-
-
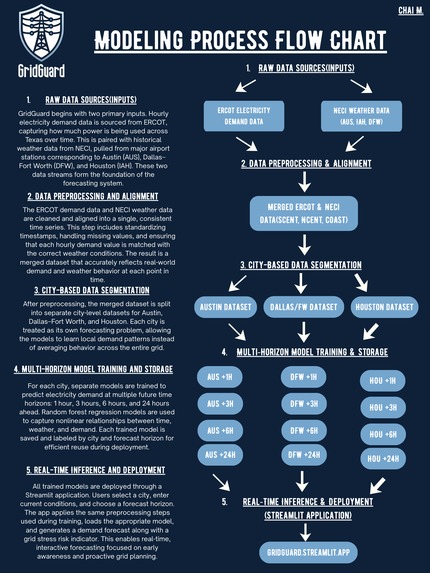
Flowchart
Inspiration
In February of 2021, Texas experienced one of the largest power blackouts in U.S. history. A severe winter storm caused massive demand spikes and power plant failures, leaving more than 4.5 million people without electricity, with outages lasting for days in some communities.
Living in Texas, this was something I experienced firsthand. I lost power in freezing temperatures, and in that moment it became clear how fragile everyday life can be without electricity. Electricity is not just a convenience. It is what keeps people safe, connected, and able to get through emergencies.
That experience stuck with me and led to a simple question. What if grid operators could anticipate stress coming before it became a crisis?
What it does
This project is an electricity demand forecasting and risk assessment system focused on improving grid reliability and resilience during periods of high stress.
It predicts short term electricity demand from one hour up to twenty four hours ahead using historical grid demand, weather data, and time based patterns. Users can input real time conditions like current demand, temperature, city, and time, and instantly see a forecast along with an estimated grid stress risk.
I focused on three major Texas cities Austin, Houston, and Dallas because I chose them to represent some of the largest and most distinct electricity demand patterns in the state. Each city has different population sizes, climate behavior, and usage trends, which makes them useful for understanding how demand changes across regions rather than treating the grid as one average system.
The goal is not just prediction. It is awareness. When operators know a spike is coming hours in advance, they have time to act early instead of responding once demand is already too high.
How I built it
I built the system in Python using real ERCOT Texas electricity demand data from 2021 combined with historical weather data from NECI.
I used pandas extensively to load, clean, and restructure the raw datasets. This included aligning timestamps between demand and weather sources, filtering data by city, handling missing values, and creating consistent time series data that could actually be used for modeling. A significant amount of time went into data cleaning and validation before any ML happened.
I split the data by city and treated Austin, Houston, and Dallas as separate forecasting problems. This allowed each model to learn local demand behavior instead of averaging patterns across the entire state.
For each city, I engineered time based features such as hour of day, day of week, and seasonal indicators, along with weather features like temperature. NumPy was used heavily during this stage to manage numerical arrays and keep feature formatting consistent across training and inference.
I trained separate ML models for multiple forecast horizons ranging from 1 hour, 3 hours, 6 hours and 24 hours ahead. Using scikit learn, I primarily relied on random forest based regressors because they handled nonlinear relationships between demand, weather, and time features well and produced more stable predictions during high demand periods.
Matplotlib was used throughout development to visualize historical demand trends, daily and seasonal patterns, and extreme spikes. These visualizations helped guide feature engineering decisions and made it easier to debug cases where the models behaved unexpectedly.
Once trained, I saved each model using joblib so the app could load the correct model based on city and forecast horizon without retraining anything at runtime.
I then built a Streamlit app that connects user inputs directly to the trained models. The app applies the same preprocessing used during training, loads the appropriate model, and outputs a demand forecast along with an estimated grid stress risk in real time.
Challenges I ran into
One of the biggest challenges was working with real world data. Demand and weather data came from different sources with different timestamp formats, resolutions, and gaps. A lot of time went into aligning timestamps correctly and making sure features actually lined up instead of being slightly offset and silently breaking the models.
Extreme events, especially February 2021, were another major challenge. Demand behavior during that period looks nothing like a normal day. Models trained on limited data can easily overfit or behave unpredictably during these conditions, especially for longer forecast horizons.
Managing multiple cities and multiple forecast windows added complexity quickly. Instead of one model, I was training and maintaining many models across different cities and time horizons. Keeping preprocessing, feature engineering, and model organization consistent across all of them required a lot of iteration and debugging.
There was also a tradeoff between accuracy and stability. Some models performed well on average but produced unrealistic jumps during high stress periods. Since the goal was early awareness rather than perfect predictions, I had to prioritize reasonable and stable behavior over squeezing out small accuracy gains.
Deployment brought its own problems. Large trained model files exceeded standard GitHub limits, which forced me to learn Git LFS and troubleshoot repeated push failures. I also had to ensure preprocessing during deployment matched training exactly, since even small inconsistencies caused runtime errors.
Accomplishments that I'm proud of
The main thing I’m proud of is that the project actually works end to end. I started with raw ERCOT demand data and ended with a live app where users can input conditions and get real forecasts and risk signals in real time. It’s not just a model sitting in a notebook.
I’m also proud of how I handled multiple cities and forecast horizons. Instead of building one generic model, I trained separate models for Austin, Houston, and Dallas, each predicting demand from 1 hour up to 24 hours ahead. Keeping all of those models organized and making sure the correct one runs based on user input took a lot of trial and error.
Working with real 2021 Texas grid data was another big accomplishment. The data wasn’t clean, demand patterns weren’t normal, and extreme events made modeling harder. Dealing with missing values, alignment issues, and unstable demand made the project feel much closer to a real infrastructure problem than a typical ML assignment.
I’m also glad I pushed the project all the way to deployment. Turning the models into a live Streamlit app made the system usable and interactive instead of just technical. Getting through version control issues, large model files, and deployment problems was frustrating, but it made the final result much more solid.
What I learned
This project taught me that most of the difficulty is not in the model itself. The hardest parts were understanding the data, cleaning it, aligning timestamps, and making sure inputs actually meant what I thought they meant.
I learned that accuracy alone is not enough. Models that look good on paper can still behave poorly during extreme conditions, which matters a lot when dealing with real infrastructure systems.
Working with multiple cities showed me how different regional demand patterns can be even within the same grid. Treating them separately led to better insights and more reliable forecasts.
I also learned a lot about deployment and engineering. Dealing with large files, dependency management, and keeping training and inference consistent showed me what it actually takes to move a project from local code to something that runs online.
What's next for GridGuard
Looking ahead, I want to train the models on multiple years of data instead of just 2021. That would help the system generalize better and handle unusual conditions more reliably.
I also want to expand beyond Austin, Houston, and Dallas to include more regions and get a broader view of grid behavior across different climates and usage patterns.
Another area to improve is the grid stress risk calculation. With access to more system level data like reserve margins or constraints, that signal could become more realistic and informative.
There is also room to improve the app itself by refining the interface and making the forecasts easier to interpret, and having it more visually appealing.
Built With
- ercot
- github
- joblib
- lfs
- matplotlib
- neci
- numpy
- pandas
- python
- scikit-learn



Log in or sign up for Devpost to join the conversation.