-
-
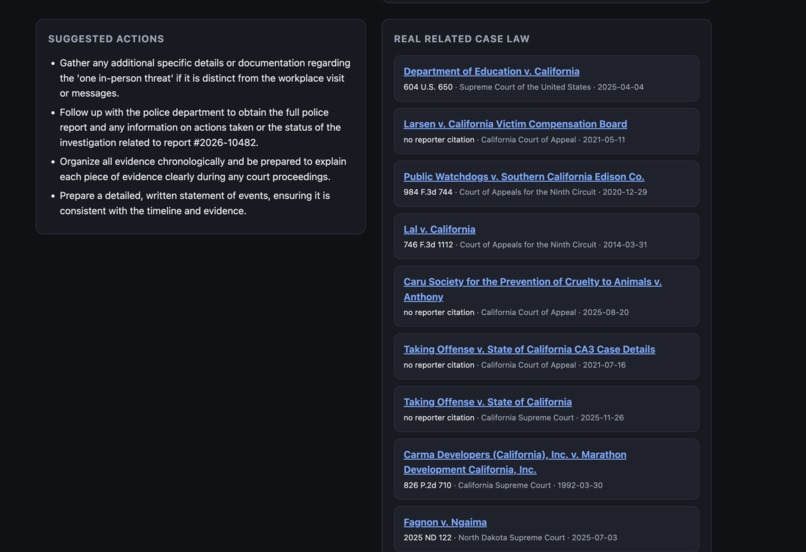
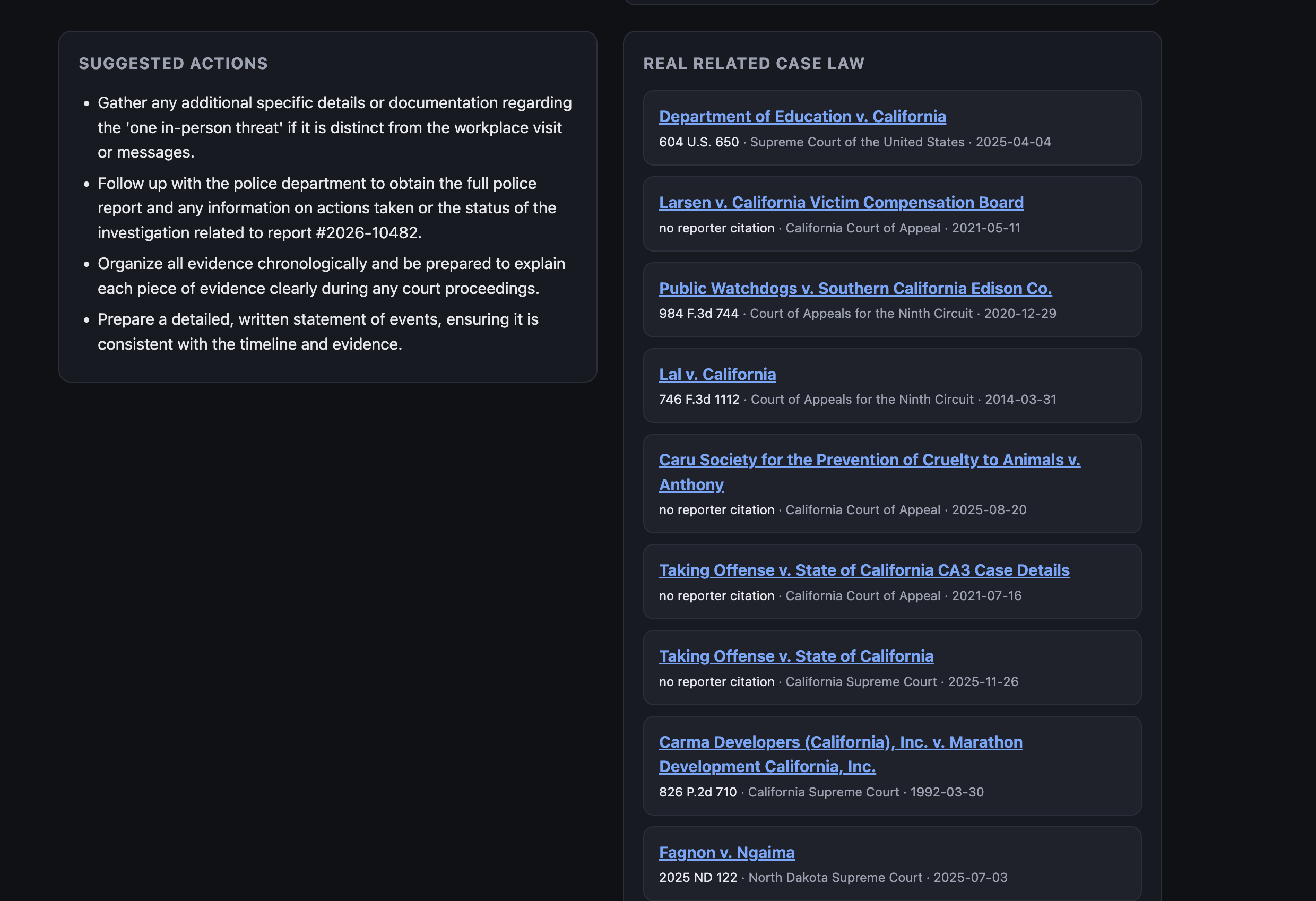
Case Laws Returned from API
-
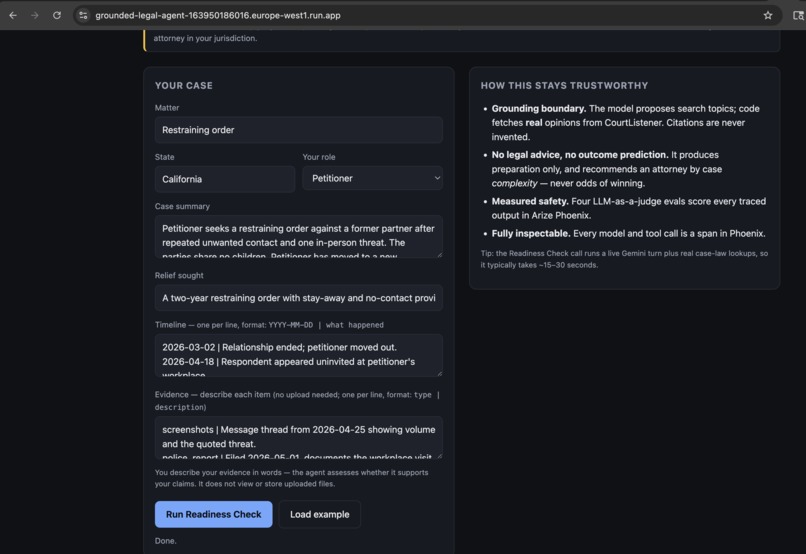
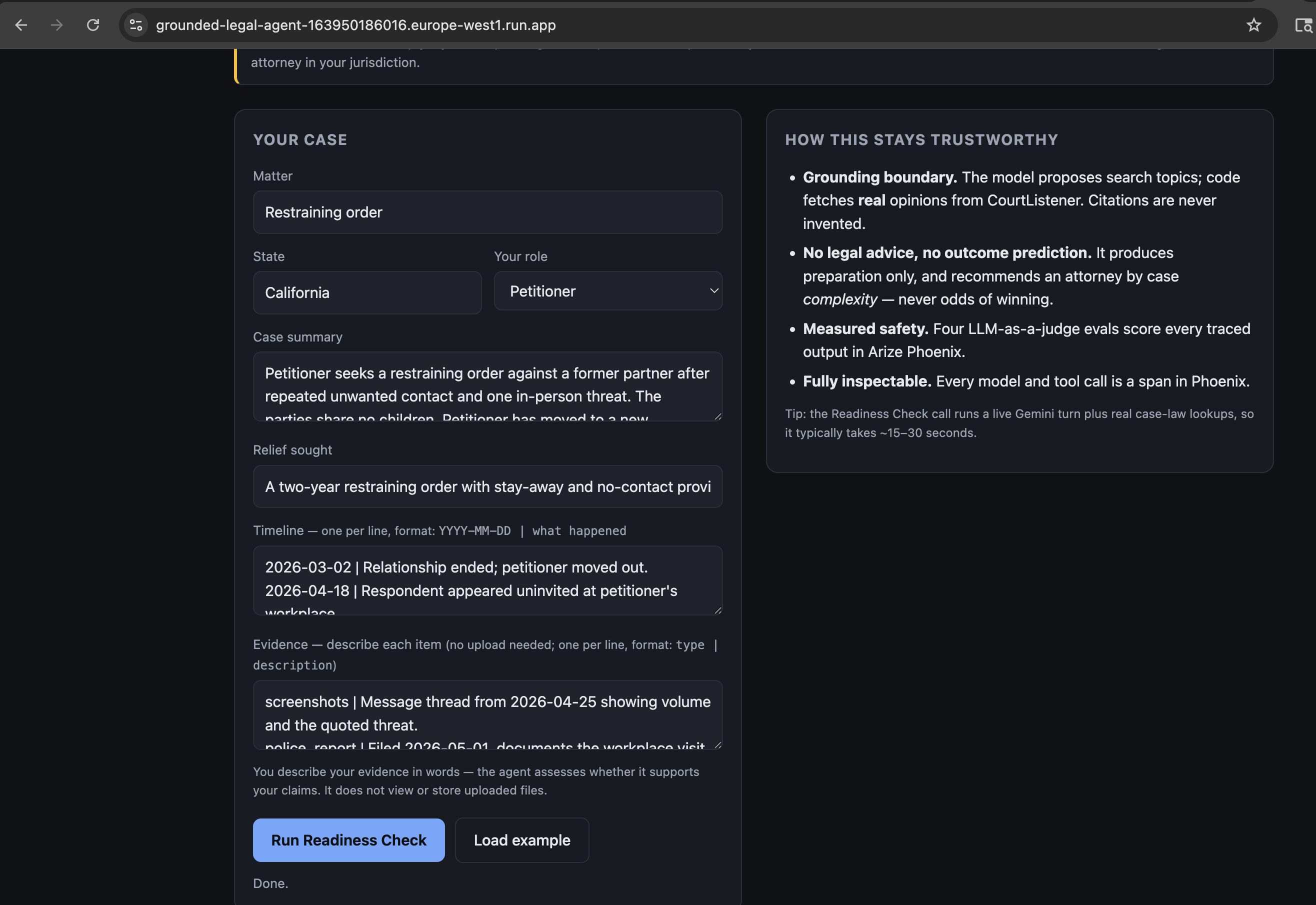
Intake form data
-

Gemini Analysis

Inspiration
LLMs in legal settings have a notorious failure mode: confidently inventing case citations, which has gotten real lawyers sanctioned. They also drift into legal advice and predicting outcomes — risky for unauthorized-practice-of-law reasons and harmful to vulnerable users. I wanted to show that you can put an LLM in a high-stakes domain safely — and prove it stayed safe — using Gemini + Arize.
What it does
A self-represented person submits their case (summary, timeline, evidence). The agent returns a structured Readiness Check: a neutral summary, concrete strengths and gaps, an evidence-clarity assessment, an attorney-recommendation band based on case complexity (never odds of winning), suggested next actions, and real, linkable case law. Every response carries a clear not-legal-advice disclaimer.
Key features
- Grounding boundary — the model proposes neutral search topics; code fetches real opinions from CourtListener; only real, linkable cases reach the user. Fabricated citations are structurally prevented, not just discouraged. (Verified run: 8/8 returned cases resolved to live CourtListener URLs — see READINESS_REPORT.txt.)
