-
-
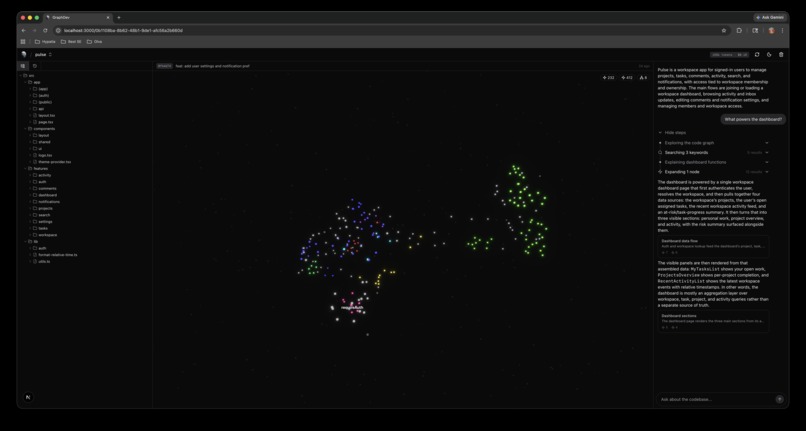
GraphDev UI
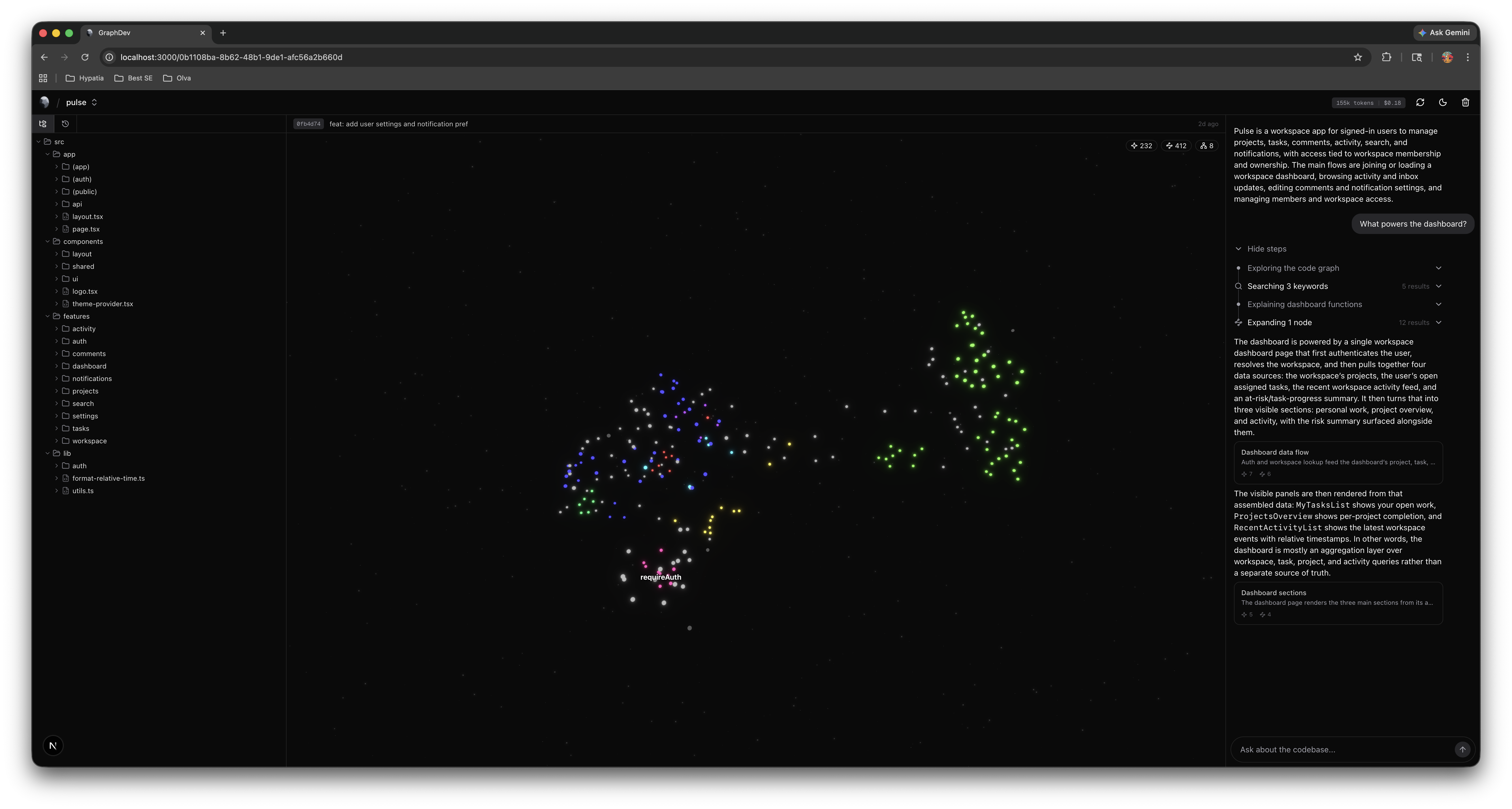
GraphDev: From Blind Diffs to Structural Understanding
About the Project
Inspiration
Vibe coding is fast. Teams ship features in hours, not weeks. But the speed creates a problem: nobody fully understands what they built. When a PR lands, the reviewer sees a diff — changed lines in changed files. They don't see that modifying TaskForm ripples through TaskBoard, which ripples through Dashboard, which affects three subsystems they didn't know were connected.
