-
-

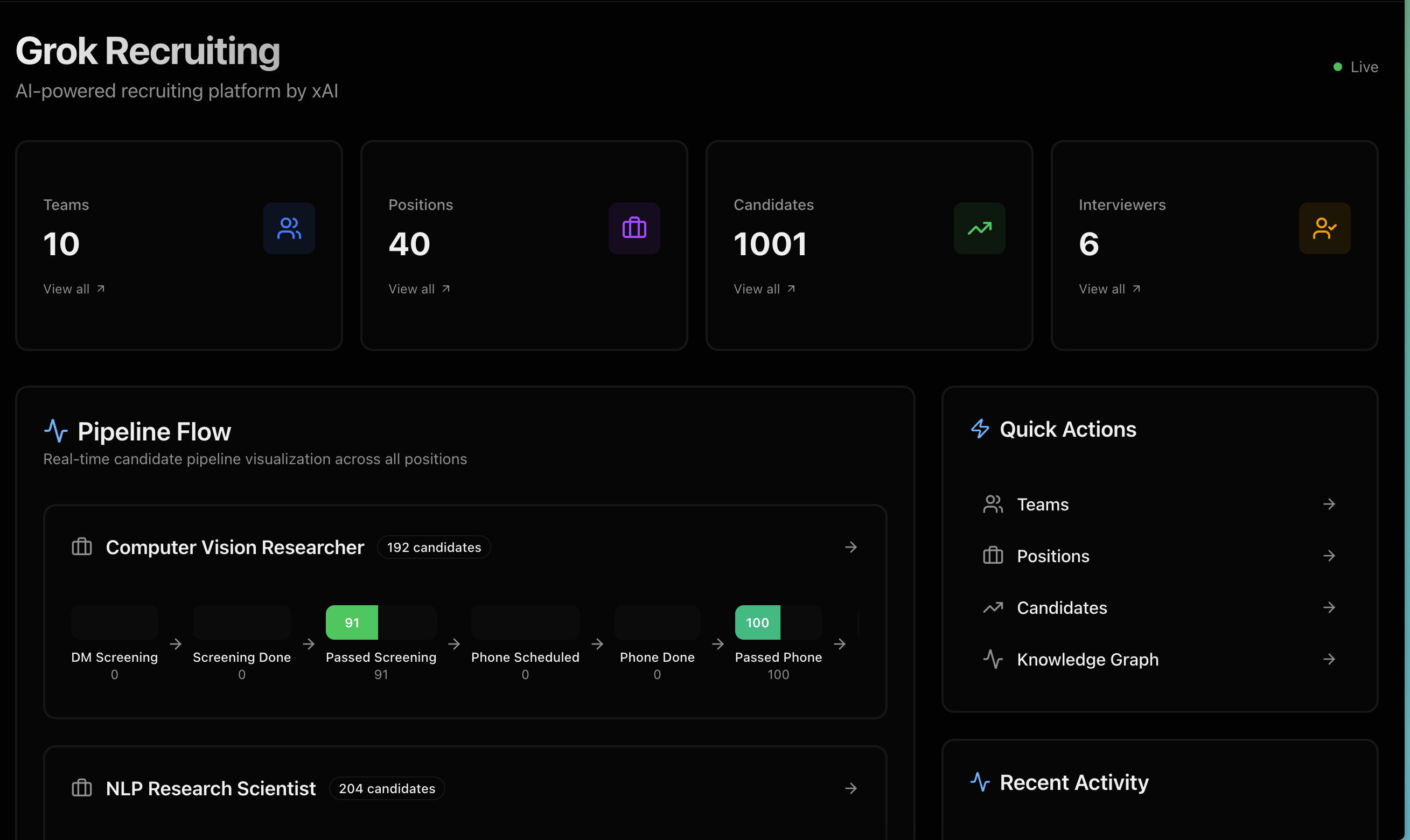
Graph of candidates, positions, teams, and interviewers
-
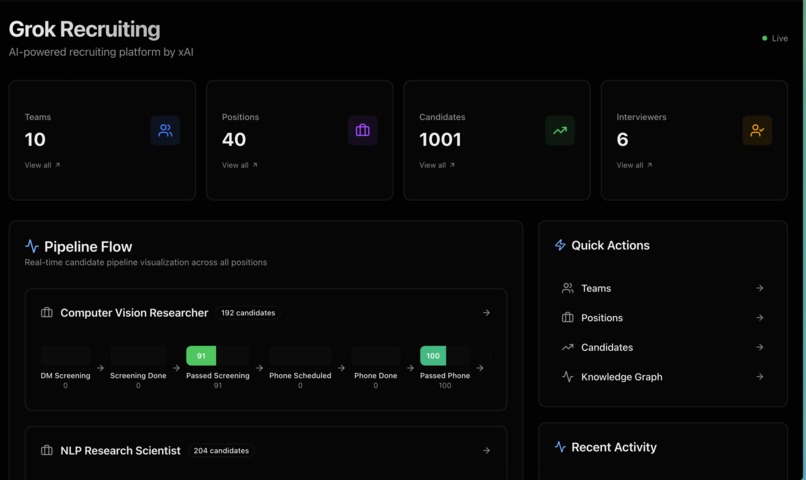
Dashboard
GrokRecruiter - Devpost Submission
Inspiration
Traditional recruiting is broken. Companies post jobs and manually sift through responses. Phone screening is time-consuming. Matching candidates to teams is subjective. We wanted to build an AI system that automates the entire recruiting pipeline - from posting positions on X to conducting phone screens to matching candidates to teams - using a specialized knowledge graph backed by research.
