-
-
Project Demo
-
Project Demo
-
Project Demo
-
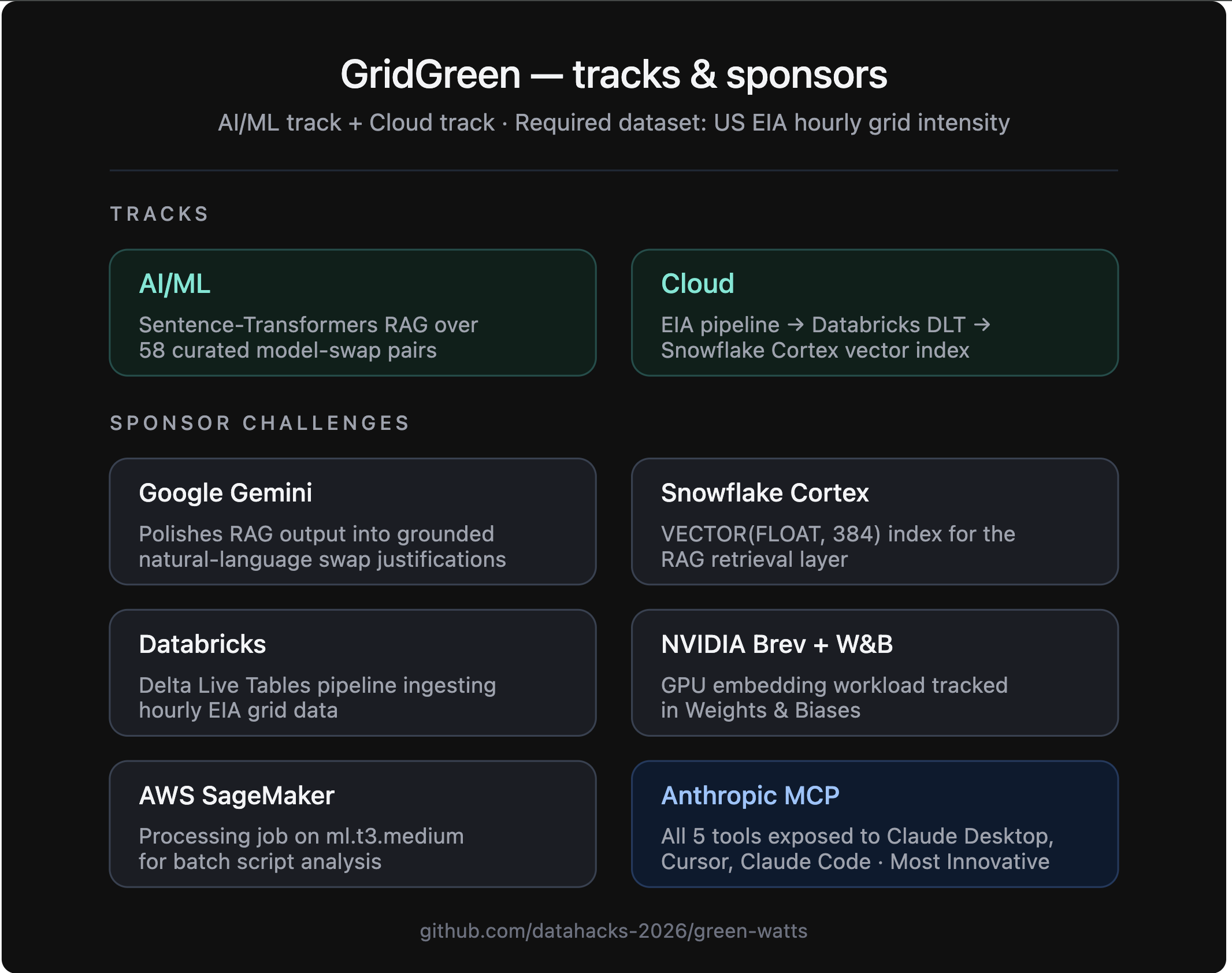
Tracks Information
-
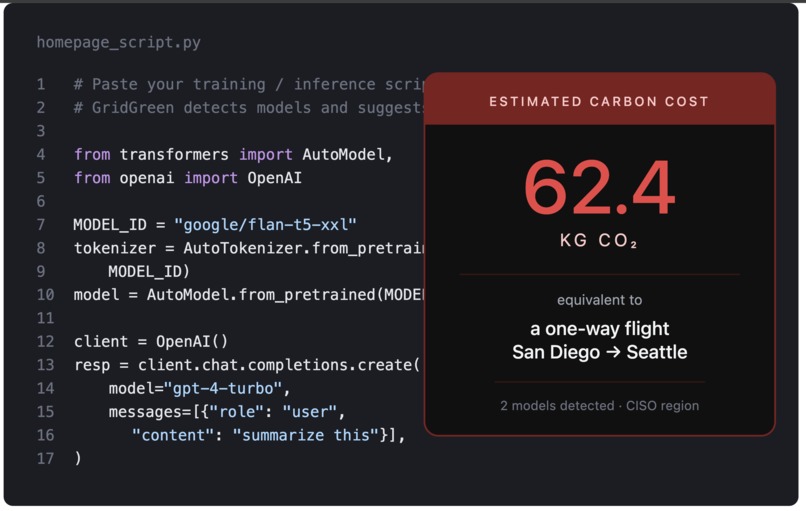
Example
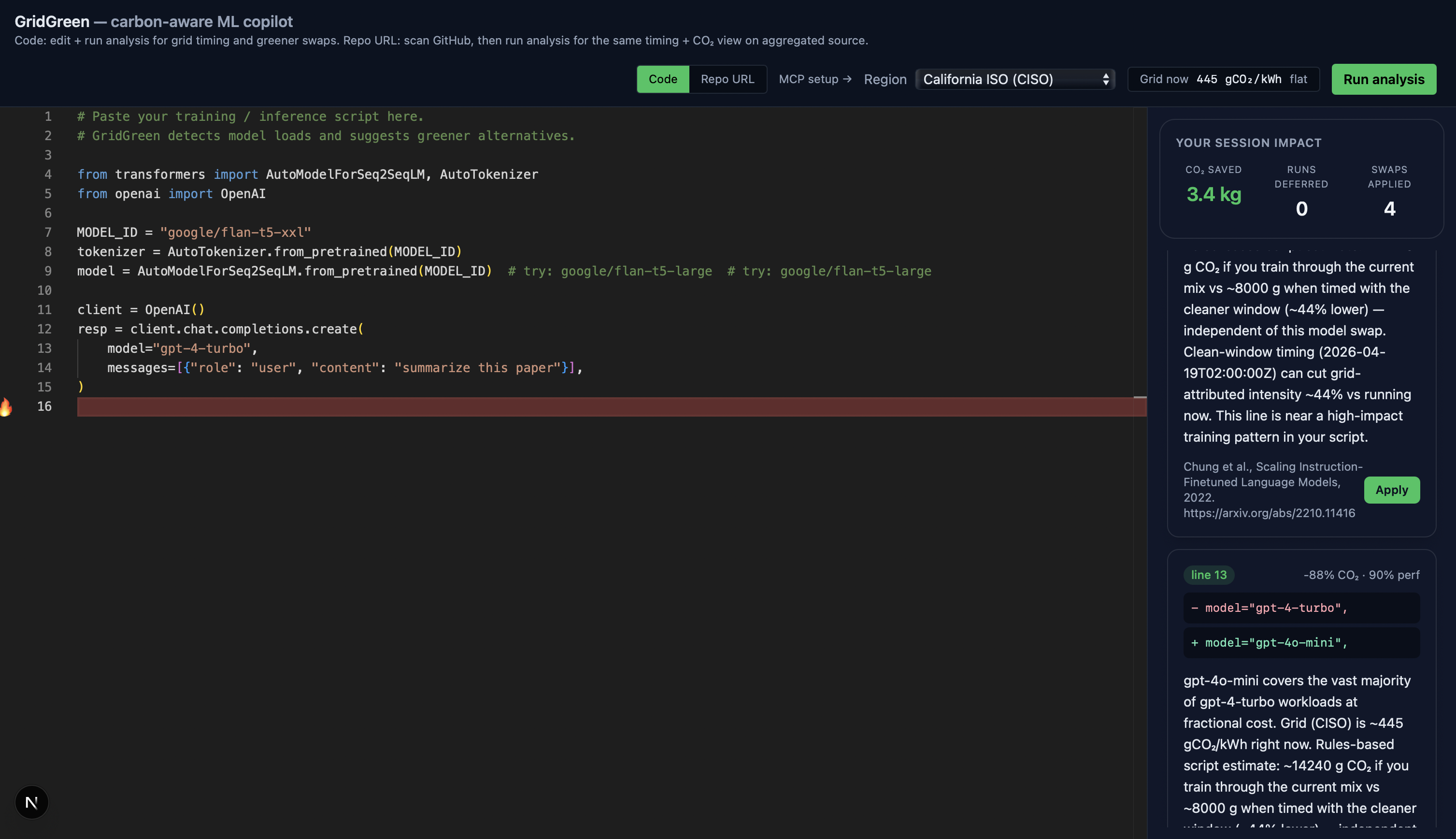
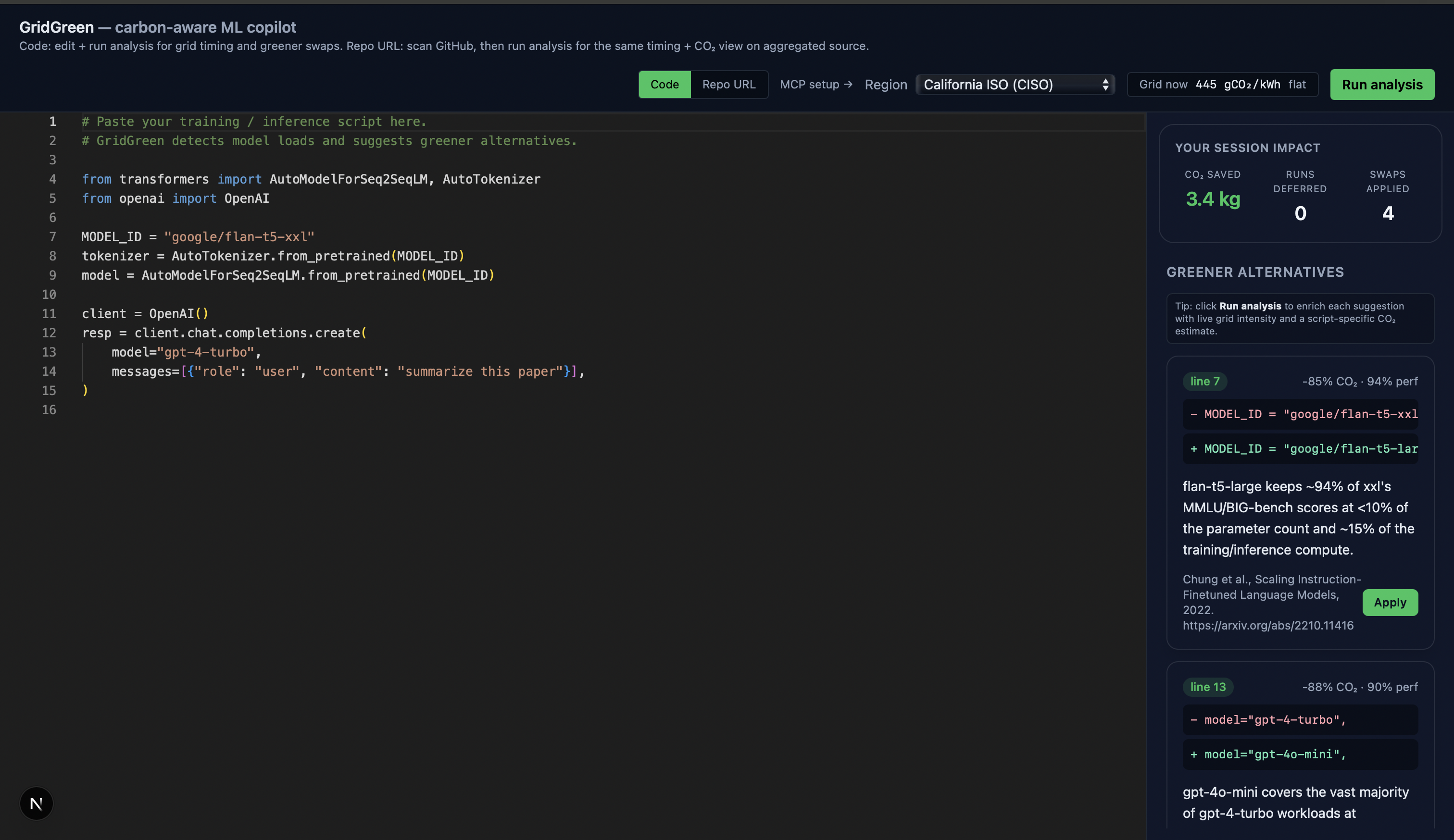
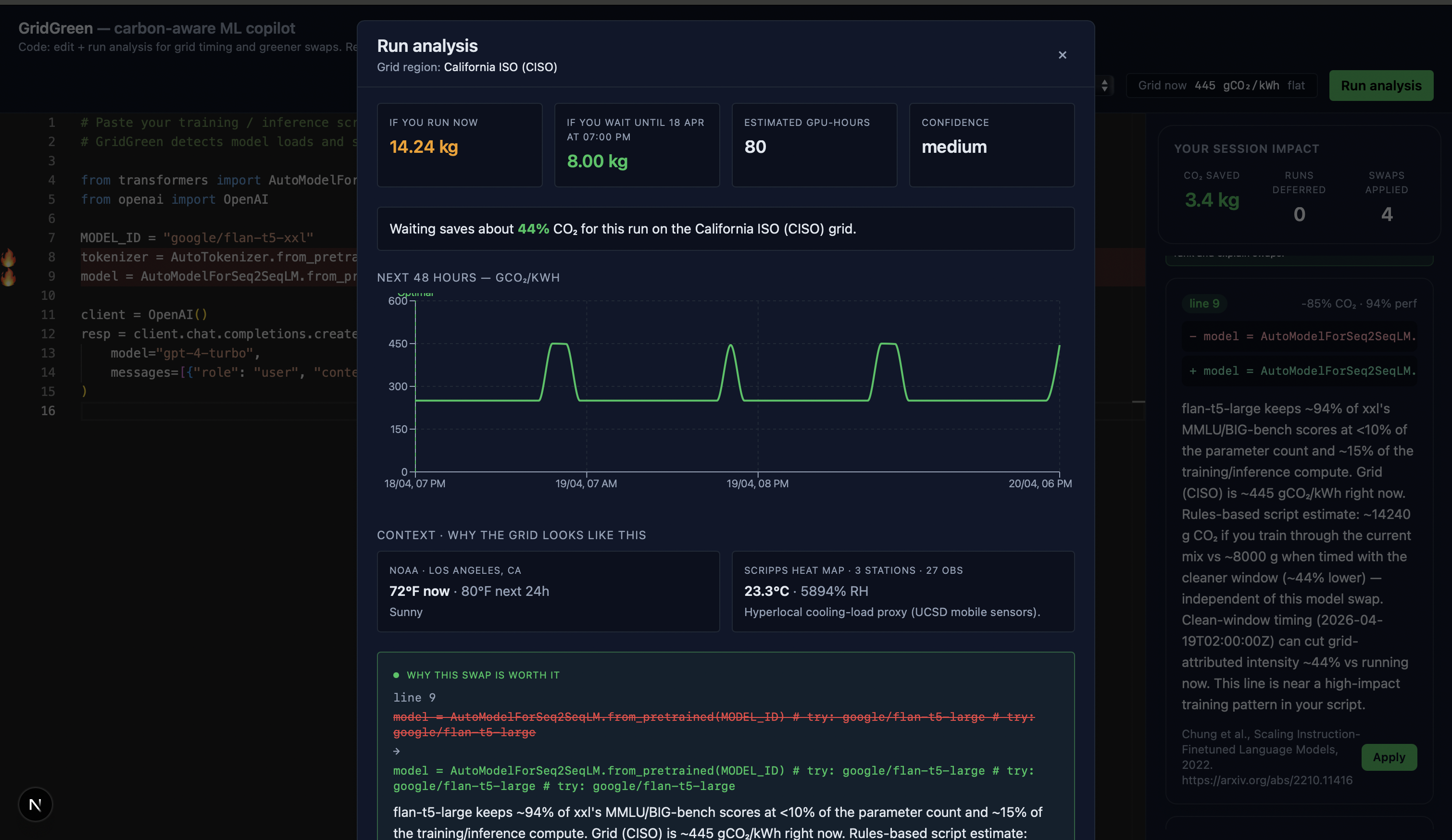
Inspiration
