GraphRAG Neo4j Assistant
Inspiration
I was inspired by the growing complexity of knowledge management in organizations where critical information is scattered across numerous documents, databases, and knowledge silos. Traditional search methods often fail to capture the interconnected nature of information and relationships between entities. I recognized that graph databases like Neo4j, combined with modern LLM capabilities, could revolutionize how we interact with organizational knowledge by leveraging the power of connections rather than just content.
The gap between powerful graph database technology and user-friendly interfaces prompted me to create a solution that would make graph-based knowledge exploration accessible to non-technical users while still providing the depth and context that subject matter experts need.
What it does
GraphRAG Neo4j Assistant serves as an intelligent interface to your organization's knowledge graph, offering two specialized search modes:
Global Assistant Mode: Provides broad conceptual analysis by exploring relationships across your entire knowledge graph, helping users understand the big picture and discover unexpected connections between different domains of knowledge.
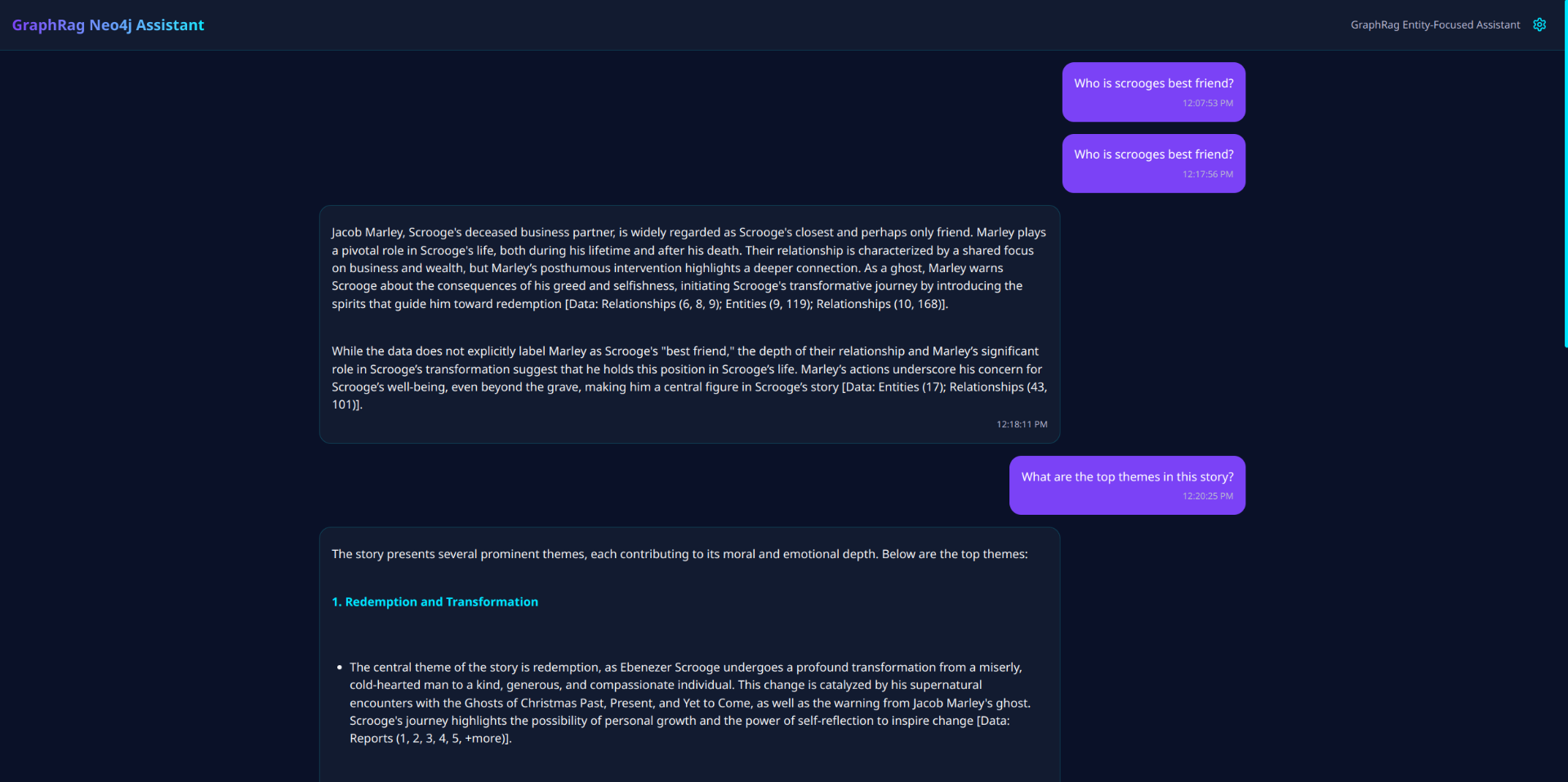
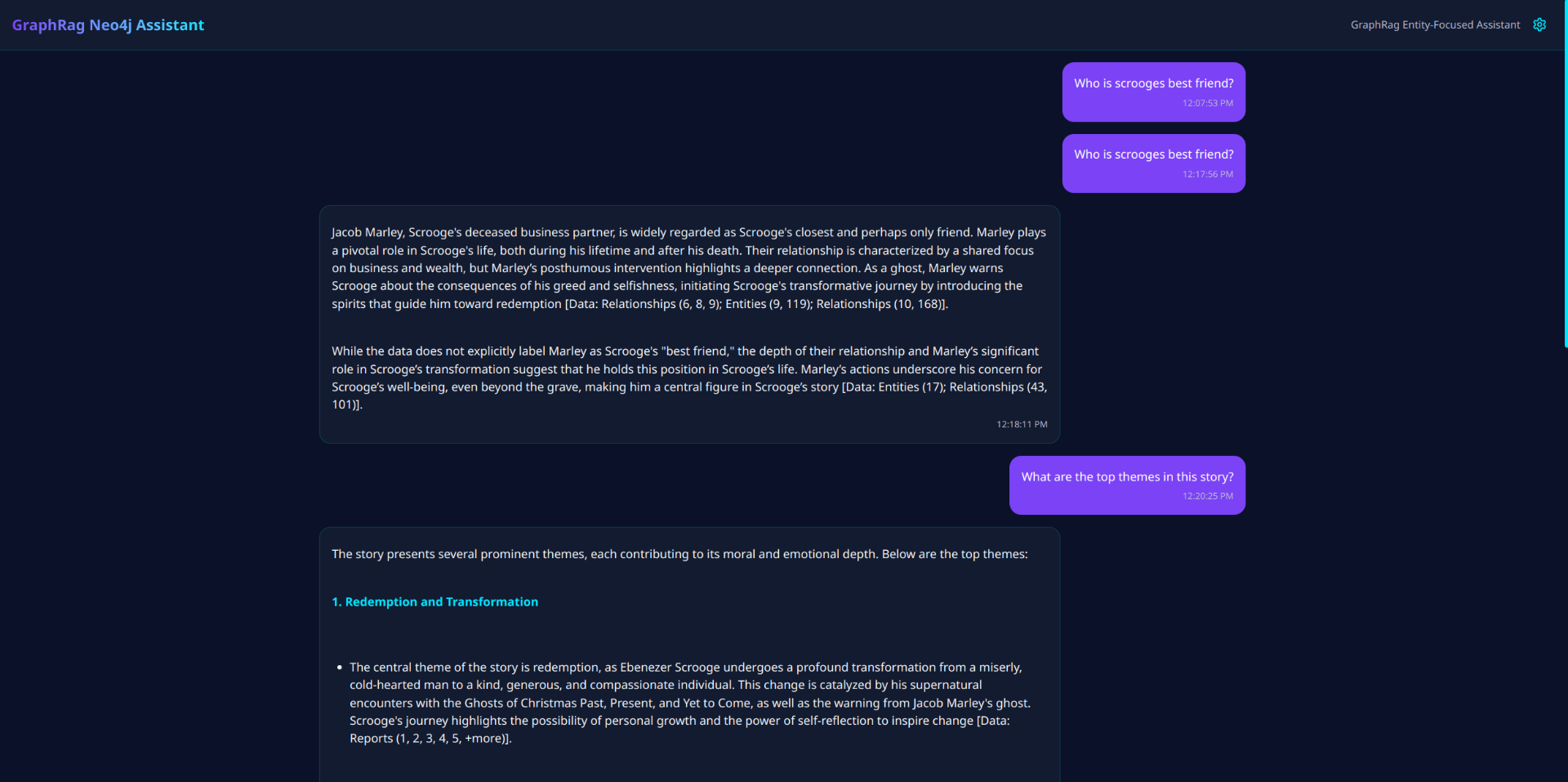
Entity-Focused Mode: Delivers precision searches targeting specific entities and their immediate relationships, ideal for deep-diving into particular topics or understanding the context around specific concepts.
The system automatically routes queries to the appropriate search mode through an agent-based architecture, ensuring users get the most relevant information without needing to understand