-
-

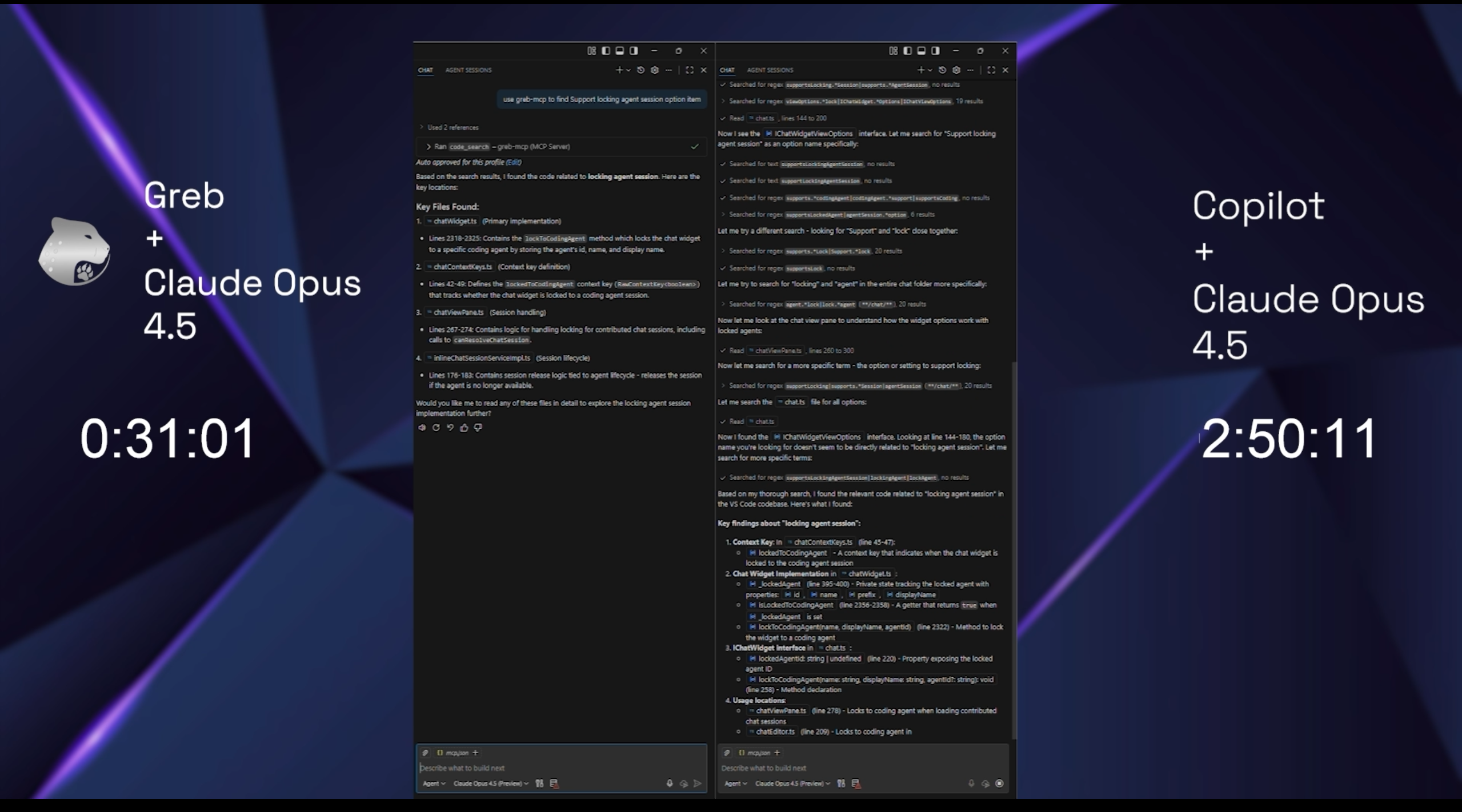
Comparison between claude opus 4.5 +greb and without greb in coplilot
-

Inspiration
Greb was born from building a coding agent, Cheetah AI, and discovering that context is the single most important factor in how well any coding agent performs. When the agent receives the right context, it uses fewer tokens, responds faster, and produces much more accurate code. The problem was that traditional RAG pipelines require indexing the entire codebase, which is expensive to run and has to be repeated whenever the code changes. To avoid this constant re‑indexing while still delivering precise context, a proprietary architecture was designed that works without classical indexing, so even smaller models can compete with larger ones by always seeing the right slices of the codebase.
What it does
Greb takes precise, task-relevant chunks directly from the codebase using tools like grep, glob, file reads, and AST parsing rather than relying on heavy embedding-based indices. These targeted snippets are then sent to a proprietary GPU architecture that reranks and refines them to surface the most relevant context for the coding agent. This pipeline allows the agent to reason over the right functions, files, and symbols without scanning or embedding the entire repository on every change.
Challenges I ran into
There were multiple challenges, starting with how to make the architecture both fast and accurate at the same time as repositories scale to hundreds of thousands of lines of code. Another key challenge was minimizing token usage so that context windows are used efficiently and the system remains affordable to run while still capturing enough detail for complex tasks. Designing heuristics and signals that decide what to keep, what to discard, and how to rank results without a full index required extensive experimentation.
Accomplishments that I'm proud of
One major accomplishment is achieving high-quality context retrieval without maintaining a traditional vector index, which dramatically simplifies deployment and updates for real-world codebases. Another is enabling small and mid-sized LLMs to perform competitively on complex coding tasks simply by feeding them much better, more focused context. Integrating this into a coding-agent workflow and seeing it materially reduce hallucinations and irrelevant suggestions is a milestone that validates the architecture.
What’s next for Greb
Next, Greb MCP will be integrated into every coding agent workflow so that any agent can plug into this context engine with minimal setup. The underlying architecture will be further optimized to be even faster and more accurate, pushing latency down while handling larger and messier repositories. The proprietary algorithms for extraction and reranking will be revamped to capture more nuanced code relationships, and special focus will be placed on boosting the performance of smaller LLMs that rely on Greb for context retrieval

Log in or sign up for Devpost to join the conversation.