-
-
Groove - Welcome Screen
-

Groove - Features
-
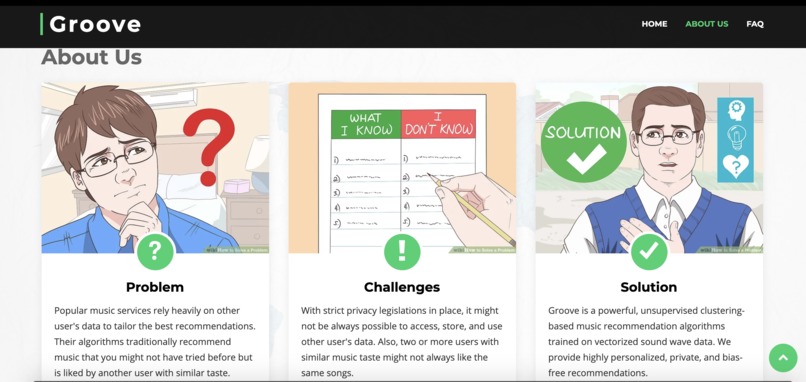
Groove - About Us
-

Groove - FAQ
-
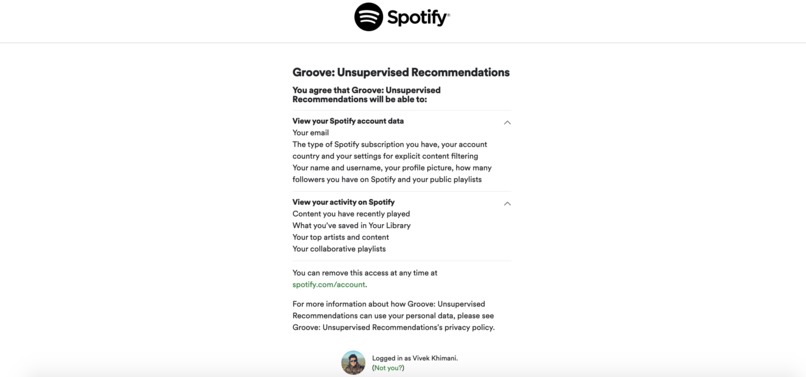
Spotify Authentication Gateway
-
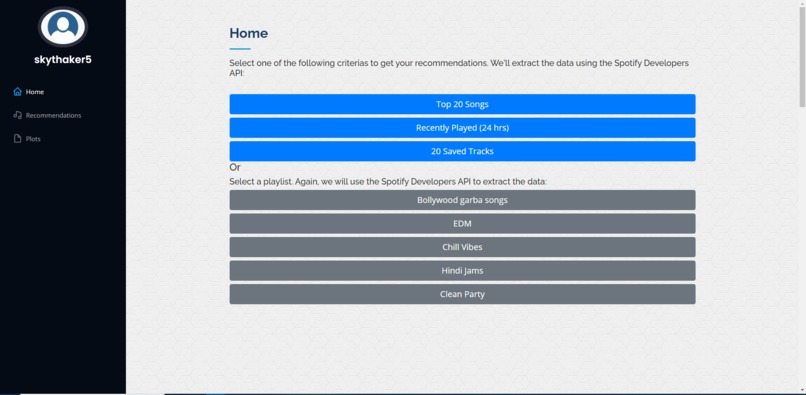
User Landing Page (After Spotify Authentication)
-
