Inspiration
Every day, schools generate thousands of printed pages — assignments, study guides, meeting agendas, administrative paperwork, classroom handouts, and a disproportionate share of that output is waste that has nothing to do with necessity, but wasteful formatting. Oversized text, highlighting, double-spaces, hard page breaks that leave most of a sheet blank, bulleted lists that dedicate an entire line to a single word, and wordy parahraphs. None of this is visible to the person who hits Print, the cost is deferred to a sheet of paper they never see being wasted.
We wanted to close that feedback loop at the one moment it actually matters: before the print job is sent, inside the editor where the decision is being made. GreenPages turns invisible formatting externalities into a quantified, actionable, one-click-fixable signal, directly into student and faculty's pre-existing workflows.
What it does
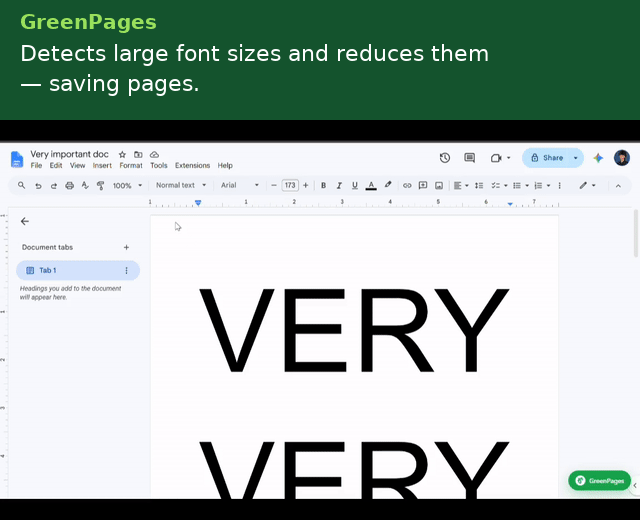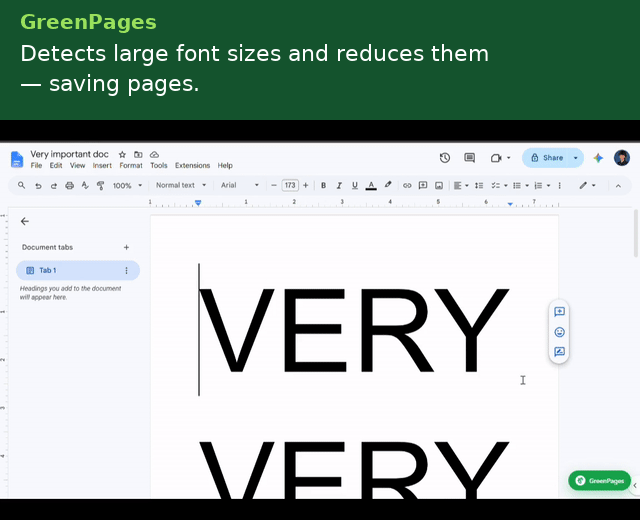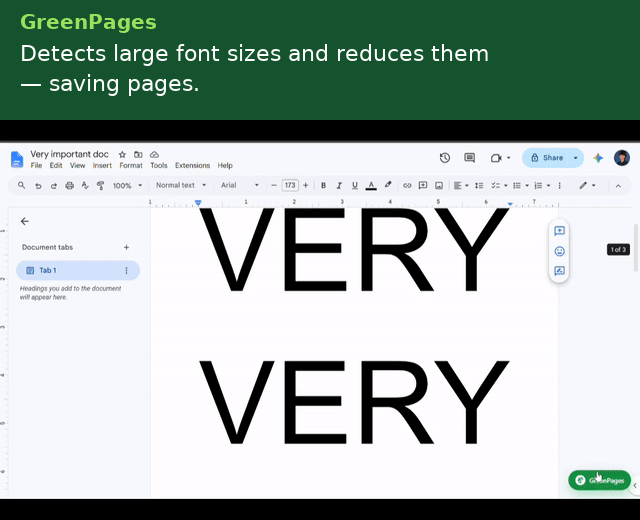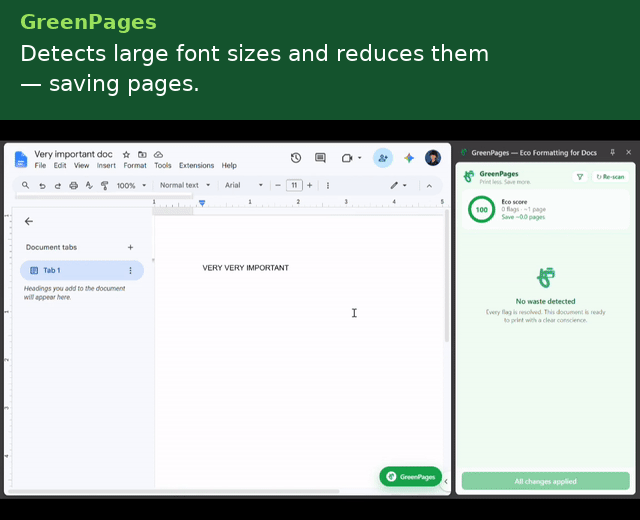
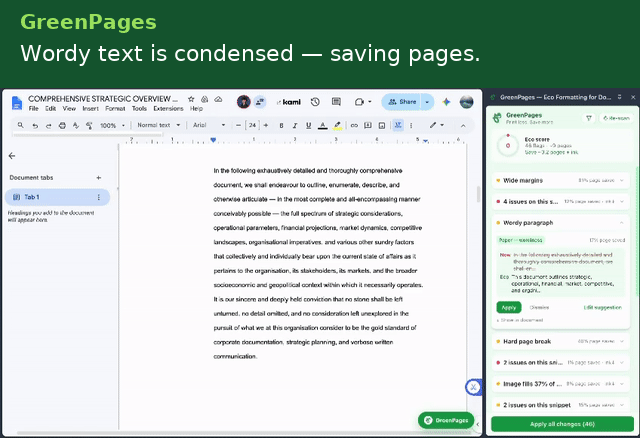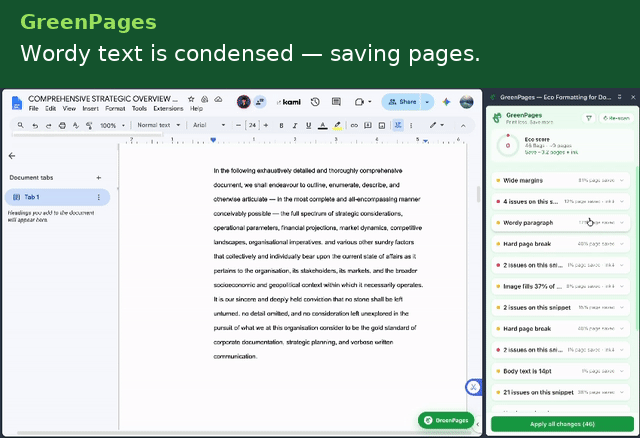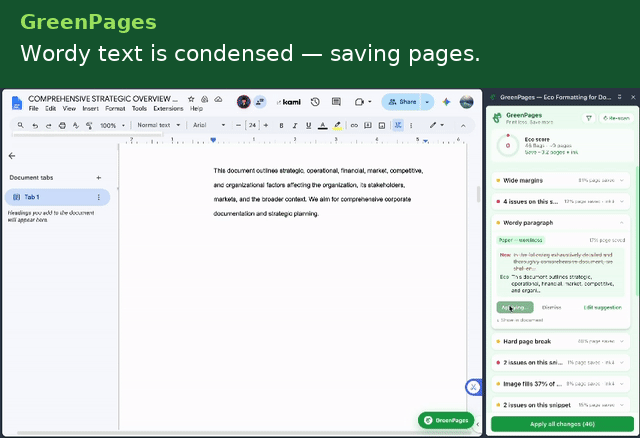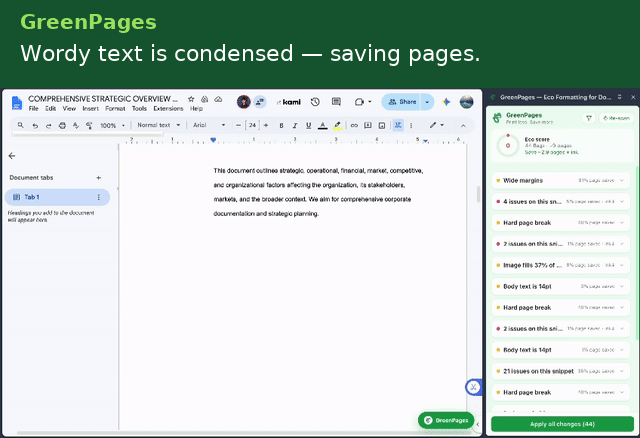
GreenPages is a Manifest V3 Chrome extension that continuously analyzes a Google Doc's structural model and surfaces paper/ink-saving recommendations as accept/reject cards in a side panel.
The analysis engine runs ten independent, deterministic detectors, powered by Gemini 2.5 Flash.
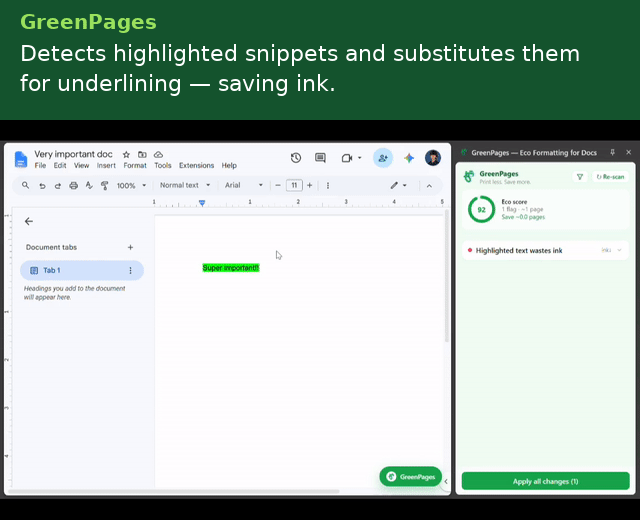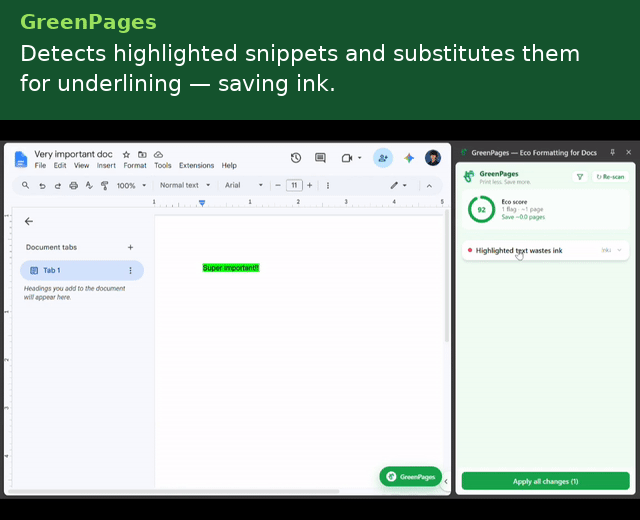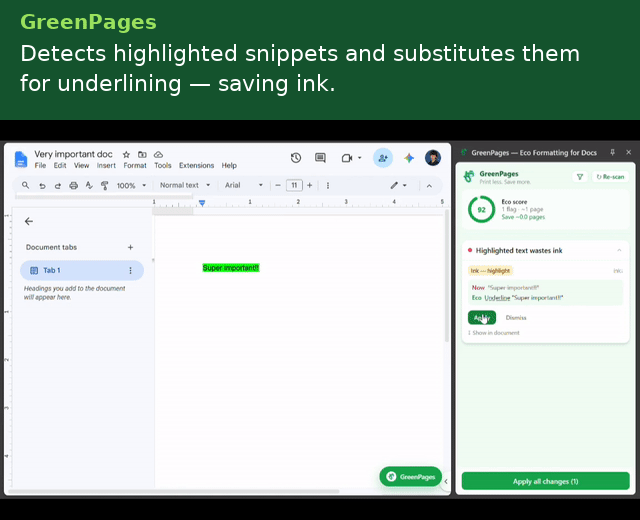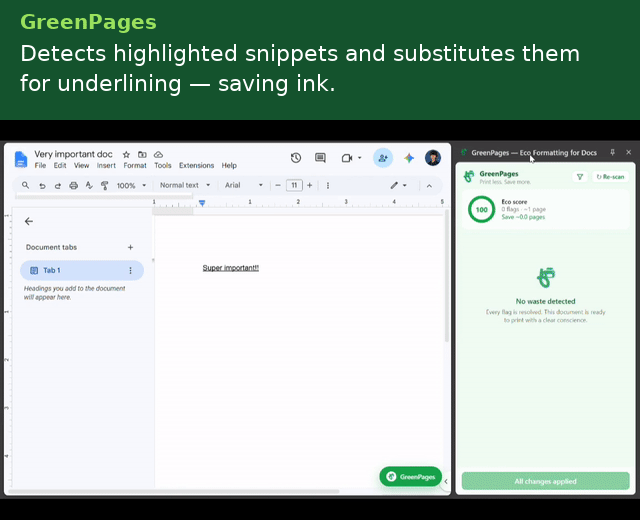
- Highlight → underline — background fills are ink-expensive; underline preserves emphasis at a fraction of the cost.
