-
-
Custom Landing Page, no AI, custom blender models + three.js
-
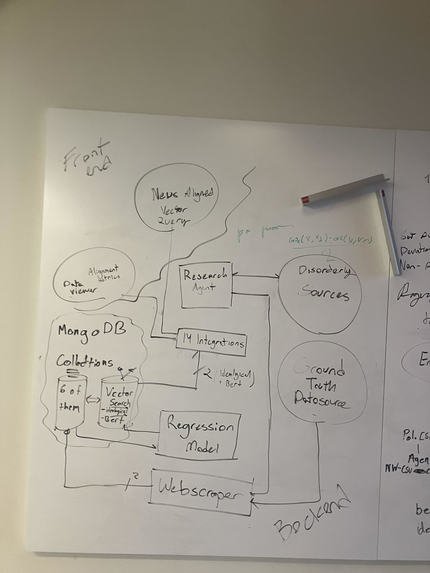
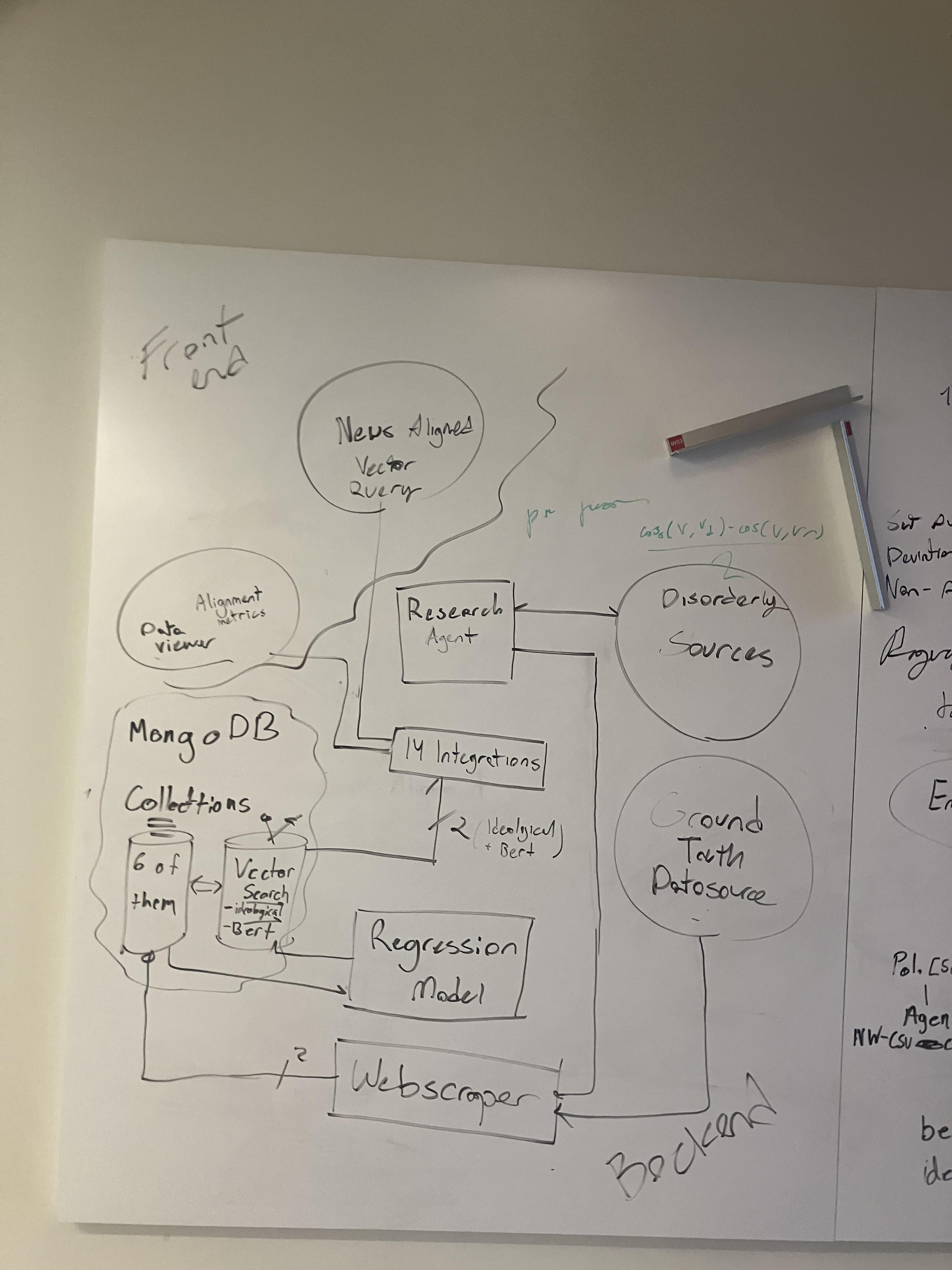
Whiteboard System Design
Gríma
def - A secondary advisor from J.R.R. Tolkien's Lord of the Rings who whispers in the ear of power, shaping decisions invisibly.
