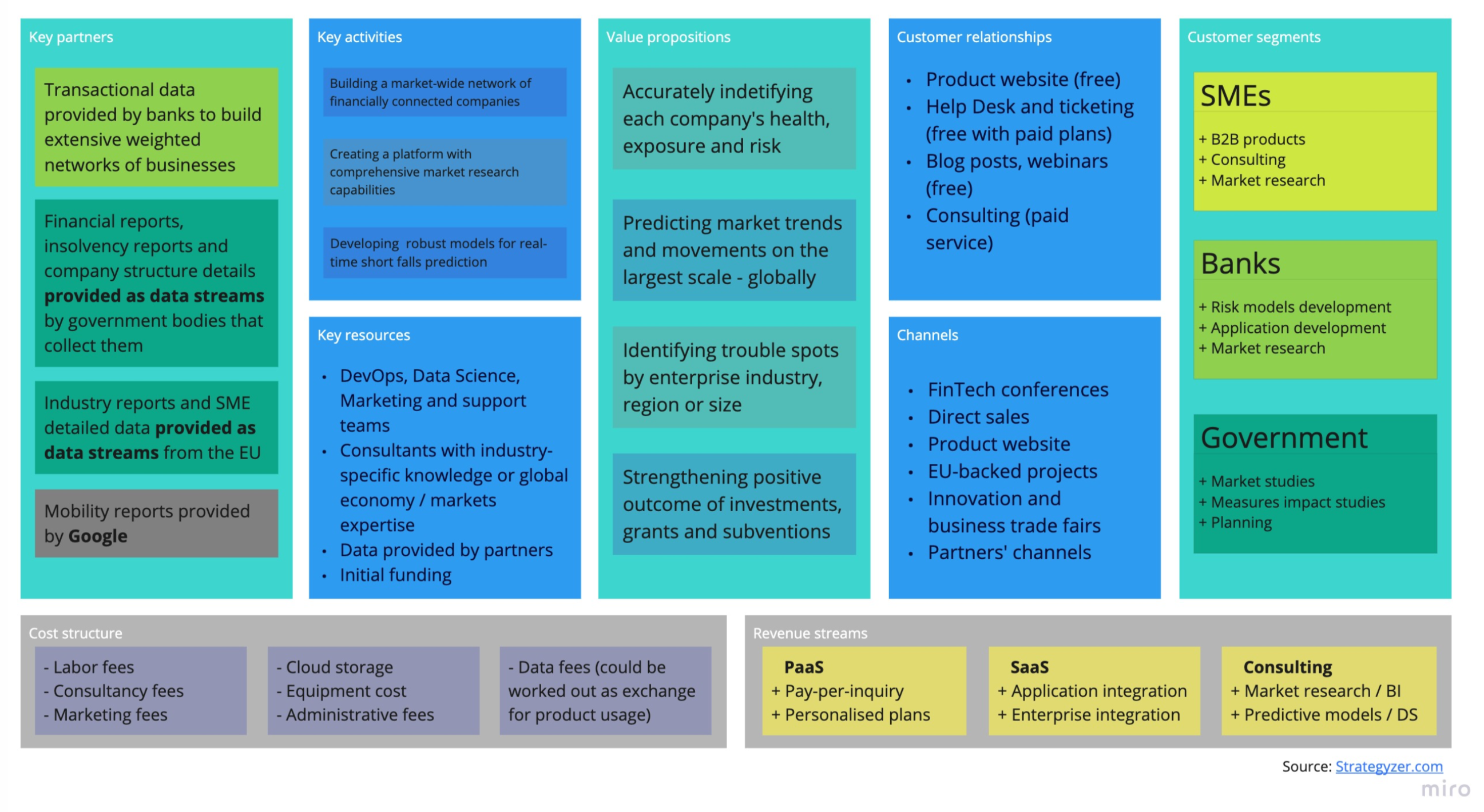
Inspiration
The inspiration comes from exploring publicly available financial (or financial-related) datasets. We wanted to get as close to the banks' predictions of default as possible, using just a fraction of data of a much lower quality. If we could accomplish that, it would serve as a good enough base to apply to the modelling of the economic downturn we find ourselves in due to COVID-19 pandemic. We hypothesise that this model, when built upon more accurate and detailed data, would be able to pin-point the trouble spots, help identify the healthy businesses and those who can survive with minimal funding, which would make it a great asset in the fight to restore the economy.
What it does
The key feature in our model is adding the network of connected companies (companies that may be in business with each other) to the financial data. This means turning a network graph into a series of variables that are readable inputs for our machine learning algorithms, also known as graph embedding. We found that even the smallest networks have profound impact on all of their nodes' behaviours. Combined with industry mobility reports this would give us a much clearer picture of how exposed a company actually is in this time of potential economic crisis.
How we built it
We used python as our main language and deepnote as our development platform. Our predictive model is built on lightgbm and we used node2vec for graph embedding. We also used standard data science libraries in python, like pandas, scipy, scikit-learn etc. As far as data goes, we took the advantage of publicly available financial data of Croatian companies, as well as the Croatian Market Court Registry, to get company officers and members (board or otherwise). We linked companies if they shared a common person as either one of the members and officers, under the assumptions that:
- bad leaders (with a history of failures) will most likely ruin their companies
- good leaders will likely pull (or keep) their companies in the black
- if two companies share more than 2 members/officers (i.e. are neighbouring nodes in the same network), they are likely to be in business together (surprisingly accurate for small markets such as Croatia)
To account for the crisis, we used the aforementioned mobility reports to simulate the expected losses (in industries related to those reports) in 3 scenarios:
- Business as usual by June 1st
- Business as usual by September 1st
- Business as usual by the end of the year
For companies with no apparent ties to the mobility reports, we used the overall insolvency increase to slightly modulate the financial data.
Challenges I ran into
There were two main challenges:
- Getting the data - even though it is public, getting quality data has proven to be much less available then originally thought
- Building a business model - fooled naively by the assumption that "Hackaton" meant lots of writing code I completely disregarded the need to expand on the business model of the project. Thankfully our mentor was very forthcoming
Accomplishments that I'm proud of
As a team we've managed to get a working submission on our first Hackaton, which was our goal from the start. As team lead, I am proud of my resourcefulness in the area of Business Modelling and pitching
What I learned
I learned how unprepared we came here, what it means, and takes, to do a hackaton and how to approach the next one (with more business-oriented people in the team). Also, I learned quite a bit about Business models for such a short time.
What's next for Graph Embedding for Insolvency Prediction
Next is trying to partner up with governments or banks (or both, preferably) to be able to use transactional data and build real weighted networks of companies. If we do that, then improving, writing clean and scalable code, deploying, testing - and a lot of hacking. :)



Log in or sign up for Devpost to join the conversation.