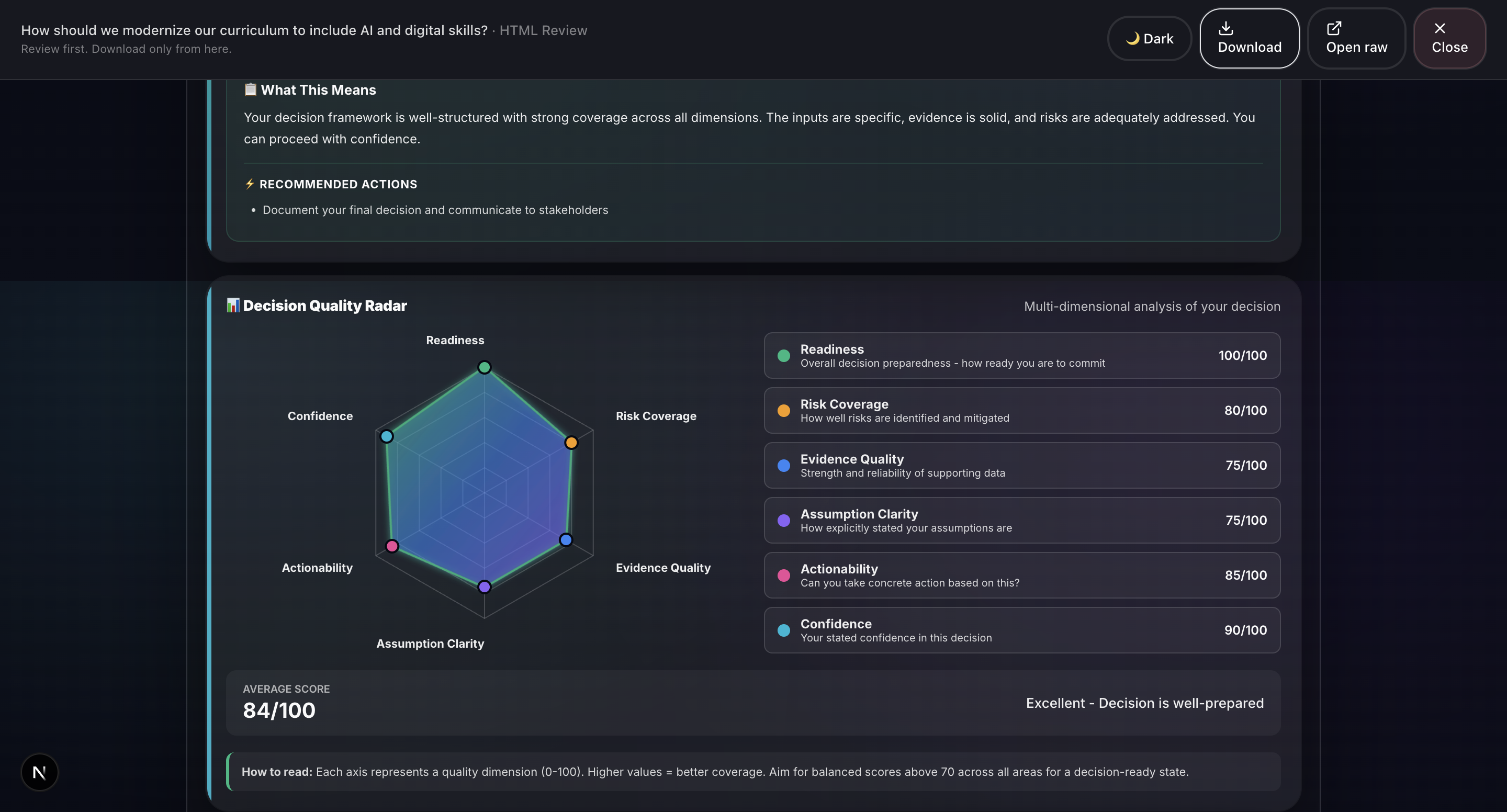
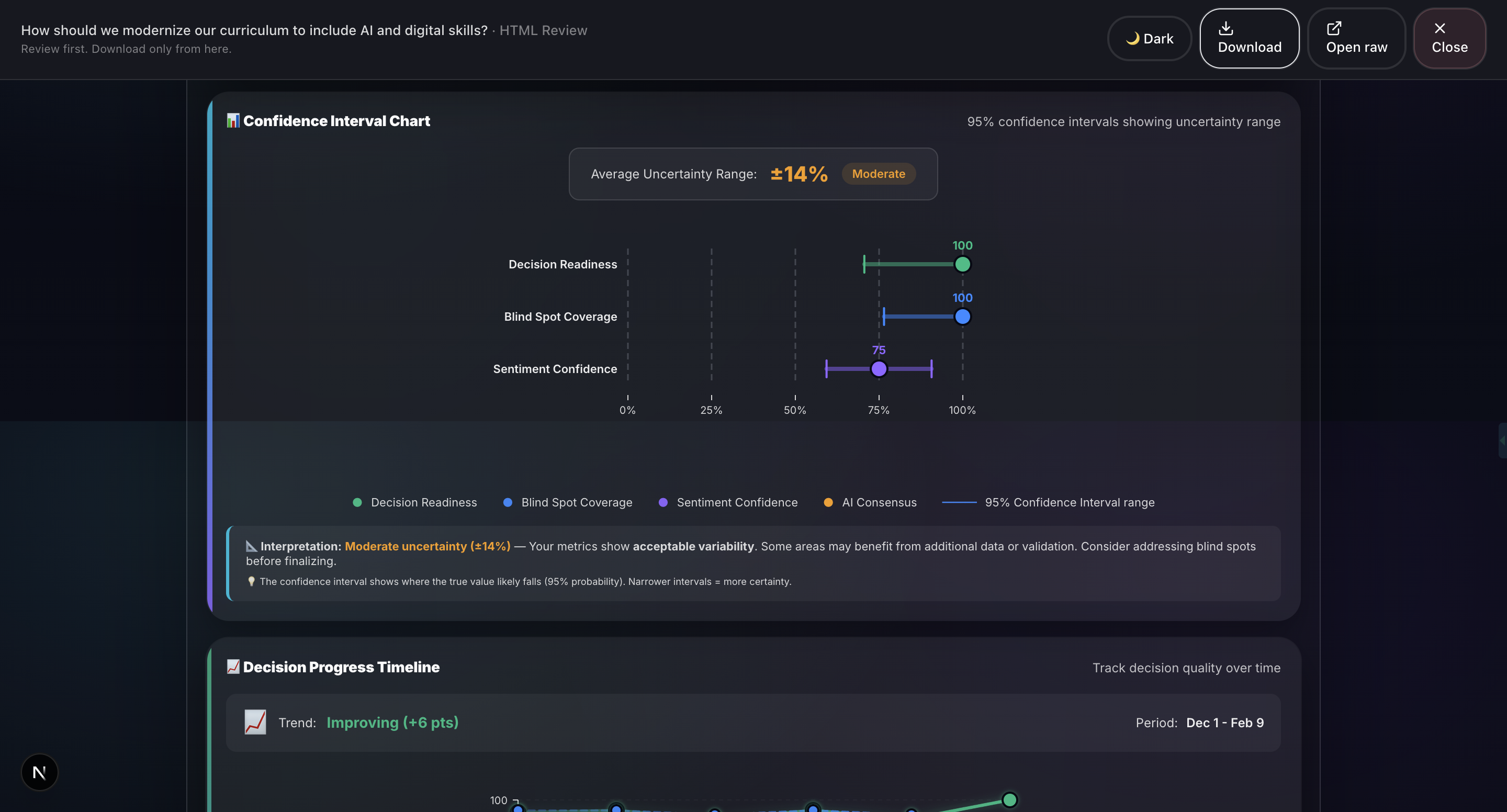
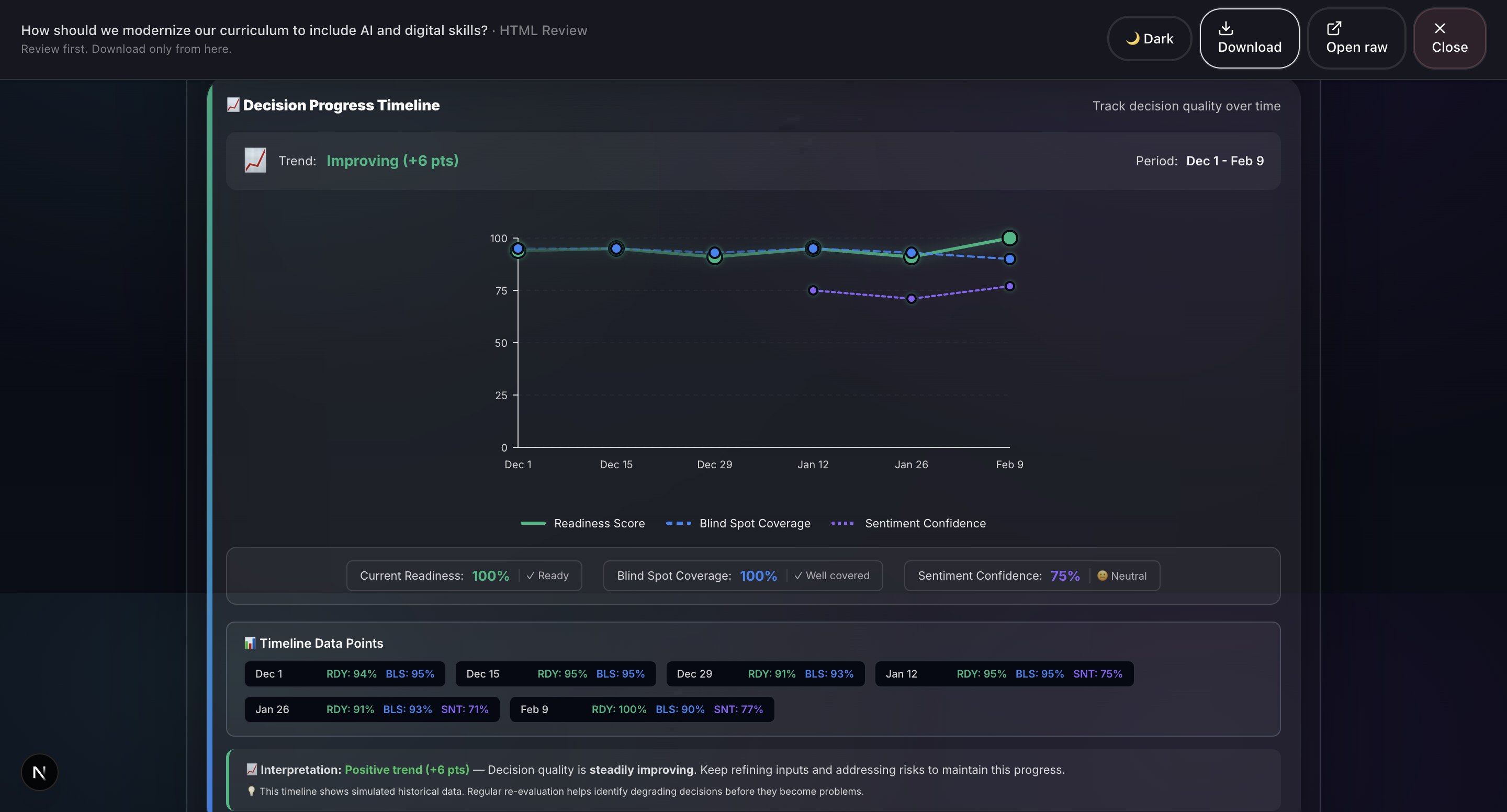
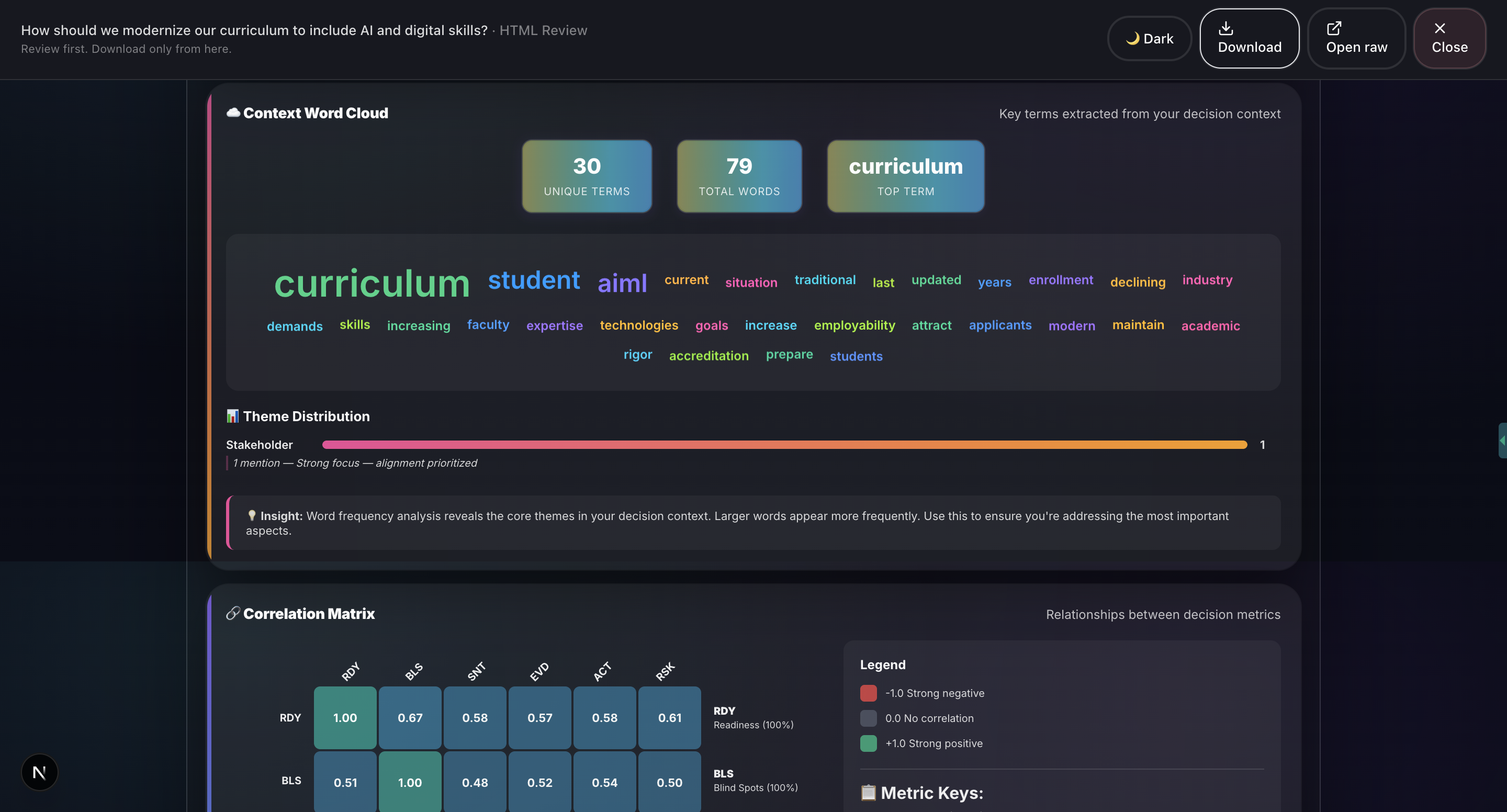
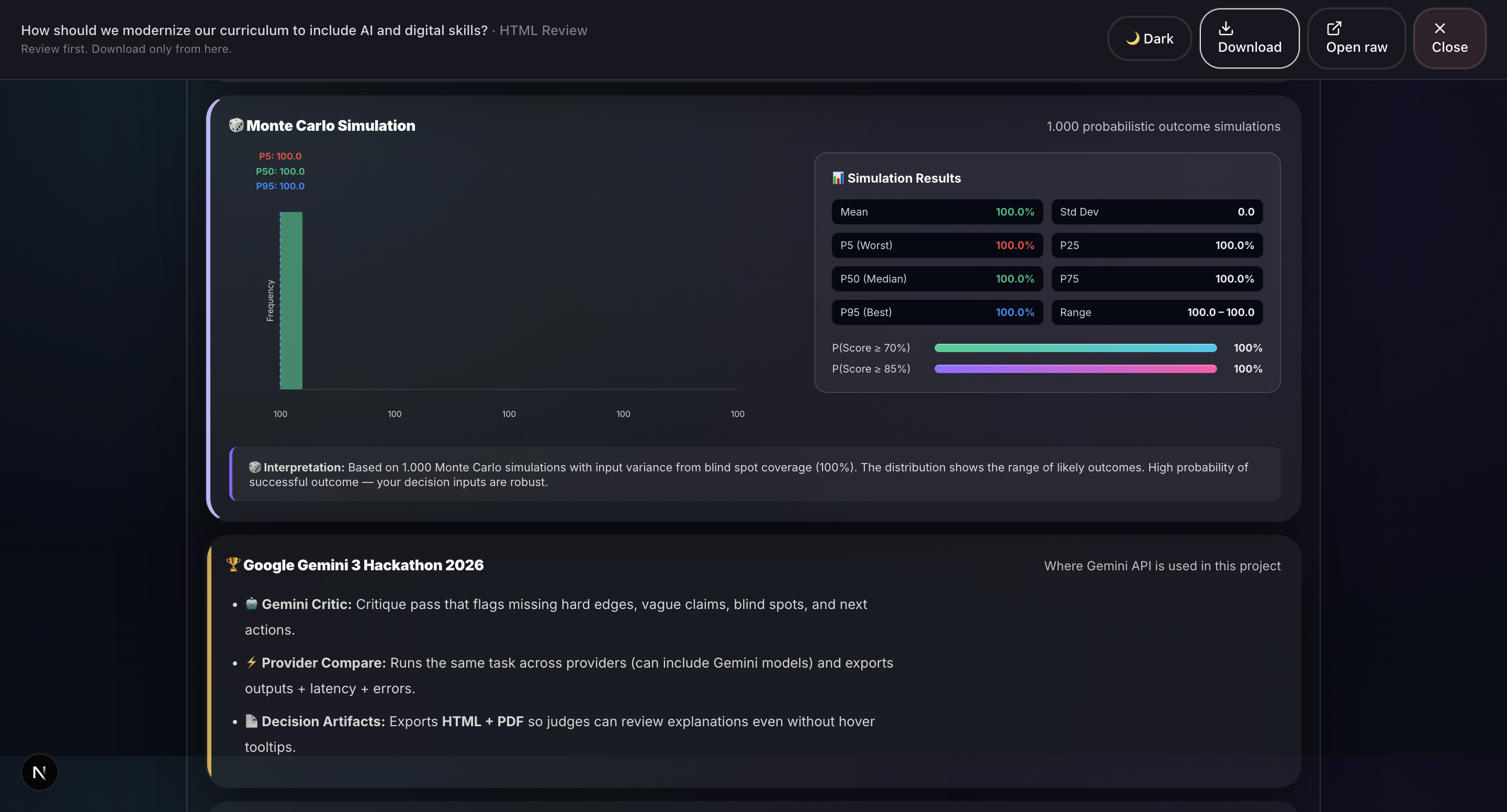