In the United States, our executive branch is comprised of 15 agencies led through roughly 4,000 politically appointed officials, starting with Senate-confirmed cabinet secretaries. These individuals set policy direction and appoint an additional ~2,500 noncareer SES and Schedule C officials within their organizations — operational leaders and confidential aides who steer the programs and regulations that have a daily impact on Americans.
Yet the public has almost no visibility into who these people are or what they believe. The GAO found in 2026 that the government's own appointee database is missing entire federal entities and over 130 Senate-confirmed positions, with 600+ entries containing errors (GAO-26-108164). The only major public tracker covers roughly 800 of the top-tier roles, leaving the ~2,500 lower-tier appointees who actually run programs and control information flow effectively invisible. The Journal of Politics (2025) confirms what this opacity costs: appointee vacancies and instability correlate directly with lower federal agency performance, and the damage falls hardest on rural communities, where USDA Rural Development has lost 36% of its staff and Social Security field offices are closing, stranding seniors hours from the nearest service point (NSAC, 2025; Urban Institute, 2025). In the end, Americans are left in the dark on who's accountable for steering some of the most polairizng and impactful decisions in our government.
What it does
These challenges are why we built Gríma is a civic transparency platform that deploys an agentic research pipeline to scrape, entity-resolve, and fuse data across 10+ government and public sources into unified profiles for 1,600+ federal appointees. Using NLP embeddings calibrated against validated political science models, Gríma maps each official's ideology, tracks drift over time, and connects niche policy moves to the people calling the shots.
How we built it
The services needed to power Gríma can be categorized into the research agent and its 14 custom microservices (anthropic tools) to scrape sources, the story researcher, custom NLP BERT embedding pipeline, and the KEY MongoDB storage layer which hosts the MASSIVE amounts of data we collected and powers the Vector Search functions for the ML pipelines.
Research Agent: The research agent is the backbone of the platform, a FastAPI-based orchestrator that coordinates 14 purpose-built microservices to ingest, normalize, and enrich political data from across the federal government and the public web. Each microservice acts as a specialized scraper or API adapter targeting a single authoritative source, and the agent dispatches them in parallel to build a comprehensive dossier on every executive-branch appointee. These are all the integraions with individual tools that we build: Washington Post Appointee Tracker, Plum Book Importer, Congress.gov Speech Extractor, Congressional Bill Analyzer, Federal Register / Executive Order Scraper, Public Statement Collector, Social Profile Aggregator, OpenSecrets Campaign Finance, FEC Bulk Data Adapter, ProPublica Records, VoteView DW-NOMINATE Scores, ScrapingDog News Search, ScrapingDog Image Fetcher, Court Listener API, GAO Audit Reports, Wikipedia, and USOGE Financial Disclosures.
BERT embedding pipeline: Training:
- Embed 11k+ documents from Research Agents for all members of Congress 2012 - Present into a 384 TinyBERT vector
- Add Regression head to project & regress TinyBERT vector into 2 dimension DW-Nominate standard political ideology scores
- Calculate loss based on DW-Nominate ground truth member political and socioeconomic scores https://voteview.com/data
Inference:
- Aggregate 1k+ documents for current executive political appointees
- Embed documents per person, average pool document vectors, and regress embedding to 2 dim ideology vector.
- Compute raw scores from vectors based on cosine similarity from average centroids.
MongoDB Storage & RAG:
Challenges we ran into
Accomplishments that we're proud of
What we learned
Built With
- anthropic
- blender
- huggingface
- mongodb
- numpy
- python
- pytorch
- react
- scikit-learn
- scipy
- three.js
- typescript

Log in or sign up for Devpost to join the conversation.