-
-
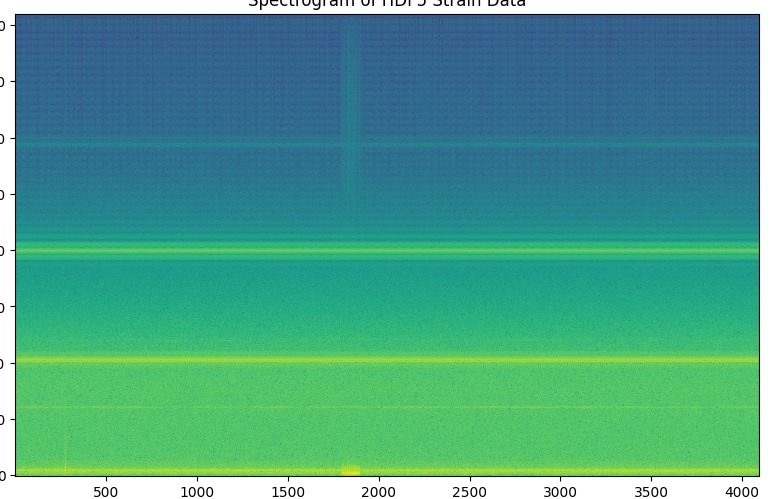
Spectrogram of a possible gravitational wave anomaly
-
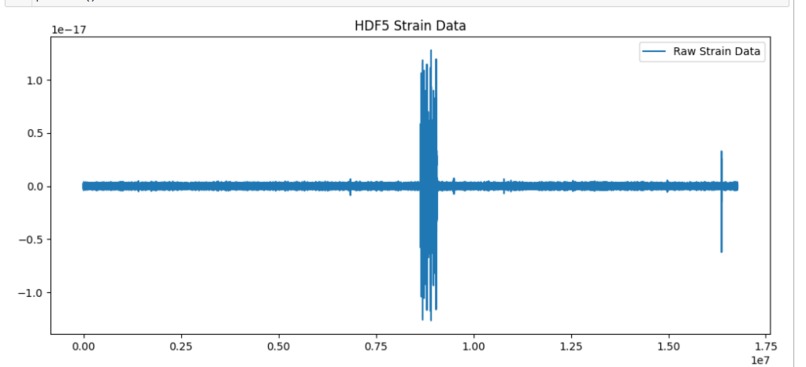
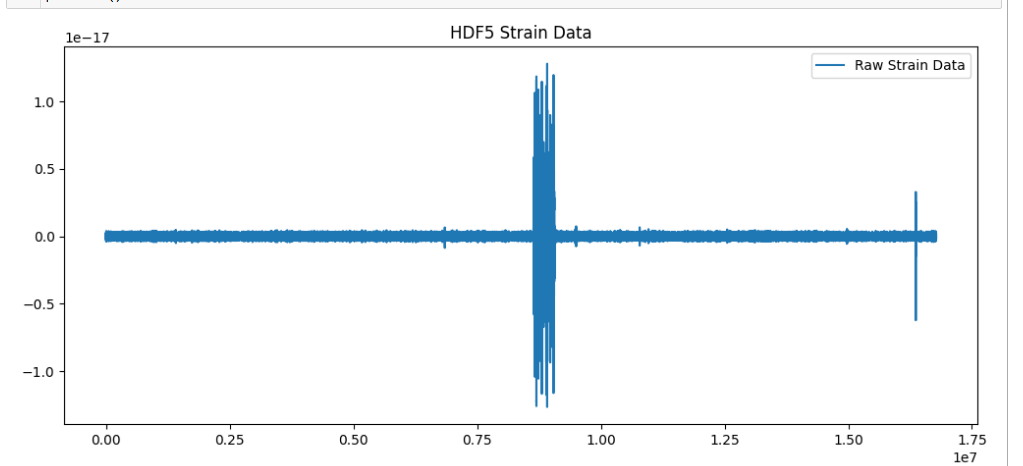
Raw wave strain data graph
-
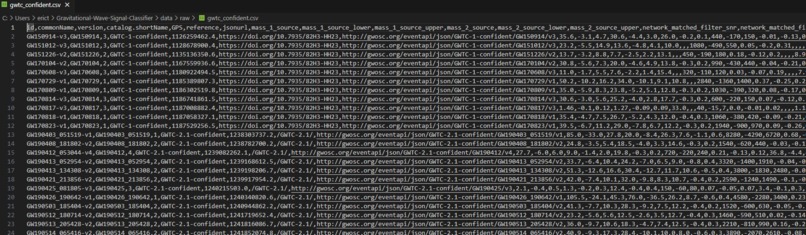
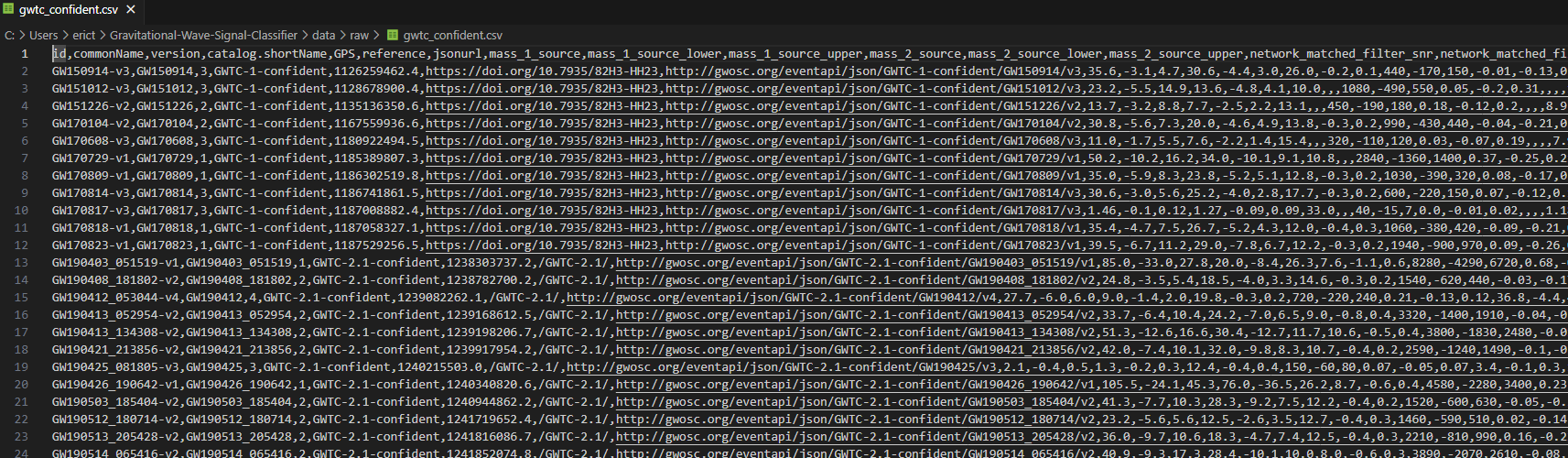
Gravitational event data from the GWTC
Inspiration
Gravitational wave detection plays a major part in the exploration of our universe, giving us an alternative to using electromagnetic signals. The first direct detection of gravitational waves in 2015 confirmed Einstein’s predictions and won the 2017 Nobel Prize in Physics; we believe working on gravitational wave classification means contributing to a new and revolutionary field of astrophysics. However, the raw strain data collected by the LIGO and Virgo labs have a lot of extra noise which interferes with the detection of gravitational waves. We wanted to tackle the challenge of filtering out this extra noise and classifying the waves to determine if a cosmic event had occurred using machine learning and spectrogram analysis. Through this method, we believe we can automate the identification of gravitational waves in the midst of the noise in order to speed up the detection and classification of cosmic events, greatly contributing to a modern field of astrophysics.
What it does
We used a machine learning model trained on labeled data from the Gravitational Wave Open Science Center (GWOSC) to classify real cosmic event gravitational wave data by separating it from the noise in the strain data using spectrogram analysis with prebuilt image feature extraction models. The model also classifies real events based on confidence levels, using the GWTC confident and marginal data from the GWOSC using a feedforward neural network. Our project also filters strain data from .hdf5 files containing data from the Gravitational Wave Open Science Center (GWOSC).
How we built it
We used a Jupyter notebook and various python libraries(sklearn, keras, tensorflow, pandas) to take in data and build models to make predictions. We utilized spectrogram analysis, feedforward neural networks, and tree based classification in order to predict cosmic events.
