-
-
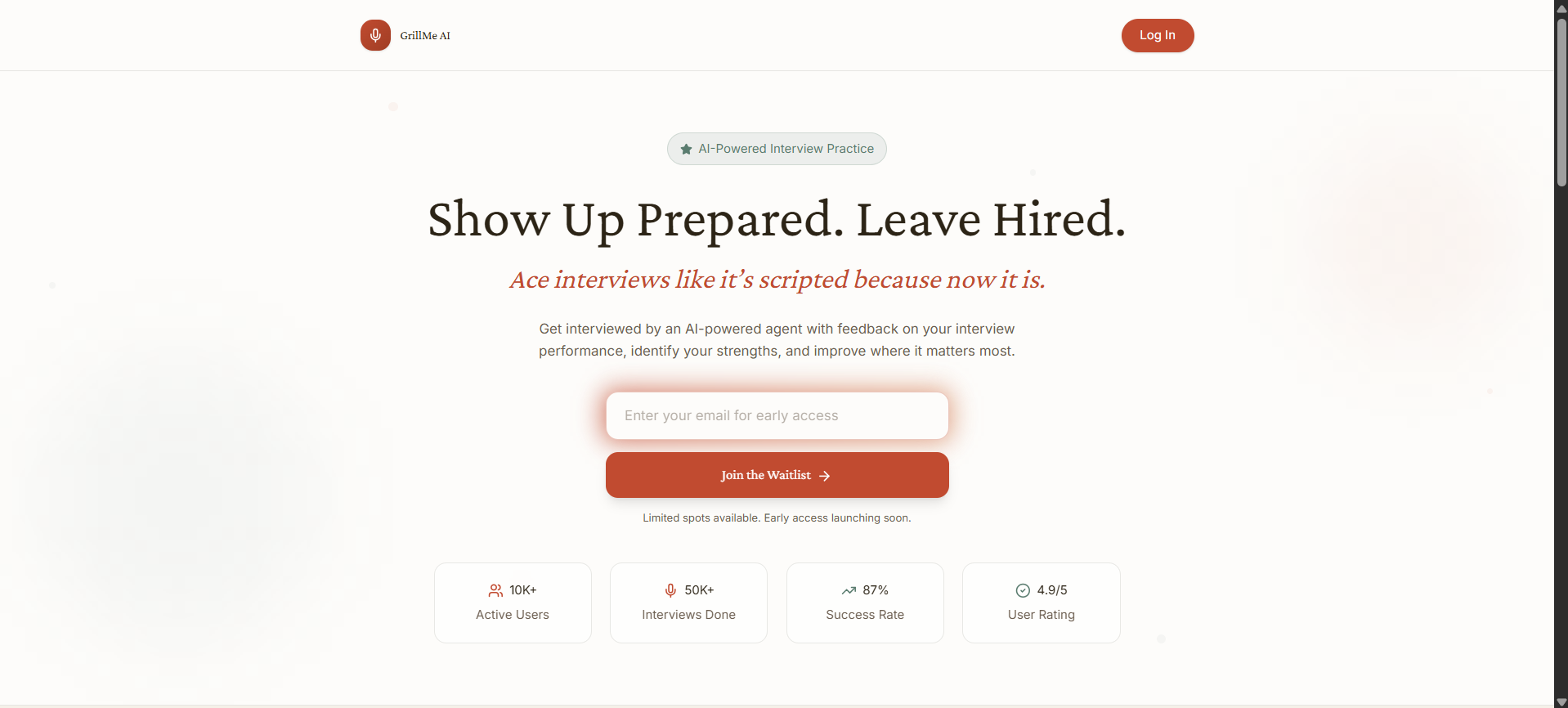
Front Page
-
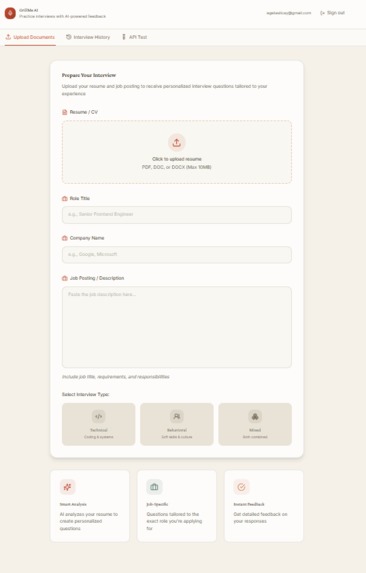
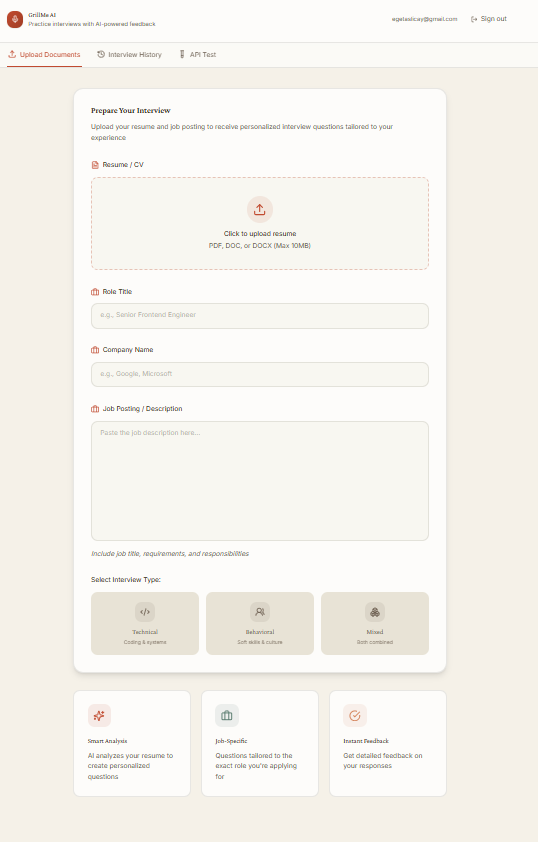
Resume Entry Page
-
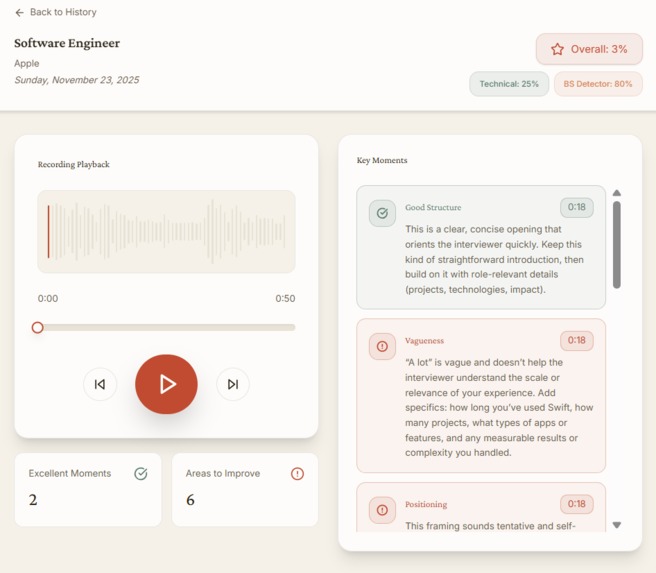
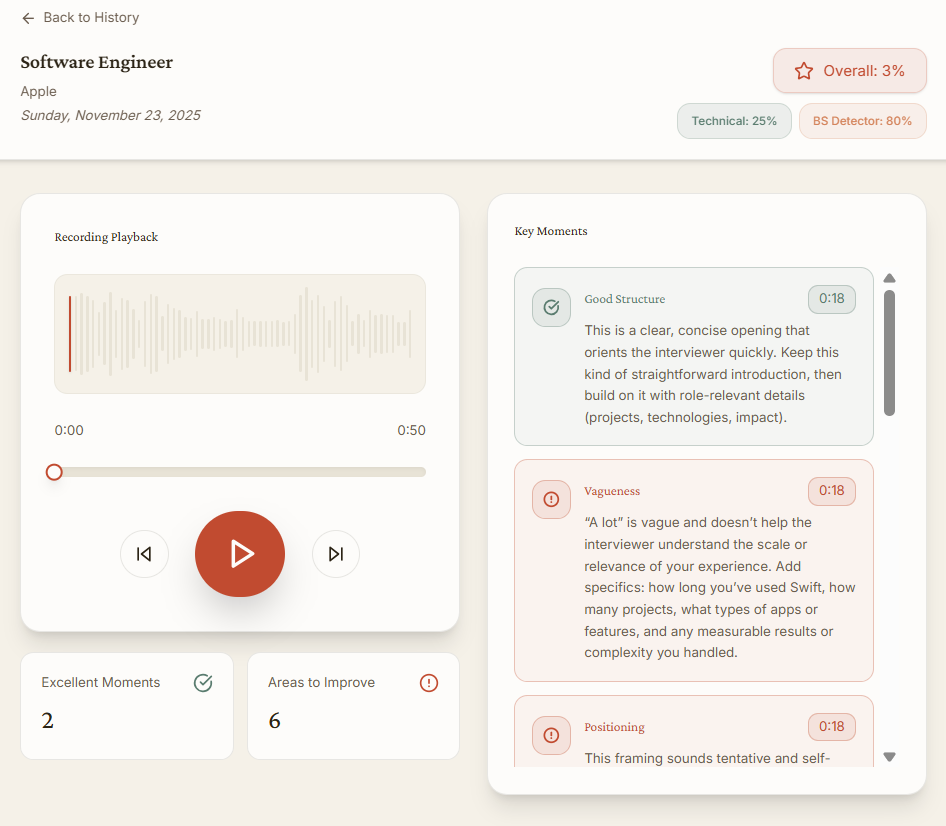