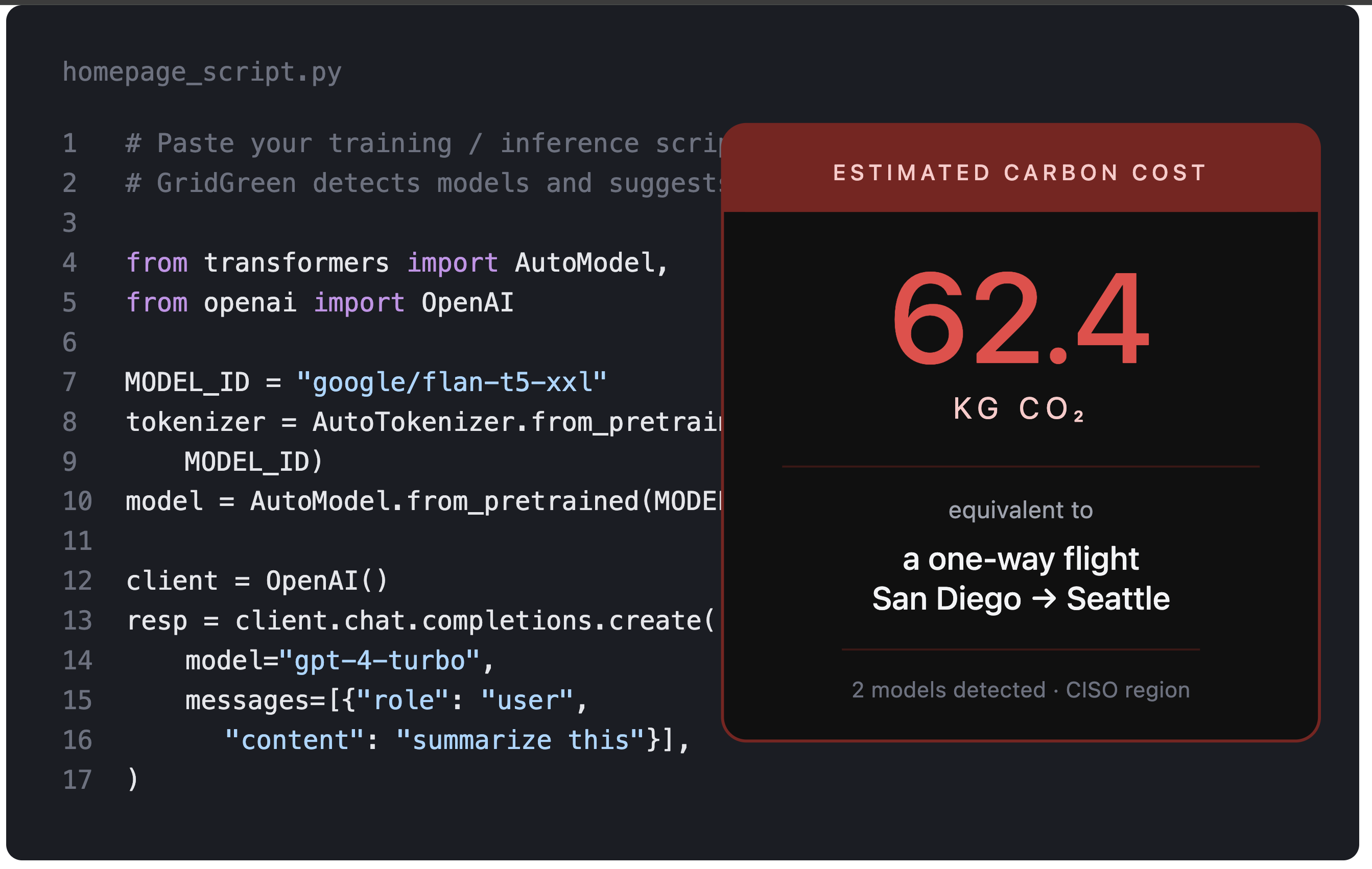
Every model.fit() is a climate decision but ML engineers have no idea.
A single fine-tune of a mid-sized LLM on AWS can emit more CO₂ than a round-trip flight from San Diego to New York. And the same job run six hours later, on a cleaner grid, can cut that in half. Yet nobody sees