Blind reviews in vibe-coded repos lead to subtle breakages, missed integrations, and architectural drift. We built GraphDev to fix this.
What It Does
GraphDev turns a codebase into a semantic graph, then powers an agent that understands the true structural impact of every PR.
The graph engine parses TypeScript/Next.js codebases using tree-sitter, extracts code units (functions, components, hooks, API handlers), maps dependency edges (calls, renders, http_calls), generates LLM descriptions and embeddings, clusters subsystems using HDBSCAN, and computes 2D/3D layout via UMAP.
The PR agent reacts to merge request events. It diffs the PR against the graph, runs BFS ripple analysis to find indirectly affected code, scores subsystem-level impact, and posts a structured review comment with risk level, affected units, gaps found, and a link to an interactive graph visualization.
The Duo Chat agent lets developers explore architecture interactively. "What connects to the task system?" "Analyze MR !3." "Fix the gaps you found." It calls the GraphDev API, presents impact reports, suggests improvements, and commits fixes with approval.
How We Built It
The system has three layers:
GraphDev Engine (FastAPI + SQLite) — tree-sitter parser extracts code units and edges from TypeScript. OpenAI generates descriptions and embeddings. HDBSCAN clusters units into feature subsystems. UMAP computes layout coordinates. The MR analysis endpoint diffs branches, walks the graph via BFS, and produces an ImpactReport with risk scoring.
Graph Visualization (Next.js + Three.js) — interactive 3D graph where nodes are code units, edges are dependencies, and colors represent subsystems. MR overlay mode highlights changed nodes in red, ripple-impacted nodes in yellow, and dims unaffected code.
GDAP Integration — a custom agent (GraphDev Explorer) for interactive Duo Chat analysis, and a custom flow (GraphDev PR Analyzer) that auto-triggers on MR events and posts impact comments. Both run Anthropic through GitLab AI Gateway.
Architecture
PR created on GitLab
|
v
Flow triggers --> analyzes diff, reads files, posts impact comment
|
v
Developer opens Duo Chat --> GraphDev Explorer agent
|
v
Agent calls GraphDev API (analyze-by-url)
|
+--> Clones repo, parses with tree-sitter
+--> Diffs against semantic graph
+--> BFS ripple analysis (depth 2, skips hubs)
+--> Scores cluster-level impact
+--> Returns ImpactReport + visualization URL
|
v
Agent posts structured report + graph link
|
v
Developer views interactive graph visualization
|
v
Agent suggests fixes --> developer approves --> agent commits
|
v
Agent syncs graph --> updated visualization
Challenges
Cross-project triggers: The hackathon namespace restricts force-pushing and project creation. We solved this by embedding the target codebase (Pulse) inside the hackathon project with a source_root parameter that scopes the parser to a subdirectory.
Cluster labeling: HDBSCAN clusters were getting generic labels ("ui", "workspaces") because labels were derived from centroid file paths. We replaced this with majority-vote labeling across all cluster members, producing feature-aligned labels (tasks, notifications, dashboard, settings).
Graph diffing at scale: Comparing a PR branch against a graph snapshot requires parsing changed files in isolation while preserving context from unchanged code. We use symlinks to reconstruct the full project tree in a temp directory, then run the parser against it.
What We Learned
- Tree-sitter is remarkably good at extracting semantic structure from TypeScript — function boundaries, JSX component detection, import resolution all work reliably.
- HDBSCAN with embedding vectors produces meaningful subsystem clusters that align with human-designed feature boundaries — if you label them correctly.
- The gap between "seeing a diff" and "understanding impact" is exactly what a semantic graph fills. The agent can identify missing integrations (unwired functions, missing activity logging) that a human reviewer would likely miss.
Built With
- anthropic-claude
- fastapi
- fly.io
- gitlab
- gitlab-ai-gateway
- gitlab-duo-agent-platform
- hdbscan
- next.js
- numpy
- openai-api
- python
- react
- scikit-learn
- shadcn/ui
- sqlite
- sqlmodel
- tailwind-css
- three.js
- tree-sitter
- typescript
- umap
- zustand




Log in or sign up for Devpost to join the conversation.