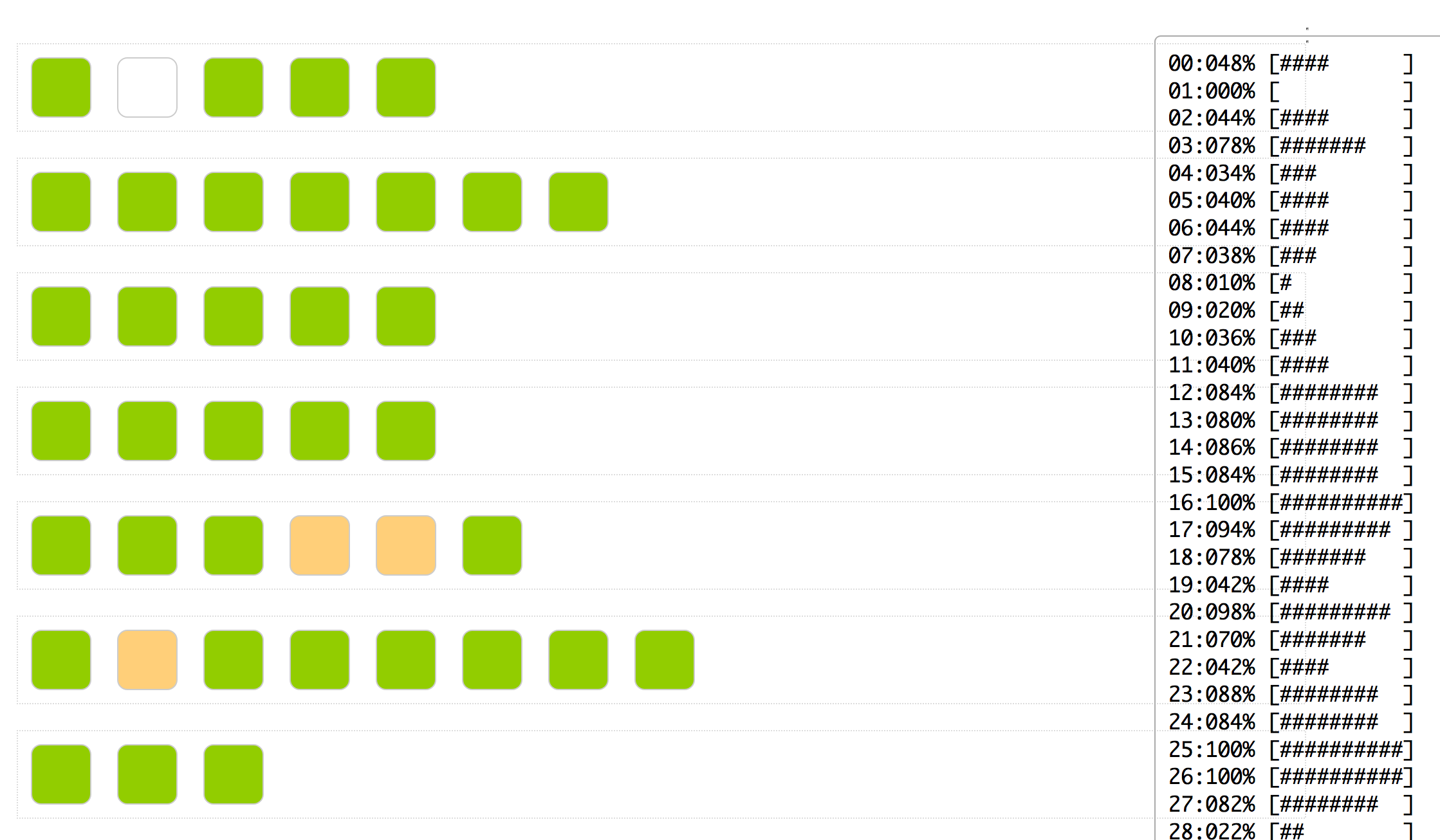
Inspiration
We are students who are extremely interested in distributed systems and multi-threaded applications. Whenever we worked on distributed applications we always felt a gap between our understanding of how the system is working and how the system is actually working. We wanted a way to visualize how the information is spreading and how the resources are being utilized in the network so as to have a better understanding of our system. Enter Gridy.
What it does
- It helps you visualize the information spread in your distributed application.
