-
-
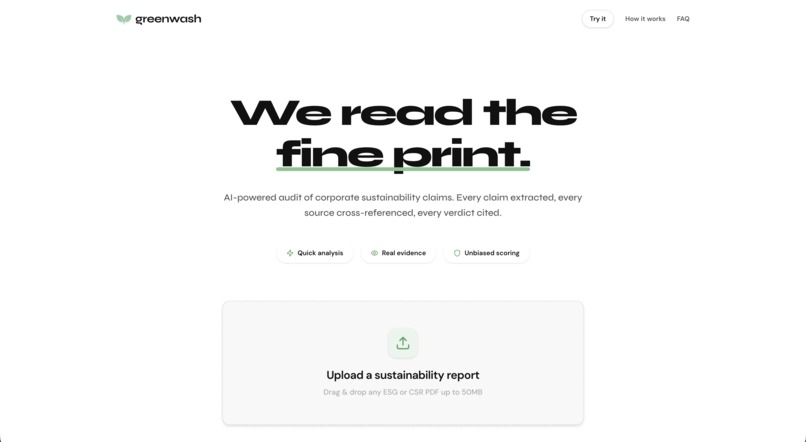
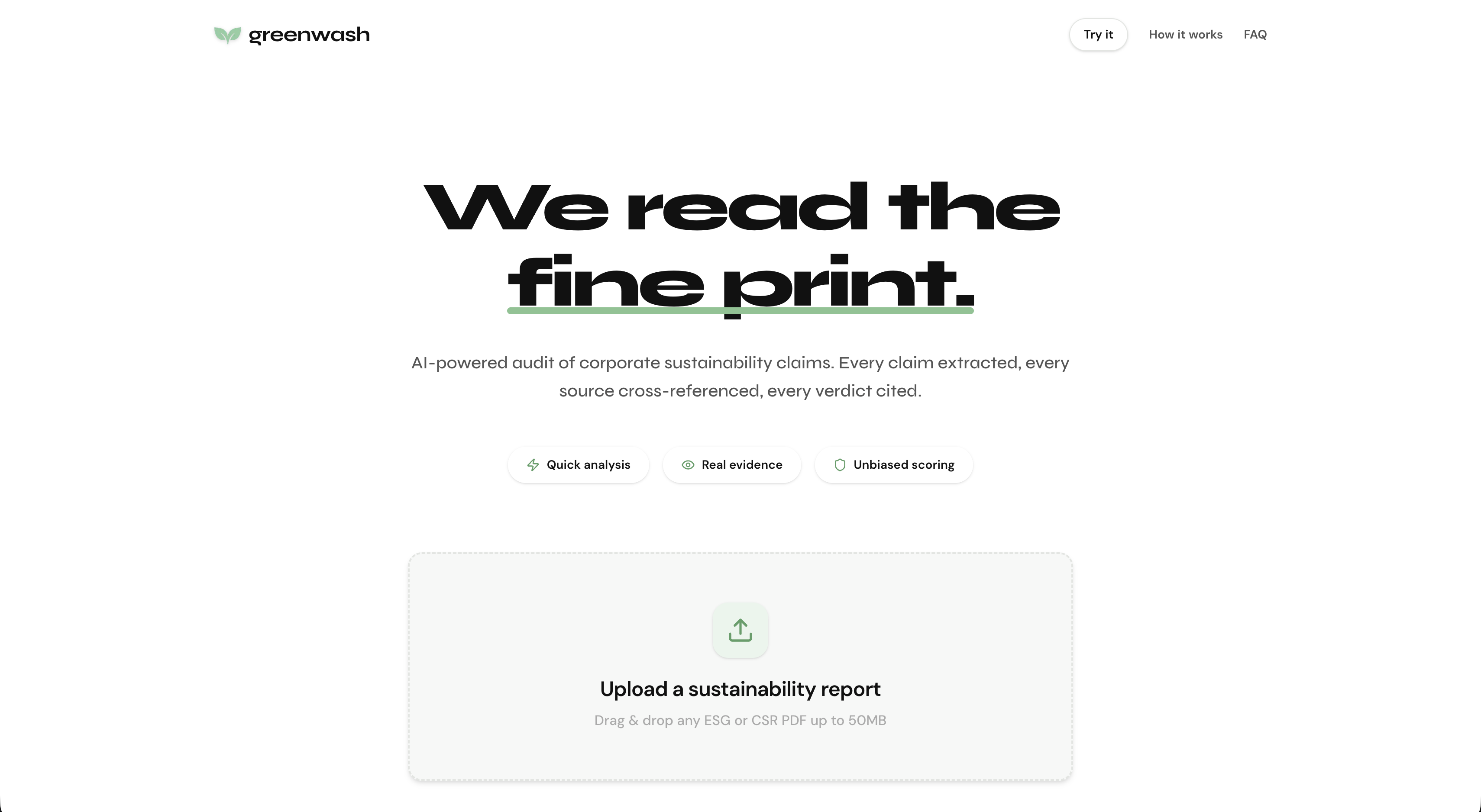
Main page
-

How it works
-
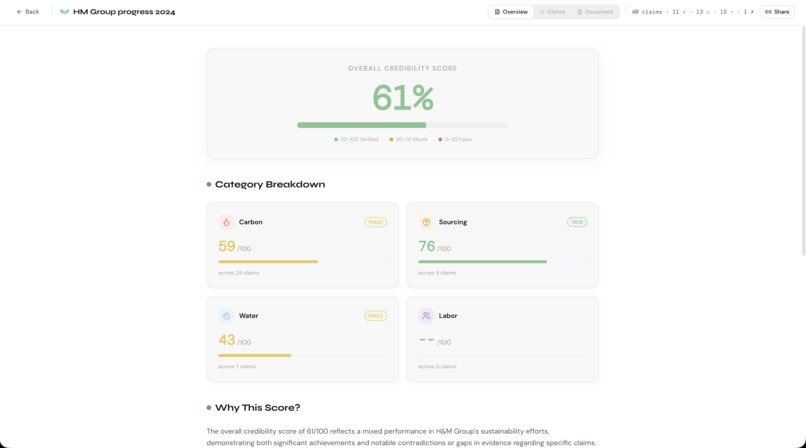
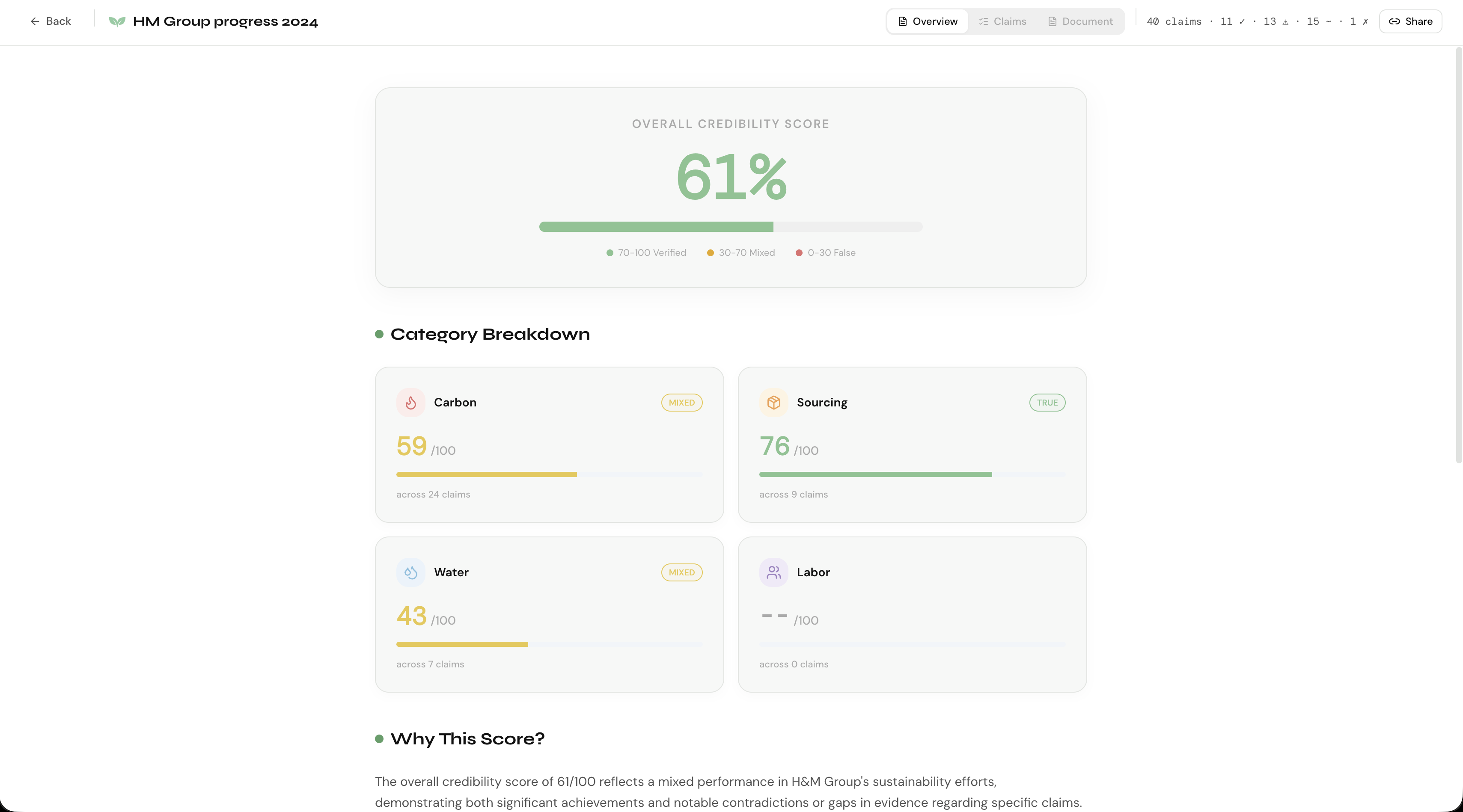