this until it's already on the electricity bill.
We wanted a tool that makes the climate cost of ML visible before you hit run, and suggests concrete fixes in the engineer's own editor.
What it does
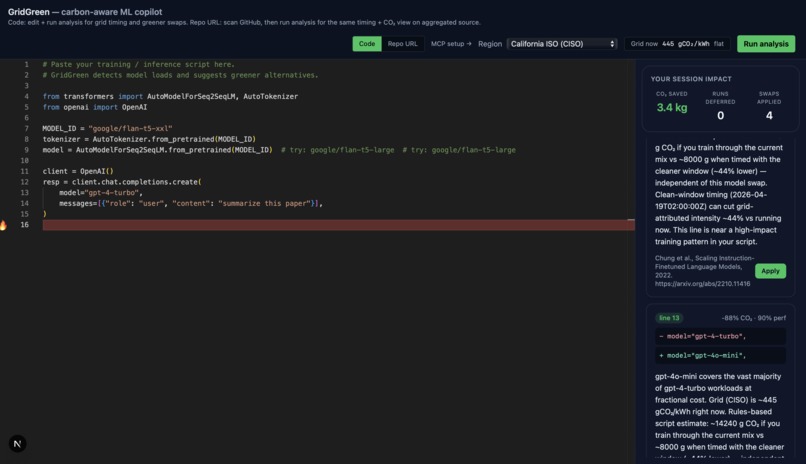
GridGreen is a carbon-aware copilot for ML engineers. Paste any training script and it gives you:
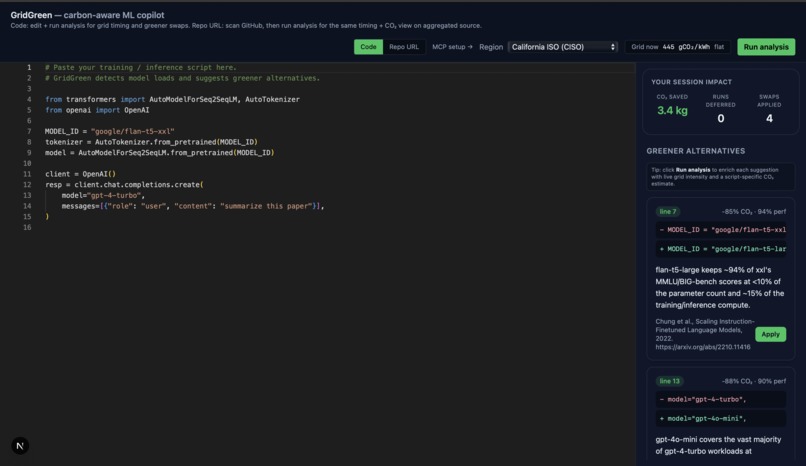
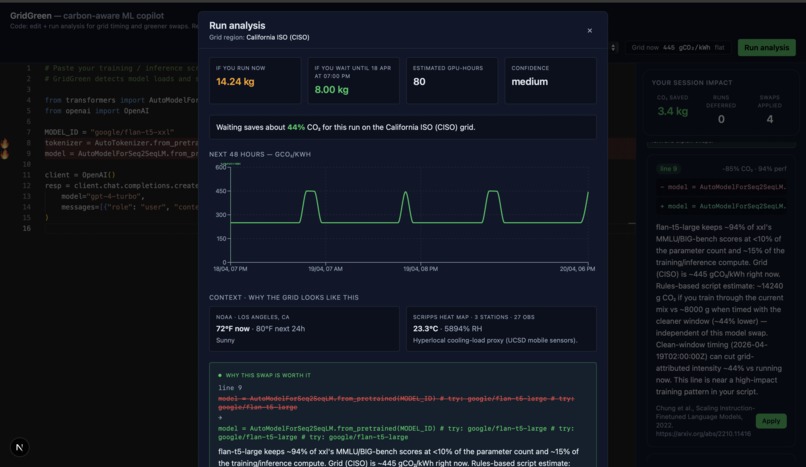
1. Carbon estimate — CO₂, GPU-hours, kWh for your exact workload, grounded in published scaling laws (Patterson 2022, Kaplan 2020, Strubell 2019) with stated limitations. 