Greenlight
Multi-agent prior-authorization appeals with verification as the moat. LA Hacks 2026 · Catalyst for Care track.
Elevator Pitch
We built Greenlight, a multi-agent system that turns a denied prior authorization into a polished, fully-cited appeal letter in three minutes — and refuses to ship the letter if a single claim isn't grounded in the patient's chart, the payer's coverage policy, or peer-reviewed literature.
Problem
Prior authorization (PA) is the most universally hated workflow in American medicine. Per the AMA's 2024 PA survey: physicians spend 14–16 hours/week on PA paperwork. 94% of physicians report PA causing care delays. 33% report PA leading to serious adverse events for patients. 24% report PA-driven hospitalizations. Patients abandon prescribed treatment because the appeal cycle is so slow that they give up.
The harm is not evenly distributed. The patients who suffer most are exactly the ones with the least slack — rural Medicare Advantage seniors, oncology patients on time-sensitive regimens, and patients of small or under-staffed practices that can't absorb the administrative load.
The fact that this hasn't been fixed isn't a market gap — Cohere Health, Anterior, Co/Pilot, Latent, and Banjo Health have collectively raised hundreds of millions on this exact problem. The gap is that prior architectures treat the PA workflow as one large LLM call, which is unacceptable in healthcare: a single hallucinated lab value or fabricated drug interaction puts a real patient at risk. The unsolved sub-problem is trust, and trust requires architecture.