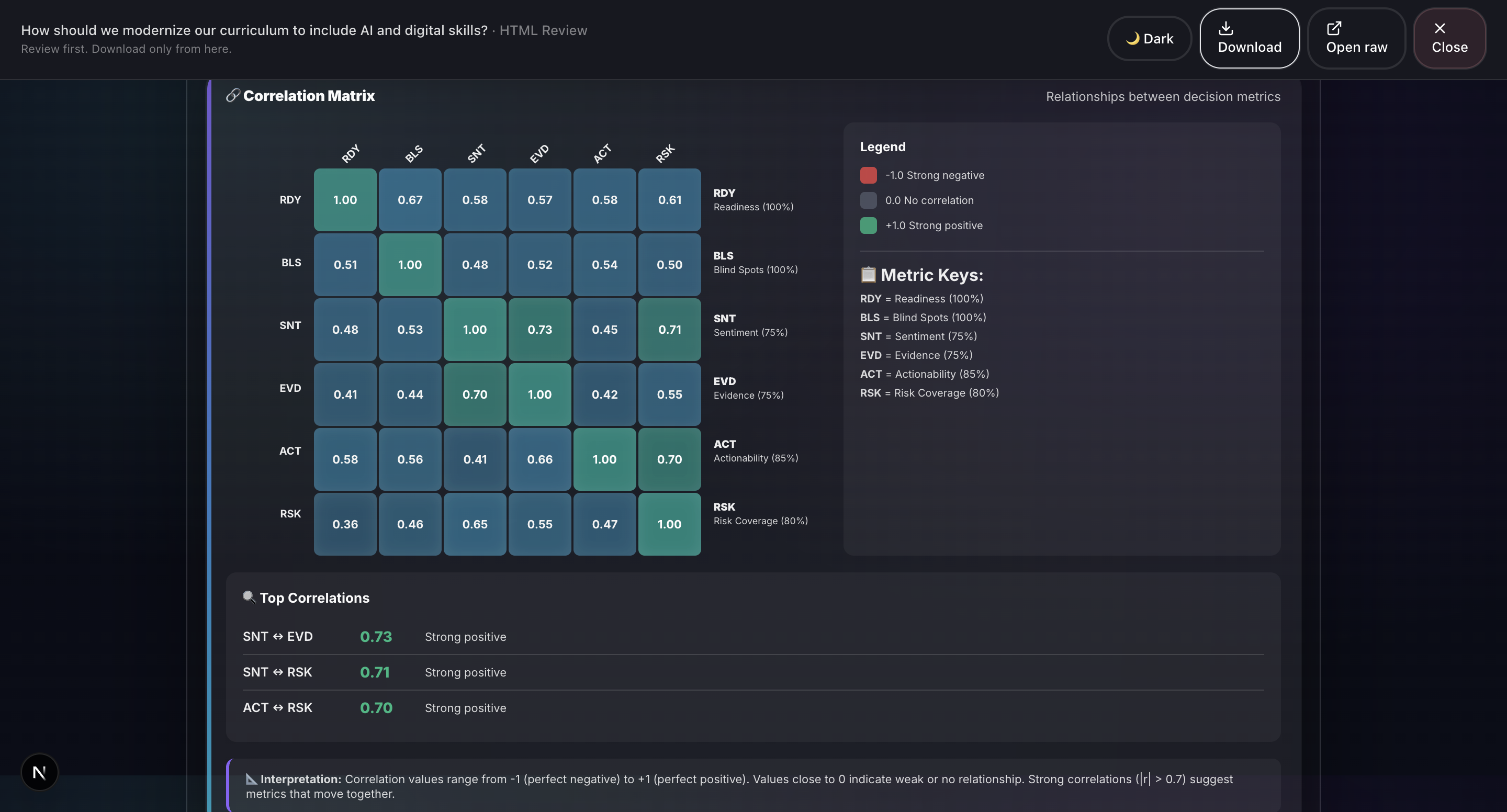
- Report Generation: Professional HTML and PDF reports with 20+ visualizations including Monte Carlo simulation, confidence intervals, correlation matrices, word clouds, and radar charts.
- Export and Share: Download, share via WhatsApp/Telegram, export to Google Docs/Sheets, and local gallery storage.
Key Differentiators
- Decision-grade output: Not a chatbot response, but an auditable PDF/HTML artifact with explainable scoring.
- Adversarial validation: Deep Reasoner does not encourage your decision. It actively tries to break it.
- Multi-provider consensus: Compare Gemini vs Groq vs OpenRouter to find agreement and disagreement.