Post Interview Analysis Page
-
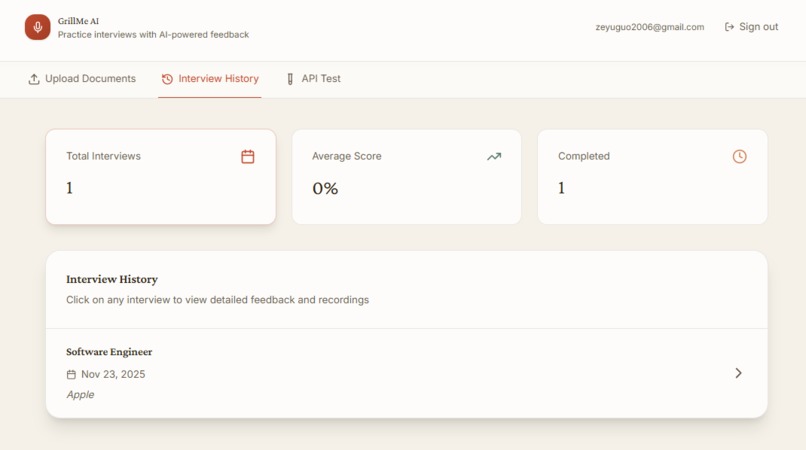
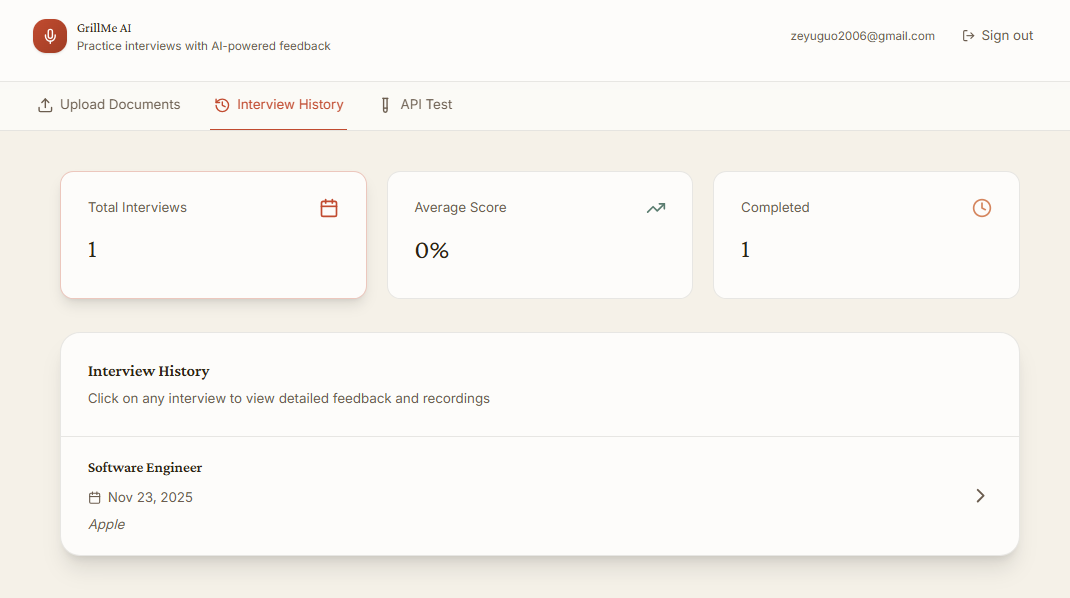
All interviews Page
Inspiration
Interview preparation tools often fall into two extremes: generic question banks or text based chat systems that fail to recreate the pressure of a real interview. Students and early career professionals repeatedly described three problems: practice feels unrealistic, feedback is vague, and nothing adapts to their resume or target job.