Solution
Greenlight decomposes the PA appeal into the five things a real specialist team would do in parallel, gives each task to a single-purpose agent, and gates the final letter behind a verifier that refuses to ship any claim it can't trace to a source.
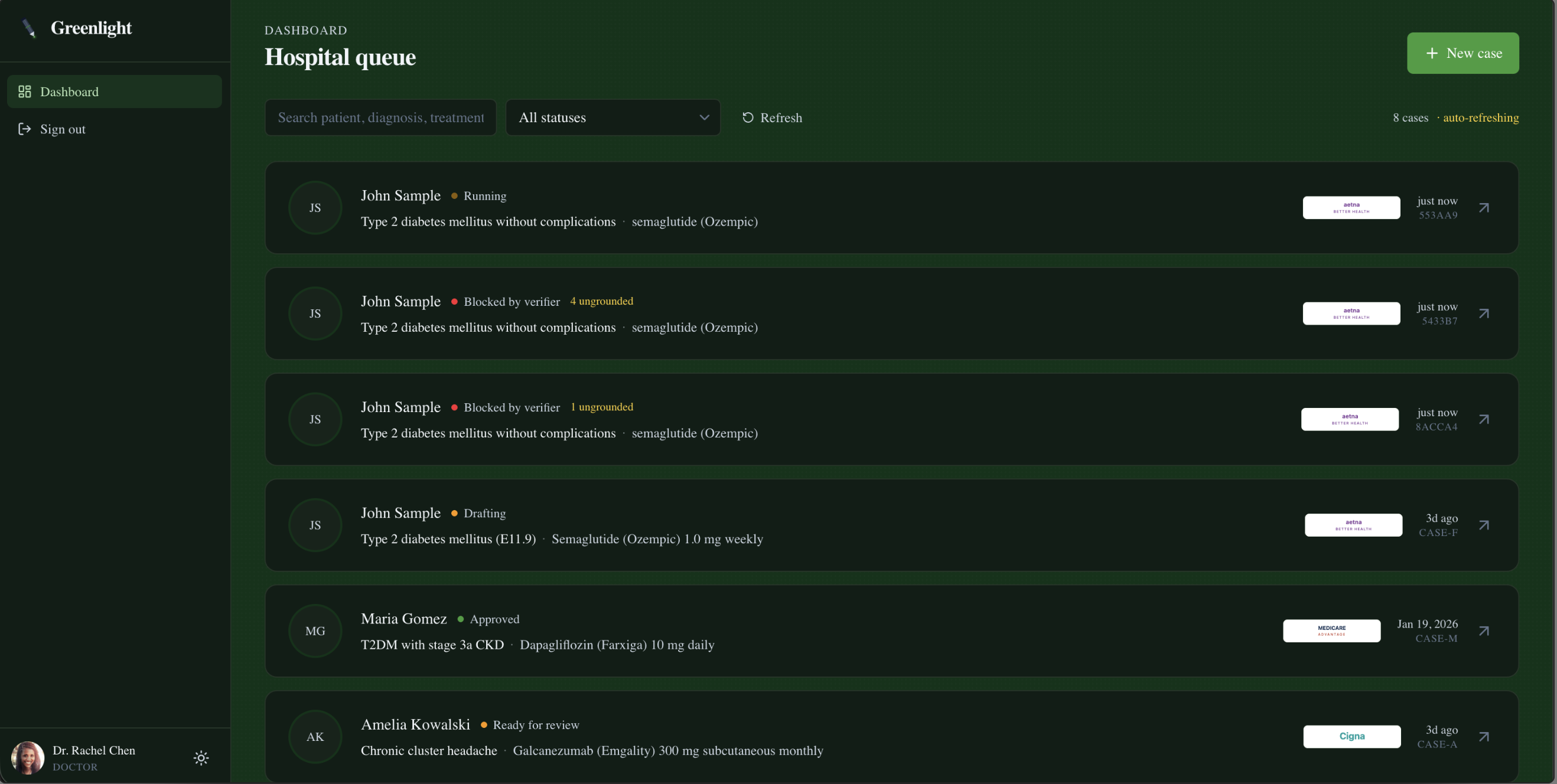
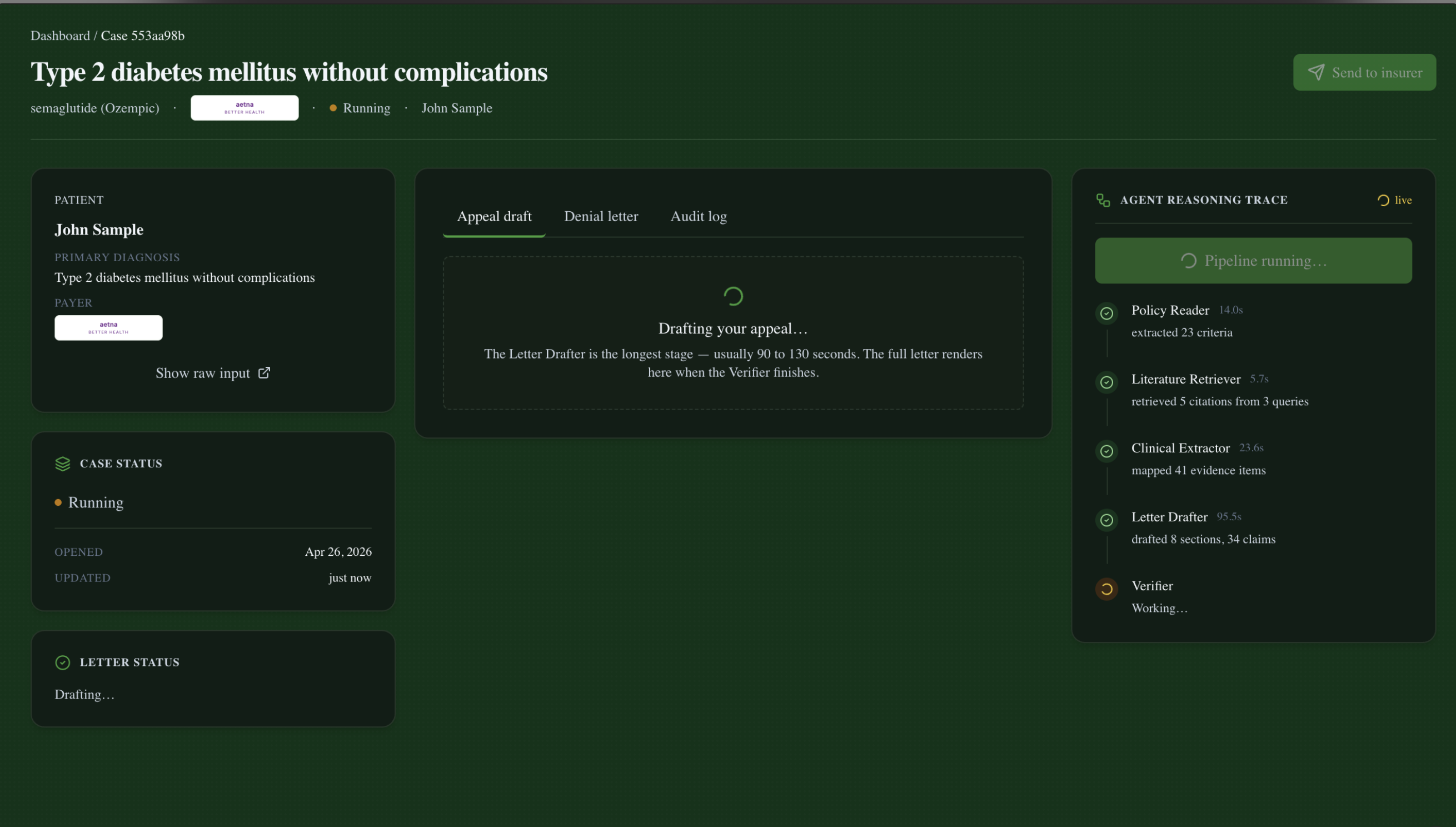
The user surface looks like a real clinical product: a doctor (or medical assistant) opens a denied case from their queue, hits Run pipeline, and watches five agents work through a live trace — Policy Reader → Clinical Extractor + Literature Retriever (in parallel) → Letter Drafter → Verifier. After ~3 minutes, either the letter renders with green hover-citation badges and a Send to insurer button, or the page surfaces a red banner listing every ungrounded claim with the verifier's rationale and Send is disabled until those claims are revised.
Where existing PA-automation companies treat their pipelines as black boxes, Greenlight is open and audit-first: every agent's output is persisted, every claim in the letter is one hover away from its source span, and the verifier's refusal-to-ship is the central guarantee a clinician can actually rely on.
Key Features
- Five specialist agents + one orchestrator, each with a strict
