-
-

landing page
-
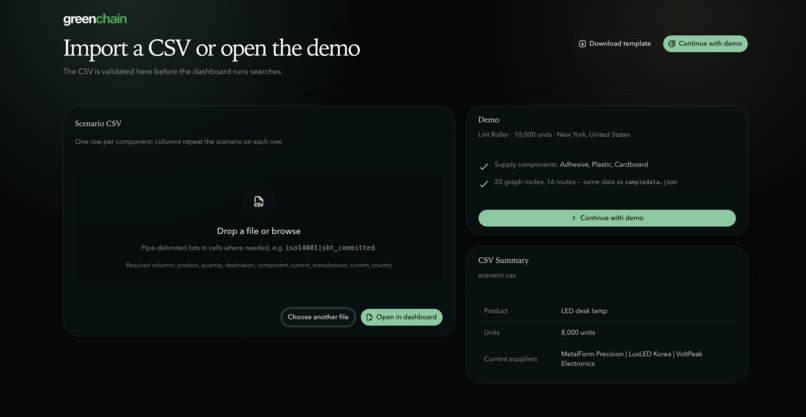
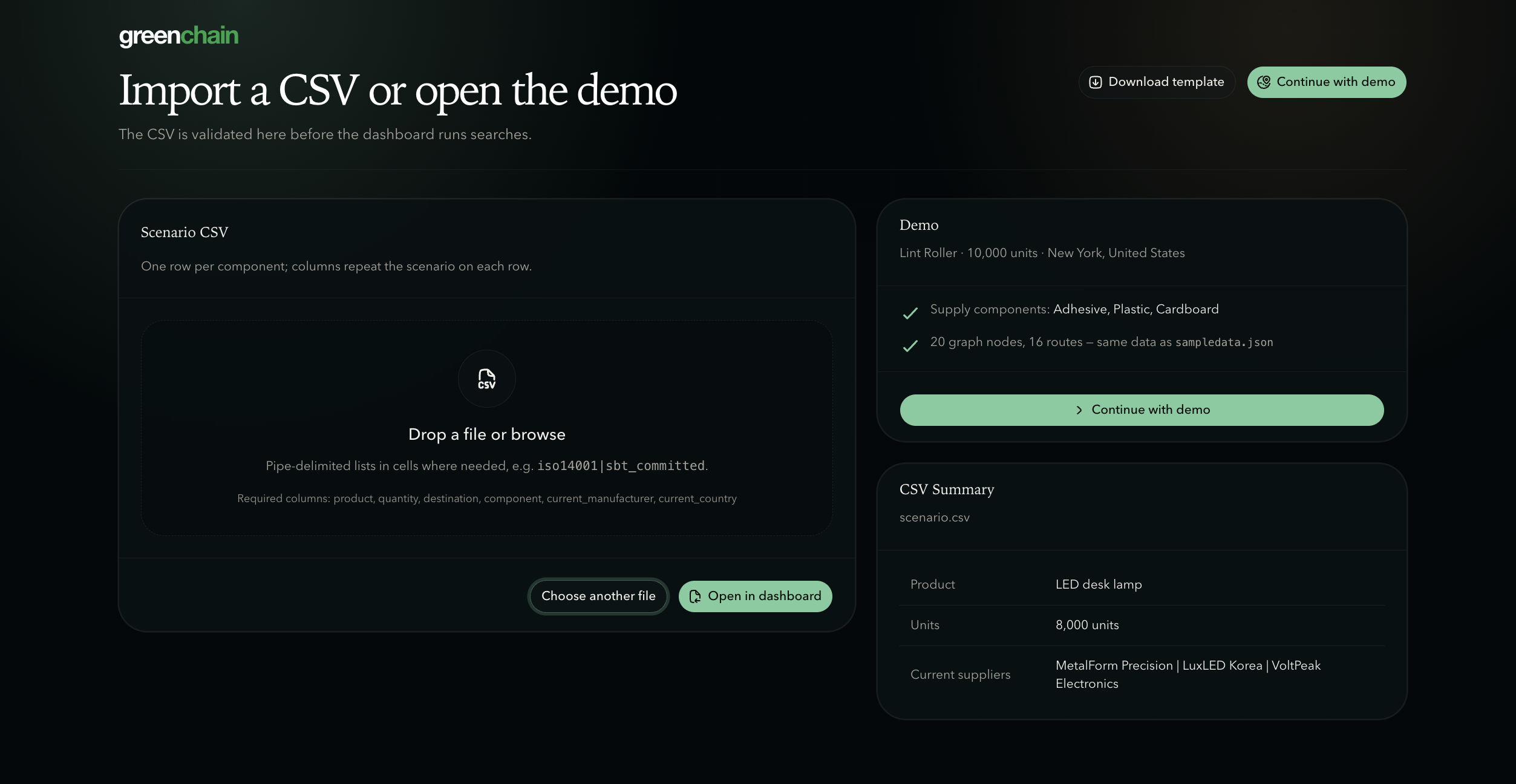
file upload page
-

loading page
-
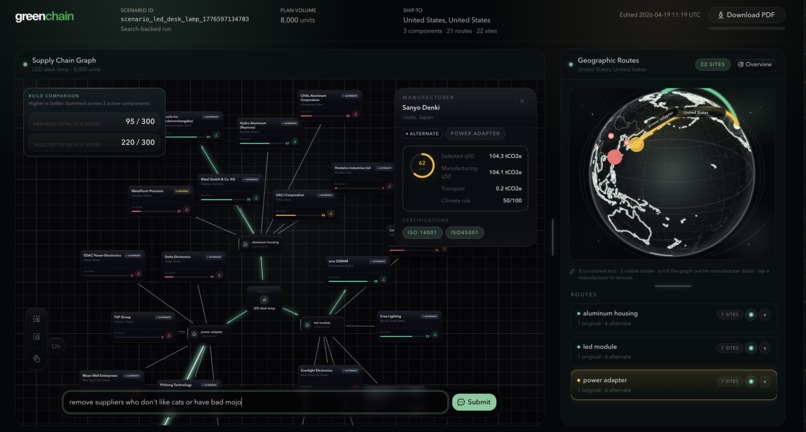
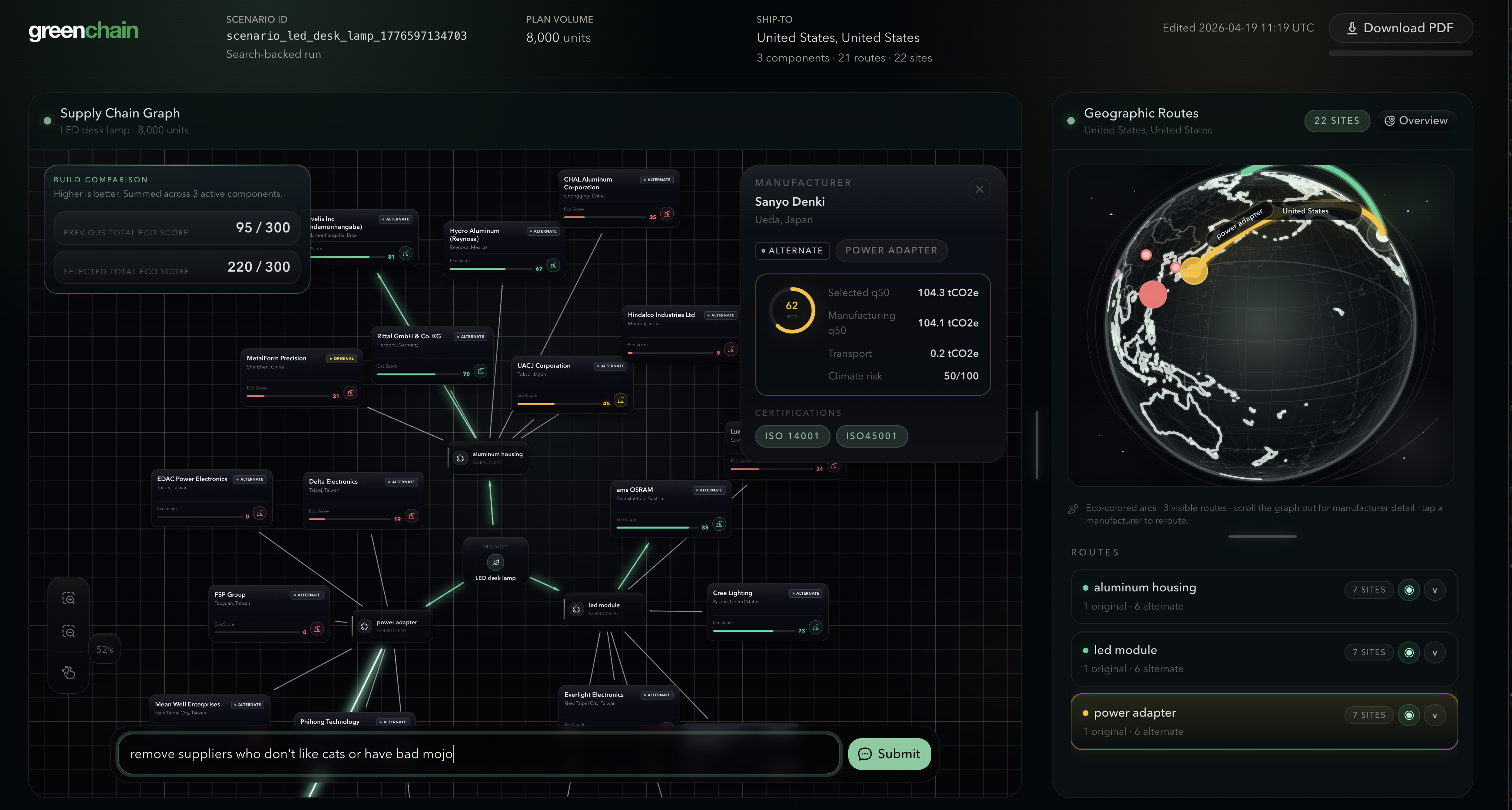
dashboard view with toggleable options


Inspiration
Global supply chains are responsible for over 60% of corporate greenhouse gas emissions, yet the vast majority of procurement decisions are made with zero visibility into those emissions. A procurement manager choosing between factories in China versus Portugal, or air freight versus sea freight, has no fast, accessible tool to answer: which option is actually better for the planet?
Existing ESG software costs upwards of $50,000 per year, requires months of onboarding, and is built for compliance teams — not for the fast, real-world decisions that procurement managers make every week. On top of