-
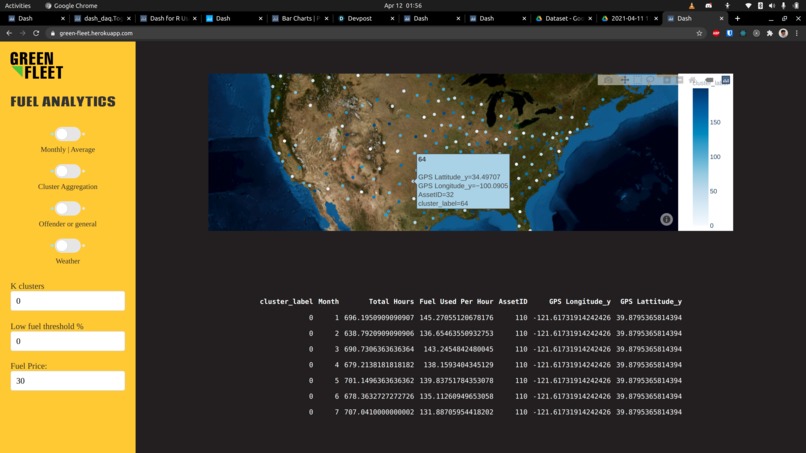
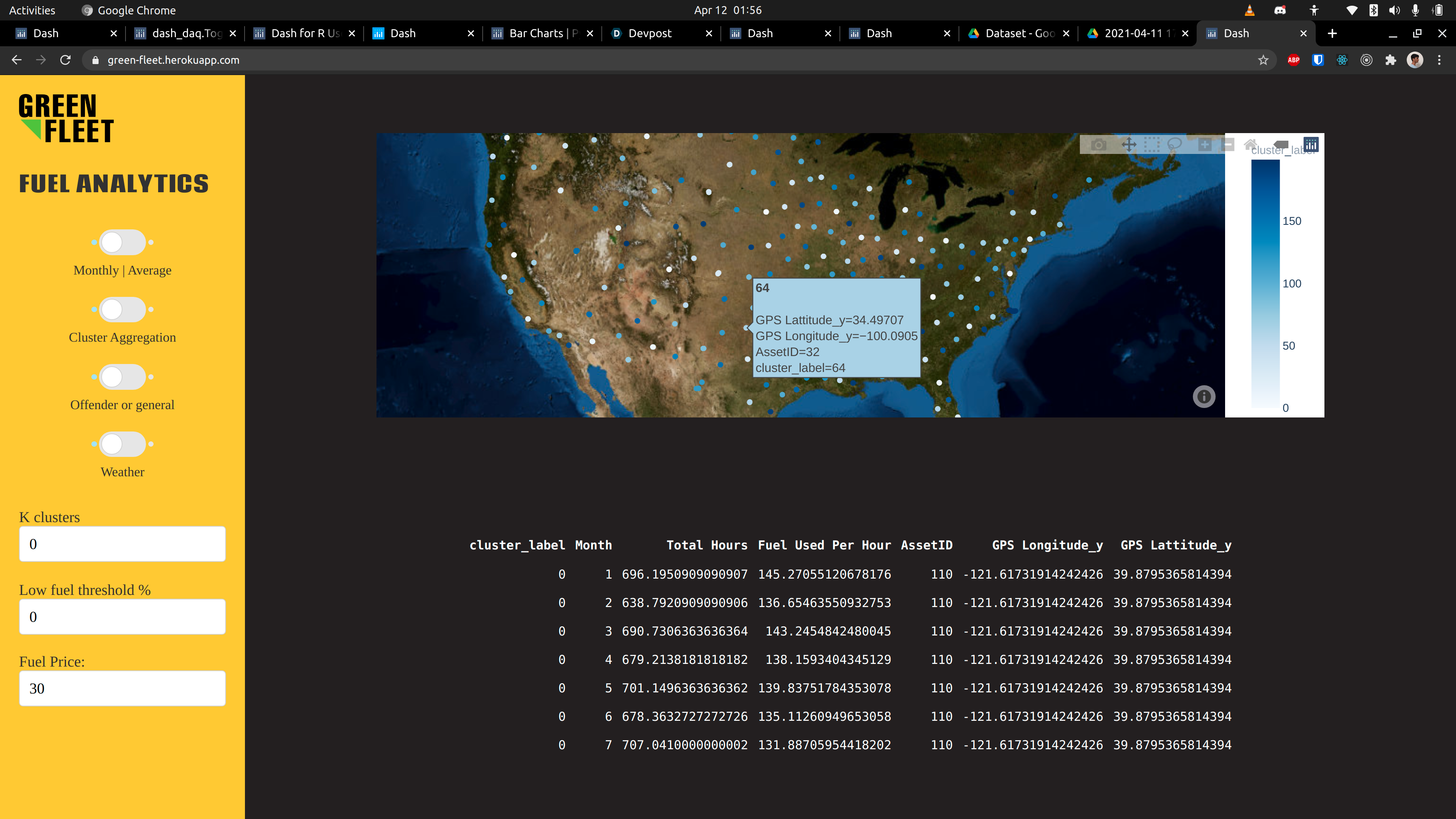
Web Dashboard
-

Green Fleet Logo
-
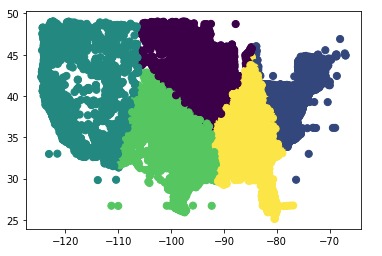
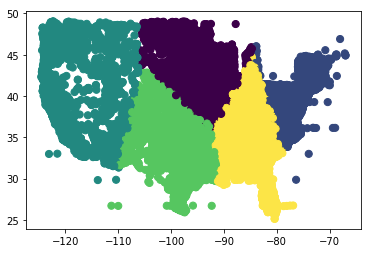
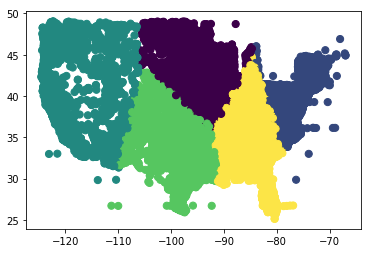
K means clustering of raw data
-
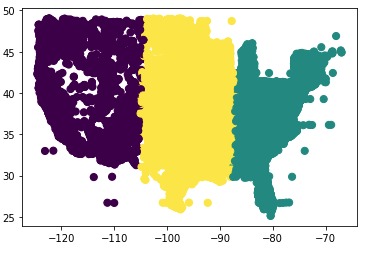
K means clustering of raw data
-
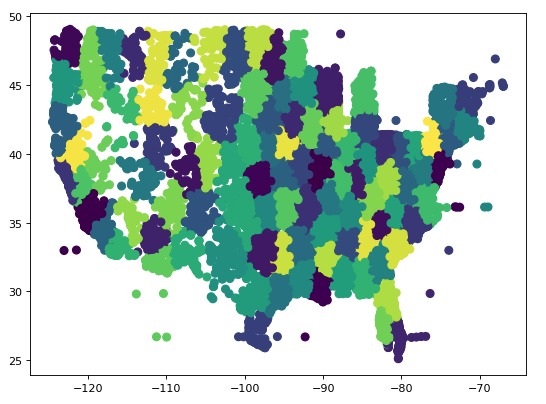
-
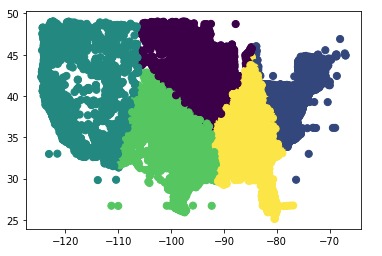
K means clustering of raw data

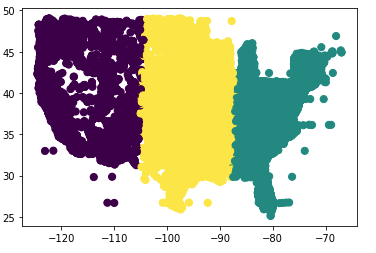
Inspiration:
This project was built as a part of Caterpillar’s ‘Hack My Fleet’ Challenge. With thousands of operational machines and technical equipment across the U.S., logistical management is a very high priority to ensure maximum productive efficiency. The majority of this role is undertaken by fleet managers, who monitor and periodically report the functioning of machines at all active sites in a structured manner. Consequently, Caterpillar maintains a massive dataset containing operational analytics that detail important activity and equipment status. With all these considerations in mind, and the data provided from Caterpillar, we built a fleet management web-app. While operational data is already used to great effect for the purposes of saving damage costs and preventing unequal resource distribution, we decided to expand on fuel insight functionalities for our systematized service. We believe that the tools within will be useful to fleet managers in the real world who want to be more conscious of their carbon footprint and identify underperforming parts of their fleet.