uagents.Modelrequest/response contract. Independently testable, independently deployable. - Verifier-as-gate, not afterthought. Every factual claim in the letter must trace to either a chart span (lab value, problem-list entry, clinical note quote), a policy criterion span, or a citation in our PubMed corpus. Verifier rejects → API marks the case
blocked_by_verifier→ UI disables Send-to-insurer. - Live SSE-driven dashboard. Server-Sent Events stream per-agent progress (
agent_started/agent_completed/agent_failed/verifier_complete/pipeline_complete) into a per-case live trace. History replay on connect means a late-joining tab sees the full run. - Atlas Vector Search literature retriever. AWS Bedrock Titan Text Embeddings V2 (1024-dim cosine) over a curated 12-paper PubMed corpus (SUSTAIN trial program, ADA Standards of Care, AACE guidelines). The Letter Drafter cites by stable slug (
sustain-6,ada-soc-2024-pharmacologic) so the rendered letter reads cleanly to a human reviewer. - Citation hover popovers. Every
[N]marker in the rendered letter resolves throughclaims[N-1].source_ids[]→source_registry[id]→ original chart text or full citation metadata. Ungrounded claims render in amber instead of green; verifier-blocked claims show a red banner above the letter. - Role-based UI. Doctors see their hospital's queue + an hours-saved counter + Send-to-insurer. Medical assistants see only cases they drafted + Mark-ready-for-review. Patients see only their own case's status text — no draft contents.