that, the EU is now actively forcing large companies to measure and report their Scope 3 supply chain emissions, creating urgent demand for exactly this kind of tool.
We built GreenChain because this gap is real, the problem is urgent, and nobody has moved fast enough to build the wide-surface comparator that procurement teams actually need.
What it does
Simply put, GreenChain is an environmental supply chain comparator. You describe what you're sourcing — product, destination market, quantity, candidate countries, and transport mode — and GreenChain automatically discovers real manufacturers for the components, scores them across five environmental dimensions (manufacturing emissions, transport carbon, grid carbon intensity, certifications, and climate risk), and ranks them on a live dashboard. Results render as a force-directed supply chain graph and an interactive 3D globe with animated shipping routes. You can then write plain-English scenario edits to swap suppliers and analyze the data, exporting a full sustainability report — an actionable sourcing decision in a matter of minutes.

Key features
Multi-agent research swarm: Manufacturer discovery is handled by a Dedalus-orchestrated agent swarm running Claude Sonnet 4.6 on Dedalus Machines. Agents fan out in parallel across Brave Search to find real manufacturers (filtering out aggregators), crawl their sustainability and ESG pages with BeautifulSoup to extract certification signals (ISO 14001, CDP A/B/C, Science Based Targets), and invoke a suite of scoring tools — all coordinated by the Dedalus runtime. The swarm automatically retries with expanded geography if too few alternatives surface and deduplicates by normalized name and country before passing candidates downstream.