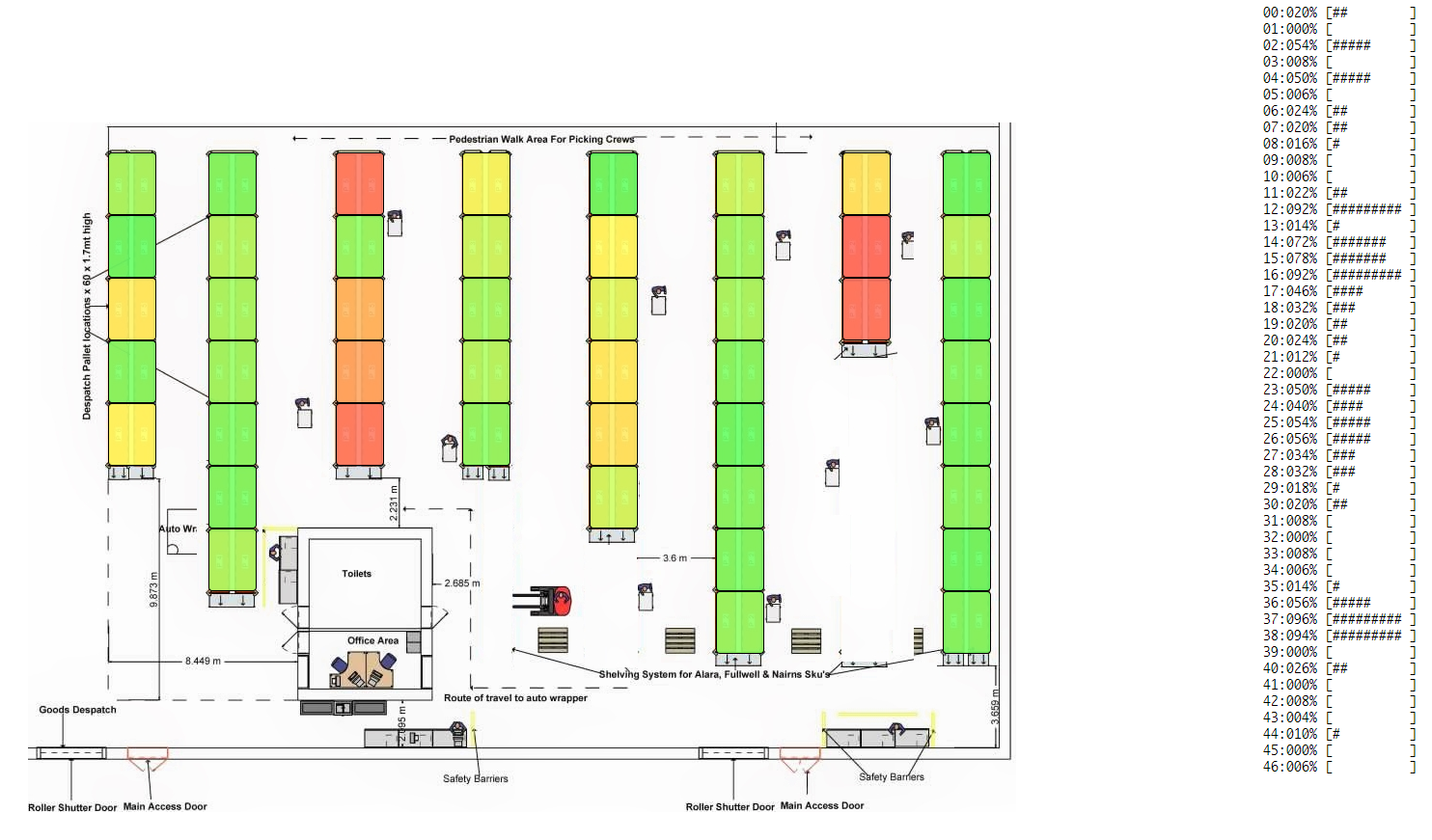
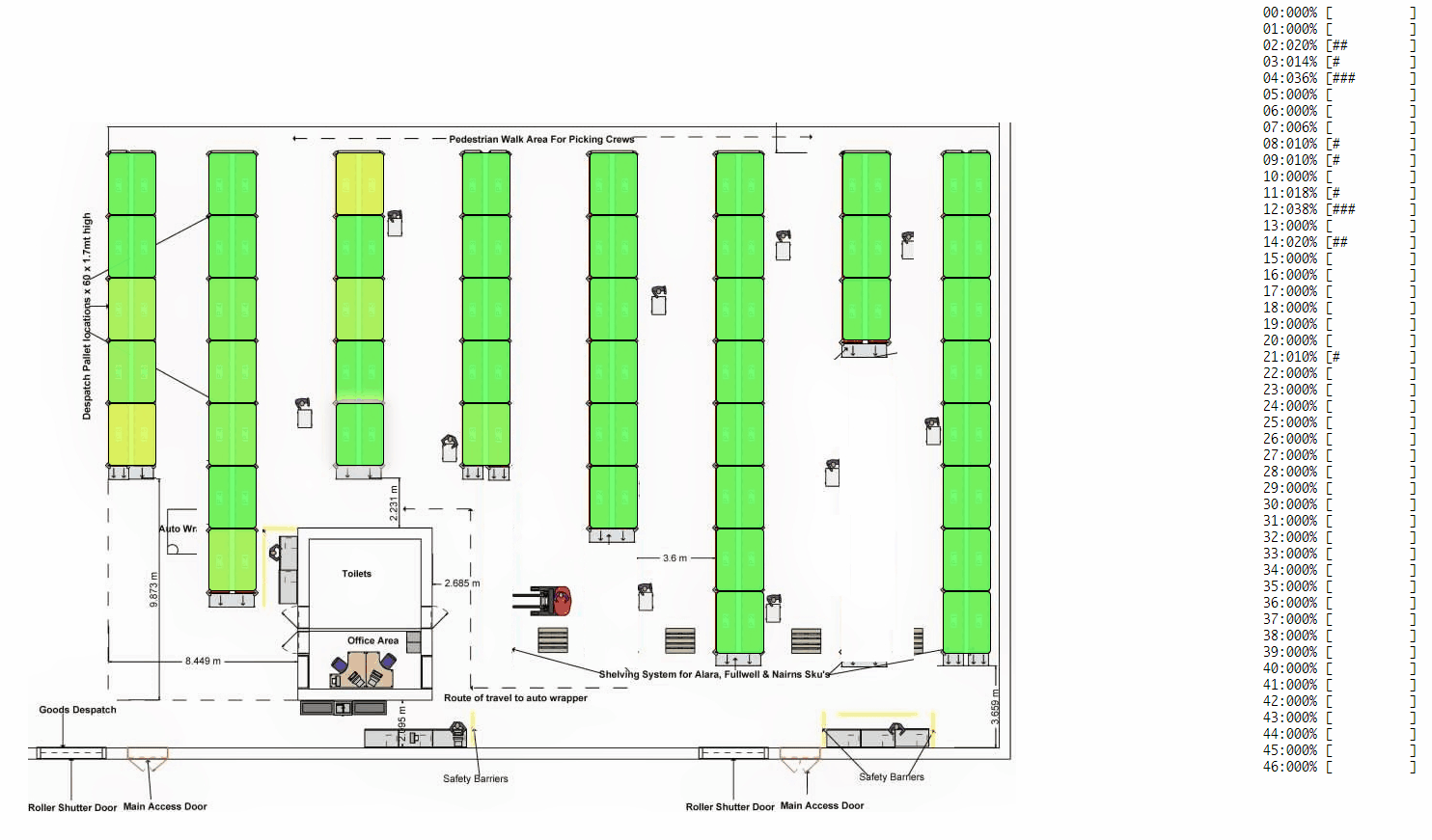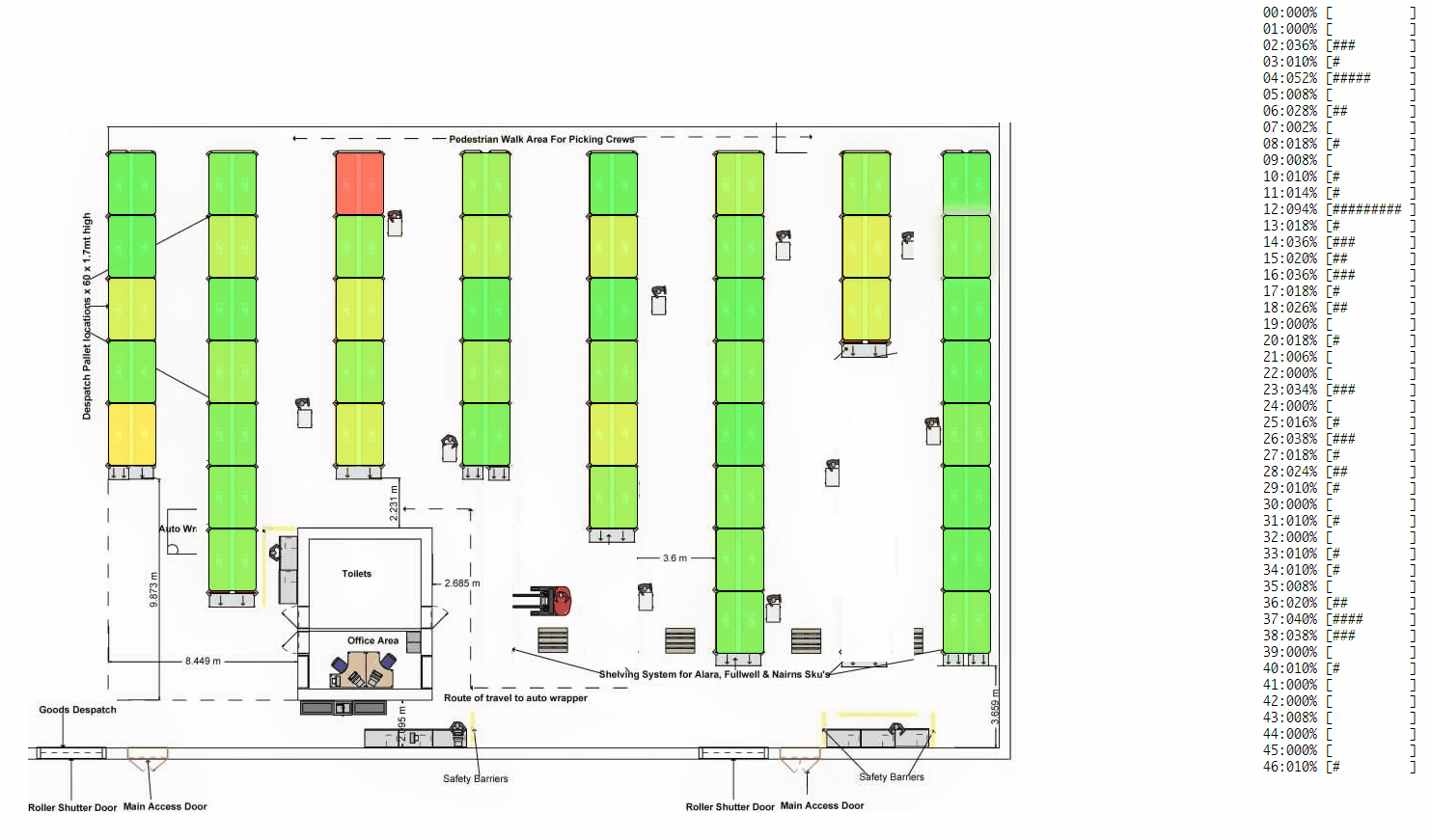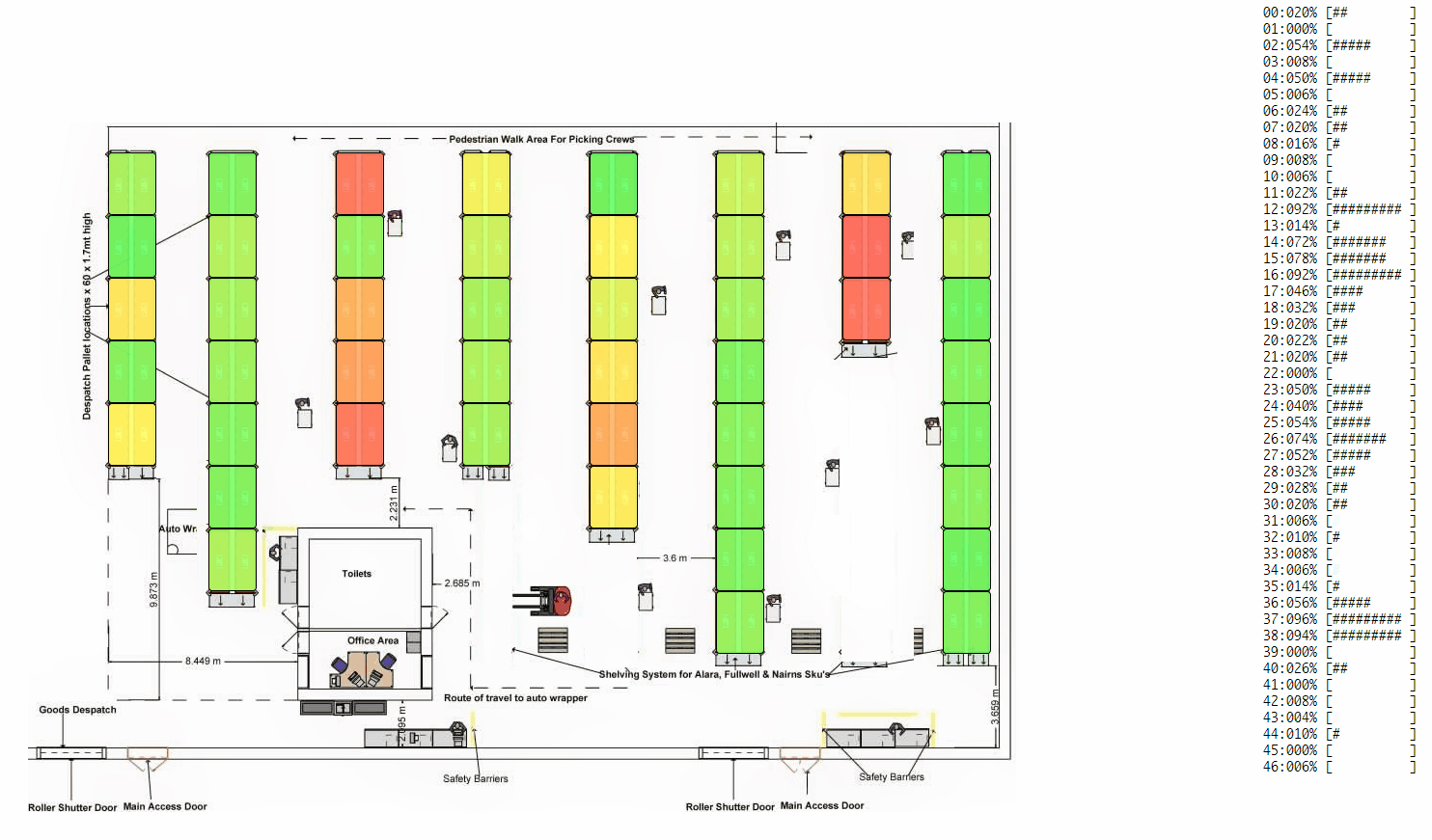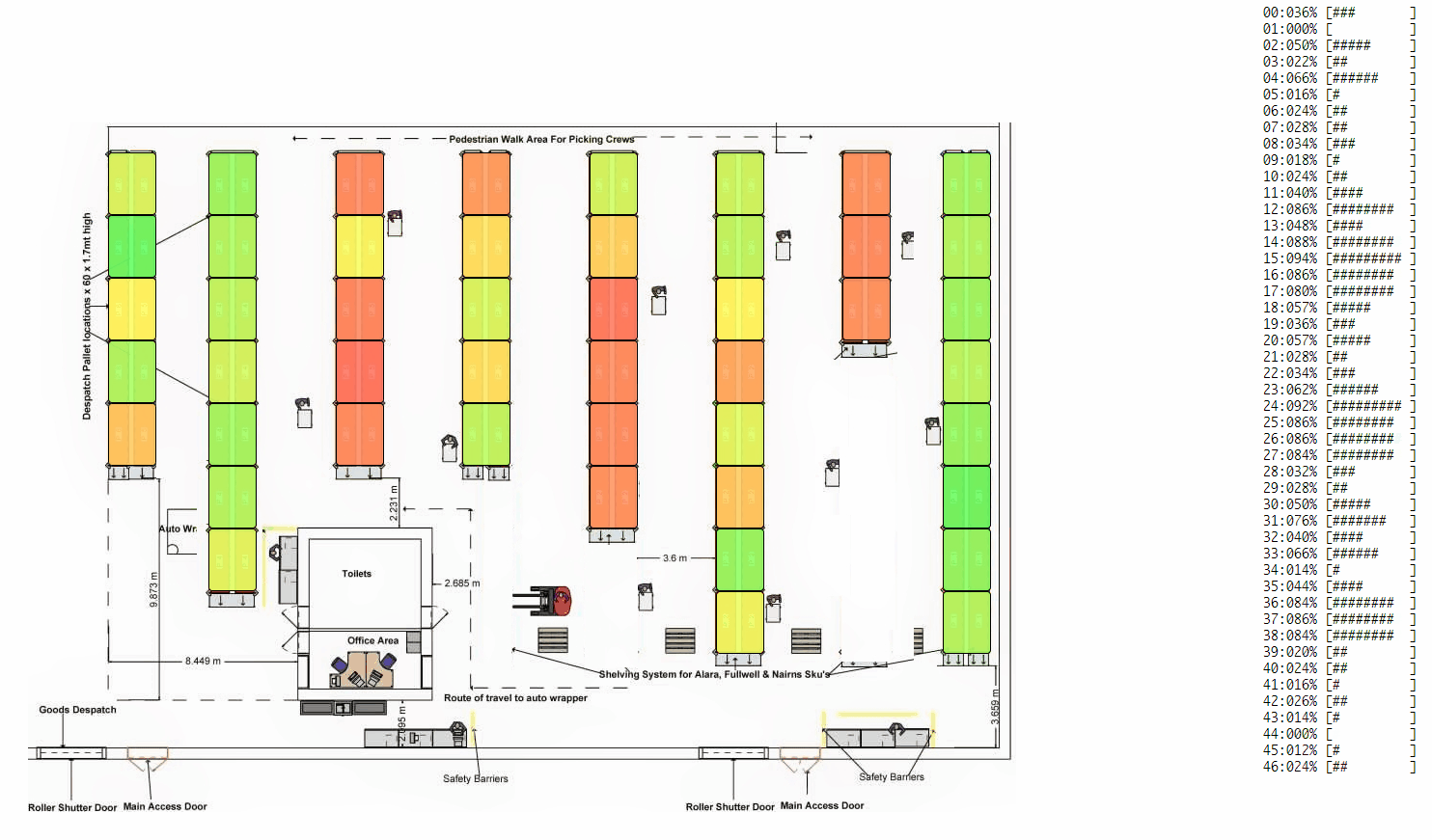
- For the use-case of producer-consumer (the most generic and common type of a warehouse), we can look at under/over utilization of resources, process bottlenecks, single point of failures (if any) and measure how well any process is load balanced. As a result, we can make necessary changes to the process and iteratively make it better.