- Oversized body font — flags any run set more than 1pt above the document's own default and proposes a fontSize rollback.
- Blank-run collapsing — compresses runs of ≥2 empty paragraphs to a single separator line.
- Trailing blank-page elimination — detects when end-of-document blank lines spill onto an otherwise-empty extra sheet, and removes exactly enough to pull content back onto the prior page.
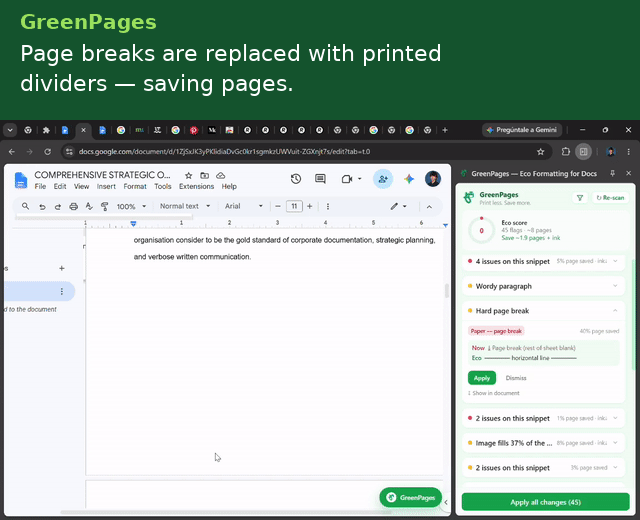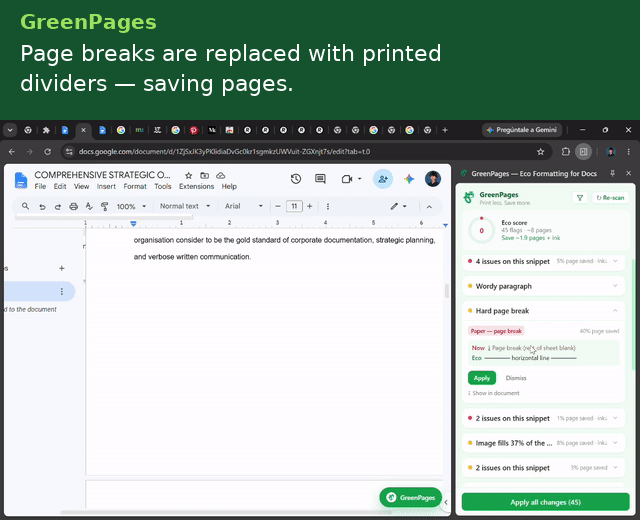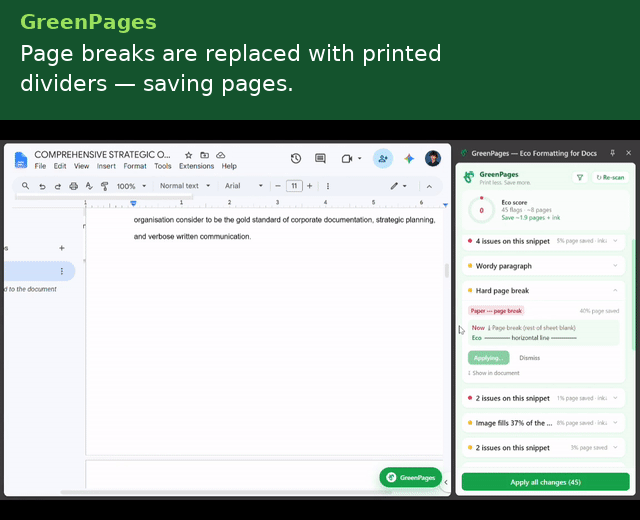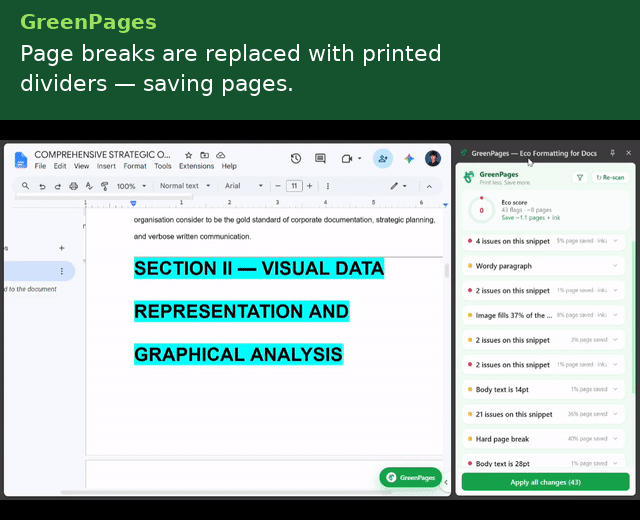
- Hard page break → horizontal rule — replaces a forced page break (which can strand the rest of a sheet blank) with a compact divider.