How It Works
Intake. A doctor or assistant clicks New case → Run flagship example (or pastes raw chart JSON, denial JSON, and policy text). The form posts to
POST /api/caseson the FastAPI bridge.Orchestrator dispatch. The orchestrator (
agents/orchestrator.py) returns{case_id}immediately and runs the pipeline in a background thread. It emits structured events at every agent boundary via anevent_callbackparameter — these are persisted to MongoDB (greenlight.audit_log) and pushed to any subscribed SSE consumer.Parallel kickoff. Policy Reader and Literature Retriever run concurrently in a
ThreadPoolExecutorbecause they're data-independent. Policy Reader takes the policy text + treatment name and returns a list of structuredCoverageCriterionobjects withcrit_NNIDs andSourceSpans pointing back to the policy text. Literature Retriever uses Claude to generate targeted search queries against the diagnosis, then hitsagents.shared.retrieval.search()which embeds each query via Bedrock and runs$vectorSearchagainst thecitations_vector_indexAtlas index. Returns a deduped list ofCitationobjects.Clinical extraction. Clinical Extractor takes the FHIR-lite chart and the criteria, scans free text in clinical notes plus structured fields, and produces a per-criterion
EvidenceItemmap plus a one-paragraphpatient_summaryso the Drafter doesn't have to re-parse raw chart JSON.Letter drafting. Letter Drafter takes criteria + evidence + citations + denial reason and produces eight typed
LetterSections (Clinical History, Medical Necessity Argument, Evidence-Based Support, etc.), a renderedfull_letter, and aclaims[]array — every assertion in the letter, marked with thesource_ids[]it relies on.Verification. Verifier runs in two stages. Stage 1 (resolution): every
source_idcited by every claim must resolve to a real entry in the source registry (chart spans + policy spans + retrieved citations). Asource_idlikeada-soc-2024-cardiovascularthat doesn't exist in our corpus = immediate fail. Stage 2 (semantic grounding): the resolved span text is fed back to Claude alongside the claim, with a strict prompt asking "does this source actually support this claim, or is it close-but-not-quite?" Each verdict carries aseverity(major/minor/None) and a rationale.all_grounded == Falseis a ship-stop, not a warning. The orchestrator marks the caseblocked_by_verifierand the UI disables the Send button.Persistence + live UI. The orchestrator's event callback writes each event to
greenlight.audit_logand the final state togreenlight.cases. The dashboard pollsGET /api/casesevery 3s while any case is running. The case-detail page attachesuseCaseStreamtoGET /api/cases/{id}/stream, which replays prior events from history and then streams new ones live. Whenpipeline_completefires, the page refetchesGET /api/cases/{id}and renders the letter (and the verifier banner if any claim was flagged).
End-to-end on the flagship case at real LLM speeds: ~190 seconds. Per-agent durations recorded in our integration tests: Policy Reader 13s, Literature Retriever 6s (parallel with PR), Clinical Extractor 31s, Letter Drafter 105s, Verifier 39s.
Technologies Used
Frontend. Next.js 16 (App Router, React 19), Tailwind 4 with @theme block design tokens, shadcn/ui primitives, framer-motion, lucide-react. Dark mode default. Typed API client in lib/api.ts mirrors the Pydantic shapes from agents/shared/models.py.
Agents / backend. Python 3.11+, uagents + uagents-core for the agent framework, FastAPI for the REST + SSE bridge (agents/api/server.py), pymongo for persistence, boto3 for Bedrock embeddings, pypdf for policy extraction.
AI / LLM. Anthropic Claude (Sonnet 4.6 by default for structured extraction; Haiku 4.5 for the cheaper agents). Structured-output validation with one-retry-on-error in our Claude wrapper (agents/shared/llm.py). AWS Bedrock Titan Text Embeddings V2 (amazon.titan-embed-text-v2:0, 1024-dim) for both citation ingest and query embedding — same model on both sides so similarity is meaningful.
Database. MongoDB Atlas. Three live collections: greenlight.cases (one document per pipeline run, holds the rendered letter + claims + verdicts + source_registry + audit log), greenlight.audit_log (append-only event stream, queryable by case_id for SSE history replay), greenlight.citations (the embedded PubMed corpus). Atlas Vector Search index citations_vector_index on the embedding field with cosine similarity and a filter on relevant_for tags.