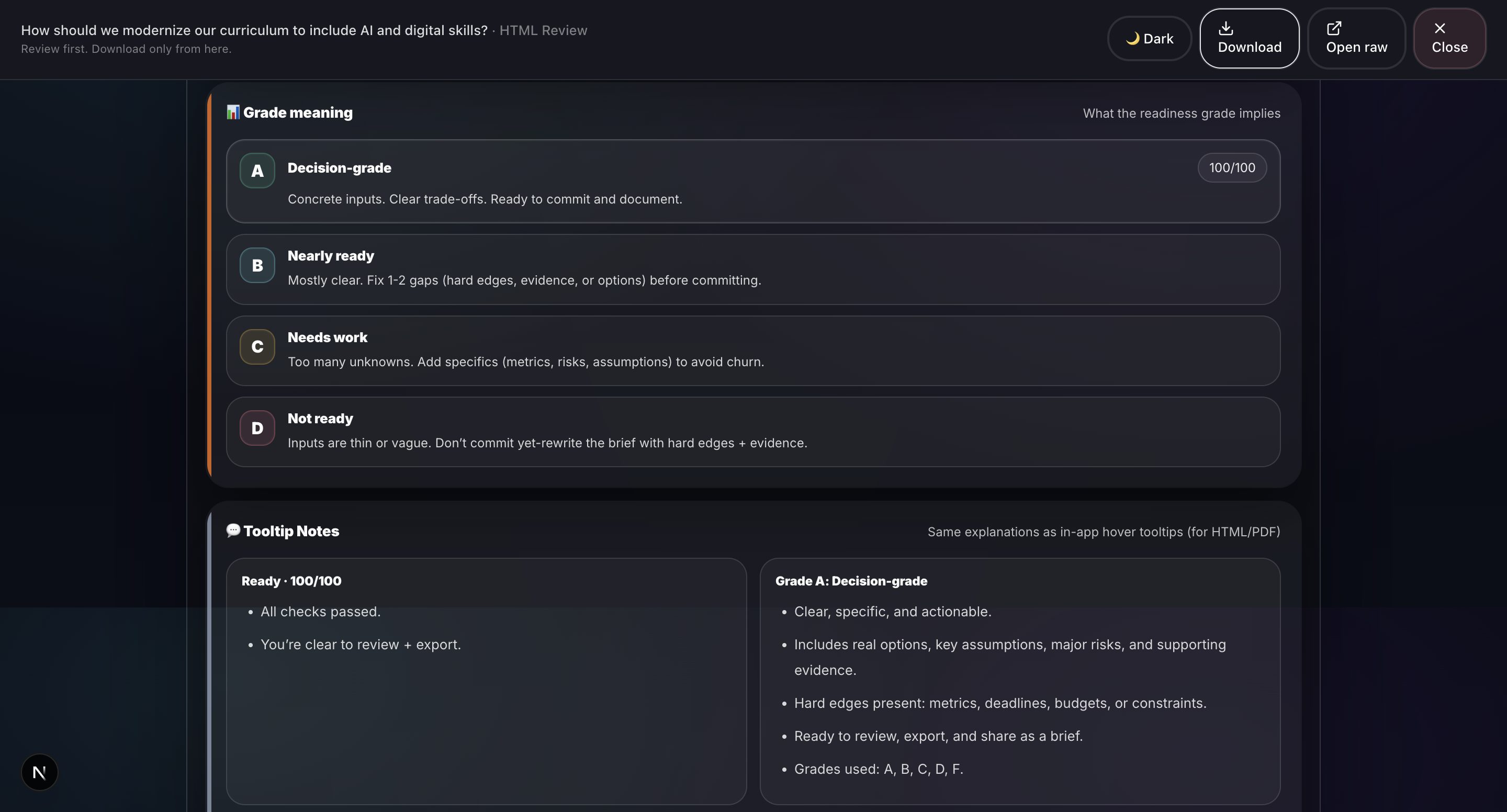
- Deterministic scoring: Readiness, Half-Life, and Blind-Spot Index are computed locally, not hallucinated.
- Local-first architecture: Evidence ledger stored in browser. No cloud dependency for core analysis.
How we built it
Architecture:
- Frontend: Next.js 14 (App Router) + React 18 + TypeScript + Tailwind CSS + Framer Motion
- AI Layer: Gemini 3 (Flash + Pro) for Critic, Stress Test, Sentiment, Conclusion, and Research. Groq (Llama 4 Scout) for fallback. OpenRouter for multi-model comparison.
- Scoring Engine: Rust compiled to WebAssembly for deterministic, client-side readiness scoring.
- Report Engine: Custom HTML renderer (13,000+ lines) with dark/light mode, CSS animations, and Python-based PDF generation using Jinja2 + WeasyPrint.
- Visualization: 20+ chart types built with pure HTML/CSS/SVG (no D3 dependency in reports).
- Storage: Local-first with browser localStorage for ledger, gallery, and preferences.
Gemini 3 Integration Points
- Gemini Critic: Gemini 3 (Flash + Pro). Structured critique: Identifies hard edges, generic language, blind spots, and next actions, powered by Gemini 3.
- Deep Reasoner: Gemini 3 (Flash + Pro). Adversarial stress test: Runs a structured stress test using Chain of Thought reasoning and 5-dimensional scoring, powered by Gemini 3.
- Sentiment Analysis (ABSA): Groq Llama 4 Scout. Aspect-based sentiment analysis across different decision dimensions, powered by Groq.