Overview section
-
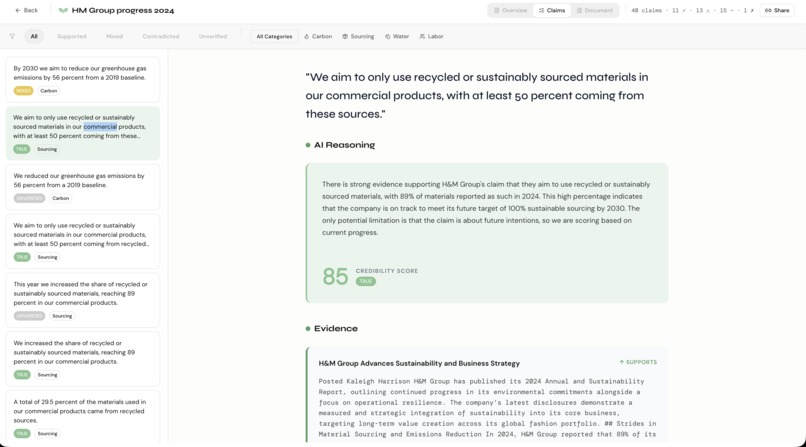
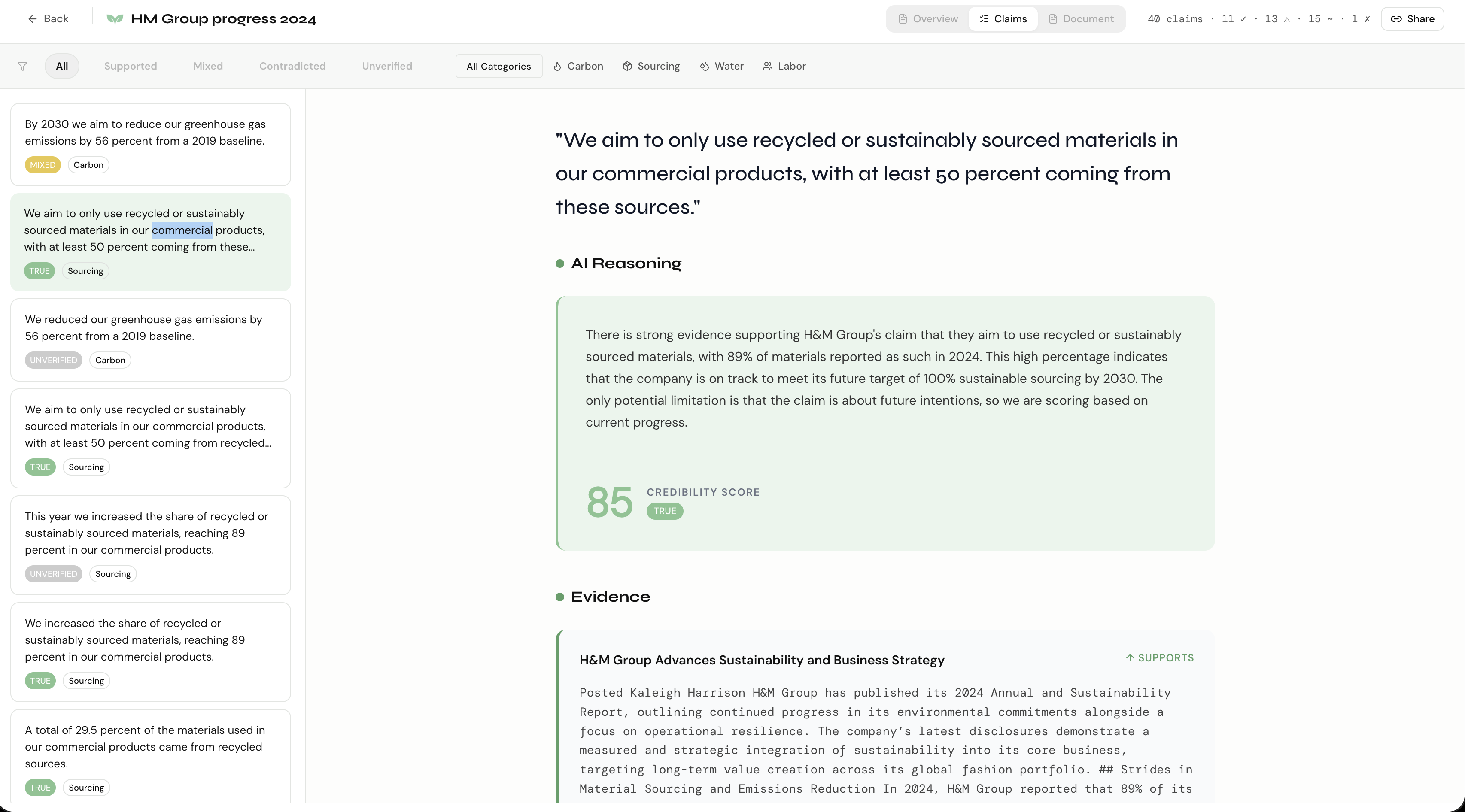
Claim section
-
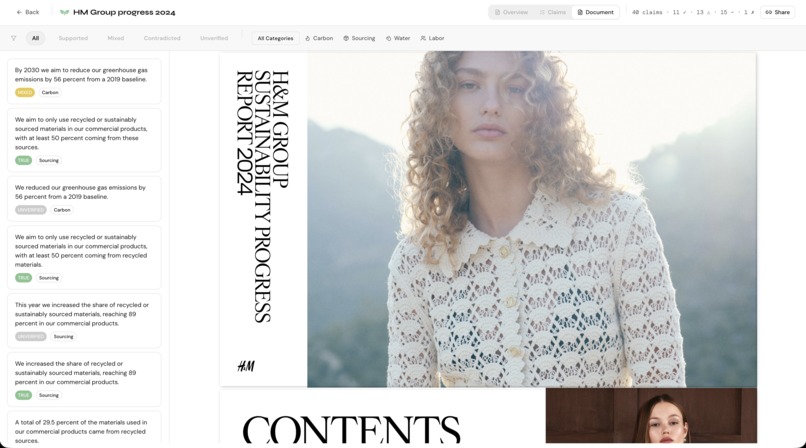
Document section
-

Logo


Inspiration
Corporate sustainability reports are the most unaudited documents in existence. Companies publish bold environmental claims — "carbon neutral by 2030," "100% responsibly sourced," "net zero operations" — with virtually no independent verification. The evidence to audit these claims exists publicly: government emissions registries, third-party audits, investigative journalism, NGO reports. Nobody had connected it with AI.