Dev tooling. Built end-to-end in Claude Code. Branch-per-feature with PRs into main. We used Claude Code's agent framework expertise to bootstrap the uagents wiring and stayed in it for nearly every commit.
Deploy. Live at trygreenlight.us on a single Vultr cloud-compute instance — Next.js, the FastAPI bridge, and the agent runtime colocated. MongoDB Atlas is the only off-instance dependency. Local-dev is two terminals (uvicorn agents.api.server:app --port 8000 + npm run dev).
Architecture
Modularity through strict message contracts. Every inter-agent message is a uagents.Model class in agents/shared/models.py: PolicyReaderRequest/Response, ClinicalExtractorRequest/Response, LiteratureRequest/Response, LetterDraftRequest/Response, VerifierRequest/Response, plus the top-level AppealRequest/AppealResponse. The schemas are versioned at the field level: adding a field is fine; renaming or removing one means coordinating with every consumer. This let three engineers write five agents in parallel without merge conflicts on the wire format.
Real-time via Server-Sent Events. We chose SSE over WebSockets deliberately: the pipeline is one-way (server → client) during a run, native browser EventSource handles auto-reconnect on transient failures, and the protocol fits cleanly behind a vanilla HTTP proxy. The bridge holds a threading.Lock per case so the history snapshot is taken at queue-registration time — an event firing mid-registration goes either fully into history or fully into the new consumer's queue, never both. (This bug bit us once; we fixed it before integration day was over.)
Persistent audit trail. Every agent run, every event, every verdict is in MongoDB. The dashboard reads its queue from greenlight.cases. Case-detail rebuilds the agent trace from audit_log when a tab connects after pipeline_complete. This isn't a logging convenience — it's the backbone of the verifier story. "Why was this letter held?" is a query, not a guess.
The Verifier as load-bearing architecture. Most LLM systems treat verification as a post-hoc checker. Ours treats it as a pipeline gate that integrates with the storage and UI layers as a first-class concept. When the Verifier returns all_grounded == false, three things happen atomically: the case status flips to blocked_by_verifier, the API serializes every ungrounded verdict (with severity, rationale, and the original cited source IDs), and the UI's <VerifierFailureBanner /> renders above the letter with Send to insurer disabled and a tooltip explaining why. The verifier is the difference between "AI generated something" and "AI generated something we can defend in front of a payer's medical director."
Failure isolation. Literature Retriever failures (Bedrock outage, Atlas index unreachable) are caught in the orchestrator and the pipeline continues with an empty LiteratureResponse instead of crashing. The verifier will then flag any claim that tried to cite literature, but the rest of the letter ships through. This is the right default for a real clinical product: degrade, don't disappear.
Scalability. Agents are stateless message handlers. The orchestrator runs the pipeline in a background thread but the work each agent does is independent and could be horizontally fanned out. MongoDB is the only stateful component, and the schema is denormalized for read-side dashboard queries (counts + status badges without joins).
Track & Company Challenge Justification
Catalyst for Care (primary track)
PA is the largest-impact, lowest-fun, highest-cost-per-patient process in American outpatient medicine. The problem is healthcare-defining and we built a working tool that addresses it directly — a doctor at the booth can drop in a synthetic case and see a credible appeal letter generated in front of them in three minutes. Every architectural decision (the verifier moat, the audit trail, the citation hovers, the role-based access) is in service of clinicians who actually have to ship this letter to a payer's medical director — not in service of a hackathon vibe.
Cognition Challenge — eliminating professional toil
Cognition's challenge prompt names two paths: making AI coding agents more capable, or eliminating professional toil that agents can't yet handle. Prior authorization is the canonical example of professional toil: high cognitive load, high volume, low intrinsic value, perfectly automatable, and currently devouring 14–16 hours of every American physician's week. We picked it on purpose.