ML scoring pipeline: Each candidate flows through three layers. Manufacturing emissions are estimated by an XGBoost quantile regression model (q10/q50/q90 uncertainty bands) trained on EPA USEEIO v1.3 sector factors cross-referenced with Ember Climate grid intensity and ND-GAIN climate risk indices, using GroupShuffleSplit to evaluate on unseen country-sector combinations and Spearman rank correlation for validation. Transport emissions are computed from first principles via the GLEC framework (sea/air/rail/road kgCO₂/tonne-km factors) against a port-distance lookup from precomputed data, with a regional fallback chain for countries without major port records. Finally, a ScoreAssembler normalizes all five dimensions into a 0–100 composite eco-score with configurable weights, applying certification multipliers (CDP A = −10%, no-disclosure = +15%) exactly once to avoid double-penalization.
Visualization and scenario editing: The dashboard splits into a directed supply chain graph (physics-settled with spring + collision + repulsion, best-eco path highlighted) and a Three.js 3D globe with depth-sorted geodesic arcs animated by transport mode. Scenario edits written in plain English are processed by K2 Think V2 for safe structured JSON mutation with SQLite revision history. Sustainability reports are synthesized by the Gemini API and exported as markdown memos.
How we built it
- Frontend: React + Next.js for frontend with route handlers
- Styles: Tailwind CSS + PostCSS + tw-animate-css for base UI
- Components: shadcn/ui + Radix UI + react-resizable-panels + Hugeicons for UI support
- Globe: Three.js 3D Earth with geodesic arcs, animated by transport mode; custom SVG from world-atlas topology with custom projection/path code
- Backend: FastAPI for main JSON API server
- Protocol: Uvicorn for ASGI server
- Schema: Pydantic v2 for request/response validation
- Database: SQLite for local caching of manufacturer results, search audit logs, and scenario edit history
- Web Scraping: BeautifulSoup4 for fetching sustainability pages for certification signals
- AI/Agent Layer: Dedalus Labs SDK for orchestrating supplier-research agent and containerized environments with persistent state for deep research
- Search Model: Claude Sonnet 4.6 for research
- Search API: Brave Search API for discovering manufacturers
- Scenario Filtering: K2 Think V2 for advanced prompt-based scenario editing
- Reports: Gemma 4 in Gemini API for downloadable scenario reports
- ML/Scoring/Algorithms Layer: XGBoost quantile regression for estimating manufacturing emissions
- Data Processing: NumPy + pandas for inference, dataset loading, and model training
- Splits: scikit-learn for the training pipeline
- Robustness: GroupShuffleSplit for evaluation split by country-industry to ensure model is tested on unseen country/sector contributions; Spearman rank correlation for validation
- Data Sets: EPA USEEIO v1.3 for base sector emissions, Ember Climate for country CO2 intensity, ND-GAIN for country climate risk/readiness scores
Sponsor notes
Dedalus
Containers
For best use of Dedalus containers, GreenChain ingests manufacturer sustainability pages as evidence for supply-chain scoring. Treating the public web as untrusted input, we route all HTTP page retrieval through a Dedalus Machine provisioned on the Dedalus Container Service (DCS) at https://dcs.dedaluslabs.ai.
At backend startup, the service provisions a Machine via the DCS REST API using Bearer authentication (the Python SDK does not yet expose the Machines API, so we call the documented HTTP endpoints directly). Once the Machine reaches a running phase, each page read is executed as a remote command through POST /v1/machines/{id}/executions using a curl argv vector where the URL is a separate argument. That design prevents shell metacharacter injection from turning a fetch into arbitrary command execution. The backend polls GET /v1/machines/{id}/executions/{exec_id} until completion, then retrieves the captured stdout/stderr body from GET /v1/machines/{id}/executions/{exec_id}/output. HTML text extraction and downstream parsing remain in-process in the backend (BeautifulSoup) after the HTML returns, preserving a clean trust boundary: untrusted network retrieval happens inside Dedalus infrastructure, while scoring logic stays in the application’s controlled environment.