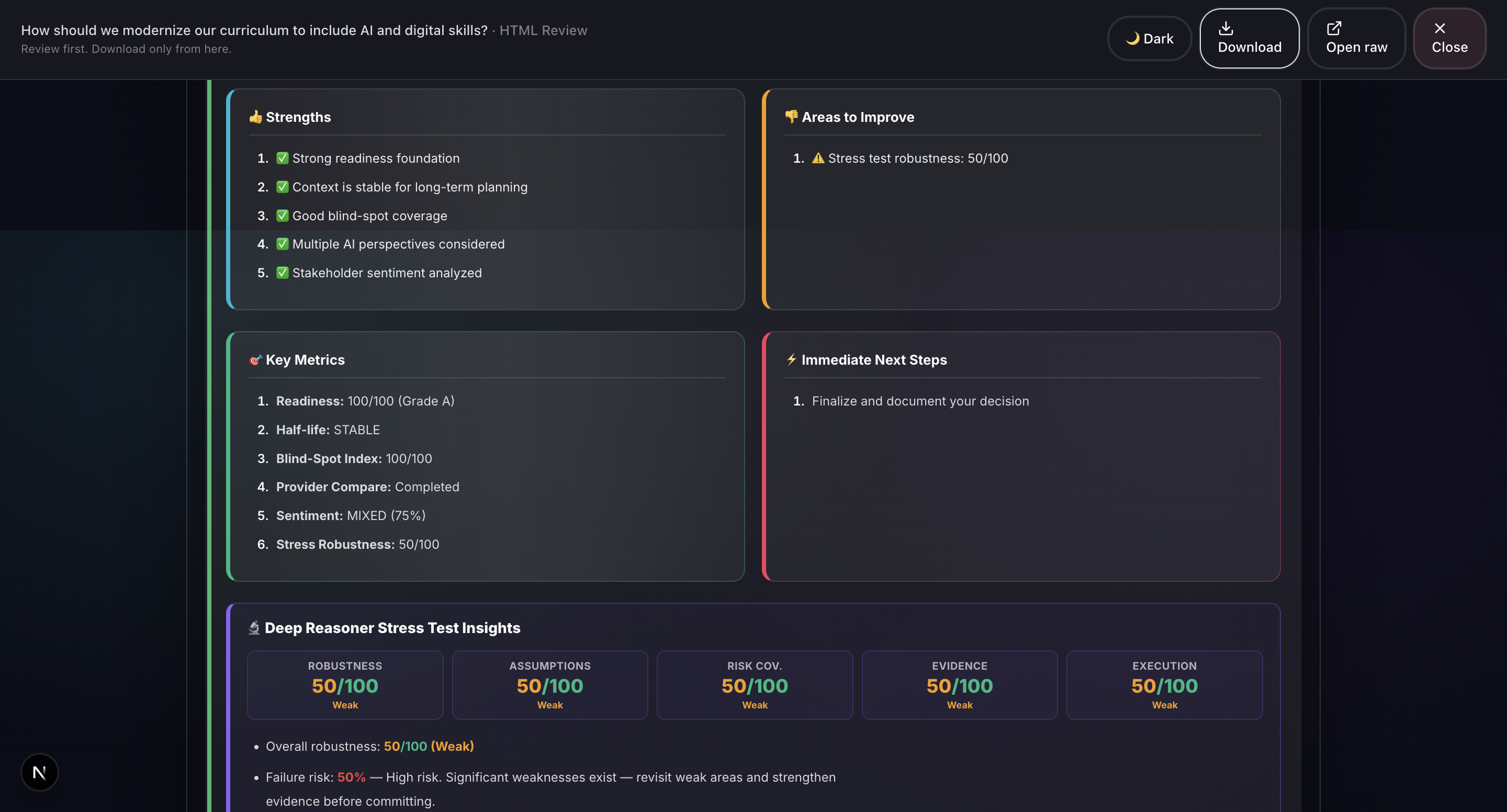
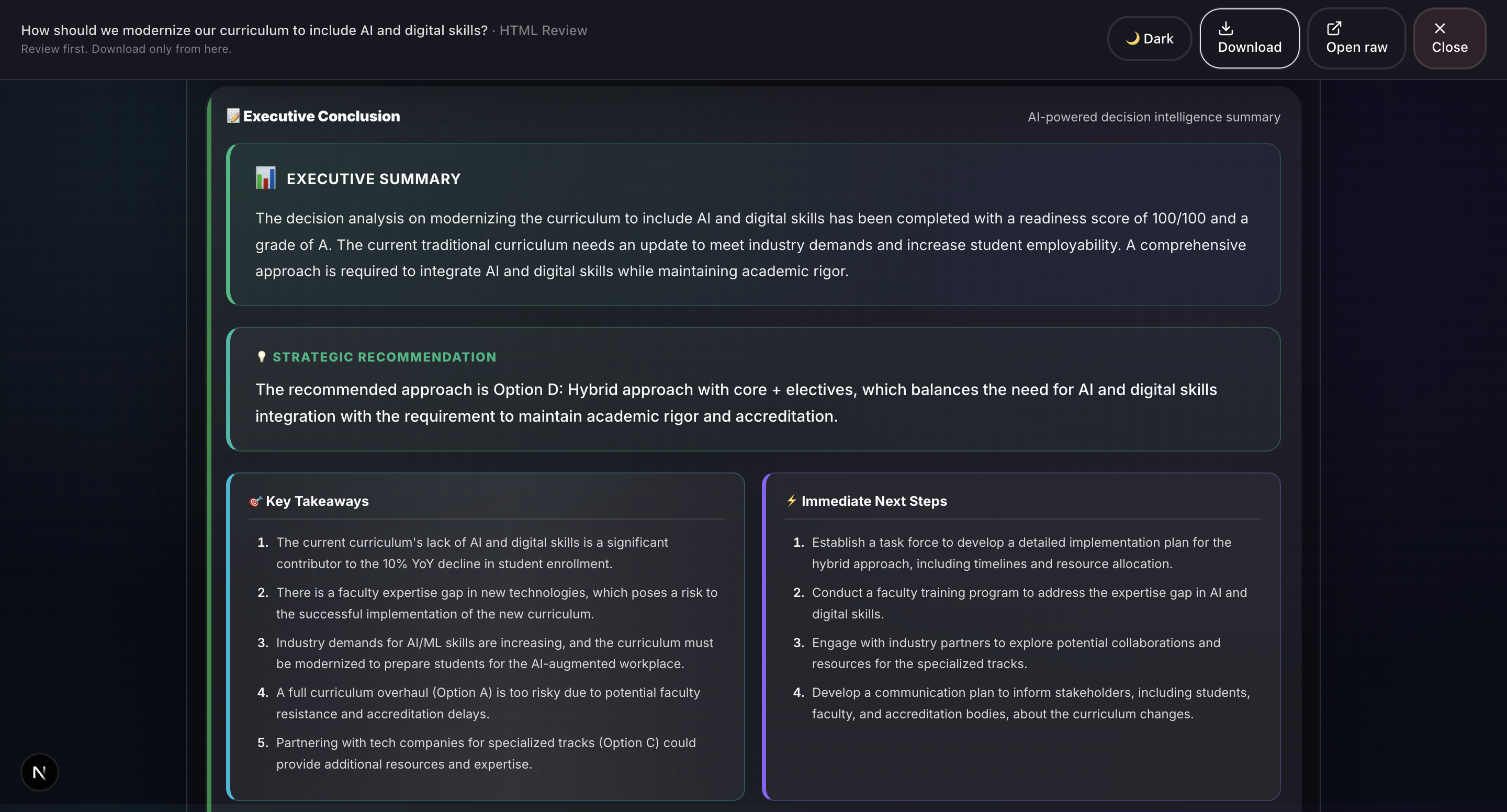
- Conclusion: OpenAI GPT-4: AI-generated executive summary with a priority action checklist, powered by OpenAI.