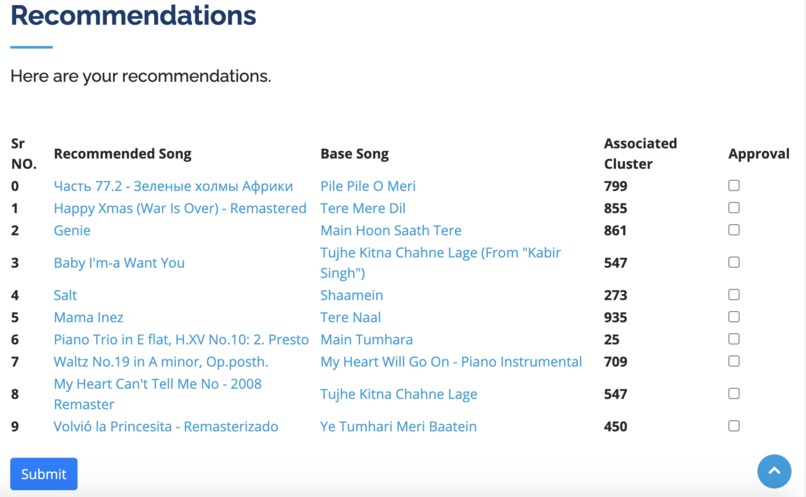
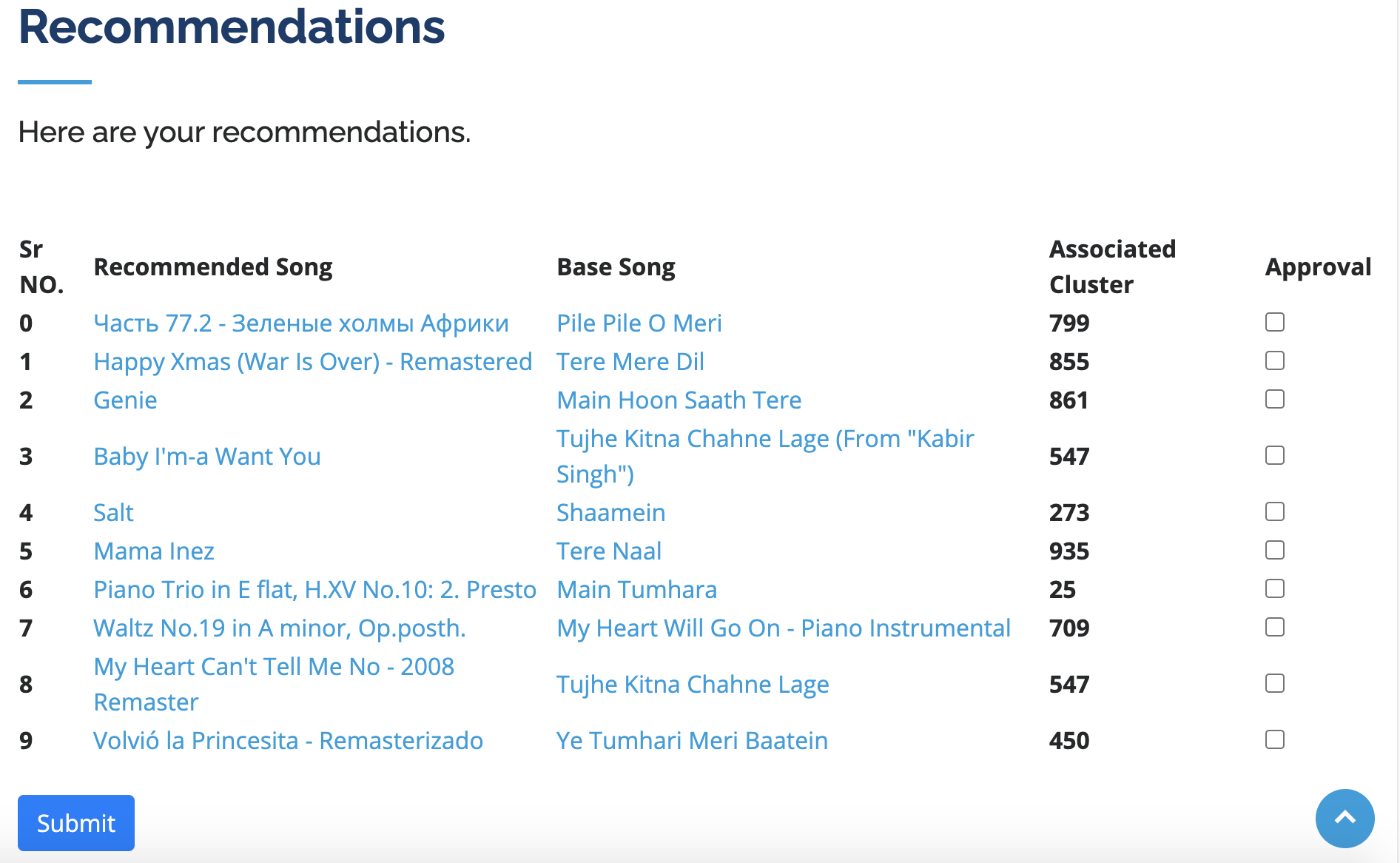
Recommendations Using Our Unsupervised ML Algorithms
-
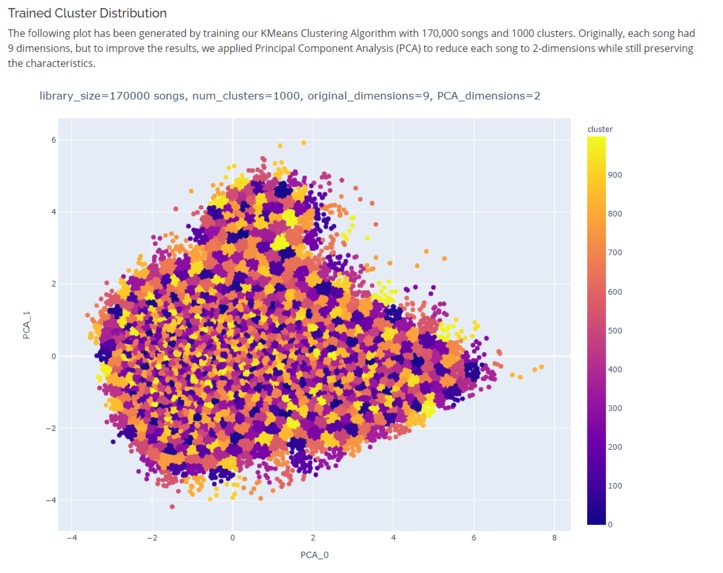
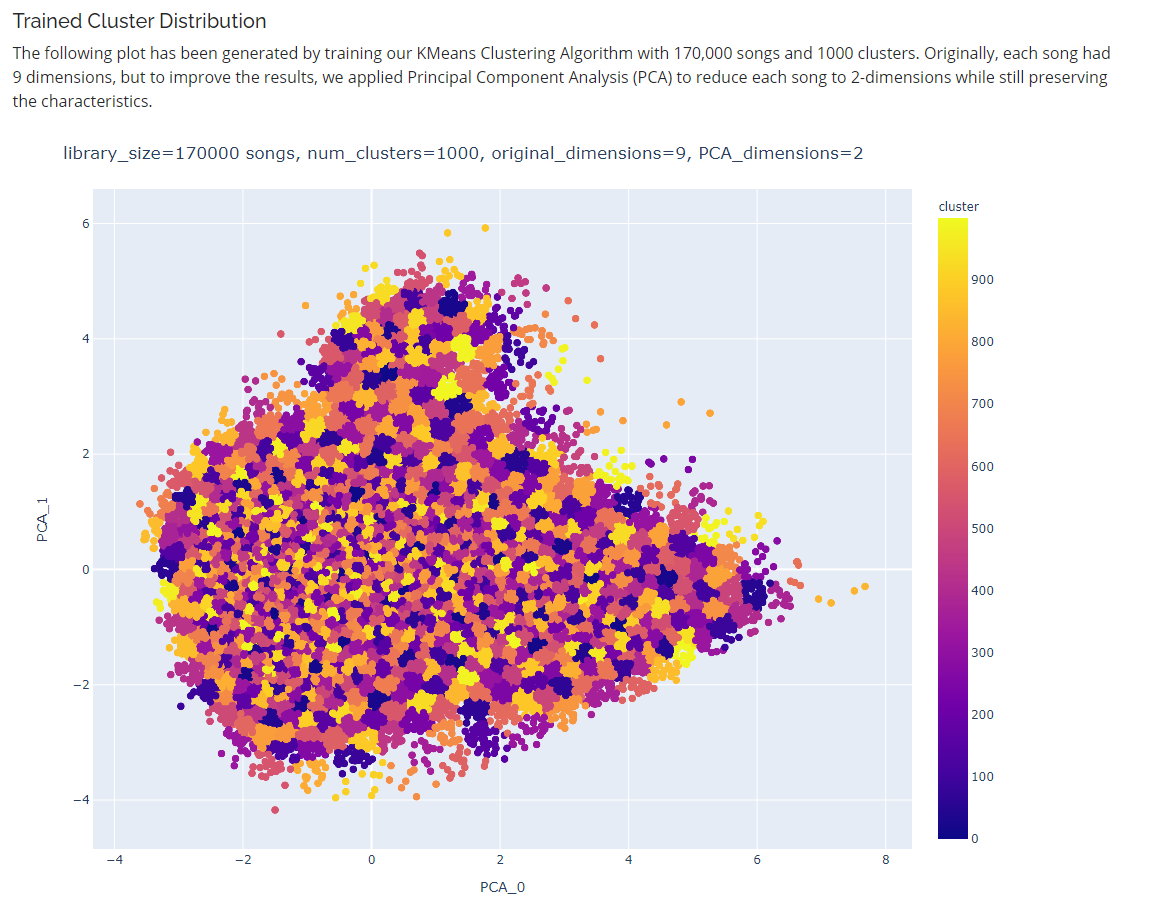
Trained Cluster Distribution generated by training our KMeans Clustering Algorithm with 170,000 songs and 1000 clusters