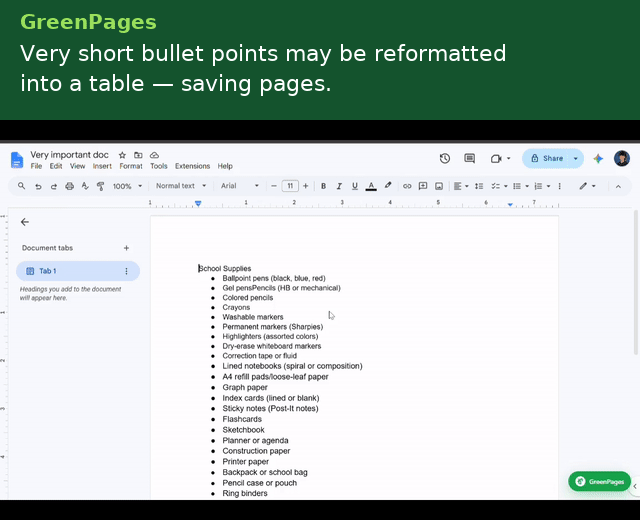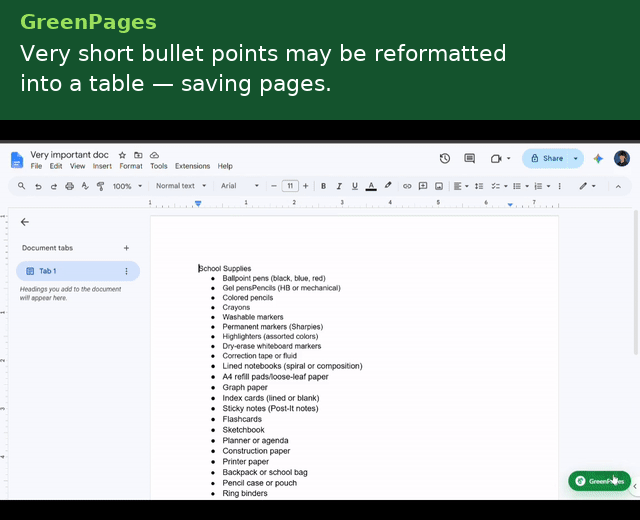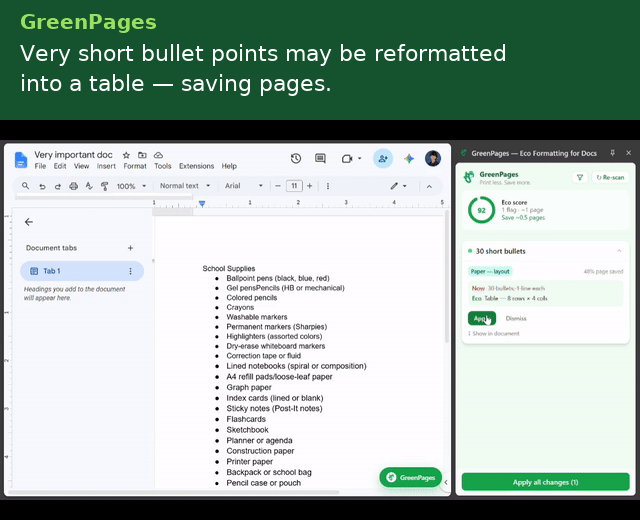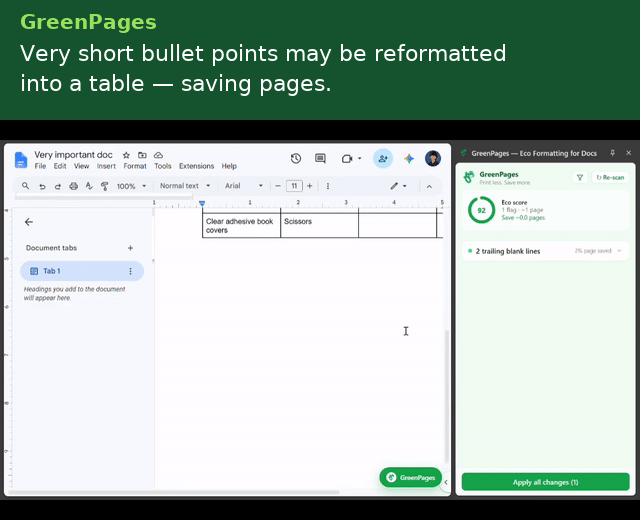
- Bullet sprawl → table — when ≥5 short bullets each consume a full line, proposes a column-balanced grid covering the same content in a fraction of the vertical space, saving paper.
- Verbose paragraph condensation — flags paragraphs that are long and compressible, with an editable, AI-assistable rewrite suggestion.