- For a gossip/information-dissemination scenario, we can look at whether nodes are hearing the gossip, how many times they are hearing it and how effectively they are able to pass on the gossip. Further, you can speed-up the visualizations to look at a whole day's data in minutes. Continuous monitoring and viewing past-trend and old logs is natively supported
How we built it
- Gridy is language agnostic. Yes you read that right!
- Just put our cute little logs in your awesome program and you are done!
- We used Elixir for the back-end simulation. It is a concurrent functional language built on top of the Erlang battle-tested VM that is used to develop highly distributed and fault tolerant applications.
- We used actor model to create our topology and simulate the producer-consumer scenario
- We used node.js to read the logs, filter the useful ones and render it in a browser for visualizations using web sockets.
Challenges we ran into
Simulator
Developing the pipeline topology with the producer-consumer algorithm was challenging and fun. Writing actor-model to simulate the entire back-end was a great learning experience
Visualizer
Dividing work across the 3 of us to write the back-end and front-end. Real-time rendering on browsers needed us to use websockets. Handling real-time log processing was interesting
Accomplishments that we're proud of
Developed a generic distributed systems visualizer was an achievement. To add your own grid (map of a warehouse or any topology of your system that needs visualization), you just need to
- Add two lines in your existing code (for logging)
- provide us with your topology/map (in html)
If you want to use our simulator to experiment with your topology, you just need to
- add your topology or use one of the ones we support ( 2D, full, line, etc)
- add your business logic of each node like its capacity, what process it does, how is its current size is defined, how much delay you want to simulate between node conversations etc.
What we learned
- Writing functional, concurrent, distributed apps
- Parsing huge amount of data and using websockets
- Teamwork and friendship. JK lol.
What's next for Gridy
- Better visualizations
- Better per-node information visuals
- Maintain history of nodes and visualize it using pretty charts
- Machine Learning for future usage predictions
- Making things more modular on our side so as to make this framework plug and play
Built With
- css
- elixir
- erlang
- html5
- javascript
- node.js
- websockets



Log in or sign up for Devpost to join the conversation.