-
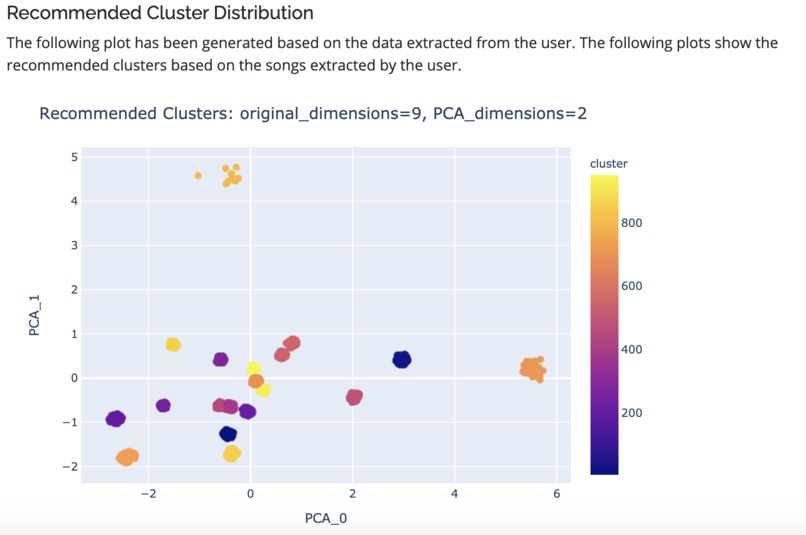
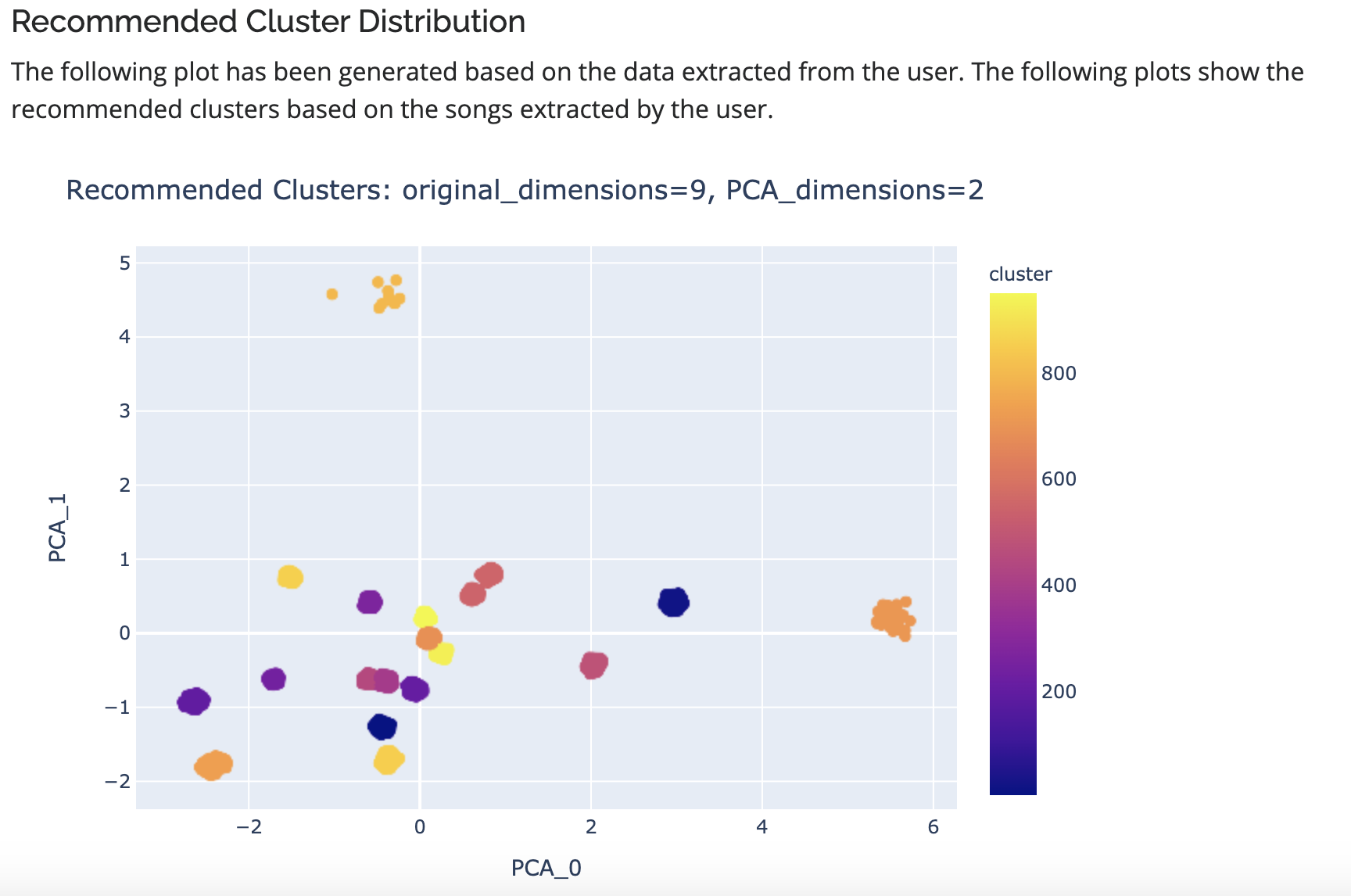
Recommended Cluster Distribution generated based on user preferences fed to trained KMeans Clustering Algorithm



Inspiration
Spotify and other popular music apps rely heavily on other users data to tailor the best recommendations from millions of options available. Traditionally, they find the music in your playlist and find other users with similar interests. After matching two or more users with similar interests, the algorithm recommends the music that a user might not have tried before, but is liked by another user with similar taste. Of course, the companies don't disclose the exact details about their algorithms as it helps them stand out from the competitors. However, the approach described above is usually a backbone of any music recommendation algorithm.
