-
-
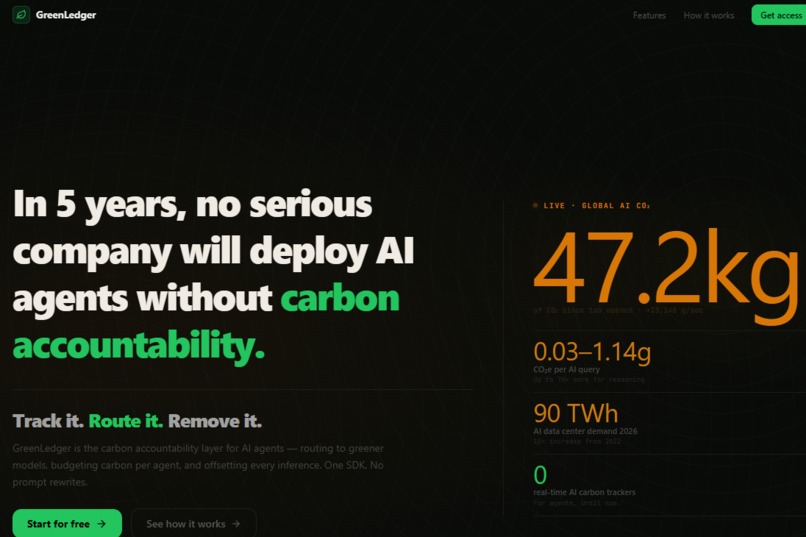
The GreenLedger Dashboard: Real-time visibility into your AI's carbon footprint, wallet budgets, and climate impact
-
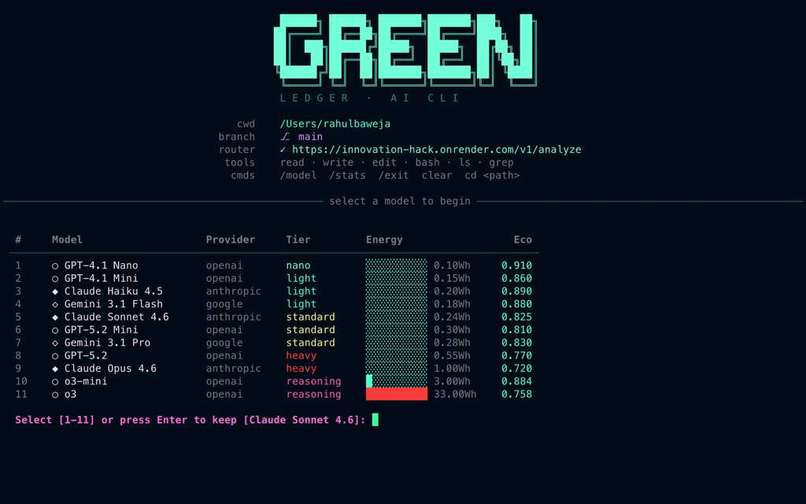
GreenLedger CLI in action: Tracking carbon budgets and downgrading heavy models on the fly
Inspiration
AI's energy footprint is growing rapidly, but not every task requires a massive, power-hungry model. We realized there is a huge "overkill" problem in the industry: developers and users frequently default to heavily resource-intensive models (like Claude-Opus 4.6, Gemini 3.1 Pro or GPT-5.4) for simple tasks like basic formatting, translation, or short summaries. We were inspired to build a system that acts as a "strict AI efficiency router" to intercept these requests, dynamically downgrade them to greener alternatives without sacrificing capability, and divert the financial savings toward carbon removal.
What it does
GreenLedger is an intelligent API gateway and sustainability middleware for AI requests. When a user or agent submits a prompt, our smart router analyzes the task's complexity (Light, Standard, or Heavy) and domain (Coding vs. Reasoning). If a user selects an "overkill" model for a simple task, GreenLedger intercepts the request and routes it to a highly eco-efficient alternative (like claude-haiku-4-5 or gemini-3.1-flash).
After execution, it generates a standardized "Environmental Receipt" that tracks the exact tokens used, latency, carbon emissions (co2e_g), and water consumption. Most importantly, it calculates the money saved by downgrading the model and diverts those savings into a "Levy Ledger" to fund carbon offset initiatives like Stripe Climate.
How we built it
We utilized a Next.js 14 frontend and a FastAPI (Python) backend to handle the core orchestration. For the core routing intelligence, we deployed a lightweight llama3.2:1b model locally via Ollama. This acts as our decision engine, using strict JSON formatting to analyze prompt complexity and recommend model downgrades. To keep routing instantaneous for basic tasks, we also implemented fast heuristics (e.g., checking for <10 word prompts or keywords like "summarize" or "translate").
For security, we built a BYOK (Bring Your Own Key) keystore that encrypts and decrypts user API keys on the fly before executing the inference.
Challenges we ran into
One of the biggest challenges was ensuring that our "Green Router" didn't consume more energy than it saved. Using a massive LLM to classify prompts would defeat the purpose. We solved this by hosting a highly efficient, 1-billion-parameter local model (llama3.2:1b) on a VM and combining it with instant keyword-based heuristics. Another challenge was prompt engineering the local Llama model to prioritize "Capability First"; we had to implement strict tie-breakers and output formatting to ensure the router never assigned a low-tier model to a high-complexity reasoning task, which would result in a failed response.
Accomplishments that we're proud of
We are incredibly proud of successfully building a working, LLM-driven routing pipeline that catches overkill queries in real-time. We managed to get a local Llama model to reliably output strict JSON routing decisions. Additionally, we are proud of our comprehensive ReceiptData engine. It doesn't just execute the query; it calculates the exact API cost difference between the original requested model and the routed model, explicitly tracking the "CO2 avoided" and allocating the financial savings to a concrete carbon levy.
What we learned
We learned a tremendous amount about LLM orchestration and constraint-based prompting. We discovered that simple, fast heuristics (like prompt word count) combined with a tiny, local LLM are more than capable of accurately classifying AI task complexity. We also learned how to seamlessly integrate local Ollama instances asynchronously with a FastAPI backend using httpx, ensuring our gateway remains non-blocking even under load.
What's next for GreenLedger
We plan to fully integrate the Stripe Climate API so that when our Levy Engine accumulates enough savings from downgraded models, it automatically triggers a real-world financial transaction to purchase carbon removal credits.


Log in or sign up for Devpost to join the conversation.