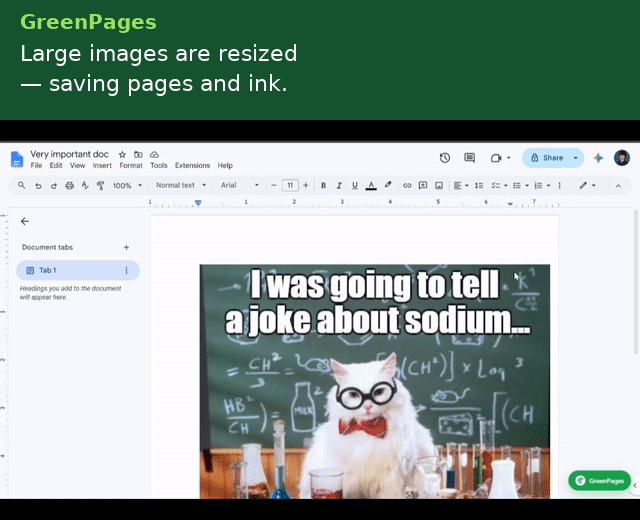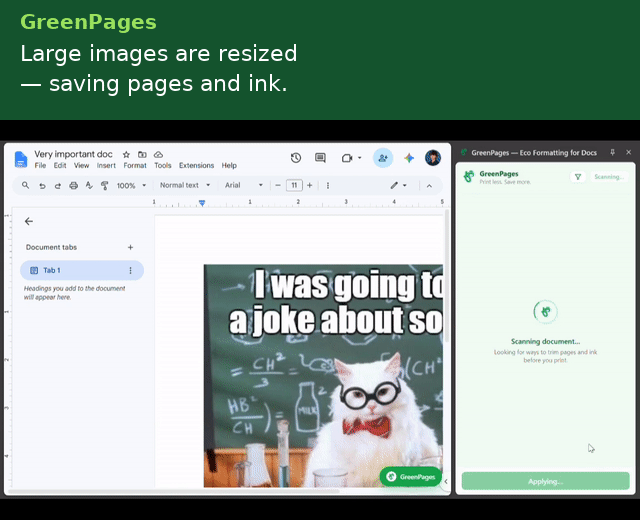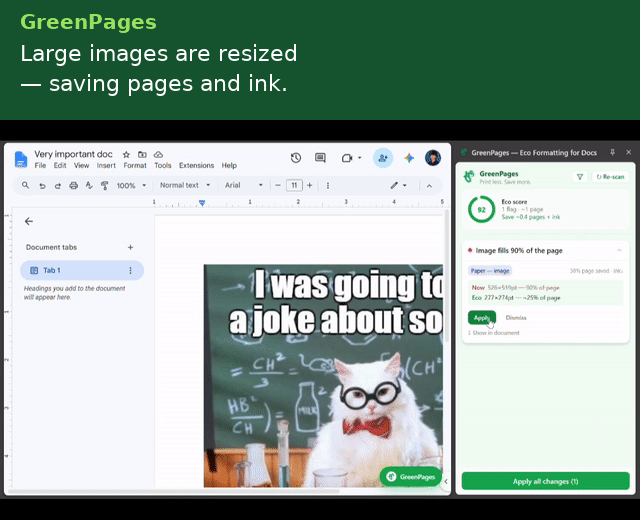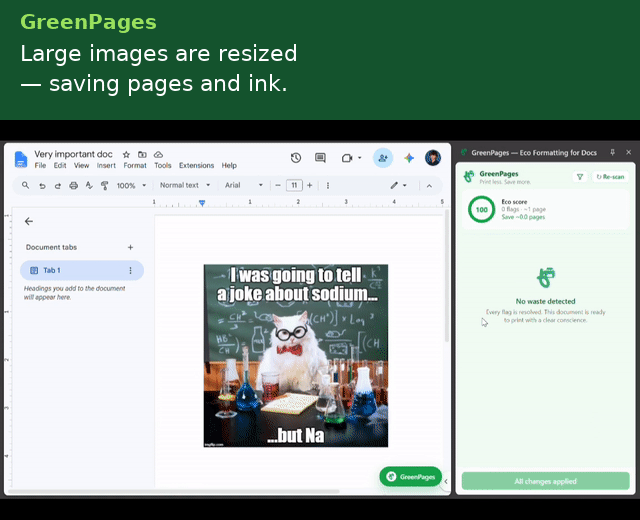
- Oversized image downscaling — flags inline images covering more than 25% of the printable page area and computes a corrective scale factor.
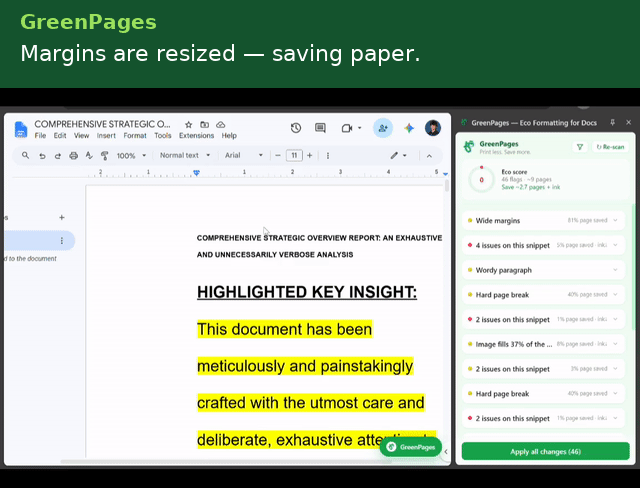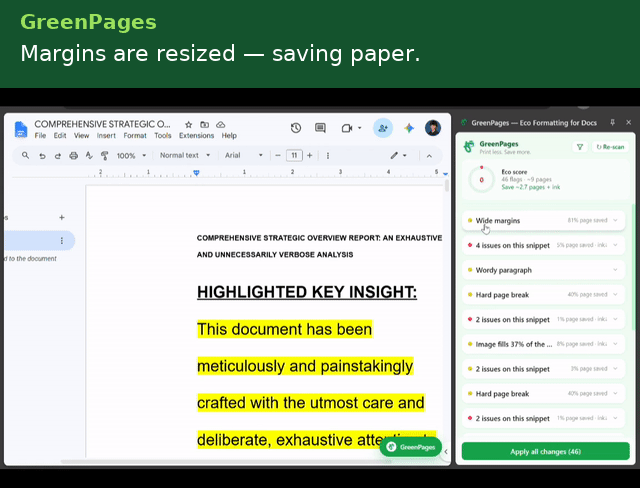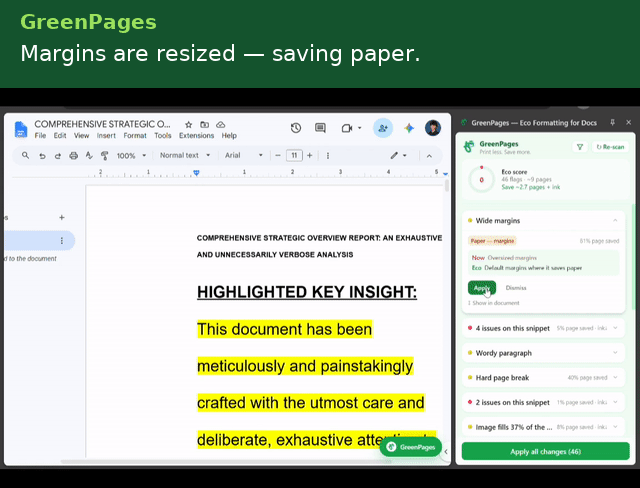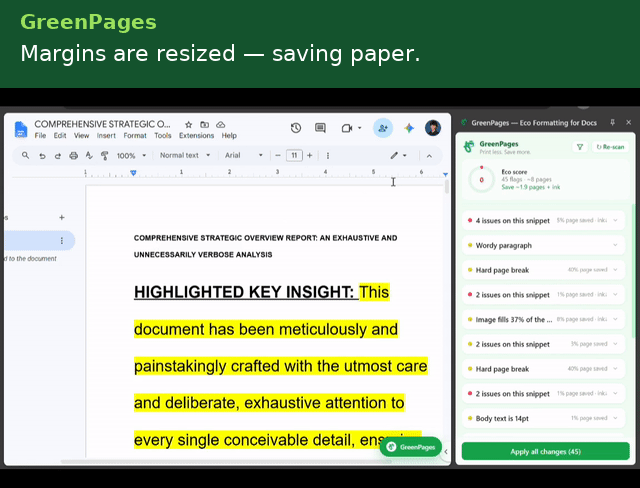
- Wide margin fix — resets only the margins that are larger than the Docs default.