Challenges we ran into
Throughout our project, we came across several obstacles that tested our problem-solving skills and forced us to adapt our approach. One of our biggest challenges was finding a reliable way to extract meaningful features from spectrograms. While spectrograms are a powerful tool for visualizing signals in the frequency domain, converting them into usable data for our machine learning models was more difficult than expected. Many existing feature extraction techniques were designed for audio signals, making them less effective for gravitational wave data.
Initially, we planned to train a convolutional neural network to classify gravitational wave signals. However, we realized that we didn’t have enough data to train a deep network from scratch. With little training samples, our CNN couldn't handle overfitting and generalization, forcing us to use a tree based classifier, which worked out better.
Working with HDF5 files was more complicated than expected. At first, we ran into issues where we were accessing metadata instead of the actual strain data. Understanding the structure of these files and extracting the time-series strain data was a big step in our project.
Once we had the strain data, another challenge was transforming it into spectrograms. The data required careful preprocessing, and we had to determine the right window sizes and frequency ranges to generate useful spectrogram representations.
Gravitational wave data is incredibly noisy, making it difficult to identify real signals. Some confirmed events even had multiple anomalies when they should have had none, leading to false positives in our model. This forced us to rethink our anomaly detection strategy, taking us to explore tree based classification as an alternative.
Despite these challenges, each roadblock pushed us to think and refine our approach. In the end, our ability to adapt and learn from these difficulties improved our project and gave us a better understanding of gravitational wave analysis and machine learning!
Accomplishments that we're proud of
We were successfully able to build a machine learning model which could classify gravitational wave events from the noise in strain data, using advanced signal processing techniques and patterns we found in our spectrogram and strain data to make anomaly detection algorithms. By understanding the patterns from spectrograms and applying learning methods like random forests and FNNs, our model was able to distinguish between marginal events and confident events with high accuracy (95% for voting classifier and 91% for random forest)
This achievement not only demonstrated our ability to overcome and solve complex problems using ML, but also showed new possibilities for analyzing large-scale astrophysical datasets. With our mode, we are trying to contribute to the ongoing effort to detect and classify gravitational waves, potentially assisting in the discovery of even NEW cosmic events.
What we learned
This project taught us how to work with real astrophysical data and machine learning techniques. Working with LIGO and Virgo data from the Gravitational Wave Open Science Center has given us valuable experience in handling large, complex datasets and extracting meaningful signals from a noisy environment. This has taught us about signal processing techniques such as filtering and spectrogram analysis, as well as how we can automate these processes with machine learning.
Along with this, we learned a lot about the application of artificial intelligence in scientific research. Implementing machine learning models such as tree based classifiers and FNNs gave us insight into how AI can be used for time-series classification and astrophysical discovery. It expanded our understanding of feature engineering, model evaluation, and the challenges of training AI on real-world scientific data. Finally, this project reinforced the importance of teamwork and problem-solving. At the beginning, we knew it would be a challenge to not only build a classification model but also process large data sets effectively. We learned how to allocate tasks based on individual strengths and create an environment where everyone could contribute and grow.
What's next for us
For the next steps in this project, we look to refine our machine learning model by expanding the dataset and increasing its robustness. If we get the opportunity and resources as well, one of the biggest changes we look to make would be to download more hdf5 files. This requires computer space, which we were limited on while doing this project. More computer space would have enabled us to put more data into our random forest classifier (2nd one that takes raw strain data to see if we have anomalies in the data) which would have exponentially increased the accuracy of our model.
One key improvement will be gathering more labeled data from the Gravitational Wave Open Science Center to train the model, which will help overcome the limitations we faced with data scarcity. Additionally, we'll explore more advanced feature extraction techniques and experiment with different neural network architectures, such as convolutional neural networks, to better handle the spectrogram analysis and improve event classification accuracy. We also plan to enhance our data preprocessing pipeline to better manage the complexities of the HDF5 files and reduce the noise in the strain data, allowing the model to focus more on relevant patterns.
Beyond technical improvements, we also look to make the model more efficient. This includes optimizing computational performance, possibly by utilizing parallel processing or cloud computing resources, to handle larger datasets more effectively. Another focus will be improving the interpretability of the model to get better insights of the features that distinguish real gravitational wave events from noise. This will put our project forward but also contribute to the scientific community by providing more reliable tools for detecting gravitational waves, which can lead to new discoveries.