We set out to create a system that understands a user's background, identifies weaknesses, and offers specific, actionable feedback. GrillMe AI was built to provide realistic mock interviews that respond to the user's resume, job description, and spoken answers.
What it does
GrillMe AI provides personalized mock interviews using real time voice interaction. Users upload their resume, paste a job description, and choose an interview type. The system extracts relevant details, identifies gaps between the resume and the job requirements, generates a targeted question set, and conducts a full voice interview with a live transcript.
After the interview, the Analyzer produces detailed scoring and timestamped highlights. Users can review their strengths, weaknesses, vague answers, and specific mistakes. All past interviews are saved with audio playback, transcripts, and scoring history.
Key features:
- Resume parsing for PDF and DOCX
- Job description analysis
- Personalized Attack Plan with targeted questions
- Real time two way voice interviews
- Lifeline hints during the interview
- Live transcript with status indicators
- Structured analytics with multiple scores
- Timestamped feedback (green, yellow, red)
- Interview history with audio and transcripts
How we built it
Frontend (React, TypeScript, Vite)
The frontend manages resume uploads, validation, job description input, and the full interview flow. It handles microphone permissions, displays streaming transcripts, coordinates the voice session, and renders all scores and highlights. Tailwind and Radix UI support styling and accessibility. A Vite proxy forwards all /api/* requests to the backend during development.
Backend (Cloudflare Workers + Hono)
The backend is fully deployed on the edge. Major components include:
- Resume Parsing: Mammoth and UnPDF convert DOCX and PDF files into structured text.
- Attack Plan Generator: OpenAI models analyze resume content and job requirements to produce tailored question sets.
- Real Time Voice: ElevenLabs provides low latency two way audio for the interview loop.
- Interview Analyzer: OpenAI processes transcripts to produce the Overall Score, Technical Depth Score, BS Detection Score, and all timestamped highlights.
- Supabase: Stores user accounts, interview sessions, transcripts, audio references, and metadata.
- Zod: Provides shared type safe validation across the frontend and backend.
Key endpoints include:
- User creation and authentication
- Creating interview sessions
- Retrieving interview history
- Fetching ElevenLabs configuration
- Requesting lifeline hints
- Running the analysis pipeline
- Fetching results
Challenges we ran into
Real time audio synchronization
Synchronizing ElevenLabs streaming, Cloudflare Worker constraints, and the browser event loop required a carefully designed event based architecture to maintain consistent latency.
Resume parsing inconsistency
Resumes vary widely in formatting and structure. Building a robust extraction pipeline required multiple fallback paths and extensive validation.
Designing meaningful scoring logic
We needed feedback that accurately identified vague answers, missing detail, or shallow technical depth. This required multi step prompt engineering and repeated iteration.
Data flow and state consistency
Interview sessions pass through several stages: parsing, configuration, voice session, analysis, and results. Keeping these states consistent across the edge backend, Supabase, and the frontend required careful type safe design.
Accomplishments that we are proud of
- Delivering a voice first low latency interview experience with ElevenLabs
- Building a complete resume plus job description analysis pipeline
- Creating the Attack Plan system for targeted questioning
- Producing detailed timestamped feedback that identifies strong, vague, and incorrect moments
- Deploying both the frontend and backend in a production ready architecture
- Implementing a history system with audio, transcripts, and scoring
What we learned
- How to architect a real time voice application on an edge environment
- How to parse and normalize text from PDF and DOCX resumes
- How to design multi stage AI pipelines for question generation and analysis
- How to use Zod to enforce end to end type safety
- How users interpret feedback and what format helps them improve
What is next for GrillMe AI
We plan to extend the system with:
- Company specific interview models
- Follow up questions that adapt dynamically to user answers
- Delivery and communication analysis
- Long term progress tracking
- Support for system design interviews
- Expanded analytics for behavioral interviews
Built With
- auth
- cloudflare-workers
- elevenlabs-api
- elevenlabs-conversational-ai-sdk
- git
- hono
- lucide-icons
- mammoth
- node.js
- npm
- openai-api
- radix-ui
- react
- storage)
- supabase-(postgres
- tailwind-css
- typescript
- unpdf
- vite
- wrangler
- zod

Log in or sign up for Devpost to join the conversation.