On shutdown, the Machine is destroyed with DELETE /v1/machines/{id} using an If-Match revision header, so provisioning is an explicitly lifecycle-managed egress isolation layer aligned with how real services operate.
Agent Swarm
For best agent swarm implementation, GreenChain’s research mode is a tool-using agent swarm aimed at defensible supply-chain insight. It combines live web discovery, primary-source page reading, and structured domain computations.
At the orchestration layer, DedalusRunner drives anthropic/claude-sonnet-4-6 through a multi-tool workflow with up to max_steps=14 tool/reasoning steps per run. The agent can call Brave-backed web_search from the API process, invoke domain tools such as XGBoost-backed manufacturing emissions (lookup_emission_factor), GLEC-style transport modeling (calculate_transport_emissions), and certification scoring (score_certifications), and repeatedly refine its plan based on intermediate results. When multi-component scenario exploration yields an insufficient alternative set after parsing, the server re-runs the agent up to three times to broaden coverage.
At the hosting layer, the swarm’s fetch_url reads are executed on the Dedalus Machine using the same DCS executions/output flow, so the swarm can aggressively explore the web while keeping page egress pinned to KVM-isolated compute. Search and other API-backed tools remain in the backend service, which makes the architecture simple: orchestration is rich and fast-moving, while web page retrieval is isolated and lifecycle-managed.
K2 Think V2
Scenario editing sounds simple ("swap this supplier, remove that one") but it's actually a hard structured reasoning problem. Every edit touches a live JSON object representing a multi-component supply chain, where each node carries emission scores, transport calculations, and certification data that have to stay internally consistent. We used K2 Think V2 in two sequential reasoning passes: first to classify the user's intent (filter, undo, or reject), then to evaluate each alternate manufacturer individually — deciding keep or remove based on the full prompt context and the specific candidate's attributes. The reason K2 was the right model here is that these decisions are genuinely ambiguous. When a user says "show me only ISO-certified manufacturers," K2 has to reason about what "ISO-certified" means in the context of each specific component, whether an unverified supplier counts, and what the user probably intended — not just deterministically keyword-match. We run up to 6 evaluations in parallel, and K2's structured reasoning produces reliable, parse-safe JSON every time, which is non-negotiable.
Telora
GreenChain addresses a real, underserved market: the $20T global manufacturing sector has almost no modern, AI-first tooling for emissions-aware sourcing decisions. Procurement teams at mid-market companies (the ones who can't afford a Big 4 sustainability consultant) are currently making supplier selections with no environmental data at all, or worse, relying on self-reported greenwashing from factories.
GreenChain gives them a tool that works in minutes, grounded in real datasets (EPA, Ember Climate, ND-GAIN, GLEC), with a clear monetization path: SaaS subscription per sourcing seat, upsell to deeper Scope 3 tracing and ERP integrations (SAP Ariba, Coupa), and eventual enterprise data licensing for companies that need audit-ready emissions documentation for CSRD and SEC climate disclosure compliance. The regulatory tailwind alone with mandatory supply chain emissions reporting becoming law across the EU and increasingly in the US means this problem is only getting more urgent.
We built a working, end-to-end product in a weekend. The core infrastructure (agent swarm, ML scoring pipeline, scenario editor, report generation) is already there, and we want to think about customer discovery and iteration on the use cases that matter most to buyers. Our team is ambitious and wants to turn GreenChain into the next big thing.