The Cognition prompt also calls out better verification for AI-generated content as a sub-theme, and that maps directly onto our central technical bet: every factual claim in every letter is verified against an explicit source span before the letter can ship. Stage 1 catches source_ids that don't resolve (the LLM literally inventing a citation handle). Stage 2 catches paraphrase overreach where the cited source is real but the claim doesn't actually follow from it (e.g., the Drafter writes "SUSTAIN 2 showed a 1.8% A1c reduction" when the real number is 1.6%). Healthcare hallucination = patient harm; we built the architecture that lets a clinician trust the output. We built Greenlight in Claude Code end-to-end, branch-per-feature, with the agent framework writing most of our uagents wiring on the first try.
Arista Networks — Connect the Dots
Arista's prompt asks for a software solution that improves everyday life by connecting people to resources or routing useful data to solve a problem in daily life. Greenlight does exactly that — three previously-siloed data sources converge to produce one useful artifact:
- The patient chart (locked in an EHR, often only readable by the practice that owns it)
- The payer's coverage policy (public PDF but never cross-referenced with the chart at the point of decision)
- The peer-reviewed clinical literature (PubMed, ADA, AACE — exists, almost never cited in real PA appeals because nobody has time)
A specialist orchestrator routes these through five agents and delivers a single connected output: the cited appeal letter that puts the right evidence in front of the right reviewer. The patient gets their medication; the doctor gets their afternoon back; the payer's medical director gets a defensible record. Three nodes of data, one routed solution.
MLH — Best Use of MongoDB Atlas
We use Atlas as both the operational store and the vector retrieval engine:
greenlight.cases— one document per pipeline run, holding the rendered letter, theclaims[], the per-claimverdicts[], thesource_registry(flat map of every span_id and citation_id used in this run → original text), and a denormalized status for dashboard queries.greenlight.audit_log— append-only event stream. One document peragent_started/agent_completed/verifier_complete/pipeline_completeevent, queryable bycase_id. Powers SSE history replay for tabs that connect mid-run.greenlight.citations— the embedded PubMed corpus (12 entries: SUSTAIN trial program, ADA Standards of Care 2024, AACE 2022 + 2025 guidelines, mechanism reviews, meta-analyses). Each document carries the abstract text, structured metadata, controlled-vocabularyrelevant_fortags, and a 1024-floatembeddingfield.- Atlas Vector Search index
citations_vector_indexon theembeddingfield with cosine similarity, plus arelevant_forfilter field for tag-pre-filtering ({ relevant_for: { $in: ["ascvd", "ckd"] } }before similarity ranking). The Literature Retriever embeds its query with the same Bedrock model used at ingest, runs$vectorSearchover the index, and returns the top-k by similarity.
Best Social Impact Hack
The 14–16 hours/week and the adverse-event rate aren't abstract. The single largest beneficiary of this kind of automation is the under-staffed practice — the rural clinic with one biller for forty doctors, the safety-net hospital where a denied PA means the patient simply doesn't get the medication, the small oncology group that can't afford Cohere Health's contract. Our core thesis is redistribution of burden: the system absorbs the toil so that small practices can serve more patients without administrative collapse. Every architectural decision (the audit trail that survives staff turnover, the role-based UI that lets a single biller manage a queue across multiple doctors, the deterministic verifier that catches issues a tired clinician would miss at the end of a long shift) compounds in exactly the settings where the harm is worst.
MLH — Best Domain Name from GoDaddy
We registered trygreenlight.us via GoDaddy. Short, intent-readable, ends in the .us TLD that signals American-healthcare focus, and the leading verb (try) is the right call-to-action for a hackathon judge clicking through from Devpost.
MLH — Best Use of Vultr
The full stack is deployed on Vultr — the Next.js web app, the FastAPI bridge (agents/api/server.py), and the agent runtime — all colocated on a single Vultr cloud compute instance, fronted by trygreenlight.us. MongoDB Atlas is the only off-instance dependency. We chose Vultr over Vercel because the Letter Drafter agent's response can run upwards of 100 seconds against Claude Sonnet 4.6, which exceeds the standard serverless-function timeout window — a single long-lived VM is the right shape for our pipeline, and Vultr's hourly billing made the demo deploy free.