The regulatory tailwind made this urgent. The EU Green Claims Directive (effective 2026) imposes legal liability for unsubstantiated sustainability claims. Canada's Competition Act (amended 2024) explicitly targets greenwashing. Investors, journalists, and regulators need a verification layer that doesn't exist yet. I built it.
What It Does
GreenWash ingests any corporate ESG or sustainability report PDF and produces a claim-by-claim credibility audit in under 90 seconds. It:
- Extracts every explicit, verifiable sustainability claim from the document
- Cross-references each claim against real-world evidence — third-party news, government registries, NGO investigations, and industry audits
- Scores each claim on a 0–100 credibility scale with a verdict: True, Mixed, Contradicted, or Unverified
- Generates an overall credibility score and a detailed qualitative analysis
The result is a fully cited, evidence-backed audit report — the kind that would take a human analyst days to produce.
How I Built It
The pipeline runs in five sequential steps:
Step 1 — PDF Extraction
I use pdfjs-dist server-side to extract full text from uploaded PDFs, handling both digital and legacy document formats.
Step 2 — Claim Extraction GPT-4o-mini processes the text in parallel chunks using structured output JSON schema, extracting only explicit, verifiable claims and categorizing each into Carbon, Sourcing, Water, or Labor.
Step 3 — Evidence Gathering For each claim, Tavily advanced search fires two category-specific queries. Carbon claims search CDP scores and SBTi validation. Labor claims search human rights audits and violation records. A GPT relevancy filter ensures only sources about the specific company are inserted as evidence.
Step 4 — Credibility Scoring GPT evaluates each claim against its evidence, distinguishing between future targets and reported achievements, and outputs a confidence score with chain-of-thought reasoning.
Step 5 — Overall Analysis The overall credibility score is computed mathematically as a weighted average of all non-unverified claims. GPT generates the qualitative analysis narrative based on the computed score — not the other way around.
The frontend is built in Next.js with a real-time streaming processing screen, a two-panel claims dashboard, and a PDF viewer with a claims sidebar. All data is persisted in Supabase.
Challenges
The hardest problem was evidence quality. Early versions returned irrelevant sources — articles about Shell showing up for H&M claims, or the company's own sustainability report being used to validate itself. I solved this through:
- Category-aware search queries targeting the right databases per claim type
- Explicit self-domain exclusion in Tavily to block the company's own websites
- GPT relevancy filtering that asks whether a source actually concerns the specific company and claim topic
Balancing scoring accuracy was equally difficult. Too strict and everything scored FALSE. Too lenient and everything scored TRUE. The breakthrough was two key distinctions:
- Unverified ≠ False. Lack of direct confirmation means the pipeline couldn't find evidence — not that the claim is wrong. This distinction alone fixed a large class of incorrect FALSE verdicts.
- Tense detection. "I aim to reduce emissions by 56% by 2030" (future target) should be scored on whether the company is on track — not whether it has been achieved. "I reduced emissions by 41%" (reported achievement) should be scored strictly against independent confirmation.
What I Learned
- Evidence retrieval quality matters more than model quality. A smarter model on garbage evidence still produces garbage verdicts.
- Prompt engineering for scoring is more nuanced than prompt engineering for extraction. Getting a model to distinguish "not enough evidence" from "contradicted evidence" required very explicit rules.
- The regulatory context is the real moat. GreenWash isn't just a useful tool — it's infrastructure for a legal reality that's already arriving in the EU and Canada.
Built With
- credibility-scoring
- dm-sans
- entity-disambiguation
- framer-motion-backend:-next.js-api-routes-(serverless)-database-&-auth:-supabase-(postgresql
- framermotion
- google-oauth)-llm:-openai-gpt-4o-mini-(claim-extraction
- next.js
- openai-api
- overall-analysis)-search-&-evidence:-tavily-api-(advanced-web-search)-pdf-processing:-pdfjs-dist-(server-side-text-extraction)
- pdfjs-dist
- react-pdf-viewer-(client-side-rendering)-fonts:-syne
- relevancy-filtering
- storage
- supabase
- tailwind-css
- tailwindcss
- tavily-api
- typescript

Log in or sign up for Devpost to join the conversation.