- Wide paragraph indent fix — narrows per-paragraph indents that are forcing extra line wraps.
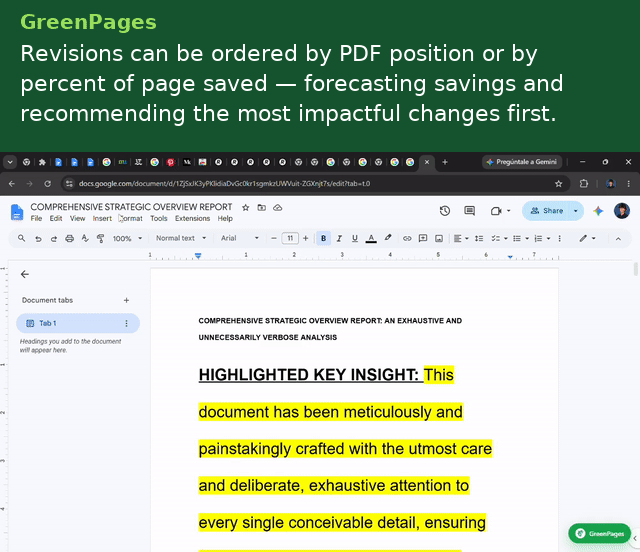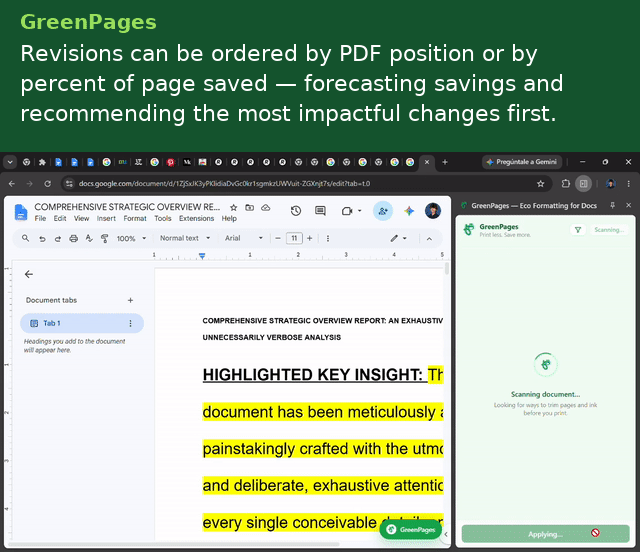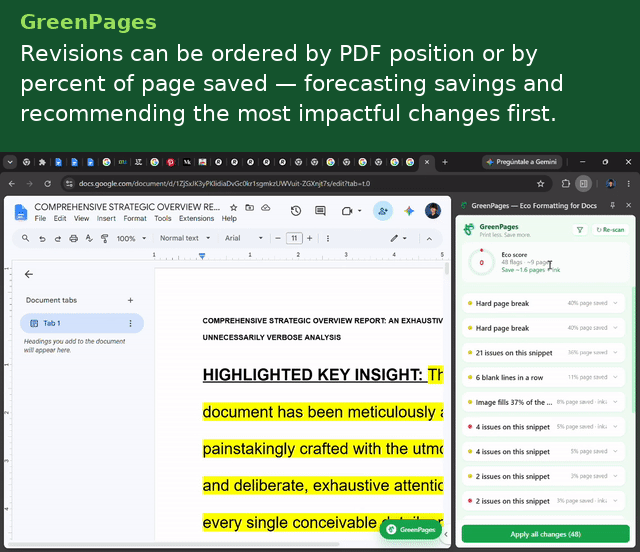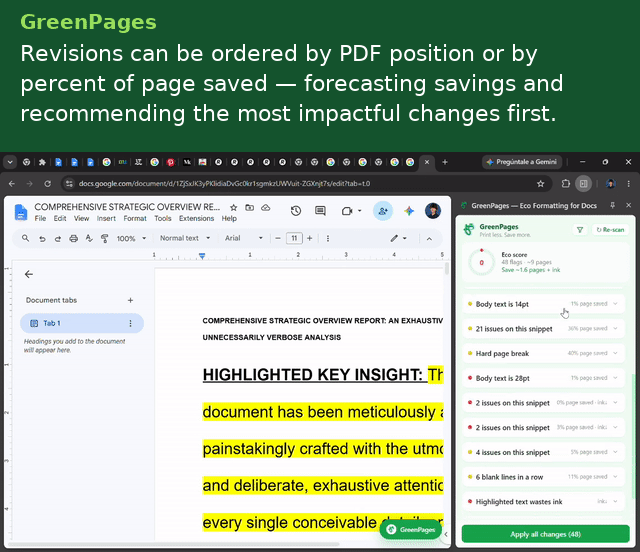
Each detector emits a position-anchored Flag carrying a human-readable explanation, a before/after preview, a quantified paper/ink impact estimate, and a serializable EditAction — so the UI layer never needs to know how a fix is applied, only that one exists.