2. Greener model suggestions - RAG-backed swaps over 58 curated model pairs (flan-t5-xxl → flan-t5-large: −85% compute, 94% MMLU retained), with citations and Gemini-polished reasoning. 3. Grid-aware scheduling - Live 48-hour carbon-intensity forecast from the US EIA. Tells you the cleanest window to run in the next two days. 4. Session scorecard - Tracks cumulative CO₂ you've saved by accepting suggestions and deferring runs. 5. MCP agent mode - Same tools exposed via the Model Context Protocol, so Claude Desktop, Cursor, and Claude Code can call GridGreen directly from inside your agentic workflow.
How we built it
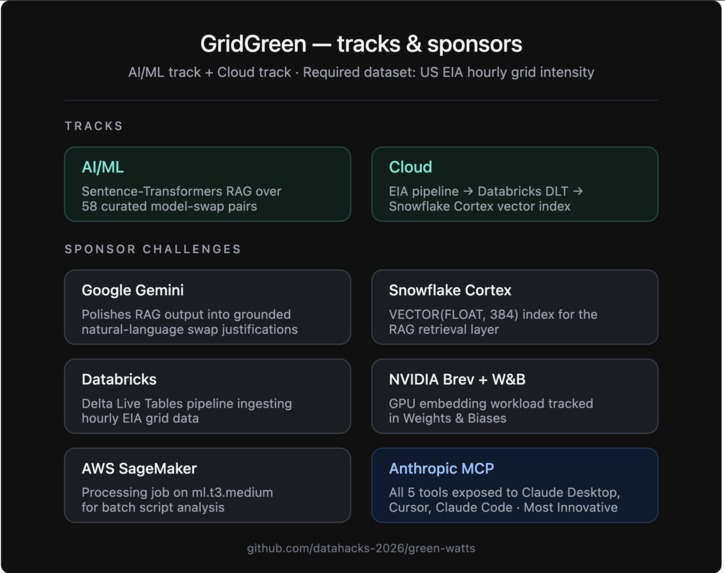
Dataset (required): US Energy Information Administration hourly grid data the official DataHacks 2026 Non-Scripps Energy dataset for 5 balancing authorities (CISO, ERCO, PJM, MISO, NYIS). Ingested, cleaned, and stored in SQLite with a Prophet / seasonal-naive fallback forecaster on top.