the underlying technology. All interactions happen through a real-time chat interface that supports markdown formatting and maintains a searchable history of previous queries and responses.
How I built it
I constructed the GraphRAG Neo4j Assistant using a microservices architecture powered by the uAgents framework:
Backend Processing: I developed Python-based agents that handle different types of queries, built on Flask/Quart for asynchronous request handling and LangChain for prompt engineering and LLM integration.
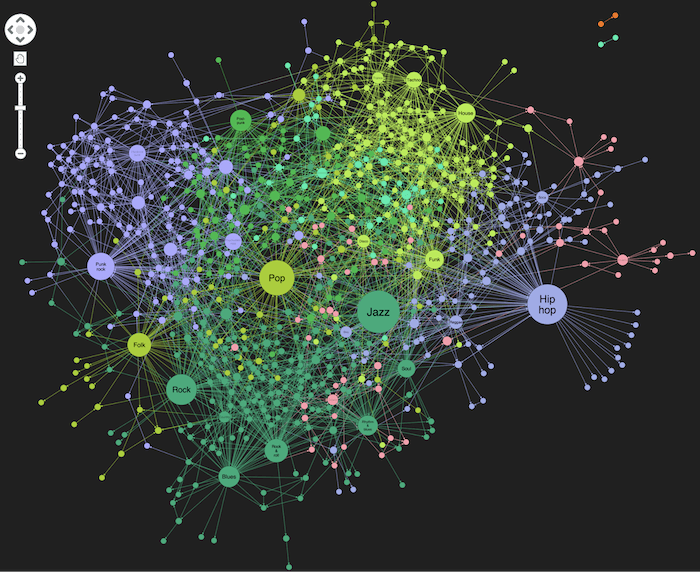
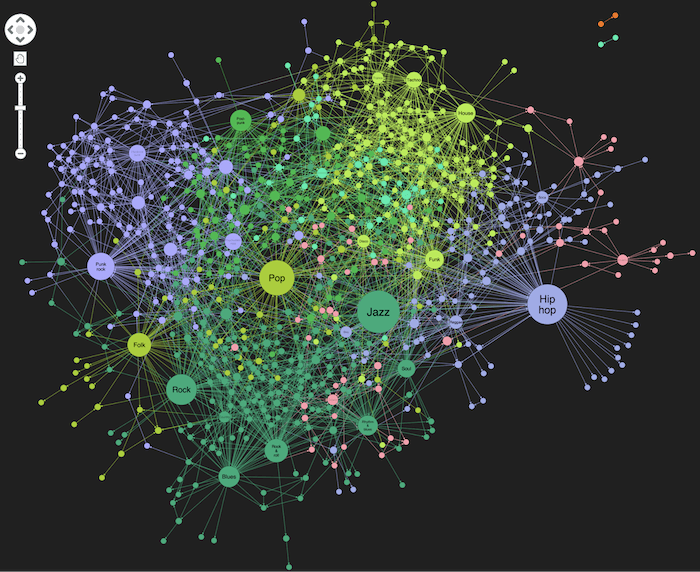
Knowledge Graph Integration: I leveraged Neo4j's graph database capabilities with vector indexing to store both structural relationships and semantic embeddings, allowing for hybrid searches that combine graph traversal with semantic similarity.