Aggregated across all outstanding flags, the side panel renders a live EcoScore: $$\text{EcoScore} = \max!\left(0,\ \min!\left(100,\ 100 - 8n\right)\right)$$ where $$n$$ is the number of unresolved flags.
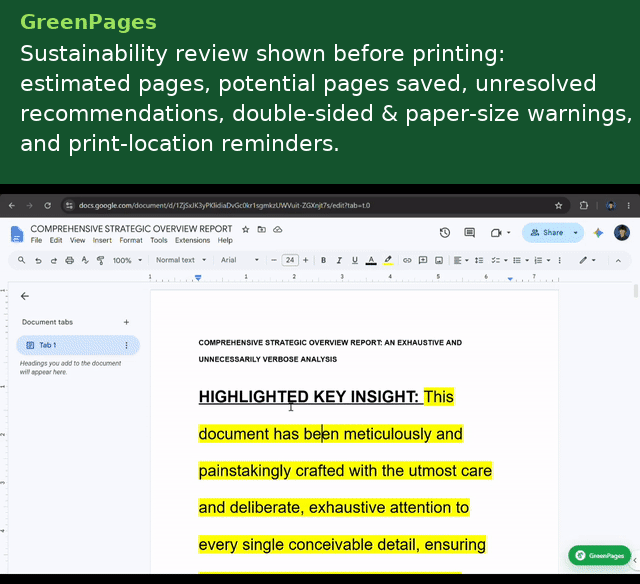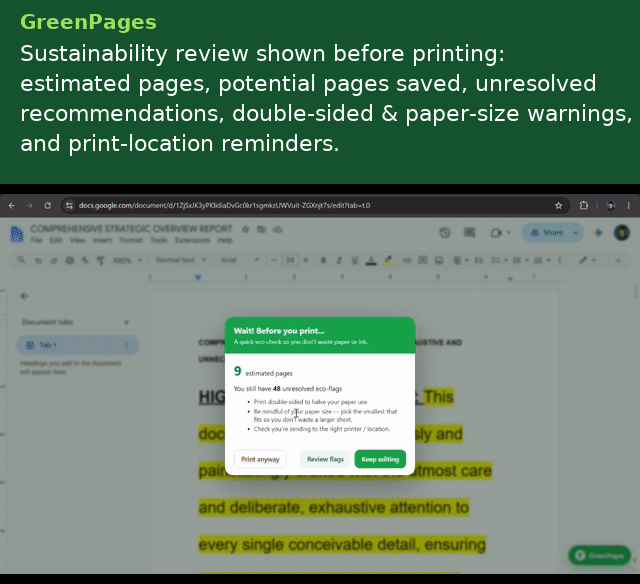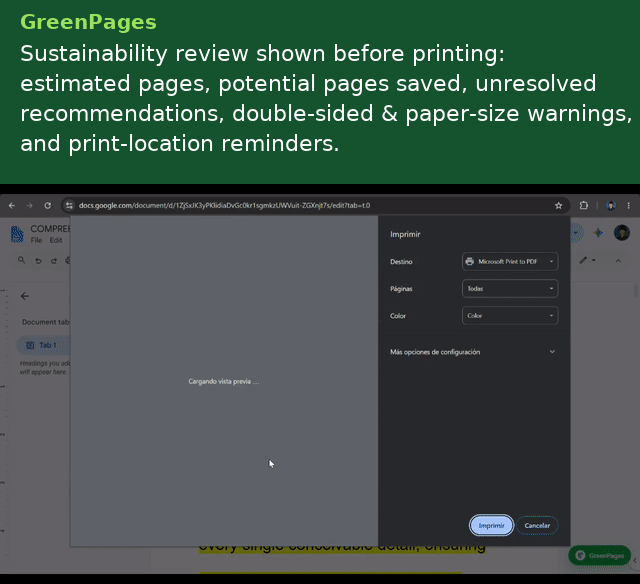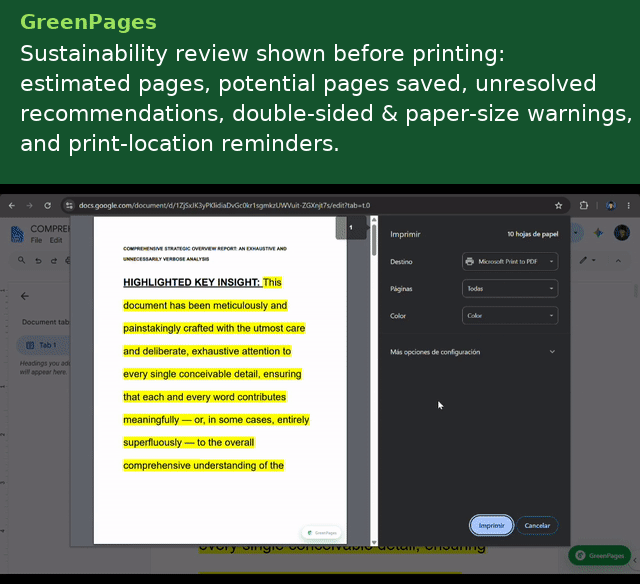
Before the native print dialog ever opens, a print-intercept layer (capturing Ctrl/Cmd+P and beforeprint) shows a set of reminders to increase sustainable practices: exact or estimated page count, potential pages saved, unresolved recommendation count, a double-sided printing reminder, and a paper-size/printer-location check.
How we built it
Extension shell — Manifest V3, scaffolded and bundled with @crxjs/vite-plugin on Vite 5, TypeScript end-to-end, Vitest for unit coverage. The extension's manifest key is pinned so an unpacked load always resolves to the same extension ID — without it, every machine/path produces a different ID, and the OAuth client registered against one specific ID in Google Cloud Console would stop authenticating different devices.