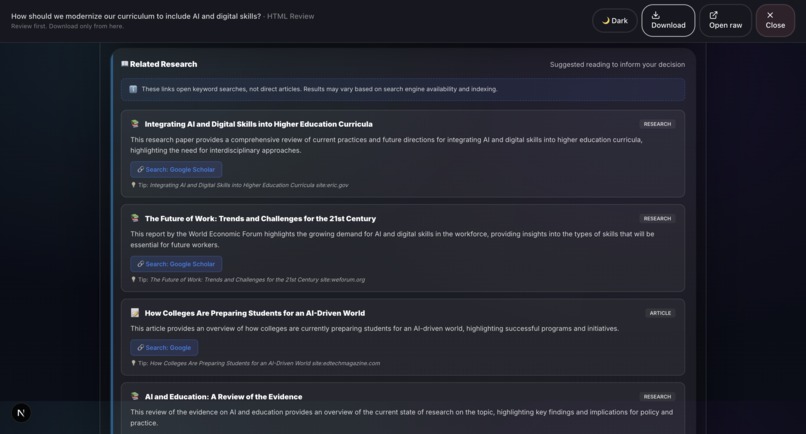
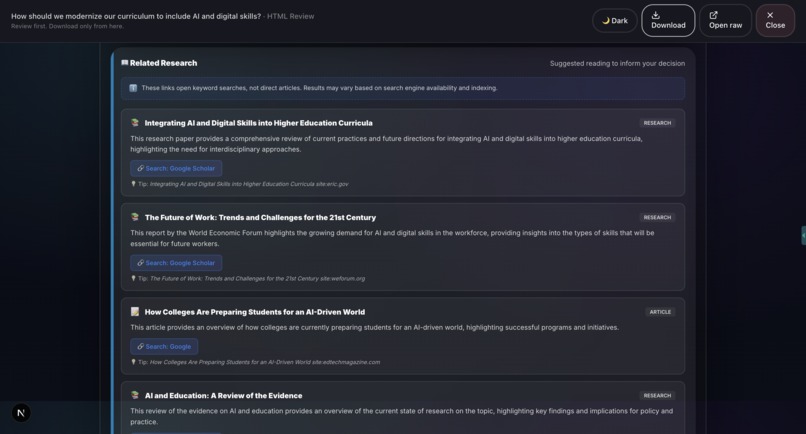
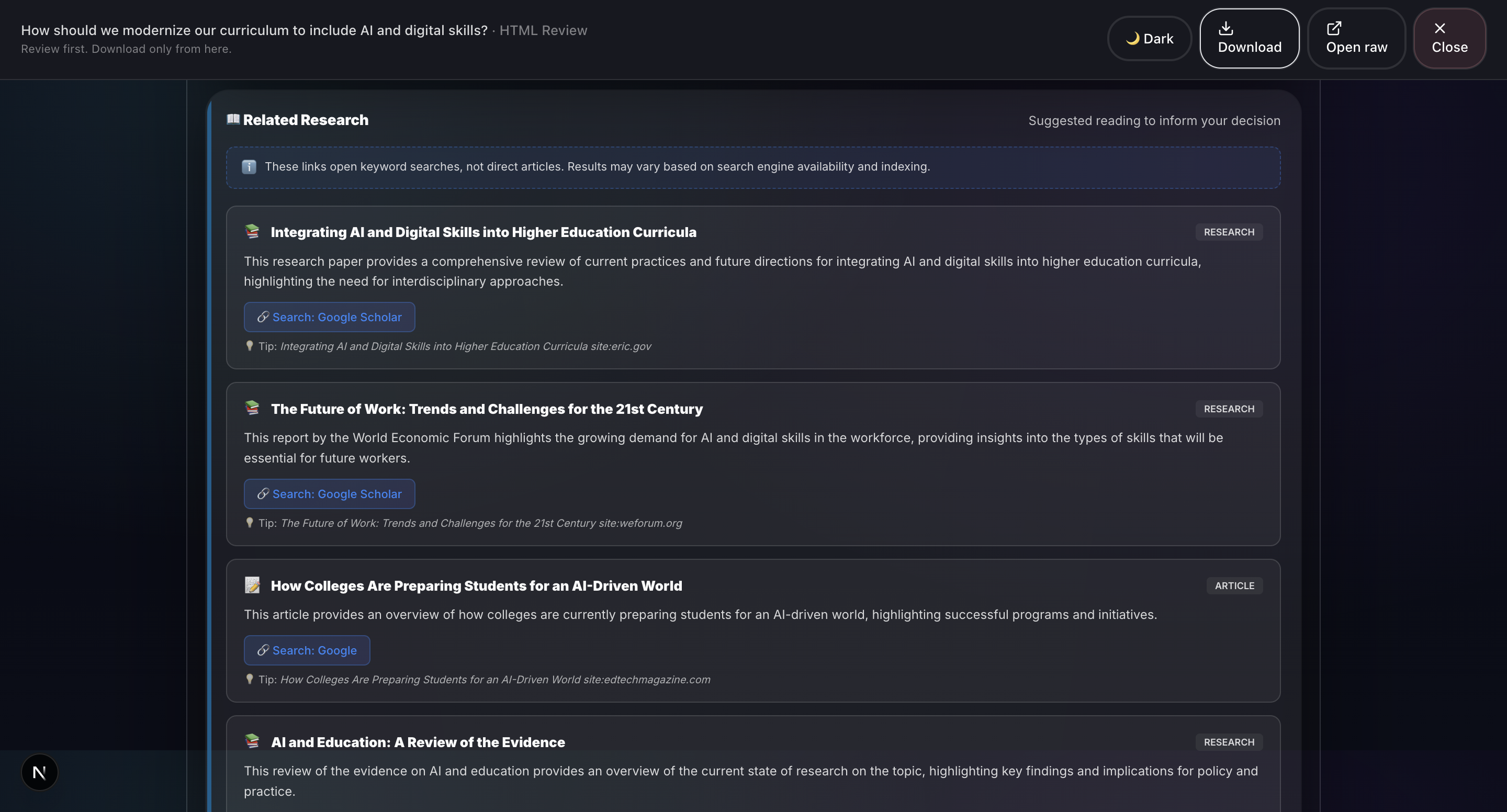
- Research: Gemini 3 (Flash + Pro): Related research suggestions and educational context, powered by Gemini 3.