What We Built
GrokRecruiter is an end-to-end AI recruiting platform that automates both inbound and outbound recruiting using X integration, automated phone screening, and a research-backed knowledge graph for intelligent matching.
How We Built It
Outbound Recruiting: X Integration & Posting
Position Creation & X Posting:
- Grok AI Position Creation - Companies chat with Grok to describe roles. Grok extracts requirements, must-haves, tech stack, team context.
- AI-Generated X Posts - Grok generates engaging job posts optimized for X. Companies can post directly with one click.
- Distribution Flags - Positions can be flagged for X posting or Grok availability (for candidate queries).
Interested Candidate Tracking:
- Comment Monitoring - System tracks when candidates comment "interested" on X posts.
- Automatic Candidate Creation - Creates candidate profiles from X handles, syncs data from GitHub, arXiv, X activity.
- DM Screening Service - Automatically sends personalized DMs asking for additional information.
- DM Response Polling - Continuously polls X API for DM responses, parses them with Grok AI, extracts structured data.
DM Screening Flow:
- Candidate comments "interested" → System creates profile → Enters pipeline at
dm_screeningstage - System sends personalized DM based on position requirements and candidate gaps
- Polls for DM responses → Grok extracts information → Calculates screening score
- Passes threshold? → Moves to
dm_screening_passed→ Ready for phone screen - Fails? → Moves to
dm_screening_failed→ Rejected
Inbound Recruiting: Automated Pipeline
Pipeline Stages (Fully Tracked):
dm_screening- DM sent, waiting for responsedm_screening_completed- Response received, score calculateddm_screening_passed- Passed screening (score ≥ 0.5)phone_screen_scheduled- Phone call scheduledphone_screen_completed- Call finished, decision madephone_screen_passed- Passed phone screenmatched_to_team- Team matching completedmatched_to_interviewer- Interviewer matching completedaccepted/rejected- Final decision