State architecture: the service worker (src/background/service-worker.ts) is the single source of truth: it owns the active DocModel, the current Flag[], dismissed-flag ids, and Settings. The side panel (React 18 + Zustand) and the content script talk to it exclusively through a typed chrome.runtime message protocol (GET_STATE, REANALYZE, APPLY_FLAG, DISMISS_FLAG, UPDATE_SETTINGS, GET_PRINT_SUMMARY, OPEN_PANEL) rather than ad hoc events, applying a flag re-runs analysis server-side so the flag list and EcoScore never drift out of sync with the document.
Document model — DocModel deliberately mirrors the Google Docs API's own structural shape (paragraphs → styled text runs → textStyle), flattened into a single character-offset address space with structural anchors (docStart/docEnd) carried on every run and paragraph.
The edit seam — the UI never mutates a document directly; it asks an EditBackend to apply() an EditAction. MockDocsBackend mutates an in-memory clone (zero credentials, zero network, fully demoable offline); GoogleDocsBackend maps the same actions to Google Docs batchUpdate requests, translating flat offsets into live document indices via the anchors captured at read time.
Docs API write-path engineering — the API's limitations forced some specific workarounds:
- It exposes no in-place image resize request, so a resize is a delete-and-reinsert of the inline image at the new dimensions, computed as $$\text{scale} = \sqrt{A_{\text{target}}/A_{\text{current}}}$$ to hit the target page-area fraction on both axes.
- It exposes no insertHorizontalRule via batchUpdate, so a hard page break is replaced by deleting the break and giving the now-empty paragraph a bottom border — visually identical to Docs' own Insert → Horizontal Line.
- Table cell indices don't exist until the table itself exists, so converting bullets to a table is a two-pass flow: create an empty grid, re-read the document to learn each cell's real index, then fill cells in descending index order so each insertion doesn't shift the indices still queued behind it.
- After every applied edit, the document is re-fetched in full rather than manually bookkeeping index shifts — trading one network round-trip for correctness, since batchUpdate requests apply sequentially and a single off-by-one would corrupt every subsequent translation.
Exact page counting: the Docs API itself exposes no page count. GreenPages calls Drive's files.export to render the document to PDF exactly as Google would print it, then reads the page count directly off the raw PDF bytes by locating the page tree's /Type /Pages dictionary and its /Count field (falling back to counting /Type /Page leaf objects), avoiding a full PDF-parsing dependency in a service-worker bundle. When that path isn't available (missing scope, network failure), it falls back to Gemini.
AI layer
Vercel serverless functions (api/analyze.ts, api/condense.ts) call Gemini 2.5 Flash directly via generativelanguage.googleapis.com's generateContent endpoint. Gemini is invoked to analyze improvements that may be made to the document, and to rewrite verbose paragraphs.
Uses not one, but multiple of the recommended AI capabilities:
- Predictive modeling/Pattern detection — forecasting usage or waste before it happens, by calculating % of page saved through Natural Language Processing (NLP) and ranking comments based on score.
- Recommendation systems — suggesting which actions have the highest impact, by ranking fixes based on % page saved percentage
- Generative AI — using NLP to identify changes to be made, as well as rewriting wordy paragraphs
OAuth: chrome.identity.getAuthToken with internal token caching and automatic invalidate-and-retry on a 401, scoped to documents (read/write) and drive.readonly (used solely to drive the PDF-export page count, since the Docs API can't provide one).
Challenges we ran into
- The canvas constraint. Google Docs paints its body to , not to addressable DOM nodes — there is no per-word geometry to anchor an inline underline or highlight over, and any such overlay would break on scroll, zoom, or re-render. This ruled out a Grammarly-style inline annotation layer entirely. Instead, we opted for a side panel operating on document offsets, with batchUpdate edits addressed the same way.
- Gemini 2.5 Flash's hidden reasoning budget. Early integration produced 200 OK responses with no usable text — finishReason: MAX_TOKENS and an empty candidates[0].content.parts. Because the code only triggers a behavioral fallback on missing text (rather than surfacing an explicit error), this initially looked like "the AI just isn't doing anything" instead of a configuration bug. The root cause: 2.5 Flash is a hybrid thinking model leading it to spend all of its tokens on thinking rather than outputs. The fix was setting generationConfig.thinkingConfig.thinkingBudget: 0 explicitly, redirecting the full budget to actual detection and rewrites.
- Balancing automation against user authority. Every fix, structural or AI-sourced, is a proposed EditAction requiring explicit Apply this ensures humans are kept in the loop to verify the factuality of documents, especially important in an academic context.
Accomplishments that we're proud of
- Built the first google extension which recommends changes in formatting in order to save ink and paper. *Ten eco-detectors with real Vitest coverage across the rules engine, the batchUpdate translation layer, table layout, and PDF page-counting.
- An architectural seam (EditBackend) clean enough that the entire suggestion UX was built, tested, and demoable against a mock document well before any Google API credential existed.
- Exact page counts on a live document — derived from the same PDF rendering pipeline Google's own print path uses, parsed without a PDF library.
- A print-intercept that activates before the native print dialog, rendered into a Shadow DOM so a host page we don't control (Google Docs) can neither style our modal nor be styled by it.
What we learned
Sustainability problems are very often visibility problems as the environmental cost of a formatting choice is real but deferred and invisible at decision time, and a quantified, in-context nudge changes behaviors far more than any hallway poster.
Technically, we came away with hands-on depth in: Manifest V3 service-worker-as-state-owner architecture; chrome.identity OAuth token lifecycle management; the Google Docs batchUpdate request model and its sequential-application semantics; reverse-engineering enough of the PDF page-tree structure to count pages without a parser dependency; and prompt/inference engineering specific to a hybrid reasoning model — namely, that "thinking" token budgets are a first-class lever that has to be managed explicitly, not assumed away.
Built With
- chrome
- gemini
- google-docs
- java
- manifestv3
- react
- tailwind
- typescript
- vercel
- vite




Log in or sign up for Devpost to join the conversation.