SDHacks 2015 Talk
Anatomy of Web Scrapers: Building Data Apps
Google Hangout
GraphUCSD:
Web Demo
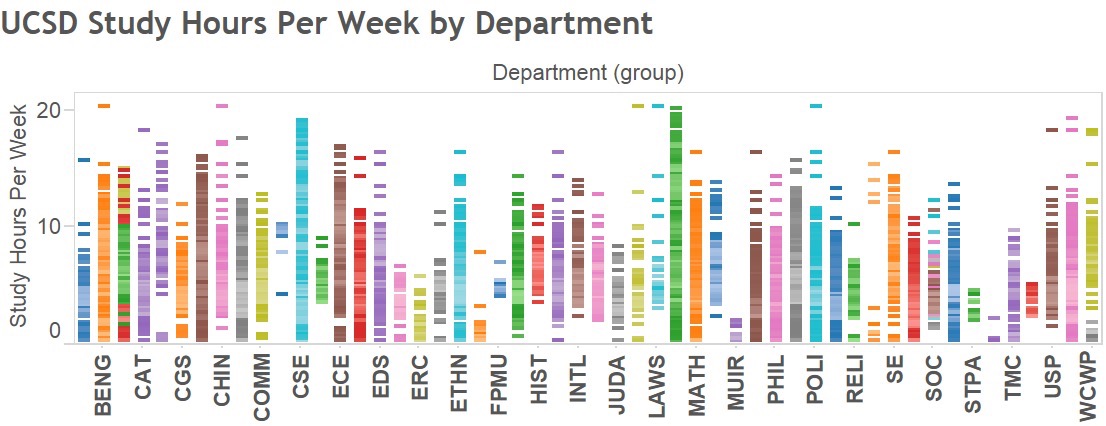
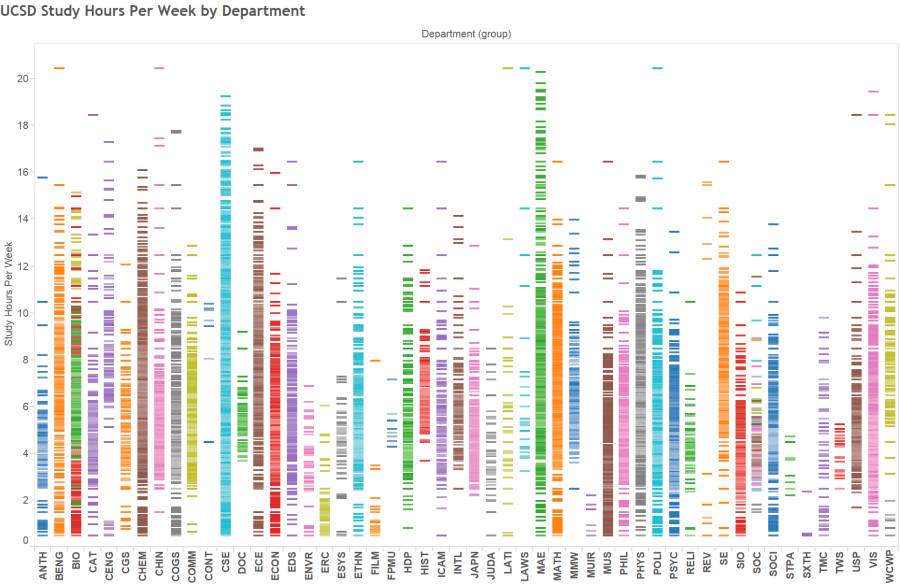
Class Study App using UCSD CAPE Data
Create a interactive visualization composed by the CAPE surveys filled at the end of each quarter
Installation
Easy way (Only OS X and Linux)
$ make all
Install Python Packages
pip install -r requirements.txt
Install Python using Anacondas
Important Libraries
Basically just scraped cape website using Python (Both Python 2 and Python 3 Work), and I used PostgreSQL as the backend. Took about a day to write, and then another day just messing around to get everything to fit the schema, so it was a fun weekend project. The packages that are required to run the scraper are
- requests: for connecting to the site
- BeautifulSoup4: for parsing
- pandas: for data mining
- SQLAlchemy as ORM.
The Anacondas Python Distribution is like the easiest way to get all the packages needed if you wish to try out the code yourself.
I also use a ThreadPool for making connections asynchronously, so that this doesn't take a million years lol.
Visualization
The visualizations I used here are Tableau
Database
So most of the code is actually data munging and cleaning up the data in order to fit the schema for PostgreSQL.
Ultimately, the schema for Postgres looks like this.
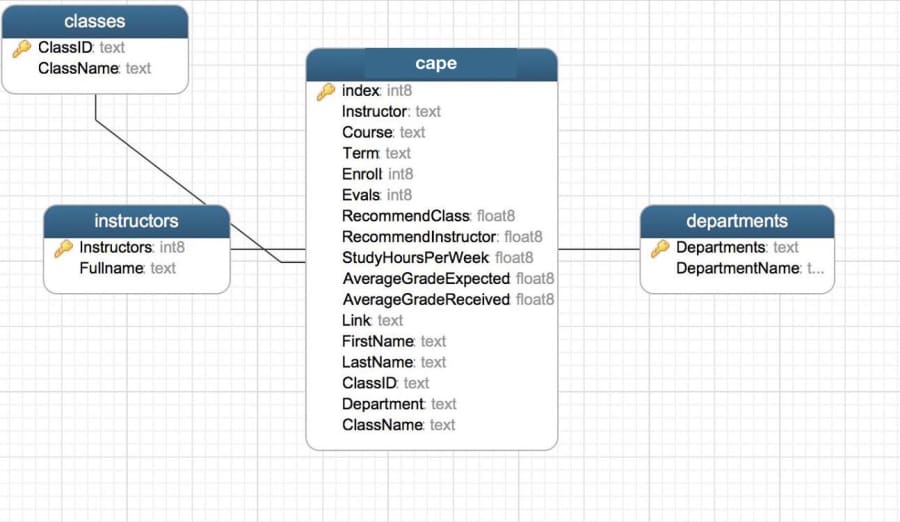
This image is a little bit old, the new schema is a little different, but you get the idea.
Motivation
Motivation for the project came out from a desire to better equip students with class selection.
Oftentimes, students utilize a 3rd party service like https://RateMyProfessor.com to make class choices. This is sub-optimal for both student and professor since these 3rd parties rely on student participation oftentimes causing anecdotal evidence from students to more important. It is disadvantageous for assistant tenure track professors be reviewed dis-favorably among students in ways that may not be consistent.
A Note on Scraping
I know that usually it's not polite to scrape from a service if they already provide an API, like reddit for instance. However, when I went to go look for one, I couldn't find any, so that gave me the green light to go ahead and write a scraper. And honestly, ever since I was a student (like 3 years ago), I was always unsatisfied with CAPE, so this is kind of my way of liberating the data so that students can access it better.
Etc..
Currently it only queries about 30-40 or so different departments and grabs the tables generated for those queries.
However, every single class also has it's own page, but since I didn't want to make 20,000 HTTP requests, I went and only grabbed the front matter.
This kind of opens it up for anyone else, or even myself to build a service that takes into account the rest of the data. In the scraper itself, I've created a column called link that actually points to the individual CAPE's for classes, so I've made it really easy for people to do this.
Conclusion
The product was built for the students with the belief in data transparency will improve the efficiency and give insight to both faculty and student body to make their quarterly decisions.

Log in or sign up for Devpost to join the conversation.