- Provider Compare: Gemini 3 (Flash + Pro): Multi-provider validation and best-option recommendation, using Gemini 3 for decision comparison.
Challenges we ran into
- Prompt engineering for structured JSON output: Ensuring Gemini consistently returns valid JSON with the exact schema required extensive iteration. To address this, we implemented strict schema definitions in the prompts and a robust safeJsonParse fallback chain to handle potential discrepancies.
- Model fallback reliability: While Gemini 3 is fully accessible and functional, we implemented a multi-model fallback chain for greater reliability and flexibility in case any model fails or provides suboptimal results:
- gemini-3-flash (main model, used for high-quality output)
- gemini-3-pro (fallback for better performance when available)
- gemini-2.5-flash (fallback for stability and broader availability)
- gemini-2.0-flash (final fallback when other models are unavailable) The chain automatically retries the next available model, ensuring smooth operations even if a model is temporarily unavailable.
- Getting the Rust-to-WASM scoring engine to produce deterministic results: Ensuring the Rust-to-WASM scoring engine produces truly deterministic results across different browsers was more challenging than expected. We solved this by conducting extensive testing across browsers and refining the WebAssembly compilation process for consistency.
- Report rendering parity: Achieving consistent rendering of the HTML report across dark/light mode, browser preview, and PDF export was a challenge. This required over 13,000 lines of meticulously crafted CSS, including explicit overrides for light-mode compatibility.
- Gemini 3 prompt architecture: Designing the Gemini 3 prompt architecture so that the Critic pass produces structured, point-by-point feedback (instead of generic summaries) required careful tuning and iteration on the prompt structure.
- Real-time Chain of Thought visualization: Rendering the AI's thinking path as an interactive timeline, while maintaining performance, was a significant challenge. We solved this using Framer Motion with staggered animations, allowing smooth transitions without sacrificing speed.
- Balancing UI complexity: With seven workflow steps, multiple panels, and real-time scoring, maintaining an intuitive interface was difficult. It required several rounds of design iterations to balance complexity with usability.
- TypeScript strict mode with AI responses: AI-generated outputs are often unstructured. Every field required safe parsing, type narrowing, and fallback values to prevent runtime crashes, ensuring the system operated smoothly in TypeScript strict mode.
- Local-first architecture with real-time AI calls: Making the entire system local-first while still supporting real-time AI calls was an architectural challenge. We solved this with a hybrid approach: all scoring and state management runs locally, while only the analysis calls go to Gemini 3.
Accomplishments that we're proud of
- Deep Reasoner is genuinely adversarial: It does not just critique; it actively tries to destroy your plan and tells you exactly how it would fail. The Devil's Advocate challenges feel like having a skeptical co-founder review your work. This feature leverages Gemini 3's adversarial capabilities to rigorously test assumptions and uncover weaknesses in any decision.
- 20+ production-quality visualizations: We’ve built charts such as Monte Carlo simulations, confidence intervals, correlation matrices, word clouds, radar charts, box plots, and time series. All are rendered natively in the browser using HTML, CSS, and SVG without relying on external charting libraries like D3. This ensures fast performance and flexibility in report generation.
- Rust WebAssembly scoring engine: Our deterministic scoring engine, compiled to WebAssembly (WASM), ensures that scores are reproducible and independent of any AI interpretation. This means the system computes decisions locally, without relying on server-side processing, ensuring local-first and accurate decision-making.
- Full dark/light mode parity: Every element in the interface, from tooltip borders to chart labels, has been explicitly styled for both dark and light modes, ensuring a seamless user experience across all themes. This design flexibility is built with over 13,000 lines of CSS.
- One-click professional reports: We’ve streamlined the process of turning unstructured decision inputs into a professional-grade report. In under 30 seconds, you can convert messy notes into a downloadable, shareable PDF or HTML report, complete with audit trails, visualizations, and AI-driven insights.
What we learned
- Gemini 3 is remarkably capable at structured analysis when given precise schema definitions and role-based system prompts. By using a carefully designed prompt architecture, we were able to direct Gemini 3 to provide actionable, structured feedback with high consistency.
- Adversarial AI (Devil's Advocate mode) produces significantly more useful feedback than encouraging AI. Users need to hear what could go wrong, not just validation. This approach helps uncover hidden risks and assumptions that are often overlooked with traditional validation.
- Multi-provider comparison reveals surprising disagreements between AI models that would be invisible with a single-provider approach. By comparing responses across Google Gemini 3, OpenAI, Groq, and others, we discovered that having diverse perspectives strengthens decision-making and highlights areas of uncertainty.
- Deterministic local scoring combined with AI-powered analysis creates a trust layer that neither approach achieves alone. Local scoring ensures reproducibility, while AI-powered analysis provides valuable insights. Together, they make decision processes more transparent and reliable.
- Progressive enhancement works: Start with local analysis, layer AI critique on top, and let users control the depth of analysis. This approach allows users to engage with the system at their own pace and complexity, enhancing their trust in the results.
What's next for Grounds
- Team collaboration: Real-time multi-user decision sessions with role-based access (Stakeholder, Analyst, Decision Maker).
- Decision history and trends: Track how decisions evolve over time with version diffing.
- Gemini 3 Pro integration: Deeper analysis with longer context windows for complex enterprise decisions.
- Custom template builder: Let organizations define their own decision frameworks and scoring criteria.
- API access: Expose Grounds as a decision-as-a-service API for integration with existing workflows.
- Mobile-first redesign: Full responsive experience optimized for on-the-go decision making.
- API upgrade for demo version: Currently, I am using the free API for demo purposes, which occasionally encounters limitations. However, the application itself is already built to be highly functional and well-optimized. I am hopeful that winning this competition will allow me to continue developing Grounds and gain access to premium API features to further enhance its capabilities.
Built With
- google-gemini-3
- groq-llama-4-scout
- next.js
- openai-gpt-4o-mini
- openrouter
- playwright
- python
- react
- rust
- tailwind-css
- typescript
- wasm








Log in or sign up for Devpost to join the conversation.