Best UI/UX
Clinical density over visual flair. The aesthetic targets are Linear / Raycast / Cursor — dense information, fast keyboard navigation, dark mode default, subtle borders over heavy shadows. Every claim in the rendered letter is a hover-to-see-source affordance with a tooltip showing the original chart text or full citation. The audit trail is visible by default on the case-detail page (right column), not buried in a settings panel. Status colors mean something specific: brand-500 green = approved/sent, amber = drafting/ready-for-review, red = denied or blocked_by_verifier. Dark mode is the default because clinical staff use this kind of tool late, on big monitors, in dim rooms.
MLH — High-Quality Sponsormaxxing
If you've made it this far, we're hitting Catalyst for Care, Cognition, Arista, MLH MongoDB Atlas, MLH GoDaddy, MLH Vultr, and Best Social Impact. Seven credible sponsor hits, no padding.
Challenges We Faced
Citation grounding was harder than it looked. Our first verifier checked that every cited source_id resolved to a known ID — easy. The Drafter passed that check trivially, then hallucinated content. We rebuilt the Verifier as a two-stage check: stage 1 still validates ID resolution, but stage 2 takes the resolved span text and asks Claude "does this source actually support this claim, accounting for paraphrase but not for fabrication?" with a constrained output schema (grounded: bool, severity: major|minor, rationale: str). This caught the failure modes we actually saw in live runs: misstated SUSTAIN trial numbers, fabricated weight-loss metrics, made-up citation handles like ada-soc-2024-cardiovascular (the LLM imagining a paper that doesn't exist).
Schema coordination across five agents. Past three agents, ad-hoc dictionaries break down — a renamed field is a silent data-loss bug. We ran every inter-agent message through a uagents.Model class in agents/shared/models.py from day one, and added a project-wide rule that field renames require coordination with every consumer. Three engineers shipped five agents in parallel without a single wire-format merge conflict.
SSE consumer race condition. Our first version of the live-trace endpoint had a duplicate-event bug: a consumer connecting mid-run would receive an event both as part of the history snapshot and in the live stream. We solved it with a per-case threading.Lock that brackets the history-snapshot read and the new-consumer queue registration. Snapshot and registration are atomic; an event firing mid-bracket goes either fully into history or fully into the new queue, never both.
Verifier latency. A naive verifier would call Claude once per claim — at ~40 claims per letter and ~1s per call, that's a 40-second tail on every run. We batch by source-document: every claim citing the same chart span is verified against that span in a single pass. Verifier total runtime sits around 39 seconds for a 43-claim letter — barely affecting the perceived demo cadence.
Synthetic chart realism. A chart that satisfies every coverage criterion is a boring demo because the verifier has nothing to catch. We deliberately under-document the flagship chart — no lifestyle-intervention notes, sparse demographic prose, no longitudinal weight series. This isn't synthetic-data laziness; it's a faithful model of how primary-care visits are actually charted (the doctor managed meds and ran out of time to write up the rest). The verifier catches the AI's overreach into things the chart never claimed, which is exactly the failure mode that exists in real clinical practice.
What We Learned
Multi-agent paid off because PA genuinely decomposes. This domain isn't a single monolithic reasoning problem with a fashionable wrapper — it's five distinct specialist tasks (read the policy, find the evidence in the chart, find the literature, write the letter, verify the letter) that map cleanly onto five agent contracts. Each agent's prompt is tractable, each agent's output is testable in isolation, and the failure surface stays small because the schemas are tight.
Verification is not a feature — it's the product. A multi-agent appeal letter generator without a verifier is a credible-sounding text generator that occasionally maims patients. The verifier is what makes the whole architecture defensible. We spent more engineering hours on the verifier (two-stage checks, severity gradation, source-registry resolution, batched LLM calls, integration with the API status field, integration with the UI's Send button) than on any other agent. That's the right ratio.
Strict uagents.Model schemas matter past three agents. With two agents you can pass dictionaries. With five agents and three engineers shipping in parallel, untyped messages are how you get silent data loss in production. The discipline of defining a Pydantic-compatible model for every cross-agent message bought us the ability to run the agents independently, mock each other's outputs, and refactor without coordination.