Phone Screening (Fully Automated):
- Vapi Integration - Real voice calls (not chatbots). System calls candidate's phone number.
- Grok AI Interviewer - Conducts personalized conversation based on:
- Candidate background (GitHub, arXiv, X activity)
- Position requirements
- Hyper-personalized questions (different for ML researcher vs backend engineer)
- Information Extraction - Grok extracts skills, experience, motivations, technical depth from conversation transcript
- Automated Decision Engine - Multi-layer validation:
- Must-have requirements check (hard filter)
- Embedding similarity to position (0.65+ threshold)
- Extracted info quality validation
- Outlier detection (catches inconsistencies)
- Bandit-based confidence scoring (0.70+ threshold)
- Result - Pass/fail decision with detailed reasoning, automatically stored in knowledge graph
Team & Interviewer Matching:
- Team Matching - Finds best team based on:
- Team needs vs candidate skills (embedding similarity)
- Team expertise alignment
- Culture fit
- Returns top matches with reasoning
- Interviewer Matching - Matches to best interviewer based on:
- Expertise overlap
- Interviewer success rates
- Interview style compatibility
- Can be automated (technical interviews based on role) or manual
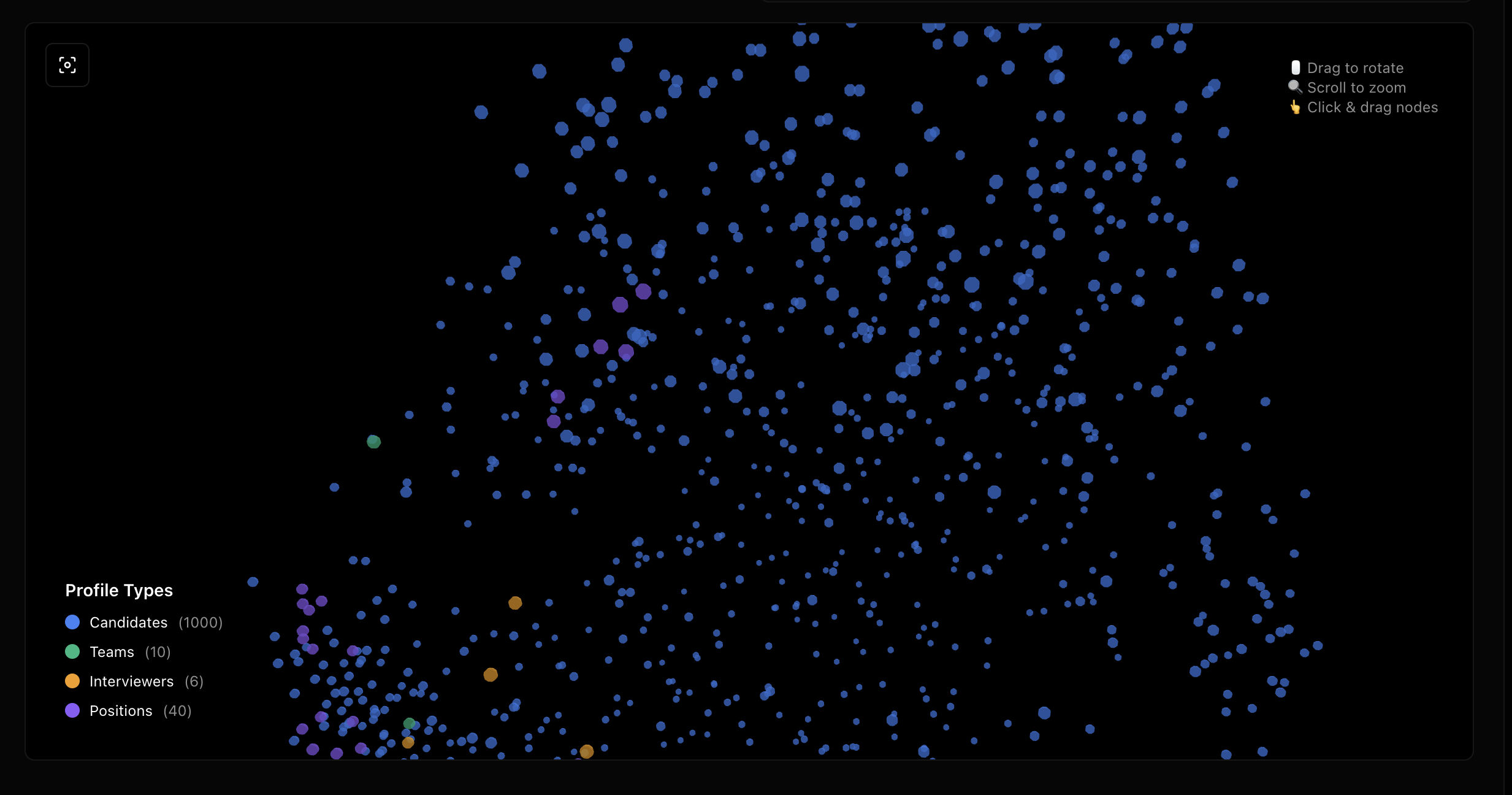
Knowledge Graph Architecture (Research-Backed)
Why Weaviate Over Neo4j:
- Neo4j is overkill for our use case. We don't need complex graph traversals.
- Weaviate is purpose-built for vector similarity search - exactly what we need.
- Faster queries: <500ms for 1000+ candidates vs seconds for Neo4j graph queries.
- Native vector support: Built-in cosine similarity, no custom queries needed.