Backend: FastAPI with 5 endpoints ( estimate_carbon , suggest_greener , check_grid , find_clean_window , scorecard ) plus a diagnostics route. Carbon estimation uses an AST + regex detector to find models, training loops, batch sizes, and practices (AMP, FSDP, gradient checkpointing, quantization), then applies FLOPs-to-energy scaling laws.
Frontend: Next.js 15 + Monaco editor so engineers can paste code in their native environment. Tailwind + Recharts + Framer Motion for the analysis panel and 48-hour forecast.
RAG: Sentence-Transformers (MiniLM) with a TF-IDF fallback over our curated corpus of 58 model-swap pairs. Swaps cite published benchmark comparisons (MMLU, BIG-bench, Open LLM Leaderboard).
MCP server: Full feature parity with the HTTP API, including Gemini-polished reasoning. Register it in claude_desktop_config.json and Claude can estimate carbon and suggest swaps mid-conversation.
Cloud integrations: Snowflake Cortex (VECTOR(FLOAT, 384) index), Databricks DLT (EIA pipeline with local fallback), AWS SageMaker Processing, NVIDIA Brev (GPU embedding workload + W&B logging), Google Gemini (NL reasoning polish).
Evaluation
We built a self-evaluation harness ( evaluation/ ) that runs 12 workloads across 4 scenarios:
| Metric | Value |
|---|---|
| Success rate | 100% (12/12 workloads) |
| Mean analysis latency | <20ms |
| Suggestion coverage | 66.7% of workloads get ≥1 swap |
| Model-swap CO₂ reduction (LLMs) | 54.9% |
| Model-swap CO₂ reduction (Vision/Audio) | 57.1% |
| Avg compute reduction per suggestion | 77.6% |
Challenges we ran into
• Grounded carbon numbers vs. hand-wavy ones. Early drafts threw out scary CO₂ numbers without citations. We scrapped that and made every response include a methodology block with paper citations and explicit limitations. • RAG on a tiny corpus. 58 pairs is too small for dense retrieval alone, so we added TF-IDF as a fallback and it dramatically improved recall on rarer model families. • EIA API flakiness. Rate limits hit us mid-hackathon. We built a mock-mode fallback so the demo never breaks, and a diagnostics endpoint that verifies real data is flowing. • MCP + Next.js dev loops. Getting the MCP server, FastAPI, and Next.js to all hot-reload without stomping on each other took an afternoon of tooling.
What we learned
• Scaling-law papers are remarkably consistent on FLOPs-per-parameter the variance is all in hardware utilization. • The US grid is dirtier at 6 PM and cleanest around 2 AM in most regions, but CISO (California) is the opposite in summer. • MCP is shockingly easy to add once your HTTP API is clean we got tool parity in under 2 hours.
What's next
• Metered validation against CodeCarbon / RAPL / DCGM telemetry. • Dataset-size inference from code (currently static-only). • A GitHub Action that comments carbon cost on every PR that touches training code. • Multi-cloud region-shifting suggestions (run in us-west-2 instead of us-east-1 today).
Built With
- amazon-web-services
- claude
- databricks
- fastapi
- gemini
- hugging-face
- mcp
- meta-prophet
- next.js
- nvidia-brev
- python
- rag
- sentence-transformers
- snowflake
- sqlite
- typescript
- wandb

Log in or sign up for Devpost to join the conversation.