What It Does:
The main goal of the project was to find regularities among discrete parameters and visualize them for the fleet manager. The service front-end would be an online dashboard mainly consisting of an interactive map with some tools to refine information geographically, by density, by type, and other meaningful ways. In addition to this interactive model, there will be a section to identify information that the fleet manager might find important including carbon emissions, and any assets with concerningly low fuel efficiency. The back-end is a set of Python functions that use ML to run clustering and sorting algorithms on the dataset.
How We Built It:
We developed our app very closely to the model provided by Caterpillar. The process, in summary, was broken down into four steps: 1) understanding the data, 2) deriving insights, 3) building the service and 4) deploying the application. First, we used Jupyter Notebooks and Python to analyze the data provided from Caterpillar for any possible trends or variations that could be of value. Eventually, we decided to move forward with visualizing the fuel consumption data with geographic location and time in the form of a web-application. We used Kmeans to form clusters of machines by using latitude and longitude. After choosing this direction, all that was left was to build “Green Fleet.” The front-end was prototyped using Figma, and MS Paint, and finally developed using the Plotly Dash framework for graph visualization. Additional assets were made with GIMP.
Challenges We Ran Into:
Our biggest challenge was the sparse dataset. Having pings sent only once a day made tracking the distance traveled by vehicles or making full use of the fuel level (percent) column not possible in the data analysis step. Additionally having such a limited number of columns made making a predictive application not worthwhile. Examining each provided column for trends, there were no correlations that we did not expect to see. Fuel burned per hour varied substantially based on geography and time, but we didn’t know what was driving it and the pattern looked largely random. The aforementioned problem also impeded some of the functionality of the web app. While there was a suggestion from Kyle Cline to simulate more frequent data pings, we ended up not pursuing this path and simply developing the web app around the given data showing a variation of fuel performance based on geographic position and time. We might have simulated the data if we did not already have our hands full with implementing the web app and cleaning the data so that it is in a useable format . Another factor that affected our workflow was the limited experience of our team. Nearly all of our team members did not have much experience in hackathons, thus figuring out task distribution and planning was a new task. Fortunately, we had a senior student who was frequently involved in such events, and guided us throughout the project. Along with this, the completely online nature of the hackathon led to coordination problems, as we had members in multiple time-zones. Learning about the details of version control and data viz. techniques also took some overhead time, but ultimately benefited our knowledge.
Finally, one of our teammates experienced a power outage that lasted six hours. This greatly limited our data analysis capabilities, and constrained us from polishing our front-end further, as data analysis took a huge portion of our time.
Accomplishments that We’re Proud Of:
We were able to successfully integrate data science algorithms into an interactive webpage. Tying in the use of multiple frameworks and platforms into a unified service in a short amount of time was, ultimately, our greatest accomplishment. While most developer tasks are confined to either front-end or back-end, facilitating a full-stack project such as this one takes relatively higher effort, and we are proud to see it through to completion.
What We Learned:
We learned about the intricacies of asset monitoring and fleet data analytics from the perspective of a large company. By observing historical data, we developed our inferential skills and human-computer interaction principles. We learnt how to meaningfully extract information that is valuable from a specific userbase’s needs. The hackathon as a whole also helped us gain project planning experience and practical coding skills.
What’s Next for Green Fleet:
The web-app we developed has a number of features that would prove useful to a fleet manager and especially an environmentally conscious one. We thought the carbon footprint report was especially meaningful in today’s time as individuals are looking to be more responsible for taking care of the environment. The map also gives unrivaled control to a fleet manager trying to understand what’s happening in their fleet. We’ll continue to refine the service cleaning up UI so that these features can be improved and more accessible to fleet managers.






Log in or sign up for Devpost to join the conversation.