However, with stricter legislations (like GDPR) and increased awareness about privacy, it might not be always possible to access, store, and use other user's data. As the preferred music and playlists can be strong indicator about the psychological conditions of a listener, music might soon get classified as a sensitive user data. Additionally, if two or more users have same taste for a specific song, it cannot be implied that they might share the taste for other songs. At times, a user might only like a specific song due to favorite artist, popular album, or even the actors. In that case, a liked song might introduce a bias and might degrade the performance of the recommender. Lastly, we believe that users often tend to like songs with similar intrinsic sound wave characteristics like beats, tempo, timbre, pitch, frequency, etc.
What it does
As a result, we introduce Groove: An Unsupervised, Data Sensitive Music Recommendation Algorithm.Groove aims to address the issues mentioned in the previous paragraphs and is built using powerful, unsupervised clustering algorithms trained on vectorized sound wave characteristics data. By introducing an unsupervised recommendations approach instead of the traditional approaches, we provide highly personalized, private, and bias-free recommendations. More importantly, our system is implemented to collect and improve based on the recommendation feedback collected from the users.
How we built it
Traditional music recommendation algorithms use a popular collaborative filtering algorithm which finds other users with similar music taste as yours and make recommendations from their library which you might not have heard before. In our case, we have compiled a huge library of Spotify songs and trained an unsupervised clustering algorithm based on implicit sound wave characteristics. Once we get your preferences from Spotify, our algorithm will select an appropriate cluster for your song based on the wave characteristics. We will pick the closest song from the determined cluster and recommend it to you. As a result, we will only use your preferences and clusters generated from our library to make recommendations. We will not use other user's data. This is combined with a sleek and user-friendly web UI to streamline a user's experience.
Challenges we ran into
- Compiling the database containing 170,000 songs and vectorizing to determine intrinsic sound wave characteristics
- Training K-Means clustering algorithm on a huge amount of high-dimensional data
- Determining the appropriate hyperparameters (PCA dimensions, Number of Clusters, etc.) for training the K-Means clustering algorithm
- Dynamically fetching the user data from Spotify API and generating plots, clusters, and results using the trained algorithm
- Designing and implementing an intuitive UI in a short span of time, making it fully functional, and hosting it for real-time testing.
Accomplishments that we're proud of
- Developing and hosting a fully usable product in the extremely short span of time
- Making competitive and relevant recommendations without using any external user data
- Able to connect the Spotify API and use it for connecting the entire pipeline without any bugs
- Developing and training the ML algorithm with appropriate hyperparameters and best possible results
- Deploying the trained ML algorithm with high-speed recommendations and optimal performance
What we learned
- Using the Spotify API, customizing it for the personal use case, and integrating it into Flask, JavaScript environment
- Developing, training, and tuning the K-Means clustering algorithm with a huge amount of high-dimensional data
- Deploying the trained ML algorithm with high-speed and optimal performance
- Generating dynamic plots using Plotly and integrating it to JavaScript for a better explanation of our decisions
- Quickly and efficiently implementing an interactive UI which satisfies the required use case
What's next for Groove
This project can be expanded upon and the results can be drastically improved using one of the following methods:
- Currently we only have 170,000 songs in our library. We can further improve the results if the model is trained with more songs.
- Currently, no filters are applied to the recommendations made by ML algorithm. We can apply filters like year of release, language, genre, etc. to make the recommendations more relevant.
- We are already collecting user approval data. Once we have enough data, we can retrain the ML algorithm with labelled data and a supervised approach to further improve the results.
- K-Means Clustering algorithm is just a starting point for this problem. We can explore more algorithms (probably time-series based clustering) and hyperparameters to get even better results.
- We can include more features (sound wave characteristics) and perform time-series based clustering to improve the results. This is a great direction for further exploration.



Log in or sign up for Devpost to join the conversation.