MLH Google Gemini Track
Report generation in GreenChain is a structured technical synthesis involving tables, numbers, etc. The Gemini API receives a fully elaborated signal bundle: three supply chain paths (current, selected, best-eco), per-component emission deltas across manufacturing, transport, grid carbon, and climate risk, plus uncertainty bands from our XGBoost quantile regression (q10/q50/q90). Gemma 4 was specifically the right fit because the report has to correctly interpret signal directionality (e.g. high eco score is good, but high carbon is bad), communicate uncertainty without overstating confidence, and produce consistent five-section markdown. That is, a downloadable report that looks the same every time. Smaller models hallucinated metric values while larger models were overkill and slower. Gemma 4 hit the sweet spot for us.
MLH GoDaddy Track
We registered makethesupplychain.work for our domain, because our project aims to make the supply chain work sustainably again.
Eragon
A procurement manager at a mid-market manufacturer doesn't need a chatbot that summarizes sustainability trends. They need to know, right now, whether sourcing a component from a factory in Portugal versus one in Shenzhen — shipped by sea versus air — is actually better for the planet, and by how much. GreenChain answers that question end-to-end, automatically, in minutes using an internal AI agent.
Challenges we ran into
We found that it was difficult determining the ideal design for user experience. We struggled over the perennial design question: how do we convey information accessibly? How do we maintain a pleasant user experience? We settled on a multitude of user views, toggleable with a middle slider for a custom user experience (whether you wanted a larger graph or a larger world view).
The agent swarm was also difficult to implement. The hardest single problem was signal quality. Brave Search returns a mix of real manufacturers, directory listings, trade aggregators, and SEO-spam factories, and the agent had to learn to distinguish them. We built a multi-pass approach, crawling the actual page to look for sustainability signals then deduplicating by normalized name and country. Even then, some components returned few alternatives, which is why we built the automatic retry-with-expanded-geography loop.
Accomplishments that we're proud of
We shipped a complete, end-to-end product. It's a system that takes an arbitrary sourcing request, fans out across the real web to find manufacturers it has never seen before, scores them against multiple environmental datasets, and renders the results as an interactive globe and supply chain graph in a matter of minutes. The XGBoost model generalizes meaningfully, the Dedalus architecture came out exactly as designed, and the K2 Think V2 two-pass scenario editor produces parse-safe, internally consistent JSON reliably. We also love the frontend. The Three.js globe and the node graph look stunning, and we're all amazed that we pulled it off.
What we learned
Agent reliability is an engineering problem, not a prompting problem. Our first instinct when the swarm returned bad results was to rewrite the system prompt, but the real fix was almost always structural: tighter schemas, deduplication logic, retry loops, etc. Working with different environmental datasets in the same pipeline also taught us just how fragmented the environmental data ecosystem is. It explains why no procurement manager is doing something similar today, and exactly why a tool that abstracts the complexity has real value. This was also our first time working with containers, and we were surprised how easy Dedalus made it, especially with our multi-layer agent swarm.
What's next for Greenchain
The most immediate extension is cost integration — layering in unit cost and lead time so procurement teams can see the Pareto frontier of environmental vs. financial performance.
Beyond that: richer certification signals from third-party registries (B Corp, Ecovadis), deeper Scope 3 upstream tracing, real-time grid carbon using live marginal intensity APIs so that time-of-day production choices show up in the score, and a saved-scenario collaboration layer so sustainability teams can share and comment on supply chain alternatives without emailing spreadsheets.
Longer term, we think GreenChain could integrate directly into procurement platforms (SAP Ariba, Coupa) as a sourcing plugin. Imagine it as a sustainability co-pilot that runs automatically whenever a buyer opens a new request for a quote. The potential is enormous, and we're really excited to develop it further.
Built With
- beautiful-soup
- d3.js
- dedalus-labs
- fastapi
- gemini
- gemma
- godaddy
- hugeicons
- next.js
- numpy
- pandas
- postcss
- pydantic
- react
- scikit-learn
- sqlite
- tailwind
- three.js
- tw-animate-css
- typescript
- uvicorn
- xgboost







Log in or sign up for Devpost to join the conversation.