Atlas Vector Search was a quiet productivity win. We had Atlas in the stack already for cases / audit logs / letters. Promoting one collection to vector search (one Atlas UI form + one ingest script) gave us semantic literature retrieval without bringing in a second data store. The Literature Retriever now answers natural-language clinical questions directly — exactly the right shape for a free-text query from the Drafter.
Claude Code on a five-agent codebase felt like having a senior engineer on every branch. Most of our agent boilerplate, the FastAPI bridge, and the SSE consumer hook were drafted in Claude Code and refined by hand. The thing that made it work was the strict schemas: with agents/shared/models.py as a single source of truth, the AI never had to guess what shape a LetterDraftResponse was supposed to be.
Future Work
Real EHR integration. SMART-on-FHIR with Epic and Cerner so charts come straight from the source system instead of synthetic JSON. HIPAA Business Associate Agreement, full audit logging at the read boundary. Zetic-style on-device clinical extraction so PHI never leaves the practice's network — the structured criteria + evidence map can travel, the raw chart never has to.
Pre-flight approval prediction. Before submitting a PA, run the chart against the policy and predict approval probability. If predicted-deny, surface the gap to the prescriber before the request goes out, instead of waiting for the formal denial.
Cross-payer learning loop. Track which arguments work for which insurers (per payer × per drug class × per criterion). Surface patterns: "Aetna Better Health denies semaglutide on crit_08 73% of the time when the chart lacks a documented FBG log; here's the exact wording that gets it through."
Self-improvement from human edits. When a clinician edits the generated letter, capture the diff. Use it as training data for the Drafter. The verifier's source-grounding check catches the worst hallucinations; human edits catch the rest.
Real-world pilot. A small community oncology practice or a rural primary-care group, processing actual denied PAs (with proper PHI handling). The hours-saved counter we already display in the dashboard becomes a real number with a real before/after.
Why This Matters
A 71-year-old woman in rural Iowa has type 2 diabetes, established cardiovascular disease, an A1c that won't come down, and a Medicare Advantage plan. Her primary-care doctor prescribes semaglutide. The plan's PA process takes two weeks; the denial cites missing documentation; the doctor's office is too short-staffed to mount a formal appeal. Six months later, she's in the ER with a non-fatal MI. Her cardiologist asks her PCP why she wasn't on a GLP-1. The honest answer is "the paperwork beat us."
The patient is a composite; the pattern is not. The AMA's 2024 Prior Authorization Physician Survey is the source of the care-delay and adverse-event rates we cite in our Problem section. The HHS Office of Inspector General's 2022 report "Some Medicare Advantage Organization Denials of Prior Authorization Requests Raise Concerns About Beneficiary Access to Medically Necessary Care" (OEI-09-18-00260) audited a sample of denied MA prior-auth requests and found that 13% met Medicare coverage rules and would have been approved under traditional Medicare — the denial wasn't a clinical judgment, it was an administrative artifact. The OIG's 2024 follow-up (OEI-09-23-00050) found the same patterns persisting two years on. Taken together, the documentation says: roughly one in eight Medicare Advantage PA denials is wrong, and almost no patient has the time, advocacy, or staff to fight it.
This story repeats every week, in every state. The thing the system has been missing isn't a smarter LLM — it's a redistribution of who absorbs the burden. Greenlight's bet is that a multi-agent system, gated by a verifier we'd actually trust, can take the toil off the clinician's plate without taking the safety story with it. The doctors get their afternoons back. The patients get their meds.
Built With
- amazon-bedrock
- amazon-web-services
- anthropic
- claude
- fastapi
- framer-motion
- godaddy
- mongodb
- mongodb-atlas
- mongodb-atlas-vector-search
- nextjs
- pydantic
- python
- react
- shadcn-ui
- tailwindcss
- typescript
- uagents
- vultr

Log in or sign up for Devpost to join the conversation.