- Safety as a measured SLA — four Arize Phoenix LLM-as-a-judge evals score every traced output: No Legal Advice, No Outcome Prediction, Citation Grounding, Calm Factual Tone.
- Full inspectability — every Gemini call and tool call is an OpenInference span in Phoenix.
- Self-improvement loop — the agent reads its lowest-scoring traces and drafts a better system prompt for human review.
- Phoenix MCP integration — a Gemini session can query the agent's own traces, prompts,
datasets, and experiments as MCP tools (
@arizeai/phoenix-mcp). - Degrades safely — with no Phoenix key it still serves reviews (untraced); it refuses to run only without the model runtime. No silent half-broken states.
How I built it
- Agent runtime: Google ADK (
google-adk) with a singleAgent+ aFunctionTool, served behind FastAPI (POST /readiness,GET /health). - Model: Gemini
gemini-2.5-flashfor the agent, the eval judge, and the prompt improver. - Observability & evals: Arize Phoenix via OpenInference auto-instrumentation
(
openinference-instrumentation-google-adk),phoenix.evals(GeminiModel+llm_classify), andSpanEvaluationslogged back to traces. - MCP: Arize Phoenix MCP server registered in
.gemini/settings.json. - Grounding data: CourtListener REST API for real U.S. court opinions.
- Deploy: Containerized (Dockerfile) for Google Cloud Run.
Technologies used