Research Foundation: Our knowledge graph design is based on:
- Frazzetto et al. (2025) - "Graph Neural Networks for Candidate-Job Matching: An Inductive Learning Approach" - Adapted their similarity computation methodology to embeddings
- Sacha et al. - "GraphMatch: Fusing Language and Graph Representations" - Inspired our cross-type matching approach
Architecture:
4 Profile Types stored as separate Weaviate classes:
- Candidates: Technical profiles (skills, GitHub repos, arXiv papers, X activity, resume data)
- Teams: Team profiles (needs, expertise, culture, tech stack, hiring priorities)
- Interviewers: Interviewer profiles (expertise, success rates, interview style, evaluation focus)
- Positions: Position profiles (requirements, must-haves, tech stack, responsibilities)
768-Dimensional Embeddings (MPNet model):
- Specialized embedder trained on recruiting domain
- Converts each profile into 768-dim vector
- Captures semantic meaning: skills, experience, culture fit, technical depth
- Normalized for cosine similarity matching
- Research: MPNet (Song et al.) provides better semantic understanding than BERT for domain-specific tasks
Dual Storage System:
- PostgreSQL: Relational data (teams, positions, interviewers, pipeline stages, DM conversations)
- Weaviate: Vector embeddings for fast similarity search
- Both stay in sync automatically via KnowledgeGraph abstraction layer
Querying Mechanisms:
- Similarity Search: Cosine similarity between embeddings (fast, accurate)
- Cross-Type Search: Find candidates similar to position, teams similar to candidate
- Ability Clustering: K-means clustering groups candidates by technical abilities (e.g., "all CUDA experts")
- Multi-Criteria Queries: Combine metadata filters (PostgreSQL) + vector similarity (Weaviate)
- Query Engine: Advanced queries like "show me all ML researchers with 5+ arXiv papers and GitHub stars > 10k"
Research Contributions:
Embedding-Warm-Started Bandits (Anand & Liaw, 2025):
- First application of embedding similarity to initialize Feel-Good Thompson Sampling priors
- 3x faster learning vs cold-start bandits
- Used for phone screen decision confidence scoring
Position-Specific Matching:
- Not just "find similar candidates" but "find candidates similar to THIS position"
- Combines embedding similarity with position-specific requirements
- More accurate than generic similarity search
Cross-Type Similarity:
- Find candidates similar to teams (culture fit)
- Find teams similar to positions (team-position alignment)
- Enables intelligent matching across all profile types
Technical Implementation
Backend Stack:
- FastAPI - Modern Python web framework
- PostgreSQL - Relational database (multi-tenant, ACID transactions)
- Weaviate - Vector database (self-hosted, no API costs)
- Grok AI - Conversational AI, information extraction, decision-making
- Vapi - Voice call automation (real phone calls)
- X API - OAuth 2.0, posting, DM polling, comment tracking
- GitHub API - Repo data, stars, contributions
- arXiv API - Research papers, citations
Frontend Stack:
- Next.js 16 - React framework with App Router
- TypeScript - Type-safe development
- React Query - Data fetching, caching, real-time updates
- Recharts - Pipeline visualizations, distribution charts
- react-force-graph-3d - 3D embeddings visualization
- Framer Motion - Smooth animations
ML/AI Stack:
- MPNet Embeddings - 768-dim specialized embeddings (sentence-transformers)
- Feel-Good Thompson Sampling - Bandit algorithm for learning from feedback
- K-means Clustering - Ability grouping
- PCA - Dimensionality reduction for 3D visualization (768-dim → 3D)
Challenges We Faced
DM Polling & Response Parsing:
- Challenge: X API rate limits, parsing unstructured DM responses
- Solution: Efficient polling service, Grok AI for information extraction, structured data extraction
Phone Screening Automation:
- Challenge: Real voice calls (not chatbots), natural conversation, information extraction
- Solution: Vapi integration, Grok AI interviewer with hyper-personalized prompts, multi-layer decision engine
Knowledge Graph Design:
- Challenge: Choosing between Neo4j (graph) vs Weaviate (vector). Designing embeddings that capture semantic meaning.
- Solution: Weaviate for vector similarity (faster, purpose-built). Specialized 768-dim MPNet embeddings trained on recruiting domain.
Cross-Type Matching:
- Challenge: Matching candidates to positions, teams to candidates, interviewers to candidates - all using same embedding space
- Solution: Unified 768-dim embedding space for all profile types, cosine similarity for cross-type matching
What We Learned
- Vector databases > Graph databases for similarity search use cases (Weaviate vs Neo4j)
- Real voice calls are more effective than chatbots for phone screening (Vapi integration)
- DM polling requires efficient rate limit handling and intelligent parsing (Grok AI extraction)
- Cross-type embeddings enable matching across all profile types in unified space
- Multi-layer decision engines prevent false positives (must-haves + similarity + extracted info + outliers)
- Research-backed approaches (FG-TS, MPNet, graph matching) provide solid foundation
What's Next
- Enhanced DM screening with multi-turn conversations
- Automated technical interview generation based on role
- Real-time learning from recruiter feedback using Feel-Good Thompson Sampling
- Expanded data sources (LinkedIn, other platforms)
- Advanced query engine for complex talent searches
Research Citations
- Frazzetto et al. (2025) - "Graph Neural Networks for Candidate-Job Matching: An Inductive Learning Approach" - Similarity computation methodology
- Anand & Liaw (2025) - "Feel-Good Thompson Sampling for Contextual Bandits" - Bandit algorithm for decision-making
- Sacha et al. - "GraphMatch: Fusing Language and Graph Representations" - Cross-type matching inspiration
- Song et al. - MPNet embeddings for domain-specific semantic understanding
Built with: Grok AI (xAI), Weaviate, Vapi, FastAPI, PostgreSQL, Next.js, TypeScript, MPNet Embeddings, Feel-Good Thompson Sampling, X API, GitHub API, arXiv API
Built With
- arxiv-api
- docker
- fastapi
- feel-good-thompson-sampling
- github-api
- grok-ai-(xai)
- mpnet-embeddings
- next.js
- postgresql
- react-query
- recharts
- typescript
- vapi
- weaviate
- x-api

Log in or sign up for Devpost to join the conversation.