Data Indexing Pipeline: I implemented a comprehensive indexing process using Microsoft's GraphRAG framework to extract entities and relationships from documents, generate embeddings using Azure OpenAI or standard OpenAI models, and structure everything into a queryable knowledge graph.
Modern Frontend: I created a responsive user interface using React, TypeScript, and Tailwind CSS that provides real-time feedback while maintaining a clean, intuitive user experience.
Agent Communication: I utilized the Agentverse framework for service discovery and inter-agent communication, allowing the system components to work together seamlessly.
Challenges I ran into
Building GraphRAG Neo4j Assistant presented several significant challenges:
Graph Query Optimization: Crafting efficient Cypher queries that could traverse complex relationship patterns while maintaining reasonable response times required significant optimization.
Context Window Management: Balancing the amount of context provided to the LLM was challenging – too little context resulted in shallow answers, while too much overwhelmed the model's context window.
Accomplishments that I'm proud of
Despite the challenges, I achieved several notable accomplishments:
Seamless Mode Switching: The system intelligently determines whether a query requires global knowledge exploration or entity-focused analysis without explicit user direction.
Scalable Architecture: My agent-based approach allows for horizontal scaling as query volume increases, with each component handling its specialized task efficiently.
Hybrid Search Algorithm: I successfully implemented a retrieval strategy that combines both the structural advantages of graph traversal and the semantic understanding of vector similarity.
Flexible Deployment Options: The system works with both Azure OpenAI and standard OpenAI services, giving organizations deployment flexibility based on their existing infrastructure.
Comprehensive Documentation: I created detailed guides for installation, indexing, and troubleshooting to ensure smooth adoption by development teams.
What I learned
The development process yielded several valuable insights:
Graph Databases for RAG: Traditional vector databases are powerful for semantic search, but graph databases offer additional relationship context that dramatically improves answer relevance and explainability.
Agent Orchestration: Designing systems with specialized agents that communicate autonomously creates more robust and maintainable architectures than monolithic applications.
Embedding Strategy: The choice of embedding model and dimensionality significantly impacts both retrieval quality and system performance – finding the right balance is essential.
Context Engineering: How context is constructed and presented to LLMs has a profound impact on response quality, often more so than prompt engineering alone.
Neo4j Vector Capabilities: Neo4j's recent advancements in vector search functionality make it a viable single-database solution for both traditional graph operations and semantic similarity searches.
What's next for GraphRAG Neo4j Assistant
I have ambitious plans for the future of GraphRAG Neo4j Assistant:
Dynamic Schema Adaptation: Implementing capabilities to automatically adapt to different knowledge graph schemas without requiring manual configuration.
Enterprise Integration: Creating connectors for common enterprise data sources like SharePoint, Confluence, and internal databases to streamline the knowledge ingestion process.
Fine-tuning Capabilities: Adding support for fine-tuning foundation models on domain-specific data to improve response quality for specialized knowledge domains.
The GraphRAG Neo4j Assistant represents just the beginning of what's possible when combining graph databases, agent-based architectures, and large language models for knowledge management. I'm excited to continue pushing the boundaries of what's possible in this rapidly evolving field.


Log in or sign up for Devpost to join the conversation.