Google Gemini · Google Agent Development Kit (ADK) · Google Cloud Run · Arize Phoenix (OpenInference tracing, LLM-as-a-judge evals, Phoenix MCP server) · FastAPI/Uvicorn · CourtListener API · Python 3.12.
Data sources
- CourtListener (Free Law Project) — real, citable U.S. court opinions, used as the grounding source. Public REST API; works anonymously or with a free token.
- The agent's own Phoenix traces — operational data that feeds the evals and the self-improvement loop.
Findings & learnings
- Move grounding out of the prompt and into code. "Please don't hallucinate citations" in a system prompt is not a guarantee. Making the tool own the fetch — model picks the query, code owns the retrieval — turns a hope into a structural property.
- Treat safety rules as evals, not vibes. Encoding the hard rules as four scored judges made "is it safe?" a visible metric on every trace instead of a manual spot-check.
- The same operational data closes the loop. Phoenix traces feed both the evals and the prompt-improver, so the system can point at concrete failing outputs when proposing a fix.
- Degradability matters for a reference architecture. Making tracing optional (no key = no tracing, app still runs) keeps the project easy to try while showing the production path.
- The pattern generalizes. Swap
search_caselawfor any retrieval that returns real records and the grounding/eval/self-improve scaffolding fits any high-stakes domain.

Log in or sign up for Devpost to join the conversation.